







文章目录
一,进程创建
1.1 进程创建概念
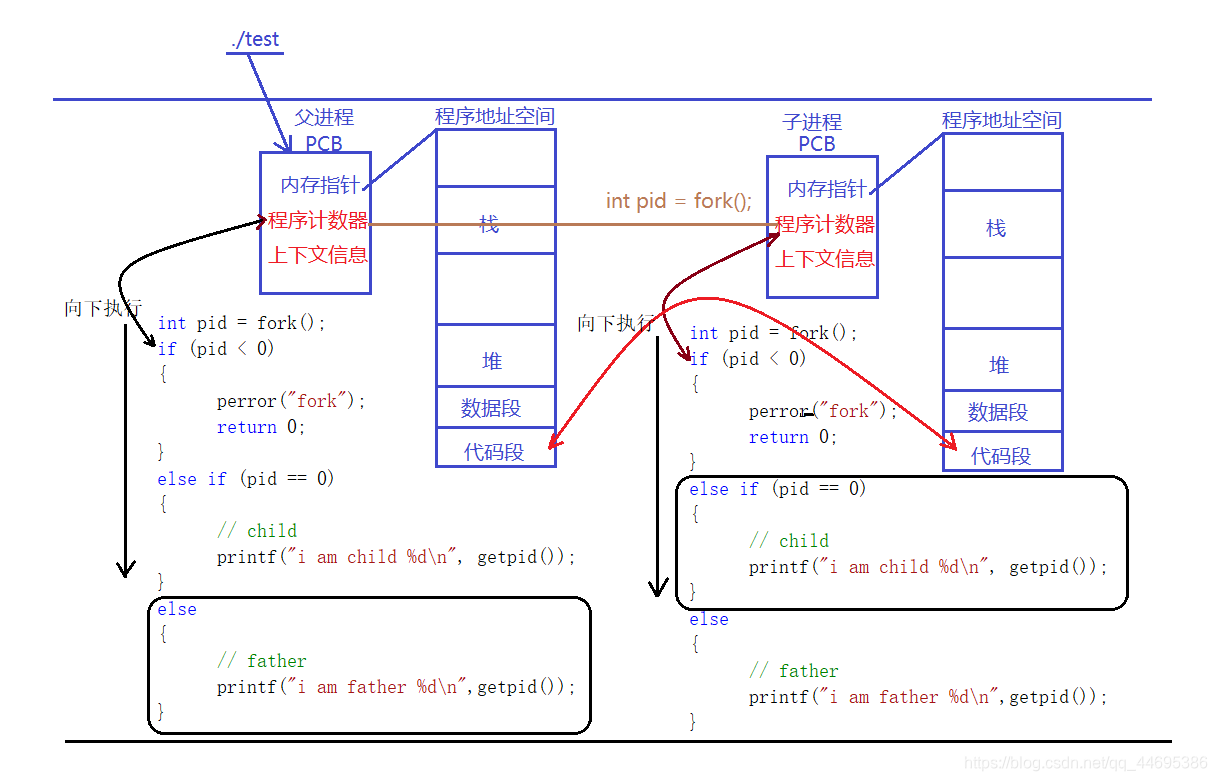
创建一个进程就是创建一个PCB,因为PCB在Linux下就是一个task_struct结构体,这个结构体存放在内核中,只能通过系统调用接口实现创建。
为什么要创建子进程??
子进程干的事情与父进程一样,当然使用返回值分流后有所不同;
有任务了,创建一个子进程,让子进程去完成任务,出了问题崩溃的就是子进程,父进程就不会崩溃了(保护父进程,分解压力)
代码共有,数据独享。
1.2 fork函数
pid_t fork(void);
通过复制父进程创建一个子进程(复制了父进程pcb中的数据)-----代码共享,数据独有。
返回值:对于父进程返回的是子进程的pid,是大于0的;
对于子进程返回值等于0;
返回值小于0—>错误(创建失败);
通过返回值可以实现父子进程代码分流
fork特性:
子进程将父进程中打开的所有文件描述符都复制了一遍,父子进程中相同编号的文件描述符在内核中指向同一个file结构体,也就是说,file结构体的引用数量增加了。
子进程不会继承父进程的一些数据:
1.子进程不复制父进程设置的锁(若继承会导致排它锁矛盾)
2.子进程不复制父进程的pid,而是产生自己的pid
3.子进程不复制父进程中的pending alarms和pending signals,而是将自己的pending alarms清除,将pending signals置为空
fork产生失败可能的两个原因:
1.当前运行中的进程数已经达到了系统规定的上限,此时错误码(errno)的值为EAGAIN
2.当前系统内存容量不足以开辟一个新的进程,此时错误码(errno)的值为ENOMEM
1.3 vfork函数
pid_t vfork(void);
1.vfork创建出来的子进程PCB拷贝部分父进程的PCB的,但是子进程的PCB执行父进程的虚拟地址空间
2.因为父子进程共有虚拟地址空间,使用了同一个栈,则若父子进程同时运行,就会带来了父子进程调用栈混乱的问题
3.因此vfork是先让子进程执行,父进程等待子进程执行完毕之后再执行
注意:
1.应当使用exit或_exit来终止vfork创建的子线程,不能使用return来终止。
若使用return来终止子线程会导父进程回到调用vfork处,进而无限创建子进程进而产生段错误
2.vfork函数返回值特点与fork相同。
1.4 fork函数和vfork函数的区别
fork相当于父母给孩子买了一套房子,父母住一个房子,孩子住一个房子。
vfork相当于孩子和父母住同一个房子。
不同点:
1. fork创建的子进程是父进程的一个副本,子进程将父进程的堆栈中存的数据信息拷贝一份到另外开辟的内存中去,并不能共享这些数据;
vfork创建的子进程并不会立刻开辟新内存拷贝数据,而是共享父进程的堆栈中的数据,直到子进程终止或者被替换之前,都是在父进程的空间中运行
2. vfork保证子进程先运行;fork是让两个进程异步运行
相同点:
fork和vfork都是调用一次,但是返回两次
二,进程终止
2.1 进程终止概念
进程终止就是如何让一个进程退出。
注意:普通函数中的return只能退出函数,不能退出进程。
进程退出的场景:
1.程序跑完了所有代码,从main函数退出
代码跑完,结果正确
代码跑完,结果不正确
2.程序没有跑完代码,程序崩溃掉了
2.2 exit 库函数
void _exit(int status);
- 功能:正常终止进程, 在任意位置调用 void exit(int status);可以在程序的任意位置退出一个进程
- 头文件:stdlib.h
- status:返回给父进程的状态值,通常用0或EXIT_SUCCESS表示成功,通常用非0或EXIT_FAILURE表示异常程序终止
2.3 _exit 系统调用
void _exit(int status);
- 功能:立即终止子进程,并关闭所有属于该进程的文件描述符,该进程的所有子进程过继给init进程,并向父进程发送SIGCHLD信号,将status作为子进程退出状态返回给父进程
