






Hadoop概要点

优势:
-
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
-
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
-
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
-
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
-
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
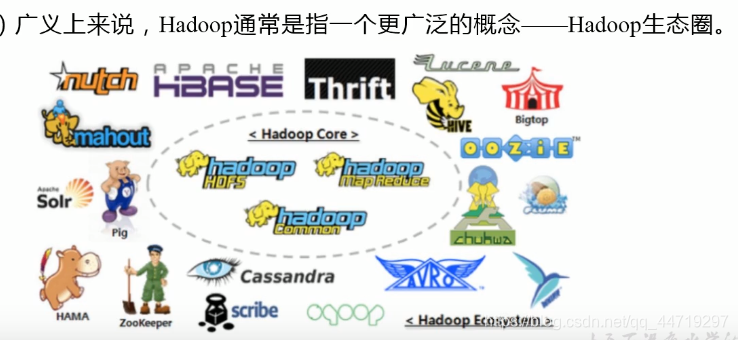
1.x 和 2.x的区别
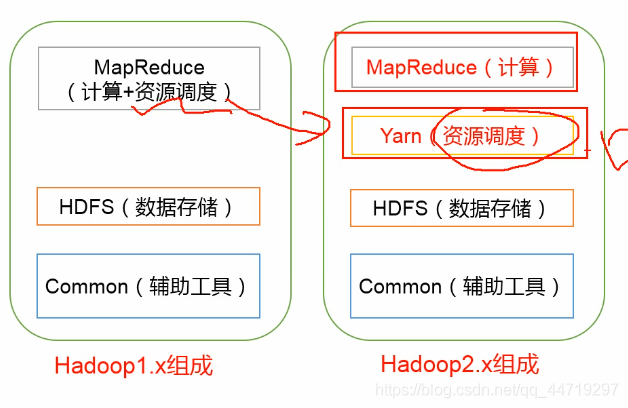
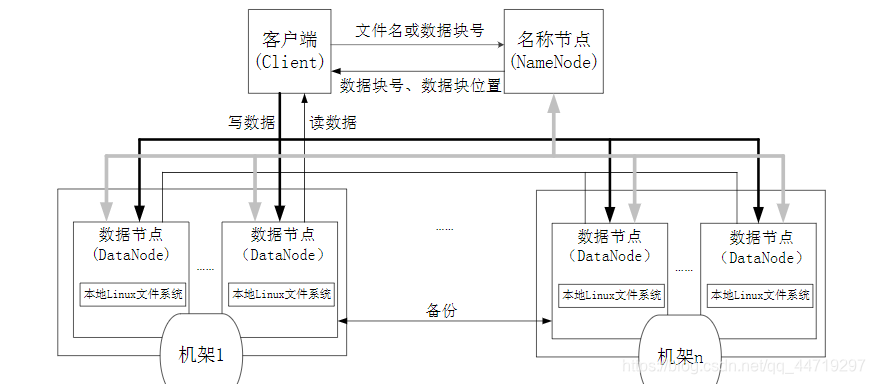
分布式文件系统的结构
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)
块
HDFS默认一个块64MB,一个文件被分成多个块,以块作为存储单位。块的大小远远大于普通文件系统,可以最小化寻址开销。
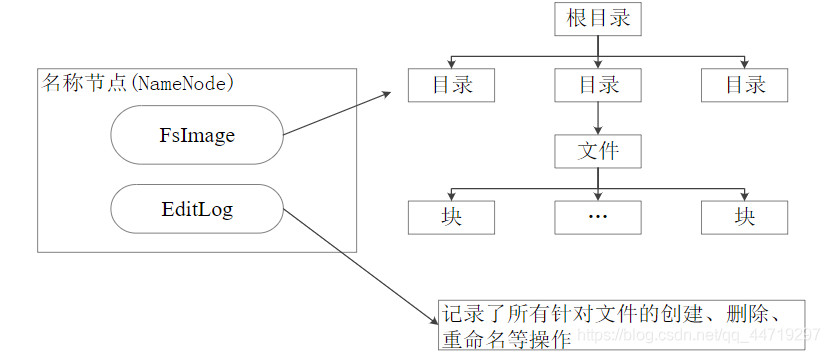
Namenode 名称文件
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog。
- 名称节点记录了每个文件中各个块所在的数据节点的位置信息,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。
•FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据。FsImage文件包含文件系统中所有目录和文件inode的序列化形式。每个inode是一个文件或目录的元数据的内部表示。
•EditLog操作日志文件中记录了所有针对文件的创建、删除、重命名等操作
•在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
•一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件
•名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中,且在向客户端发送成功代码之前,edits文件都需要同步更新名称节点的启动。
EditLog不断变大的问题
SecondaryNameNode第二名称节点。用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上。
Datanode 数据结点
•数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
•每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
客户端
•HDFS客户端是一个库,暴露了HDFS文件系统接口,这些接口隐藏了HDFS实现中的大部分复杂性
•严格来说,客户端并不算是HDFS的一部分
•客户端可以支持打开、读取、写入等常见的操作,并且提供了类似Shell的命令行方式来访问HDFS中的数据
HDFS
HDFS采用了主从结构模型,一个HDFS集群包括一个NameNode和若干个数据节点DataNode.
