







任务描述
需要收集目前国产电视剧的相关数据,预判一个电视剧的评分走向。
任务说明
收集数据,至少包含评分、电视剧名称、主演信息等三个信息。之后将数据存储到一个csv表中。表头如下:title、rating、stars,命名为tv_rating.csv。
初步分析
对比豆瓣和中国电视剧网可以看出,电视剧网有页数显示,页面的URL的page参数会发生变化。这样只需要抓取一个页面,然后用一个循环来不断执行该方法。
数据获取
网页下载有两种方法,一种用urllib3直接下载,另一种对于动态网页,需要使用selenium模拟浏览器技术下载。
所以下载网页第一步就是判断需要用那种方式。
单个页面下载
首先通过第一张方法下载网页,得到需要的数据,说明不是动态网页,可以用第一种方法获取。
#导入urllib3模块的所有类和对象
import urllib3
#第一个函数可以用来下载网页,返回网页内容
#参数url代表所要下载的网页地址
def download_content(url):
http = urllib3.PoolManager()
response = http.request("GET", url)
response_data = response.data
html_content = response_data.decode()
return html_content
#第二个函数,将字符串内容保存到文件中
#第一个参数为所要保存的文件名,第二个参数为要保存的字符串内容的变量
def save_to_file(filename, content):
fo = open(filename, "w", encoding= "utf-8")
fo.write(content)
fo.close()
# 将我们找到的电视剧网的网址存储在变量 url 中
url="http://dianshiju.tv/search.php?page=1&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD"
# 将url 对应的网页下载下来,并把内容存储在 html_content 变量中
html_conten=download_content(url)
# 将 html_content 变量中的内容存储在 htmls 文件夹中,文件名为 tv1.html 代表第一页
save_to_file("htmls/tv1.html",html_conten)
多个页面下载
可以用time模块的sleep方法来使程序暂停固定的时间。
import time
for i in range(2, 100):
a_url = url.replace("page=1", "page=" + str(i))
print("begin download:", a_url)
html_content = download_content(a_url)
file_name = "htmls/tv" + str(i) + ".html"
save_to_file(file_name, html_content)
#暂停1秒
time.sleep(1)
 到此所有数据都下载到本地了,接下来要做的就是编写代码提取出信息。
到此所有数据都下载到本地了,接下来要做的就是编写代码提取出信息。
初步分析
要使用BeautifulSoup来提取数据,首先应该分析想要的内容周围的标签结构,然后根据标签的层级关系来设计如何获取信息。
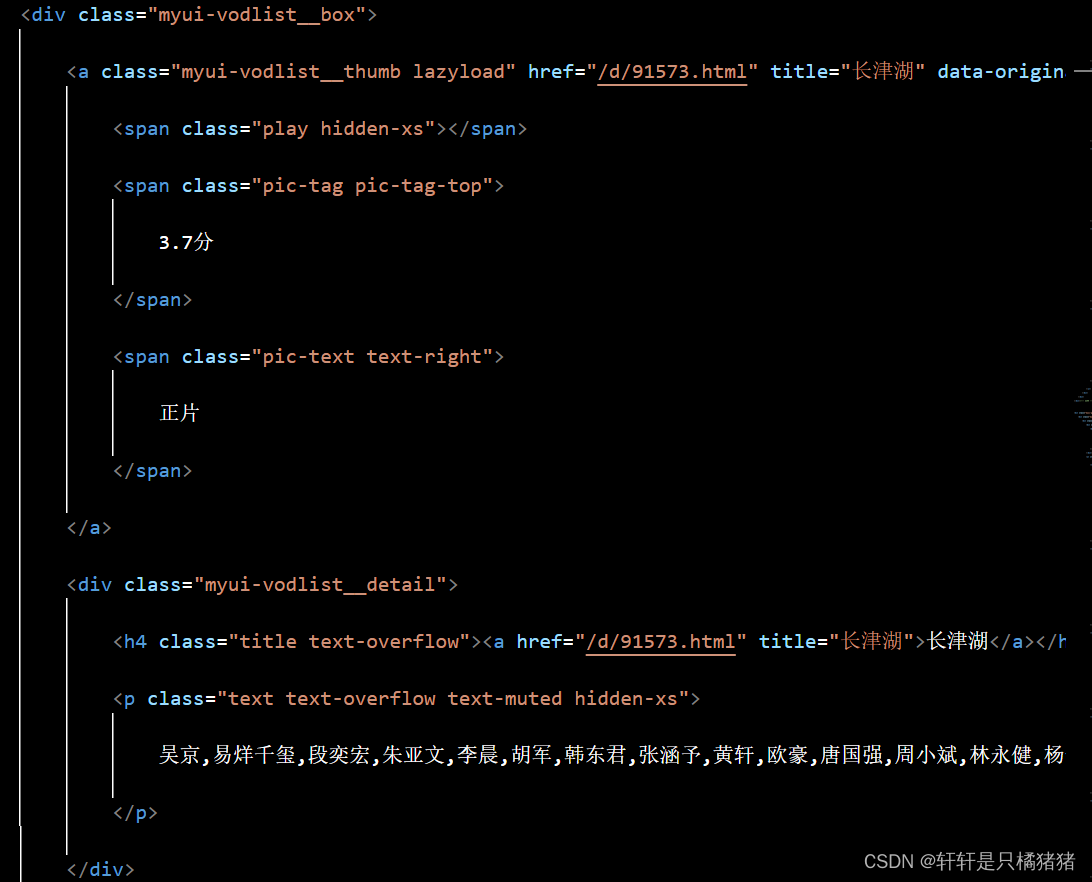 可以看到在一个class为myui-vodlist_box的div标签内部,基本包含了我们所需要的信息。
可以看到在一个class为myui-vodlist_box的div标签内部,基本包含了我们所需要的信息。
所以获取数据的思路为:
- 获取所有class=myui-vodlist_box的div标签对象
- 针对每一个标签对象,尝试:查找h4标签,获取电视剧名称;查找class=“pic-tag pic-tag-top”的span标签,获取评分;查找p标签,并获得演员信息。
提取单个html界面信息
from bs4 import BeautifulSoup
def create_doc_from_filename(filename):
fo = open(filename, "r", encoding='utf-8')
html_content = fo.read()
fo.close()
doc = BeautifulSoup(html_content)
return doc
doc = create_doc_from_filename("htmls/tv2.html")
box_list = doc.find_all("div", class_ = "myui-vodlist_box")
for box in box_list:
title_label = box.find_all("h4")[0]
rating_label = box.find_all("span", class_ = "pic-tag pic-tag-top")[0]
stars_label = box.find_all("p")[0]
#使用strip去除前后空格
title = title_label.text.strip()
rating = rating_label.text.strip()
stars = stars_label.text.strip()
print(title, rating, stars)
提取多个页面信息并保存到csv文件中
# 从参数指定的 html 文件中获取电视剧的相关信息
def get_tv_from_html(html_file_name):
doc = create_doc_from_filename(html_file_name)
box_list = doc.find_all("div", class_="myui-vodlist__box")
for box in box_list:
title_label = box.find_all("h4")[0]
rating_label = box.find_all("span", class_="pic-tag pic-tag-top")[0]
stars_label = box.find_all("p")[0]
title = title_label.text.strip()
rating = rating_label.text.strip()
stars = stars_label.text.strip()
print(title, rating, stars)
# 试试用新写的函数处理一 tv2.html
get_tv_from_html("htmls/tv2.html")

