






 本文概述了《算法导论》中算法在计算中的核心作用,介绍了插入排序、分析算法(如时间复杂度和分治法)、递归式求解、概率分析和随机算法等内容,详细解析了分治策略如归并排序和Strassen算法,并展示了如何使用主方法求解递归式。
本文概述了《算法导论》中算法在计算中的核心作用,介绍了插入排序、分析算法(如时间复杂度和分治法)、递归式求解、概率分析和随机算法等内容,详细解析了分治策略如归并排序和Strassen算法,并展示了如何使用主方法求解递归式。
文章目录
前言
《算法导论》第一部分内容
一、算法在计算中的作用
1.1 算法
定义:算法就是任何良定义的计算过程,该过程取某个值或值的集合作为输入并产生某个值或值的集合作为输出。
数据结构:一种存储和组织数据的方式,旨在便于访问和修改。
1.2 算法作用
因为计算机资源是有限的,算法能帮助我们有效的使用计算机资源,更省时间或空间。
效率:不同的算法在效率方便有显著差距。
例如:插入排序算法所花的时间大致与排序项n的平方成正比,而归并排序所花时间与nlgn成正比,当输入规模足够大时,归并排序效率远远高于插入排序。
二、算法基础
2.1 插入排序
输入:n个数的一个序列<a1,a2,…,an>。
输出:输入排列的一个排列<a1’,a2’,…,an’>,满足a1’<=a2’<=…<=an’。
也叫直接插入排序:基本操作是将一个记录插入到已经排序好序的有序表中,从而得到一个新的、记录数增1的有序表。
伪代码如下:
INSERTION-SORT(A):
for j=2 to A.length
key = A[j]
//Insert A[j] into the sorted sequence A[1..j-1].
i=j-1
while i>0 and A[i]>key
A[i+1]=A[i]
i = i - 1
A[i+1] = key
C语言实现如下:
#define MAXSIZE 10000 /*用于要排序数组个数的最大值,可根据需要修改*/
typedef struct
{
int r[MAXSIZE+1]; /*用于存储要排序数组,r[0]用作哨兵或临时变量*/
int length; /*用于记录顺序表的长度*/
}SqList;
void InsertSort(SqList *L) /*对顺序表L作直接插入排序*/
{
int i,j;
for(i=2;i<=L->length;i++)
{
if(L->r[i]<L->r[i-1]) /*需将L->r[i]插入有序子表*/
{
L->r[0]=L->r[i] /*设置临时变量,后续给插入点赋值*/
for(j=i-1;L->r[j]>L->r[0];j--)
L->r[j+1]=L->r[j]; /*记录后移*/
L->r[j+1]=L->r[0]; /*插入到正确位置*/
}
}
}
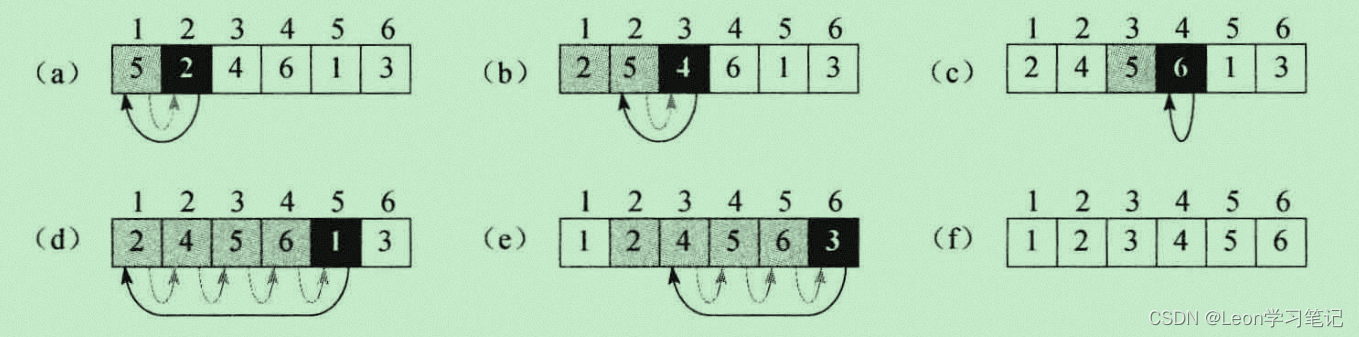
下图是输入序列为<5,2,4,6,1,3>时,直接插入排序算法的工作示意图。
循环不变式:让每次循环都成立的逻辑表达式,用于证明整个算法的正确性。
循环不变式主要用来帮助我们理解算法的正确性。关于循环不变式,我们必须证明三条性质:
初始化:循环的第一次迭代之前,它为真。
保持:如果循环的某次迭代之前它为真,那么下次迭代之前它仍为真。
终止:在循环终止时,不变式为我们提供一个有用的性质,该性质有助于证明算法的正确性。
2.2 分析算法
分析算法的时间复杂度,算法运行时间与输入规模的关系。
2.3 设计算法
2.3.1 分治法
许多有用的算法在结构上是递归的:为了解决一个给定的问题,算法一次或多次递归地调用其自身以解决紧密相关的若干子问题。这些算法典型地遵循分治法的思想:将原问题分解为几个规模较小但类似于原问题的子问题,递归地求解这些子问题,然后再合并这些子问题的解来建立原问题的解。
分治模式在每层递归时都有三个步骤:
