







目录
第十一章
11.1 动态规划理论基础
动态规划英文:Dynamic Programming,简称DP,本章有时也称动规。如果某⼀问题有很多重叠⼦问题,使⽤动态规划是最有效的。
动态规划中每⼀个状态⼀定是由上⼀个状态推导出来的,这⼀点就区分于贪⼼,贪⼼没有状态推导,⽽是从局部直接选最优的。
例如:有N件物品和⼀个最多能背重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i]。每件物品只能⽤⼀次,求解将哪些物品装⼊背包⾥物品价值总和最⼤。
动态规划中dp[j]是由dp[j-weight[i]]推导出来的,然后取max(dp[j], dp[j - weight[i]] + value[i])。
但如果是贪⼼呢,每次拿物品选⼀个最⼤的或者最⼩的就完事了,和上⼀个状态没有关系。所以贪⼼解决不了动态规划的问题。
其实⼤家也不⽤死扣动规和贪⼼的理论区别,后⾯做做题⽬⾃然就知道了。⽽且很多讲解动态规划的⽂章都会讲最优⼦结构啊和重叠⼦问题啊这些,这些东⻄都是教科书的上定义,晦涩难懂⽽且不实⽤。⼤家知道动规是由前⼀个状态推导出来的,⽽贪⼼是局部直接选最优的,对于刷题来说就够⽤了。上述提到的背包问题,后序会详细讲解。
11.1.1 动态规划问题解题步骤
做动规题⽬的时候,很多同学会陷⼊⼀个误区,就是以为把状态转移公式背下来,照葫芦画瓢改改,就开始写代码,甚⾄把题⽬AC之后,都不太清楚dp[i]表示的是什么。这就是⼀种朦胧的状态,然后就把题给过了,遇到稍稍难⼀点的,可能直接就不会了,然后看题解,然后继续照葫芦画瓢陷⼊这种恶性循环中。状态转移公式(递推公式)是很重要,但动规不仅仅只有递推公式。
对于动态规划问题,下面拆解为如下五步曲:
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
为什么要先确定递归公式,然后才考虑初始化dp数组呢?因为递推公式决定了如何初始化dp数组。
本章后面的讲解都围绕这五部曲展开。⼀些同学知道递推公式,但搞不清楚dp数组应该如何初始化,或者正确的遍历顺序,以⾄于记下来公式,但写的程序怎么改都通过不了。后序的讲解的⼤家就会慢慢感受到这五步的重要性了。
11.1.2 动态规划应该如何排查问题
相信动规的题⽬,很⼤部分同学都是这样做的。
看⼀下题解,感觉看懂了,然后照葫芦画瓢,如果能正好画对了,万事⼤吉,⼀旦要是没通过,就怎么改都通过不了,对 dp数组的初始化,递归公式,遍历顺序,处于⼀种⿊盒的理解状态。
写动规题⽬,代码出问题很正常!
找问题的最好⽅式就是把dp数组打印出来,看看究竟是不是按照⾃⼰思路推导的!
⼀些同学对于dp的学习是⿊盒的状态,就是不清楚dp数组的含义,不懂为什么这么初始化,递推公式背下来了,遍历顺序靠习惯就是这么写的,然后⼀⿎作⽓写出代码,如果代码能通过万事⼤吉,通过不了的话就凭感觉改⼀改。
这是⼀个很不好的习惯!
