







参加了场笔试,发现自己太菜太菜了,下边算是“女娲补天”吧
(都是个人理解,有点乱,不喜勿喷)
linux常用命令
ls :显示文件或目录
-l :列出详细信息
mkdir :创建目录
cd :切换目录
cd/ 转移到根目录中
cd~ 转移到/home/user用户目录下
cd/usr 转移到根目录下的usr目录中---绝对路径
cd test转移到当前目录下的test子目录中---相对路径
绝对路径:例如只要看到这个路径:c:/website/img/photo.jpg我们就知道photo.jpg文件是在c盘的website目录下的img子目录中。类似于这样完整的描述文件位置的路径就是绝对路径
相对路径:所谓相对路径,顾名思义就是自己相对与目标的位置。例如形式:img/photo.jpg
例:cd test(进入test目录)
echo :创建带有内容的文件
例:echo niubi > test.text (创建一个test文本,写入niubi)
cat :查看文件内容
例:cat test.text(查看test.text的内容)
cp :拷贝文件
mv:移动或重命名
rm:删除文件夹(删除目录需要加-r,-f强制删除)
cd…:返回上一层目录
find:在文件系统中搜索某文件
grep:在文本文件中查找某个字符串
pwd:显示当前目录
计算机网络相关
一、OSI7层模型(法定标准)
应用层
表示层
会话层 —上边三层属于资源子网用于数据处理
传输层
网络层 —下边三层属于通信子网用于数据通信
数据链路层
物理层

1、应用层
所有能和用户交互产生网络流量的程序,比如qq
2、表示层
用于处理在两个通信系统中交换信息的表示方式
功能1:数据格式变换(翻译官)
功能2:数据加密解密
功能3:数据压缩和恢复
3、会话层
向表示层实体/用户进程提供建立连接并在连接上有序的传输数据
功能1:建立、管理、终止会话
功能2:使用校验点可使会话在通信失效时从校验点/同步点继续恢复通信,实现数据同步(适用于传输大文件)
4、传输层
负责主机中两个进程的通信,即端到端的通信。传输单位是报文段或用户数据报。
功能1:可靠传输(收到确认才继续发)、不可靠传输
功能2:差错控制
功能3:流量控制
功能4:复用分用(复用:多个应用进程可同时使用下面运输层的服务(一起用)分用:运输层把收到的信息分别交付给上边应用层中相应的进程(各找各妈))
5、网络层
主要任务是把分组从源端传到目的端,为分组交换网上的不同主机提供通信服务。网络层传输单位是数据报。(数据报是分组的爹,即数据报可分成好几个分组)
功能1:路由选择
功能2:流量控制
功能3:差错控制
功能4:拥塞控制(全局拥堵)
6、数据链路层
主要任务是把网络层传下来的数据报组装成帧。传输单位是帧。
功能1:成帧
功能2:差错控制
功能3:流量控制
功能4:访问(接入)控制,控制对信道的访问
7、物理层
主要任务是在物理媒体上实现比特流的透明传输。物理层传输单位是比特。
功能1:定义接口特性
功能2:定义传输模式
功能3:定义传输速率
功能4:比特同步
功能5:比特编码
二、4层tcp/ip参考模型(事实标准)
应用层
传输层
网际层
网络接口层