1.分解原问题为若干子问题,这些子问题是原问题的规模较小的实例。
2.解决这些子问题,递归地求解各子问题。然而,若子问题的规模足够小,则直接求解。
3.合并这些子问题的解成原问题的解。
归并排序算法完全遵循分治模式。直观上其操作如下:
分解:分解待排序的n个元素的序列成各具有n/2个元素的两个子序列。
解决:使用归并排序递归地排序两个子序列。
合并:合并两个已排序的子序列以产生已排序的答案。
归并排序的关键操作是“合并”步骤中两个已排序序列的合并。我们通过调用一个辅助过程MERGE(A,p,q,r)来完成合并,其中A是一个数组,p、q、r是数组下标,满足p<=q<r。该过程假设子数组A[p…q]和A[q+1…r]都已排好序。它合并这两个子数组形成单一的已排好序的子数组并代替当前的子数组A[p…r]。
MERGE的伪代码如下:
MERGE(A,p,q,r)
n1=q-p+1
n2=r-q
let L[1..n1+1] and R[1..n2+1] be new arrays
for i=1 to n1
L[i]=A[p+i-1]
for j=1 to n2
R[j]=A[q+j]
L[n1+1]=∞
R[n2+1]=∞
i=1
j=1
for k=p to r
if L[i]<=R[j]
A[k]=L[i]
i=i+1
else A[k]=R[j]
j=j+1

归并排序的伪代码如下
MERGE-SORT(A,p,r)
if p<r
q=⌊(p+r)/2⌋
MERGE-SORT(A,p,q)
MERGE-SORT(A,q+1,r)
MERGE(A,p,q,r)
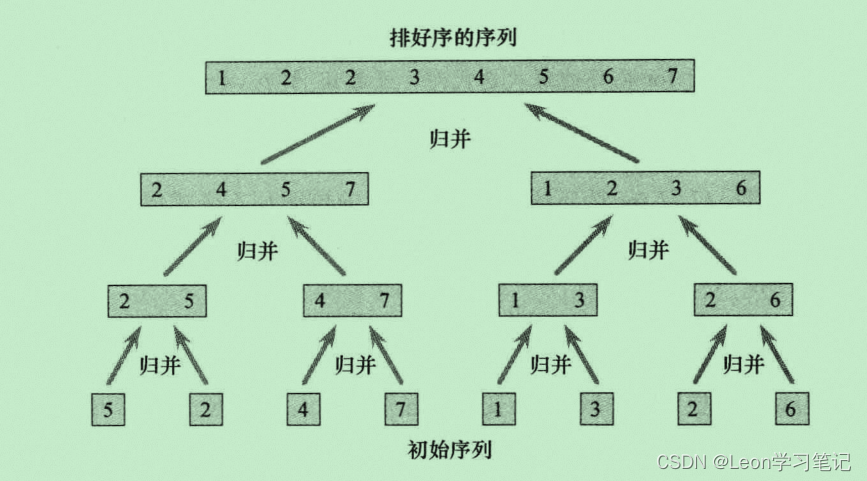
运行时间为Θ(nlgn)。
三、函数的增长
3.1 渐进记号
插入排序的运行时间刻画为函数 an2+bn+c,通常我们写成Θ(n2),除去了该函数的部分细节。
Ο,读音:big-oh;表示上界,小于等于。
Ω,读音:big omega、欧米伽;表示下界,大于等于。
Θ,读音:theta、西塔;既是上界也是下界,称为确界,等于。
ο,读音:small-oh;表示上界,小于。
ω,读音:small omega;表示下界,大于。
Ο是渐进上界,Ω是渐进下界。Θ需同时满足大Ο和Ω,故称为确界。Ο极其有用,因为它表示了最差性能。
3.2 标准记号与常用函数
单调性:单增、单减、严格增、严格减
向上取整与向下取整:⌈⌉、⌊⌋
模运算:对任意整数a和任意正整数n,a mod n 的值就是商a/n的余数。
多项式、指数、对数、阶乘、多重函数、多重对数函数、斐波那契数。
四、分治策略
关键三步骤:分解、解决、合并。
递归式与分治方法是紧密相关的,因为使用递归式可以很自然地刻画分治算法的运行时间。
本章介绍三种求解递归式的方法,即得出算法的“Θ”或“O”渐进界的方法:
1.代入法: 我们猜测一个界,然后用数学归纳法证明这个界是正确的。
2.递归树法:将递归式转换为一棵树,其结点表示不同层次的递归调用产生的代价。然后采用边界和技术来求解递归式。
3.主方法:可求解形如下面公式的递归式的界:
T(n) = aT(n/b)+f(n)
其中a>=1, b>1, f(n)是一个给定的函数。这种形式的递归式很常见,它刻画了这样一个分治算法:生成a个子问题,每个子问题的规模是原问题规模的1/b,分解和合并总花费时间为f(n).
4.1 最大子数组问题
最大子数组:最大的非空连续子数组。

使用分治策略求解最大子数组

如图a,最大子数组必然位于以下三种情况:
1.完全位于中点左侧
2.完全位于中点右侧
3.跨越中点
如图b,任何跨越中点的子数组都由两个子数组A[i…mid]和A[mid+1…j]组成。
过程 FIND-MAX-CROSSING-SUBARRAY 接收数组A和下标low、mid、high为输入,返回一个下标元组划定跨越中点的最大子数组的边界,并返回最大子数组中,值的和。
FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)
left-sum = -∞
sum=0
for i=mid downto low
sum = sum+A[i]
if sum > left-sum
left-sum = sum
max-left=i
right-sum = -∞
sum = 0
for j=mid+1 to high
sum=sum+A[j]
if sum>right-sum
right-sum=sum
max-right=j
return (max-left,max-right,left-sum + right-sum)
调用FIND-MAX-CROSSING-SUBARRAY函数花费Θ(n)时间。
以下是求解最大子数组问题的分治算法的伪代码:
FIND-MAXIMUM-SUBARRAY(A,low,high)
if high==low
return (low,high,A[low]) //base case: only one element
else mid=⌊(low+high)/2⌋
(left-low,left-high,left-sum) = FIND-MAXIMUM-SUBARRAY(A,low,mid)
(right-low,right-high,right-sum) = FIND-MAXIMUM-SUBARRAY(A,mid+1,high)
(cross-low,cross-high,cross-sum) = FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)
if left-sum>=cross-sum and left-sum>=right-sum
return (left-low,left-high,left-sum)
else if right-sum>=left-sum and right-sum>=cross-sum
return (right-low,right-high,right-sum)
else
return(cross-low,cross-high,cross-sum)
4.2 矩阵乘法的Strassen算法
若A=(aij)和B=(bij)是nn的方阵,则对i,j=1,2,…,n,定义乘积C=AB中的元素Cij为:Cij=∑aikbkj (下标是k=1,上标是n);
下面过程接收nn矩阵A,B,并返回他们的乘积C。假设每个矩阵都有一个属性rows。
SQUARE-MATRIX-MULTIPLY(A,B)
n = A.rows
let C be a new n*n matrix
for i = 1 to n
for j = 1 to n
cij = 0
for k=1 to n
cij = cij+aik*bkj
return C
该过程花费时间Θ(n3), 后续的Strassen算法的运行时间为Θ(n2.81)。
一个简单的分治算法
假定n是2的幂,则A,B,C都可以分解为4个n/2Xn/2的子矩阵,则可得以下四个公式:
C11=A11B11+A12B21
C12=A11B12+A12B22
C21=A21B11+A22B21
C22=A21B12+A22B22
每个公式对应两对n/2Xn/2矩阵的乘法及n/2Xn/2积的加法,可以设计一个直接的递归分治算法:
SQUARE-MATRIX-MULTIPLY-RECURSIVE(A,B)
n=A.rows
let C be a new nXn matrix
if n==1
c11=a11*b11
else partition A,B, and C as 4 n/2Xn/2 submatrix
C11=SQUARE-MATRIX-MULTIPLY-RECURSIVE(A11,B11)+SQUARE-MATRIX-MULTIPLY-RECURSIVE(A12,B21)