- HDFS的命名空间包含目录、文件和块,在HDFS1.0体系结构中,在整个HDFS集群中只有一个命名空间
- HDFS使用的是传统的分级文件体系,因此,用户可以像使用普通文件系统一样,创建、删除目录和文件,在目录间转移文件,重命名文件等
HDFS实现目标:
- 兼容廉价的硬件设备
- 流数据读写
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
局限性:
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
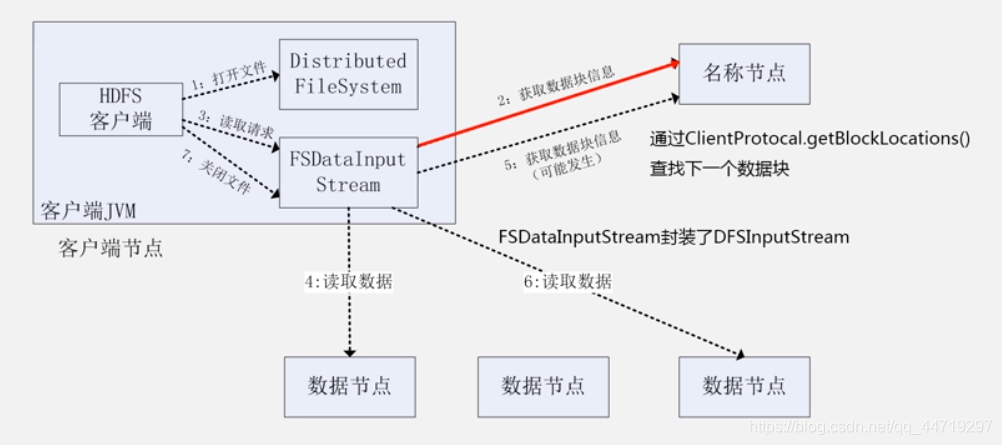
HDFS读过程
FileSystem基础方法:
- open
- read
- close
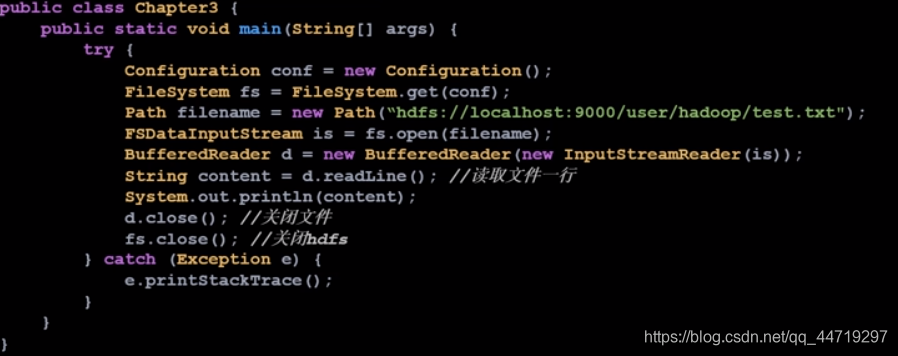
基础读过程代码:
- 通过Configuration构造方法导入hdfs-site.xml和core-site.xml两个配置文件,来获取fs.defaultFS(整个分布式文件系统的地址)
- FileSystem.get(conf),设置环境配置变量
- fs.open(URL),打开输入文件的地址
HDFS写过程
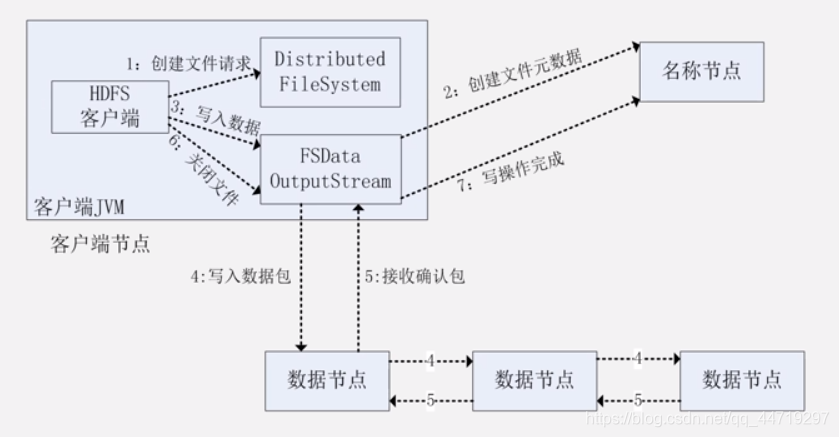
流水线复制:数据被分包,重复写在数据结点上。
通信协议
HDFS是一个部署在集群上的分布式文件系统,因此,很多数据需要通过网络进行传输。
- 所有的HDFS通信协议都是构建在TCP/IP协议基础之上的
- 客户端 通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互
- 名称节点和数据节点之间则使用数据节点协议进行交互
- 客户端与数据节点的交互是通过RPCRemoteProcedureCall来实现的。名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求。
HBase