- 头文件:unistd.h
- status:返回给父进程的状态值,通常用0或EXIT_SUCCESS表示成功,通常用非0或EXIT_FAILURE表示异常程序终止
2.4 exit和_exit的异同
不同点:
1.exit是库函数,_exit是系统调用函数
2.exit会执行用户自定义的清理函数,而_exit则不会
3.exit会冲刷缓冲区,并且关闭流等,而_exit则不会
相同点:
1.退出子进程并向父进程返回退出状态信息
2.exit是_exit的封装形式
异常退出的情况:
解引用空指针,ctrl+c, 内存访问越界等......
三,进程等待
3.1 为啥要进程等待?
进程等待就是为了防止僵尸进程的产生。
父进程等待子进程退出,获取子进程的退出返回值,释放退出的子进程资源,避免子进程成为僵尸进程。
3.2 进程等待的方法
pid_t wait(int* status);
-
status:是一个出参,供调用者获取子进程的退出状态(切记不是退出码)
-
返回值:如果成功,则返回子进程的pid; 如果失败,则返回-1(比如没有子进程)
-
功能:调用wait会导致父进程陷入阻塞状态,直到有一个子进程退出,则执行wait的逻辑之后退出
pid_t waitpid(pid_t pid, int* status, int options);
参数:
- pid:要等待子进程的进程号
pid == -1 等待任意子进程退出
pid > 0 等待指定子进程(等待进程号为pid的子进程)
- status:退出的子进程的退出状态
status是一个四个字节的数据,但是只用了低两个字节
>正常退出:只用了这两个字节当中的高8位,来表示进程的退出码 (status>>8)&0xff
异常退出:只用了这两个字节当中的低8位
高的第8位,表示:是否产生coredump标志位 (status>>7)&0x1
低的7位,表示异常信号 status & 0x7f

- options:设置当前的waitpid是阻塞的还是非阻塞的
WNOHANG 非阻塞 如果在掉用非阻塞的waitpid接口的时候,如果等待的子进程没有退出,waitpid也不会等待,直接返回,执行后面逻辑。
非阻塞需要搭配循环去使用: 如果非阻塞的接口在调用waitpid时,没有等待到子进程退出,则循环去调用waitpid接口。
0 阻塞
- 返回值:成功则返回已经退出子进程的pid大于0;若没有子进程退出返回0;若出错则返回-1;
3.3 wait和waitpid的不同之处
1.wait等待的是任意一个子进程的退出(wait是一个父进程假设有很多子进程,任意一个退出,都会处理后调用返回)
waitpid可以等待指定的子进程,也可以等待任意一个子进程,通过第一个参数确定(第一个参数pid==-1则表示等待任意)
2.wait是一个阻塞等待(wait如果没有子进程退出,则会一直等待)
waitpid可以默认阻塞,也可以设置为非阻塞,通过第三个参数确定(第三个参数option==0表示默认阻塞;option==WNOHANG则表示非阻塞)、
总结:
waitpid(pid大于0,status,0)相当于wait接口
wait接口实现其实就是调用waitpid实现。
四,进程程序替换
原理:
通过进程PCB当中的内存指针,找到进程虚拟地址空间当中的数据段和代码段,通过页表映射将数据段和代码段映射到新的程序的物理内存上,直白点,使用新的程序将之前的数据段和代码段进行更新。
程序替换是在当前进程pcb并不退出的情况下,替换当前进程正在运行的程序为新的程序(加载另一个程序在内存中,更新页表信息,初始化虚拟地址空间)
程序替换:
给一个进程替换一个新的要调度运行的程序,并且因为这个进程调度的程序已经被替换,因此当运行完毕新的程序后就会退出;原先的程序在程序替换以后的代码都不会被运行到(替换后相当于已经没有当前的代码了,只有新的程序)
看到的现象:
1.进程标识符(PID)是没有变化的
2.如果替换成功,执行的是替换之后的程序,输出的内容也和之前没有任何关系了
4.1 调用哪些函数来进行进程程序替换?