C12=SQUARE-MATRIX-MULTIPLY-RECURSIVE(A11,B12)+SQUARE-MATRIX-MULTIPLY-RECURSIVE(A12,B22)
C21=SQUARE-MATRIX-MULTIPLY-RECURSIVE(A21,B11)+SQUARE-MATRIX-MULTIPLY-RECURSIVE(A22,B21)
C22=SQUARE-MATRIX-MULTIPLY-RECURSIVE(A21,B12)+SQUARE-MATRIX-MULTIPLY-RECURSIVE(A22,B22)
return C
运行时间的递归式为:T(n)= Θ(1),(若n=1) ; 8T(n/2)+Θ(n2),若n>1。后续4.5节求解递归式可以得到这种解法T(n)=Θ(n3),所以分治算法并不优于SQUARE-MATRIX-MULTIPLY 算法。
Strassen方法
Strassen算法的核心思想是令递归树不那么茂盛一点,即只递归七次而不是八次n/2Xn/2矩阵的乘法。
包含4个步骤:
1.分解矩阵为n/2Xn/2的子矩阵。采用下标计算方法,此步骤花费Θ(1);
2.创建10个n/2Xn/2的矩阵S1,S2…,S10,每个矩阵保存步骤1中创建的两个子矩阵的和或差。花费时间Θ(n2)。
3.用步骤1和2中的矩阵,递归地计算7个矩阵积P1,P2,…,P7。每个矩阵Pi都是n/2Xn/2。
4.通过Pi矩阵的不同组合进行加减运算,计算出C11,C12,C21,C22,花费时间Θ(n2)。
Strassen算法运行时间T(n)的递归式:T(n)= Θ(1) ,若n=1; 7T(n/2)+Θ(n2), 若n>1。
利用4.5节的主方法可以求出T(n) = Θ(nlg7)。
Strassen算法细节
(1)创建如下十个矩阵:
S1=B12 - B22
S2=A11 + A12
S3=A21 + A22
S4=B21 - B11
S5=A11 + A22
S6=B11 + B22
S7=A12 - A22
S8=B21 + B22
S9=A11 - A21
S10=B11 + B12
(2)创建七次矩阵乘法:
P1=A11*S1
P2=S2*B22
P3=S3*B11
P4=A22*S4
P5=S5*S6
P6=S7*S8
P7=S9*S10
(3)计算出C矩阵:
C11=P5+P4-P2+P6
C12=P1+P2
C21=P3+P4
C22=P5+P1-P3-P7
4.3 用代入法求解递归式
分为两步:
1.猜测解的形式。
2.用数学归纳法求出解中的常数,并证明解是正确的。
4.4 用递归树方法求解递归式
在递归树中,每个结点表示一个单一子问题的代价,子问题对应某次递归函数调用。我们将树中每层中的代价求和,得到每层代价,然后将所有层的代价求和,得到所有层次的递归调用的总代价。
4.5 用主方法求解递归式
用于求解形式为:T(n)=aT(n/b)+f(n) 的递归式
其中a>=1,b>1为常数,f(n)是渐进正函数。f(n)包含了问题分解和子问题解合并的代价。例如,描述Strassen算法的递归式中,a=7, b=2, f(n)=Θ(n2);
主定理:令a>=1和b>1是常数,f(n)是一个函数,T(n)是定义在非负整数上的递归式:T(n)=aT(n/b)+f(n)
其中我们将n/b解释为⌈n/b⌉或⌊n/b⌋。那么T(n)有如下渐进界:
1.若对某个常数ε>0有f(n)=O(nlog(b)a-ε), 则T(n)=Θ(nlog(b)a)。
2.若f(n)=Θ(nlog(b)a), 则T(n)=Θ(nlog(b)algn)。
3.若对某个常数ε>0有f(n)=Ω(nlog(b)a+ε),且对某个常数c<1和所有足够大的n有af(n/b)<=cf(n),则T(n)=Θ(f(n))。

















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