三、五层体系结构


四、三次握手
自己的理解描述:
第一次:客户端发送连接请求到服务端
第二次:服务端收到连接请求后,发送确认信息到客户端(但此时服务端只知道客户端发送能力正常,并不知道客户端接收信息是否正常。如果此请求是由于网络故障滞留的早之前的请求,可能此时客户端已关闭,不能接收)
第三次:客户端发送确认信息到服务端,表明接收信息正常,正式建立连接。
五、四次挥手
自己理解描述:
第一次:客户端发送断开连接请求到服务端。
第二次:服务端发送确认收到请求信息到客户端。(此时可能服务端往客户端发送的信息还没有全部发送完,所以第二次和第三次不能一起)
第三次:服务端发送可以断开信息到客户端。
第四次:客户端发送确认断开信息到服务端,服务端断开连接。(在客户端发送之后需要等待超时时间原因:因为如果第四次发送的包信息丢失,服务端会一直处于等待断开状态,有等待超时时间服务端会重发第三次的包信息,此时客户端就会再次发送信息到服务端)
漏洞相关
一、漏洞扫描工具nmap
1、nmap是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。确定哪些服务运行在哪些连接端,并且推断计算机运行哪个操作系统(这是亦称 fingerprinting)。利用nmap来搜集目标电脑的网络设定,从而计划攻击的方法。Nmap 以隐秘的手法,避开闯入检测系统的监视,并尽可能不影响目标系统的日常操作。
2、基本功能:
(1)探测一组主机是否在线;
(2)扫描 主机端口,嗅探所提供的网络服务;
(3)推断主机所用的操作系统 。
3、操作:
进行ping扫描,打印出对扫描做出响应的主机,不做进一步测试(如端口扫描或者操作系统探测):
nmap -sP 192.168.1.0/24
仅列出指定网络上的每台主机,不发送任何报文到目标主机:
nmap -sL 192.168.1.0/24
探测目标主机开放的端口,可以指定一个以逗号分隔的端口列表(如-PS22,23,25,80):
nmap -PS 192.168.1.234
使用UDP ping探测主机:
nmap -PU 192.168.1.0/24
使用频率最高的扫描选项:SYN扫描,又称为半开放扫描,它不打开一个完全的TCP连接,执行得很快:
SYN扫描是恶意黑客不建立完全连接,用来判断通信端口状态的一种手段。
这种方法是最老的一种攻击手段,有时用来进行拒绝服务攻击。
SYN扫描也称半开放扫描。在SYN扫描中,恶意客户企图跟服务器在每个可能的端口建立TCP/IP连接。
这通过向服务器每个端口发送一个SYN数据包,装作发起一个三方握手来实现。
如果服务器从特定端口返回SYN/ACK(同步应答)数据包,则意味着端口是开放的。
然后,恶意客户程序发送一个RST数据包。
结果,服务器以为存在一个通信错误,以为客户端决定不建立连接。
开放的端口因而保持开放,易于受到攻击。
如果服务器从特定端口返回一个RST数据包,这表示端口是关闭的,不能攻击。
通过向服务器连续发送大量的SYN数据包,黑客能够消耗服务器的资源。
由于服务器被恶意客户的请求所淹没,不能或者只能跟很少合法客户建立通信。
nmap -sS 192.168.1.0/24
当SYN扫描不能用时,TCP Connect()扫描就是默认的TCP扫描:
nmap -sT 192.168.1.0/24
UDP扫描用-sU选项,UDP扫描发送空的(没有数据)UDP报头到每个目标端口:
nmap -sU 192.168.1.0/24
确定目标机支持哪些IP协议 (TCP,ICMP,IGMP等):
nmap -sO 192.168.1.19
探测目标主机的操作系统:
nmap -O 192.168.1.19
nmap -A 192.168.1.19
-p (只扫描指定的端口)
单个端口和用连字符表示的端口范 围(如 1-1023)都可以。当既扫描TCP端口又扫描UDP端口时,可以通过在端口号前加上T: 或者U:指定协议。 协议限定符一直有效直到指定另一个。 例如,参数 -p U:53,111,137,T:21-25,80,139,8080 将扫描UDP 端口53,111,和137,同时扫描列出的TCP端口。
-F (快速 (有限的端口) 扫描)
xss漏洞
1、跨站脚本攻击(XSS),是最普遍的Web应用安全漏洞。这类漏洞能够使得攻击者嵌入恶意脚本代码到正常用户会访问到的页面中,当正常用户访问该页面时,则可导致嵌入的恶意脚本代码的执行,从而达到恶意攻击用户的目的。
2、分类
(1)反射型XSS:<非持久化> 攻击者事先制作好攻击链接, 需要欺骗用户自己去点击链接才能触发XSS代码(服务器中没有这样的页面和内容)
(2)存储型XSS:<持久化> 代码是存储在服务器中的,如在个人信息或发表文章等地方,加入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,每当有用户访问该页面的时候都会触发代码执行
(3)DOM based XSS与前两者完全不同,是纯前端的XSS漏洞,XSS直接通过浏览器进行解析,就完成攻击。
注意:反射型和存储型都是通过后台输出
3、例
反射型的XSS
(1)low等级
当你在用户框输入时会回显

