






一、分层介绍
ODS、DWD、DIM、DWS、ADS
实时写入、实时读取-》消息队列kafka
ODS、DWD -》 kafka
DIM ?
DWS ?
ADS ?
DIM:事实数据根据维度ID查询相应的维度数据。
HBASE:永久存储,支持在线查询 ,列族存储,可行可列 ,比如一个列族十个列就是列存,一个列族一个列,十个列族十个列这样就是列存 √
Redis:用户表数据量大,内存使用量大
HDFS(Hive):效率低
MYSQL:维表数据属于业务库,实时数据查询Mysql会给业务库增加压力–从库 √
ClickHouse:QPS高、列存 不合适
DWS:根据不同的维度组合聚合计算不同的度量值
ClickHouse:永久存储,列存,做聚合计算效率高,幂等性(保证数据一次性)
ADS:不需要落盘,接口中的sql语句查询结果供可视化展示
二、实时架构
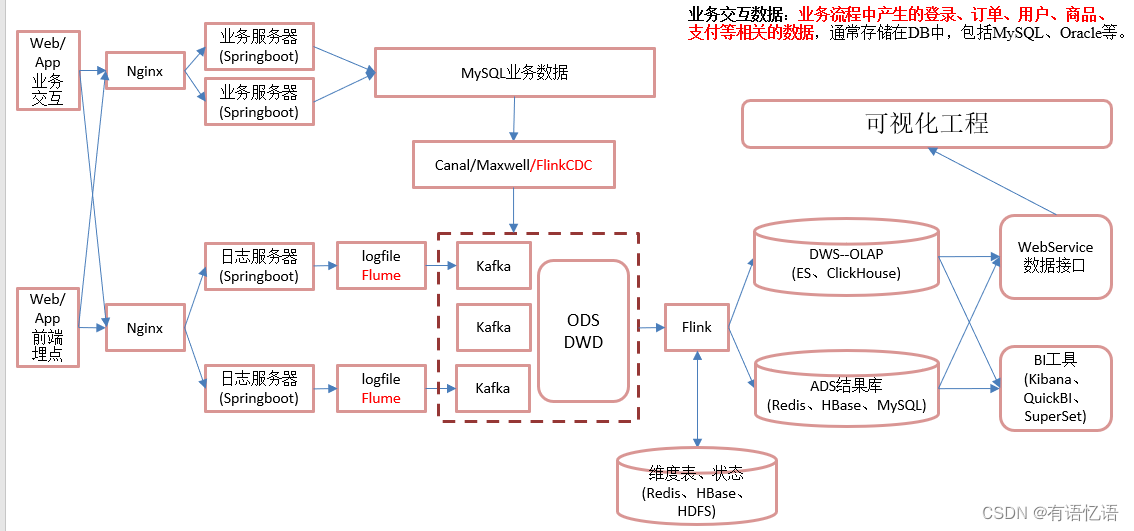
三、采集模块
TS拦截器(+时间戳+表名):解决零点漂移问题
hdfs路径:/hive_data/gmall/db/%{topic}inc/%Y%m_%d
四、数仓分层的好处
复用性
高性能、低成本
五、范式
第一范式:属性不可分割(5台电脑)
第二范式:不存在部分函数依赖
减少数据冗余
第三范式:不存在传递函数依赖
减少数据冗余、保证数据一致性
星座模型(多张事实表)
星型模型 单层维度 & 雪花模型 多层维度
六、事实表
事务性事实表:
例如:业务表
周期型快照事实表:
例如:库存表
累积型快照事实表:
有增、有改、无删除
七、业务域
八、指标体系建设
原子指标
派生指标
衍生指标
维度:观察数据的角度 用户、省份、商品
粒度:指的是特定的维度组合
各个省份中各个SPU的GMV
粒度越细,维度越多 最细粒度(所有的粒度)
九、数据
行为数据
业务数据
















 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