HBase简介:HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
HBase与传统的关系数据库的区别:
- 数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串
- 数据操作:关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系
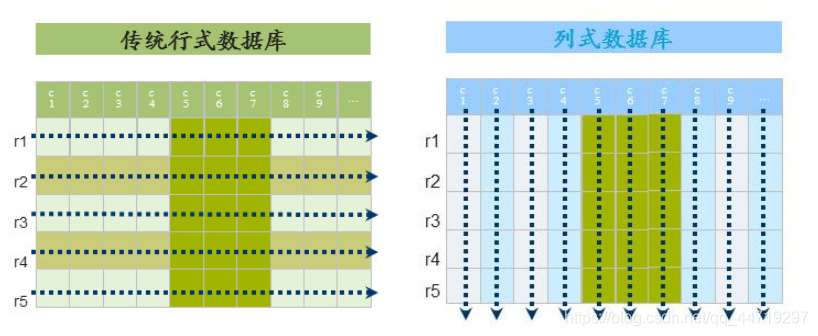
- 存储模式:关系数据库是基于行模式存储的。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的
HBase访问接口
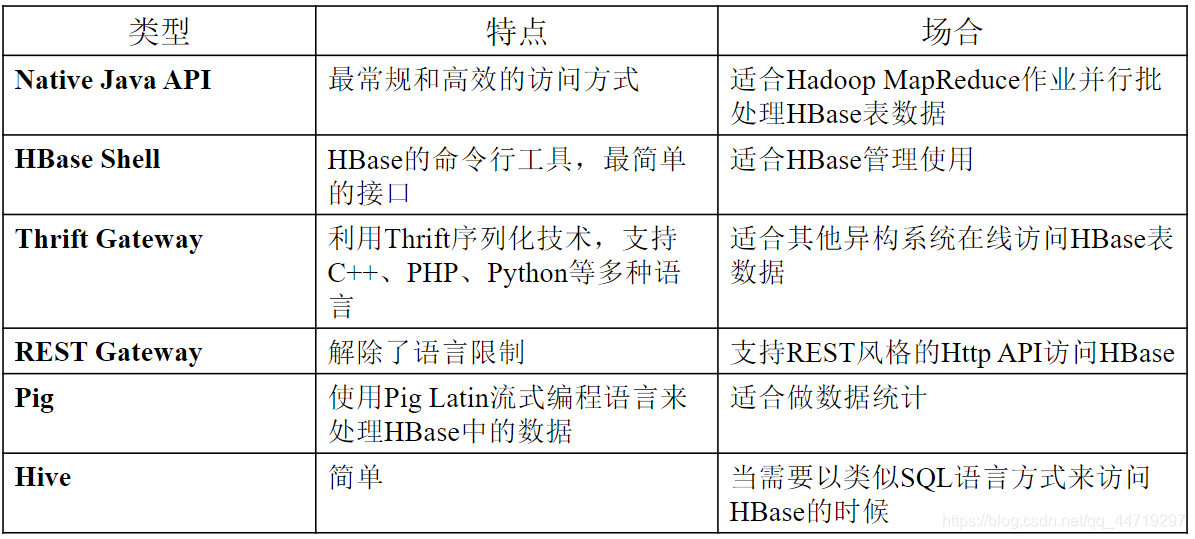
HBase数据类型
- HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳
- 每个值是一个未经解释的字符串,没有数据类型
- 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列
- 表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起
- 列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换
- HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的)

数据坐标:
HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此,可以视为一个“四维坐标”,即[行键, 列族, 列限定符, 时间戳]

对比图:
HBase功能组件
HBase的实现包括三个主要的功能组件:
- 库函数:链接到每个客户端
- 一个Master主服务器
- 许多个Region服务器