现在输入 <script>alert(1)</script>看看

这说明存在XSS漏洞,如何分别时反射型还是存储型漏洞,只要刷新这个页面,观察是否会弹窗就知道了,如果能会弹窗证明是存储型,反之是反射型
(2)medium等级
当你输入<script>alert(1)</script>,会发现出现下图,这有可能是<script>标签被过滤了,看以下源代码验证一下
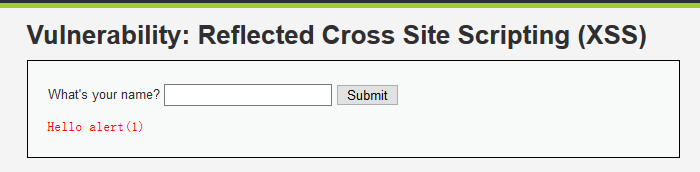
源代码:

发现<script>真的被过滤了,这时候就需要技巧去绕过限制。
几种绕过技巧
a.标签的嵌套
在<script>标签中再嵌套一个<script>
<script<script>>alert(1)</script>
b.大小写混合
服务器有可能只过滤了小写的script,那就可以通过大小写混合来绕过
(3)high等级
以下是high等级输入<script>alert(1)</script>的页面源码,发现<script>被完全过滤

能加载js脚本的标签不只有<script>,还有<img>,<iframe>
<img src=# onerror=alert(1)>
<iframe onload=alert(1)>
csrf漏洞
1、跨站请求伪造(英语:Cross-site request forgery),也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF, 是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。跟跨网站脚本(XSS)相比,XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。
简单说:攻击者盗用了你的身份,以你的名义发送恶意请求
2、CSRF攻击攻击原理及过程如下:
1. 用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
2.在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
3. 用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
4. 网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
5. 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
可以看出,要完成一次CSRF攻击,受害者必须依次完成两个步骤:
1.登录受信任网站A,并在本地生成Cookie。
2.在不登出A的情况下,访问危险网站B。
3、例
受害者 Bob 在银行有一笔存款,通过对银行的网站发送请求 http://bank.example/withdraw?account=bob&amount=1000000&for=bob2 可以使 Bob 把 1000000 的存款转到 bob2 的账号下。通常情况下,该请求发送到网站后,服务器会先验证该请求是否来自一个合法的 session,并且该 session 的用户 Bob 已经成功登陆。黑客 Mallory 自己在该银行也有账户,他知道上文中的 URL 可以把钱进行转帐操作。Mallory 可以自己发送一个请求给银行:http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory。但是这个请求来自 Mallory 而非 Bob,他不能通过安全认证,因此该请求不会起作用 这时,Mallory 想到使用 CSRF 的攻击方式,他先自己做一个网站,在网站中放入如下代码src=http://bank.example/withdrawaccount=bob&amount=1000000&for=Mallory ”,并且通过广告等诱使 Bob 来访问他的网站。当 Bob 访问该网站时,上述 url 就会从 Bob 的浏览器发向银行,而这个请求会附带 Bob 浏览器中的 cookie 一起发向银行服务器。大多数情况下,该请求会失败,因为他要求 Bob 的认证信息。但是,如果 Bob 当时恰巧刚访问他的银行后不久,他的浏览器与银行网站之间的 session 尚未过期,浏览器的 cookie 之中含有 Bob 的认证信息。这时,悲剧发生了,这个 url 请求就会得到响应,钱将从 Bob 的账号转移到 Mallory 的账号,而 Bob 当时毫不知情。等以后 Bob 发现账户钱少了,即使他去银行查询日志,他也只能发现确实有一个来自于他本人的合法请求转移了资金,没有任何被攻击的痕迹。