一般通过替换函数来完成进程程序替换,也就是exec函数簇:
int execl(const char* path, const char* arg,…)
path:带路径的可执行程序(ls /usr/bin/ls)
arg: 给可执行程序传递的参数,第一个参数是可执行程序的名称 ls -a /usr/bin/ls ;s -a
… 可变参数列表,以NULL结尾
返回值:
只有失败的时候才会配拥有返回值,返回值为-1,成功替换了,就不会再返回了
int execlp(const char* file, const char* arg, …)
file: 可执行程序的名称,如果单单只传递名称,那么就需要在PATH环境变量中配置可执行程序的路径。同时也支持传递带有绝对路径的可执行程序。
arg: 给可执行程序传递的参数,第一个参数是可执行程序的名称
… 可变参数列表,以NULL结尾
int execle(const char* path, const char* arg, …, char* const envp[]);
path: 带路径的可执行程序
arg: 可执行程序的参数,以NULL结尾
envp: 程序员自己组织环境变量,如果不传入环境变量则认为当前进程没有环境变量自己组织环境变量的时候,一定需要以NULL结尾,如果不以NULL结尾,就会报错:Bad Address
int execv(const char* path, char* const argv[]);--定参的函数
path:带路径的可执行程序
argv:给替换的程序传递的命令行参数,如果不传,则替换成功的进程当中没有命令行参数。如果传参,则必须以NULL指针结尾。
Int execvp(const char* file, char* const argv[]);
file:可执行程序的名称,同时这个可执行程序要能在PATH环境变量当中找到,否则程序替换就失败了;同时也可以传递一个带有路径的可执行程序
argv:要给可执行程序传递的参数,第一个参数是该程序的名称, 以NULL结尾
Int execve(const char* filename, char* const argv[], char* const envp[]); 系统调用函数
filename: 可执行程序的名称
argv: 定参的函数,argv:要给可执行程序传递的参数,第一个参数是该程序的名称,以NULL结尾
envp: 程序员自己组织环境变量,如果不传入环境变量则认为当前进程没有环境变量
exec函数簇当中带p和不带p区别:
如果exec函数的名称当中带有p,则表示会搜索环境变量,并且第一个参数带p的传入可执行程序的名称,不带p则传入带路径的可执行程序
exec函数簇当中带e和不带e的区别:
如果不带e则不需要程序员去组织环境变量,内核会将环境变量继承下来;
如果带有e,则需要程序员去组织环境变量,如果程序员传入NULL,则替换的程序当中没有环境变量,如果传入非NULL,则指针数组的环境变量需要使用MULL结尾。
exec函数簇当中带有l和带有v的区别:
l:表示使用可变参数列表
v:表示是一个定参的函数,使用数组进行传参
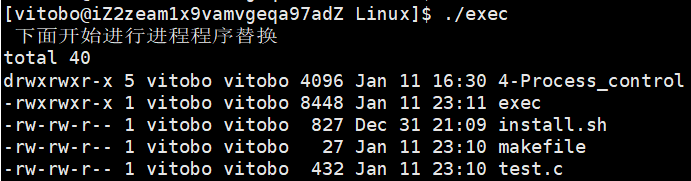
代码演示:
#include <stdio.h>
#include <unistd.h>
int main()
{
printf(" 下面开始进行进程程序替换\n");
// 将当前程序替换为ls程序
// l表示命令行以可变参数列表的形式给出,没有p则说明需要带路径,没有e 说明不需要自己组织环境变量
execl("/usr/bin/ls", "ls", "-l", NULL);
// 如果替换成功,下面语句将不再执行
printf("替换失败!!!\n");
return 0;
}














 65万+
65万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