做动规的题⽬,写代码之前⼀定要把状态转移在dp数组的上具体情况模拟⼀遍,⼼中有数,确定最后推出的是想要的结果。
然后再写代码,如果代码没通过就打印dp数组,看看是不是和⾃⼰预先推导的哪⾥不⼀样。
如果打印出来和⾃⼰预先模拟推导是⼀样的,那么就是⾃⼰的递归公式、初始化或者遍历顺序有问题了。如果和⾃⼰预先模拟推导的不⼀样,那么就是代码实现细节有问题。
这样才是⼀个完整的思考过程,⽽不是⼀旦代码出问题,就毫⽆头绪的东改改⻄改改,最后过不了,或者说是稀⾥糊涂的过了。
这也是我为什么在动规五步曲⾥强调推导dp数组的重要性。
举个例⼦哈:在「代码随想录」刷题⼩分队微信群⾥,⼀些录友可能代码通过不了,会把代码抛到讨论群⾥问:我这⾥代码都已经和题解⼀模⼀样了,为什么通过不了呢?发出这样的问题之前,其实可以⾃⼰先思考这三个问题:
1.这道题⽬我举例推导状态转移公式了么?
2.我打印dp数组的⽇志了么?
3.打印出来了dp数组和我想的⼀样么?
如果这灵魂三问⾃⼰都做到了,基本上这道题⽬也就解决了,或者更清晰的知道⾃⼰究竟是哪⼀点不明⽩,是状态转移不明⽩,还是实现代码不知道该怎么写,还是不理解遍历dp数组的顺序。
然后在问问题,⽬的性就很强了,群⾥的⼩伙伴也可以快速知道提问者的疑惑了。注意这⾥不是说不让⼤家问问题哈, ⽽是说问问题之前要有⾃⼰的思考,问题要问到点⼦上!⼤家⼯作之后就会发现,特别是⼤⼚,问问题是⼀个专业活,是的,问问题也要体现出专业!如果问同事很不专业的问题,同事们会懒的回答,领导也会认为你缺乏思考能⼒,这对职场发展是很不利的。所以⼤家在刷题的时候,就锻炼⾃⼰养成专业提问的好习惯。
小结:
这⼀篇是动态规划的整体概述,讲解了什么是动态规划,动态规划的解题步骤,以及如何debug。动态规划是⼀个很⼤的领域,今天这⼀篇讲解的内容是整个动态规划系列中都会使⽤到的⼀些理论基础。
在后序讲解中针对某⼀具体问题,还会讲解其对应的理论基础,例如背包问题中的01背包,leetcode上的题⽬都是01背包的应⽤,⽽没有纯01背包的问题,那么就需要在把对应的理论知识讲解⼀下。
⼤家会发现,我讲解的理论基础并不是教科书上各种动态规划的定义,错综复杂的公式。这⾥理论基础篇已经是⾮常偏实⽤的了,每个知识点都是在解题实战中⾮常有⽤的内容,⼤家要重视起来哈。
今天我们开始新的征程了,你准备好了么?
11.2 斐波那契数
力扣题号:509.斐波那契数
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1) = 1
F(n) = F(n - 1) + F(n - 2),其中 n > 1
给定 n ,请计算 F(n) 。
示例 1:
输入:n = 2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1
示例 2:
输入:n = 3
输出:2
解释:F(3) = F(2) + F(1) = 1 + 1 = 2
示例 3:
输入:n = 4
输出:3
解释:F(4) = F(3) + F(2) = 2 + 1 = 3
提示:
0 <= n <= 30
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/fibonacci-number
思路
斐波那契数列⼤家应该⾮常熟悉不过了,⾮常适合作为动规第⼀道题⽬来练练⼿。
因为这道题⽬⽐较简单,可能⼀些同学并不需要做什么分析,直接顺⼿⼀写就过了。但「代码随想录」的⻛格是:简单题⽬是⽤来加深对解题⽅法论的理解的。通过这道题⽬让⼤家可以初步认识到,按照动规五部曲是如何解题的。对于动规,如果没有⽅法论的话,可能简单题⽬可以顺⼿⼀写就过,难⼀点就不知道如何下⼿了。
所以我总结的动规五部曲,是要⽤来贯穿整个动态规划系列的,就像之前讲过⼆叉树系列的递归三部曲,回溯法系列的回溯三部曲⼀样。后⾯慢慢⼤家就会体会到,动规五部曲⽅法的重要性。