SSRF
1、SSRF(服务端请求伪造)是服务器对用户提供的可控URL过于信任,没有对攻击者提供的RUL进行地址限制和足够的检测,导致攻击者可以以此为跳板攻击内网或其他服务器。
2、CSRF是服务器端没有对用户提交的数据进行严格的把控,导致攻击者可以利用用户的Cookie信息伪造用户请求发送至服务器。而SSRF是服务器对用户提供的可控URL地址过于信任,没有经过严格检测,导致攻击者可以以此为跳板攻击内网或其他服务器。
3、CSRF是跨站请求伪造攻击,由客户端发起 SSRF是服务器端请求伪造,由服务器发起
汇编语言相关
寄存器
是CPU的组成部分,因为在CPU内,所以CPU对其读写速度是最快的,不需要IO传输,但同时也决定了此类寄存器数量非常有限,有限到几乎每个存储都有自己的名字,而且有些还有多个名字。
二、分类
16位 :ax,bx,cx,dx,bp,si,di,sp
32位 :eax,ebx,ecx,edx,ebp,esi,edi,esp
64位 :rax,rbx,rcx,rdx,rbp,rsi,rdi,rsp,r8-r15
三、通用寄存器
一组是数据寄存器,另一组是指针寄存器及变址寄存器
数据寄存器:
ax(ah&al):累加寄存器,常用于计算,在乘除等指令中指定用来存放操作数。
bx(bh&bl):基址寄存器,常用于地址索引
cx(ch&cl) :计数寄存器,常用于计数、保存计算值。
dx(dh&dl):数据寄存器,常用于数据传递
特点:这4个16位的寄存器可以分为高8位(ah,bh,ch,dh)以及低八位(al,bl,cl,dl)
指针和变址寄存器:
sp:堆栈指针,与ss配合使用,可指向目前的堆栈位置
bp:基址指针寄存器
si:源变址寄存器
di:目的变址寄存器
这四个只能按16位进行存取操作。
64位不同寄存器作用:
rax:累加器,是算术运算的主要寄存器,存储返回值
rbx:基址寄存器,被调用者保存,存放存储区的起始地址
rcx:计数寄存器,循环操作和字串处理的计数控制
rdx:i/o指针,i/o操作时提供外部设备接口的端口地址
rsi:源变址寄存器,与rds段寄存器联用,可以访问数据段中的任一个存储单元
rdi:目的变址寄存器,与res段寄存器联用,可以访问附加段中的任一个存储单元
rbp:基址指针寄存器,用于提供堆栈内某个单元的偏移地址,与rss段寄存器联用,可以访问堆栈中的任一个存储单元,被调用者保存
rsp:栈顶指针寄存器,提供堆栈栈顶单元的偏移地址,与rss段寄存器联用,以控制数据进栈和出栈
补充:
rax 作为函数返回值使用
rsp 栈指针寄存器,指向栈顶
rdi,rsi,rdx,rcx,r8,r9 用作函数参数,依次对应第1参数,第2参数…
rbx,rbp,r12,r13,14,15 用作数据存储,遵循被调用者使用规则,简单说就是随便用,调用子函数之前要备份它,以防他被修改
r10,r11 用作数据存储,遵循调用者使用规则,简单说就是使用之前要先保存原值
汇编中需要知道的:
ebp
标识栈底
esp
标识当前的栈指针
eip
指令寄存器:存储当前执行的指令地址
eax
一般的,默认用于存储函数返回值
进入函数时,一般首先pushl %ebp; movl %esp, %ebp来进行栈信息的保存,包括
1)将上次的栈底信息压入栈;
2)将栈底、栈指针重置为下一个栈地址。调用函数时,将 eip 的当前信息压入栈中,并更新 eip 使指向新的指令。函数返回的过程,即是从栈中读取 eip、ebp 的旧有信息并恢复上一个函数栈的过程
常用汇编指令
mov
pop 弹栈
add/sub 加减
push 压栈
lea 取地址
call 调用函数
栈帧

