







文章目录
Hadoop之HDFS文件系统入门编程
创建maven项目
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cARfy6g7-1685065470782)(E:\Java笔记\大数据\Hadoop\hadoop的HDFS文件系统\Hadoop的HDFS文件系统入门编程\HDFS文件系统入门编程.assets\image-20230525100929772.png)]](https://img-blog.csdnimg.cn/0ef05c2bf7d64e87b07acff33dd16f31.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-grLbcee3-1685065470782)(E:\Java笔记\大数据\Hadoop\hadoop的HDFS文件系统\Hadoop的HDFS文件系统入门编程\HDFS文件系统入门编程.assets\image-20230525101009482.png)]](https://img-blog.csdnimg.cn/7d93b9059ccc498ab3254cbfb005ec51.png)
配置maven仓库
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vem29I1S-1685065470783)(E:\Java笔记\大数据\Hadoop\hadoop的HDFS文件系统\Hadoop的HDFS文件系统入门编程\HDFS文件系统入门编程.assets\image-20230525101050950.png)]](https://img-blog.csdnimg.cn/fa69eb18e63a41c087ee3ec314b2134c.png)
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sin</groupId>
<artifactId>hadoop</artifactId>
<version>1.0-SNAPSHOT</version>
<!--依赖版本管理 -->
<properties>
<java.version>1.8</java.version>
<hadoop.version>2.7.7</hadoop.version>
<log4j.version>1.2.14</log4j.version>
<junit.version>4.8.2</junit.version>
</properties>
<dependencies>
<!-- Hadoop Common依赖 -->
<!-- Hadoop Common是Hadoop框架的核心组件,提供了分布式文件系统、分布式计算框架等基础功能 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- Hadoop HDFS依赖 -->
<!-- 它是Hadoop生态系统中的一个核心组件,用于存储和管理大规模数据集 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- Hadoop MapReduce Client Core依赖 -->
<!--
Hadoop的MapReduce客户端核心库
MapReduce是Hadoop的核心计算框架之一,用于处理大规模数据集。MapReduce框架由两个主要组件组成:Map和Reduce。
Map任务将输入数据分解成键值对,然后将这些键值对传递给Reduce任务进行处理。
Reduce任务将相同键的所有值组合在一起,并将它们转换为输出键值对。
-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- hadoop core依赖 -->
<!-- Hadoop -core库是Hadoop框架的核心组件,Hadoop框架是用于处理大型数据集的分布式计算平台 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<!-- hadoop client依赖 -->
<!-- 可以在Java项目中使用Hadoop客户端库,从而方便地与Hadoop集群进行交互,例如执行MapReduce任务,操作HDFS文件系统 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- log4j日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<!-- junit测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
</dependencies>
</project>
properties
# Add the log4j.properties file content between PRECEDING_CODE and SUFFIX_CODE
# 设置根日志记录器的级别为INFO,并将日志输出到名为stdout的Appender。
log4j.rootLogger=INFO, stdout
# 定义名为stdout的Appender,类型为org.apache.log4j.ConsoleAppender,用于将日志输出到控制台。
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
# 设置stdout Appender的目标输出流为System.out,即标准输出。
log4j.appender.stdout.Target=System.out