动规五部曲:
1.确定dp数组以及下标的含义
dp[i]的定义为:第i个数的斐波那契数值是dp[i]。
2.确定递推公式:
这道题之所以简单,是因为题目已经把递推公式给出了。状态转移方程:F(n) = F(n - 1) + F(n - 2)
3.dp数组应该如何初始化:
这道题也给我们了。F(0) = 0,F(1) = 1
4.确定遍历顺序:
从递归公式来看,dp[i]是依赖dp[i-1]和dp[i-2]的,那么遍历的顺序一定是从前往后。
5.举例推导dp数组:
如果按照递推公式推导,当N为10时,dp数组应该是如下的数列:0 1 1 2 3 5 8 13 21 34 55,如果代码写出来,发现结果不对,就把dp数组打印出来看看和我们推导的数列是不是一致的。
整体代码如下:
题解
class Solution {
public:
int fib(int n) {
if (n <= 1) return n;
vector<int> dp(n + 1);//初始化dp数组
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
};
在上面的代码中,我们发现其实不用维护整个dp数组,只需要维护两个数值即可(每次都在dp[0]和dp[1]的基础上计算)整体代码如下:
题解
class Solution {
public:
int fib(int n) {
if (n <= 1) return n;
vector<int> dp(2);//初始化dp数组
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
int temp = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = temp;
}
return dp[1];
}
};
递归算法是代码量思考量最少的,整体代码如下:
题解
class Solution {
public:
int fib(int n) {
if (n < 2) return n;
return fib(n - 1) + fib(n - 2);
}
};
小结:斐波那契数列这道题⽬是⾮常基础的题⽬,我在后⾯的动态规划的讲解中将会多次提到斐波那契数列!这⾥我严格按照关于动态规划,你该了解这些!中的动规五部曲来分析了这道题⽬,⼀些分析步骤可能同学感觉没有必要搞的这么复杂,代码其实上来就可以撸出来。但我还是强调⼀下,简单题是⽤来掌握⽅法论的,动规五部曲将在接下来的动态规划讲解中发挥重要作⽤。
11.3 爬楼梯
力扣题号: 70.爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
- 1 阶 + 1 阶
- 2 阶
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
- 1 阶 + 1 阶 + 1 阶
- 1 阶 + 2 阶
- 2阶 + 1 阶
提示:
1 <= n <= 45
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/climbing-stairs
举个小例子来理解此题如何抽象为dp数组的递推。假设有三节台阶,到达第三节台阶的上一个状态都有什么?在第二节台阶和在第一节台阶。在第一节台阶时有几种方法到达第三节台阶?很明显有两种(两次一节或一次两节);在第二节台阶时有几种方法到达第三节台阶?只有一种(一次一节)。但是我们知道,如果在第一节台阶时上一节台阶,这时的状态就和在第二节台阶一样了(只要再上一节就到达第三节),所以这种方法和我们在第二节台阶是重复的,所以不能重复计算。
所以,我们到达第三节台阶可以通过在第一节和第二节台阶来推导,第一节上两节和第二节上一节。所以dp[3]=d[2] +dp[1].