从下到上,大地址到小地址
栈帧就是一个函数的执行环境
函数参数、函数的局部变脸、函数执行完后返回到哪里等等
每一个栈帧代表的就是一个未运行完的函数
布尔盲注
原理:代码存在sql注入漏洞然而页面不会回显数据,也不会回显错误信息,只返回right与wrong。可以通过构造语句,来判断数据库信息的正确性,再通过页面的真和假来判断是否正确。
方法:
length():函数可返回字符串的长度
例

substring()函数可以截取字符串,可指定开始的位置和截取的长度

ord()函数可以返回单个字符的ASCII码

left(a,b)从左侧截取a的前b位
left(database(),1)>'s'
mid(,a,b,c)从位置b开始,截取a字符串的c位
ord(mid(select user()1,1))=114
union注入
1、为使 UNION 查询正常工作,必须满足两个关键要求:
各个查询必须返回相同数量的列
每列的数据类型在各个查询之间必须兼容
2、显错点概念:
比如当前表中共有三个字段,一个是标题(title)、一个是时间(time)、一个是内容(data),而我们前端不需要显示时间,只需要展示标题和内容即可。那么从数据库获得的数据中,也只有标题字段和内容字段会展示在页面上,这两个点就是显错点。
3、使用UNION联合查询时要满足一个条件,那就是我们构造的SELECT语句的字段数要和当前表的字段数相同才能联合查询,即首先我们要确定当前表的字段数。order by x是数据库中的一个排序语句,order by 1即通过第一个字段进行排序。这时我们就可以构造SELECT * FROM news WHERE id=‘1’ order by x-- a’来猜测当前表的字段数,x值递增,当页面返回数据异常时,即无当前字段时,用当前的x值减一即可得到当前表的字段数了。
知道了当前表的字段数,就可以进行UNION联合查询了。但联合查询时,页面只会显示查询到数据的第一条,也就是UNION前的SELECT语句的结果,想要显示我们自己联合查询的结果时,还必须使前一条语句失效,可以构造and 1=2使前一句SELECT语句失效。
堆叠注入
1、堆叠注入,顾名思义,就是将语句堆叠在一起进行查询
原理很简单,mysql_multi_query() 支持多条sql语句同时执行,就是以;分隔,成堆的执行sql语句,例如 select * from users;show databases;
2、原理
在SQL中,分号(;)是用来表示一条sql语句的结束。试想一下我们在 ; 结束一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:1; DELETE FROM products服务器端生成的sql语句为: Select * from products where productid=1;DELETE FROM products当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。
3、局限性
实际遇到很少,其可能受到API或者数据库引擎,又或者权限的限制只有当调用数据库函数支持执行多条sql语句时才能够使用,利用mysqli_multi_query()函数就支持多条sql语句同时执行,但实际情况中,如PHP为了防止sql注入机制,往往使用调用数据库的函数是mysqli_ query()函数,其只能执行一条语句,分号后面的内容将不会被执行,所以可以说堆叠注入的使用条件十分有限,一旦能够被使用,将可能对网站造成十分大的威胁。
报错注入
1、报错注入就是利用了数据库的某些机制,人为地制造错误条件,使得查询结果能够出现在错误信息中。这种手段在联合查询受限且能返回错误信息的情况下比较好用,毕竟用盲注的话既耗时又容易被封。
2、分类
(1)BIGINT等数据类型溢出
(2)concat+rand()+group_by()导致主键重复
这种报错方法的本质是因为**floor(rand(0)*2)**的重复性,其会生成0和1两个数导致group by语句出错。group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中更新临时表的数据;如果key不在临时表中,则在临时表中插入key所在行的数据。
例
先建立空表
取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),查询虚表,发现没有该键值,则会再计算一次floor(rand(0)*2),将结果1(第二次计算)插入虚表
查第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算),查询虚表,发现键值1存在,所以此时不在计算第二次,直接count(*)值加1
查第三条记录,再次计算floor(rand(0)*2),发现结果为0(第四次计算),发现键值没有0,则尝试插入记录,此时会又一次计算floor(rand(0)*2),结果1(第5次计算)当作虚表的主键,而此时1这个主键已经存在于虚表中了,所以在插入的时候就会报主键重复的错误了。
(3)xpath语法错误
extractvalue函数
函数原型:extractvalue(xml_document,Xpath_string)
正常语法:extractvalue(xml_document,Xpath_string);
第一个参数:xml_document是string格式,为xml文档对象的名称
第二个参数:Xpath_string是xpath格式的字符串
作用:从目标xml中返回包含所查询值的字符串
第二个参数是要求符合xpath语法的字符串,如果不满足要求,则会报错,并且将查询结果放在报错信息里,因此可以利用。
updatexml函数
原型:updatexml(xml_document,xpath_string,new_value)
正常语法:updatexml(xml_document,xpath_string,new_value)
第一个参数:xml_document是string格式,为xml文档对象的名称 第二个参数:xpath_string是xpath格式的字符串
第三个参数:new_value是string格式,替换查找到的负荷条件的数据 作用:改变文档中符合条件的节点的值
第二个参数跟extractvalue函数的第二个参数一样,因此也可以利用,且利用方式相同
Google Hacking
1、轻量级的搜索可以搜素出一些遗留后门,不想被发现的后台入口,中量级的搜索出一些用户信息泄露,源代码泄露,未授权访问等等,重量级的则可能是mdb文件下载,CMS 未被锁定install页面,网站配置密码,php远程文件包含漏洞等重要信息。
2、基本搜索
逻辑与:and
逻辑或: or
逻辑非: -
完整匹配:“关键词”
通配符:* ?
3、高级搜索
intext:寻找正文中含有关键字的网页,例如,intext:登录后台 ,将只返回正文中包含登陆后台的页面