# 导入 csv 模块
import csv
# 输入有三个参数:要保存的字典列表,csv 文件名,和表头
def write_dict_list_to_csv(dict_list, filename, headers):
# 当要处理的网页比较复杂时,增加 encoding 参数可以兼容部分特殊符号
fo = open(filename, "w", newline='', encoding='utf_8_sig')
writer = csv.DictWriter(fo, headers)
writer.writeheader()
writer.writerows(dict_list)
fo.close()
all_tv_dict = []
# 从参数指定的 html 文件中获取电视剧的相关信息
def get_tv_from_html(html_file_name):
doc = create_doc_from_filename(html_file_name)
box_list = doc.find_all("div", class_="myui-vodlist__box")
# 【新增】当前处理的文件的字典列表
tv_list = []
for box in box_list:
title_label = box.find_all("h4")[0]
rating_label = box.find_all("span", class_="pic-tag pic-tag-top")[0]
stars_label = box.find_all("p")[0]
title = title_label.text.strip()
rating = rating_label.text.strip()
stars = stars_label.text.strip()
# 【新增】使用字典来保存,字典的 key 和 csv 的表头保持一致
# # 【新增】在任务说明环节,表头为: title, rating, stars
tv_dict = {}
tv_dict["title"] = title
tv_dict["rating"] = rating
tv_dict["stars"] = stars
# 【新增】将电视剧的字典添加到当前文件的字典列表中
tv_list.append(tv_dict)
# 【新增】返回字典列表
return tv_list
# 【新增】用最新修改的 get_tv_from_html 处理 tv2.html,并将返回的结果存储在 tv_list 变量中
tv_list = get_tv_from_html("htmls/tv2.html")
# 【新增】打印获取到的列表
print(tv_list)
# 因为是处理 tv1- tv100 的文件,所以i 循环从1到101
for i in range(1, 100):
# 拼出每一次要处理的文件名
file_name = "htmls/tv" + str(i) + ".html"
# 调用 get_tv_from_html 处理当次循环的文件
# 将这个文件中的电视剧列表存储在 dict_list 变量
dict_list = get_tv_from_html(file_name)
# 将 dict_list 的内容添加到总列表 all_tv_dict 中
# 列表的拼接可以直接使用 + 号
all_tv_dict = all_tv_dict + dict_list
# 打印出总列表的长度,看看我们一共抓取到了几部电视剧
print(len(all_tv_dict))
# 调用之前准备的 write_dict_list_to_csv 函数
# 第一个参数为要保存的列表,这里就是我们存储了所有电视剧耳朵总列表 all_tv_dict
# 第二个参数为要保存的文件名
# 第三个参数为要保存的 csv 文件的表头
write_dict_list_to_csv(all_tv_dict, "tv_rating.csv", ["title", "rating", "stars"])

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