- 主服务器Master负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡
- Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求
- 客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据
- 客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
一个表会分裂成许多Region,Region又会自己不断分裂,Region拆分操作非常快,接近瞬间,因为拆分之后的Region读取的仍然是原存储文件,直到“合并”过程把存储文件异步地写到独立的文件之后,才会读取新文件。
关于Region:
- 每个Region的最佳大小取决于单台服务器的有效处理能力
- 目前每个Region最佳大小建议1GB-2GB(2013年以后的硬件配置)
- 同一个Region不会被分拆到多个Region服务器
- 每个Region服务器存储10-1000个Region
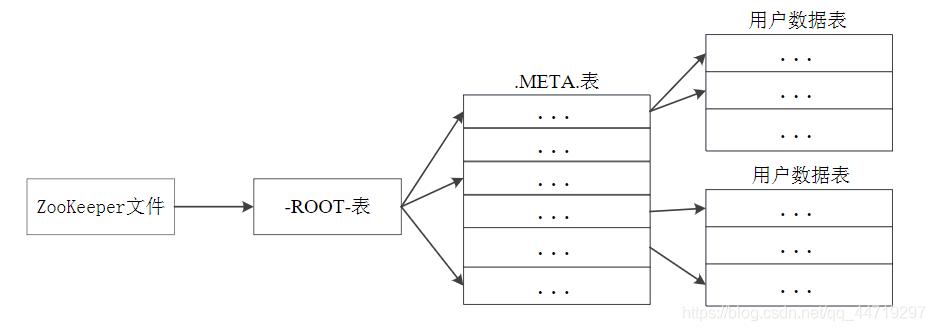
元数据表 : 又名.META.表,存储了Region和Region服务器的映射关系
当HBase表很大时,.META.表也会被分裂成多个Region。为了加快访问速度,.META.表的全部Region都会被保存在内存中
根数据表 : 又名-ROOT-表,记录所有元数据的具体位置
-ROOT-表只有唯一一个Region,名字是在程序中被写死的
Zookeeper文件记录了-ROOT-表的位置
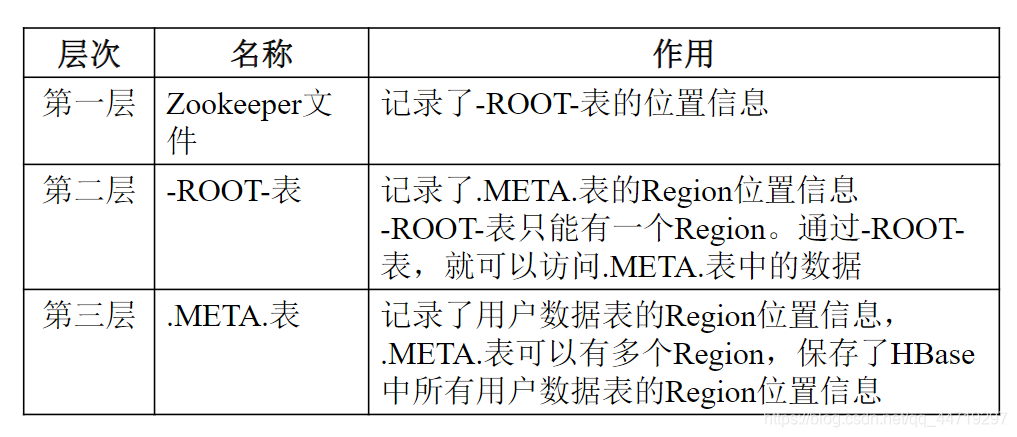
客户端访问数据时“三级寻址”。为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题。寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