intitle:寻找标题中含有关键字的网页,例如:intitle:登录后台 将返回标题中包含有登陆后台的网页

allintitle:使用方法和intitle类似,但可以选择好几个个词,例如: alltitle:登录后台 管理员

inurl:将返回url中有关键字的网页,例如:inurl:admin 将返回url中含有admin的网页

搜索管理员登录页面 inurl:/admin/adminlogin.php

搜索后台数据库管理页面 inurl:/phpmyadmin/index.php

allinurl :使用方法和inurl类似,但是可以选择多个词,例如:inurl:login admin,将返回url中含有 login 和 admin 的网页

site:指定访问的站点,例如: site:baidu.com inurl:admin 将只在baidu.com 中查找url中含有admin的网页

filetype :指定访问的文件类型,例如:site:qq.com filetype:pdf, 将只返回qq.com站点上文件类型为pdf的网页

link:指定链接的网页,例:link:www.qq.com 将返回所有包含指向 www.qq.com 的网页

related:相似类型的网页,例:related:www.nuc.edu.cn 将返回与 www.nuc.edu.cn 相似的页面,相似指的是网页的布局相似

其他
cache
网页快照,谷歌将返回给你他存储下来的历史页面,如果你同时制定了其他查询词,将在搜索结果里以高亮显示,例如:cache:www.hackingspirits.com guest ,将返回指定网站的缓存,并且正文中含有guest
info
返回站点的指定信息,例如:info:www.baidu.com 将返回百度的一些信息
define
返回某个词语的定义,例如:define:Hacker 将返回关于Hacker的定义
phonebook
电话簿查询美国街道地址和电话号码信息。例如:phonebook:Lisa+CA 将返回名字里面包含Lisa并住在加州的人的所有名字
查找网站后台
site:xx.com intext:管理
site:xx.com inurl:login
site:xx.com intitle:后台
查看服务器使用的程序
site:xx.com filetype:asp
site:xx.com filetype:php
site:xx.com filetype:jsp
site:xx.com filetype:aspx
查看上传漏洞
site:xx.com inurl:file
site:xx.com inurl:load
可能存在SQL注入的网页 inurl:?id=1
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