# 设置stdout Appender的布局为org.apache.log4j.PatternLayout,用于格式化日志输出。
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
# 设置PatternLayout的转换模式,用于控制日志输出的格式。这里的格式为:日期(年-月-日 时:分:秒)、日志级别、类名(简化)、行号、日志消息和换行符
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
测试
向hdfs中创建目录
package com.sin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.lang.reflect.Field;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @createTime 2024/4/10 8:49
* @createAuthor SIN
* @use 测试HDFS上传文件
*/
public class HDFSDemo {
//创建了一个静态的 Configuration 对象,用于配置 Hadoop 环境。
private static final Configuration configuration = new Configuration();
//创建了一个静态的 URI 对象,指定了 HDFS 的 NameNode 地址。
private static final URI uri = URI.create("hdfs://master:8020");
/**
* 向hdfs中上传文件
*/
@Test
public void testMkdir() {
try {
/**
* 在 try-with-resources 块中,创建了一个 FileSystem 对象,该对象表示与 HDFS 的连接。
* FileSystem.get(uri, configuration),通过给定的 URI 和配置信息获取 HDFS 文件系统的实例
* 使用try-with-resrource块确保在代码块结束时关闭 FileSystem 对象,避免资源泄漏
*/
try (FileSystem fileSystem = FileSystem.get(uri, configuration)) {
// mkdirs() 方法会递归地创建所有不存在的父目录。返回一个布尔值,表示目录创建是否成功。
boolean success = fileSystem.mkdirs(new Path("/demo"));
if (success) {
System.out.println("目录创建成功");
System.out.println(fileSystem);
} else {
System.out.println("目录创建失败");
}
}
} catch (IOException e) {
// 处理异常情况
e.printStackTrace();
}
}
}
测试异常
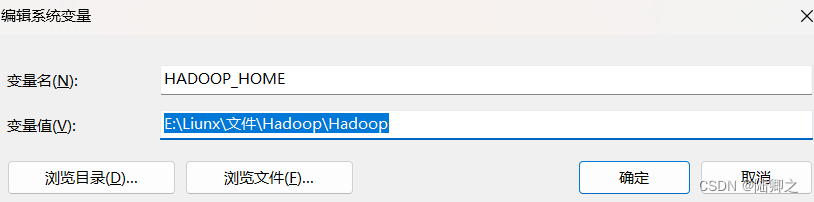
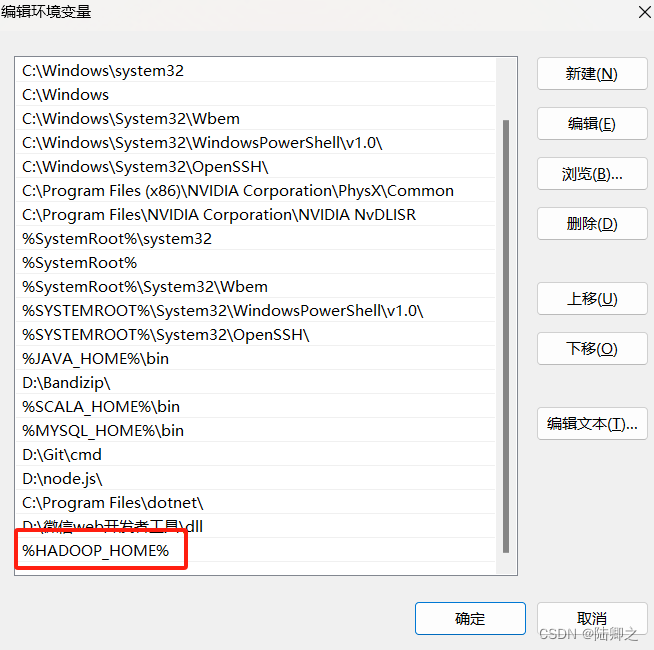
解决java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XwEsNAqx-1685065470783)(E:\Java笔记\大数据\Hadoop\hadoop的HDFS文件系统\Hadoop的HDFS文件系统入门编程\HDFS文件系统入门编程.assets\image-20230525114828907.png)]](https://img-blog.csdnimg.cn/f2af2e1e1ca9418481b8fd3058e3b1f2.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D8gOzItO-1685065470784)(E:\Java笔记\大数据\Hadoop\hadoop的HDFS文件系统\Hadoop的HDFS文件系统入门编程\HDFS文件系统入门编程.assets\image-20230525114845651.png)]](https://img-blog.csdnimg.cn/f0dfb66c8e874a6c90b2ce147b07c14c.png)
向hdfs中创建文件,及内容
//创建文件夹
@Test
public void testCreateFile() throws IOException, URISyntaxException {
// 使用 try-with-resources 语句创建一个 FileSystem 对象
try (FileSystem fileSystem = FileSystem.get(url, configuration)) {
// 创建一个名为 filePath 的 Path 对象,表示文件路径为 /demo/test.txt
Path filePath = new Path("/demo/test.txt");
// 使用 FileSystem 对象的 create 方法创建一个 FSDataOutputStream 对象
FSDataOutputStream out = fileSystem.create(filePath);
// 使用 FSDataOutputStream 对象的 writeUTF 方法写入字符串 "Hello, HDFS!"
out.writeUTF("Hello, HDFS!");
// 关闭 FSDataOutputStream 对象
out.close();
System.out.println("文件创建完成");
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0I0KkVus-1685065470784)(E:\Java笔记\大数据\Hadoop\hadoop的HDFS文件系统\Hadoop的HDFS文件系统入门编程\HDFS文件系统入门编程.assets\image-20230525115349341.png)]](https://img-blog.csdnimg.cn/f4b020d17b1d4f259e5a75eeda1b8ecf.png)
从hdfs中下载文件
//下载文件
@Test
public void testDownloadFile() throws IOException, URISyntaxException {
//获取文件示例
try (FileSystem fileSystem = FileSystem.get(url, configuration)) {
//定义文件路径
Path filePath = new Path("/demo/test.txt");
//判断文件是否存在
if (fileSystem.exists(filePath)) {
//将文件从hdfs下载到本地
fileSystem.copyToLocalFile(filePath, new Path("F:\\"));
System.out.println("文件下载完成");
}
}
}
读取文件内容
//读取test.txt文件数据
@Test
public void testReadFile() throws IOException, URISyntaxException {
// 使用 try-with-resources 语句创建一个 FileSystem 对象
try (FileSystem fileSystem = FileSystem.get(url, configuration)) {
// 创建一个名为 filePath 的 Path 对象,表示文件路径为 /demo/test.txt
Path filePath = new Path("/demo/test.txt");
// 如果文件存在
if (fileSystem.exists(filePath)) {
// 打开文件
FSDataInputStream in = fileSystem.open(filePath);
// 读取文件内容
String content = in.readUTF();
// 输出文件内容
System.out.println(content);
in.close();
}
}
}
删除文件
//删除文件
@Test
public void testDeleteFile() throws IOException, URISyntaxException{
try (FileSystem fileSystem = FileSystem.get(url, configuration)) {
//定义要删除的文件路径
Path filePath = new Path("/demo/test.txt");
//如果文件存在
if (fileSystem.exists(filePath)) {
//删除文件
fileSystem.delete(filePath, false);
System.out.println("文件删除成功");
}
}
}
重命名文件
//重命名文件
@Test
public void testRenameFile() throws IOException, URISyntaxException {
try (FileSystem fileSystem = FileSystem.get(url, configuration)) {
//旧路径(旧文件名)
Path oldPath = new Path("/demo");
//新路径(新文件名)
Path newPath = new Path("/demo1");
//判断旧文件是否存在
if (fileSystem.exists(oldPath)) {
//重命名文件
fileSystem.rename(oldPath, newPath);
System.out.println("文件重命名成功");
}
}
}
判断是文件还是文件夹
// 判断文件还是文件夹
@Test
public void testCheckFileAndDirectory() throws IOException, URISyntaxException {
// 使用FileSystem.get方法获取一个FileSystem实例,并使用try-with-resources语句确保资源被正确关闭
try (FileSystem fileSystem = FileSystem.get(url, configuration)) {
// 创建一个Path实例,表示HDFS中的/demo路径
Path path = new Path("/demo1");
// 判断/demo路径是否存在
if (fileSystem.exists(path)) {
// 获取/demo路径的文件状态信息
FileStatus fileStatus = fileSystem.getFileStatus(path);
// 判断/demo路径是否是一个文件
if (fileStatus.isFile()) {
// 输出"这是一个文件"
System.out.println("这是一个文件");
// 判断/demo路径是否是一个目录
} else if (fileStatus.isDirectory()) {
// 输出"这是一个文件夹"
System.out.println("这是一个文件夹");
// 如果/demo路径既不是文件也不是目录
} else {
// 输出"未知的类型"
System.out.println("未知的类型");
}
// 如果/demo路径不存在
} else {
// 输出"路径不存在"
System.out.println("路径不存在");
}
}
}
修改权限
@Test
public void testPermissionExample() throws IOException {
try (FileSystem fileSystem = FileSystem.get(uri, configuration)) {
// 创建一个Path实例,表示HDFS中的/demo路径
Path path = new Path("/userInput/demo/admin");
// 创建一个 FsPermission 对象,表示要设置的权限。在这里,代码尝试将权限值转换为 int 类型,然后再转换为 String 类型。
FsPermission permission = new FsPermission(String.valueOf( 755));
// 使用 FileSystem 对象的 setPermission 方法来设置指定路径的权限。
fileSystem.setPermission(path,permission);
System.out.println("修改成功");
}
}
列出hdfs文件信息
@Test
public void testListHDFSFiles() throws IOException {
// 使用 try-with-resources 语句创建 FileSystem 对象,并确保在代码块结束时自动关闭资源
try (FileSystem fileSystem = FileSystem.get(uri, configuration)) {
// 指定要列出的HDFS目录路径
Path path = new Path("/");
// 获取目录中的文件列表
FileStatus[] fileStatuses = fileSystem.listStatus(path);
// 创建SimpleDateFormat对象,用于格式化日期时间
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 打印文件和目录信息
for (FileStatus status : fileStatuses) {
// 打印文件路径
System.out.println("路径: " + status.getPath());
// 打印文件所有者
System.out.println("所有者: " + status.getOwner());
// 打印文件所属组
System.out.println("组: " + status.getGroup());
// 打印文件权限
System.out.println("权限: " + status.getPermission());
// 打印文件大小
System.out.println("大小: " + status.getLen());
// 打印文件块大小
System.out.println("块大小: " + status.getBlockSize());
// 打印文件副本数
System.out.println("副本数: " + status.getReplication());
// 格式化修改时间并打印
Date modificationTime = new Date(status.getModificationTime());
String formattedModificationTime = dateFormat.format(modificationTime);
System.out.println("修改时间: " + formattedModificationTime);
}
}
}
















 283
283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