动规五部曲:
1.确定dp数组和下标的含义
dp[i]:爬到第i节台阶有dp[i]种方法。
2.确定递推公式
从dp的定义可以看出,dp[i]有两个方向可以推导出来,一个是dp[i-1]:目前在i-1节台阶,只需上一节就可到达第i节台阶,而到达i-1台阶有dp[i-1]种方法;另一个是dp[i-2]:目前在i-2节台阶,只需一次上两节就可到达 第i节台阶,而到达i-2节台阶有dp[i-2]种方法。所以dp[i] = dp[i-1]+dp[i-2];在推导dp[i]时候,一定要时刻想着dp[i]的定义,否则容易跑偏。
3.dp数组如何初始化
回顾一些dp[i]的定义,爬到第i节台阶有几种方法。相信同学们对dp[1]=1,dp[2]等于2都没有异议。问题是dp[0]等于多少?有的人认为dp[0]=1:强⾏安慰⾃⼰爬到第0层,也有⼀种⽅法,什么都不做也就是⼀种⽅法即:dp[0] = 1,相当于直接站在楼顶,貌似有点牵强。还有的人认为dp[0]=0,我就认为跑到第0层,⽅法就是0啊,⼀步只能⾛⼀个台阶或者两个台阶,然⽽楼层是
0,直接站楼顶上了,就是不⽤⽅法,dp[0]就应该是0。
这时候大家就纠结了,其实仔细看看题目要求,n为正整数,讨论i=0,根本就没有意义!所以我们应该不考虑dp[0]如何初始化,只初始化dp[1]=1,dp[2]=2,从i=3开始递推,这样才符合dp[i]的定义。
4.确定遍历顺序
从递推公式看,dp[i]的推导是依靠dp[i-1]和dp[i-2]的,所以遍历顺序一定是从前往后。
5.举例推导dp数组
举例n=5时,dp数组应该是这样的:
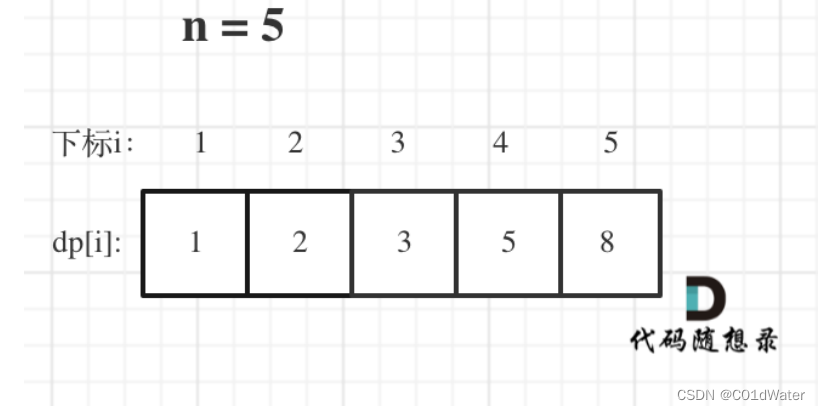
如果代码出现问题,那么我们应该把dp数组打印出来,看看究竟哪里和自己推导的不一样。欸,这不是上一题的斐波那契数列吗?唯一的区别是,没有讨论dp[0]应该是什么,因为在本题中dp[0]只在数学角度上有意义,在实际角度上是没有意义的。
整体代码如下:
题解
class Solution {
public:
int climbStairs(int n) {
if (n < 3) return n;
vector<int> dp(n+1);
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
};
和斐波那契数列一样,我们依然没有必要维护整个dp数组,只需维护两个数值就行了,优化空间复杂度代码如下:
题解
class Solution {
public:
int climbStairs(int n) {
if (n < 3) return n;
vector<int> dp(3);//如果初始化为dp(2),则dp[2]会越界
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) {
int temp = dp[2] + dp[1];
dp[1] = dp[2];
dp[2] = temp;
}
return dp[2];
}
};
小结:后⾯将讲解的很多动规的题⽬其实都是当前状态依赖前两个,或者前三个状态,都可以做空间上的优
化,但我个⼈认为⾯试中能写出版本⼀就够了,清晰明了,如果⾯试官要求进⼀步优化空间的话,我们再去优化。因为版本⼀才能体现出动规的思想精髓,递推的状态变化。
这道题⽬和动态规划:斐波那契数题⽬基本是⼀样的,但是会发现本题相⽐动态规划:斐波那契数难多了,为什么呢?关键是 动态规划:斐波那契数 题⽬描述就已经把动规五部曲⾥的递归公式和如何初始化都给出来了,剩下⼏部曲也⾃然⽽然的推出来了。⽽本题,就需要逐个分析了,⼤家现在应该初步感受出关于动态规划,你该了解这些!⾥给出的动规五部曲了。
简单题是⽤来掌握⽅法论的,例如昨天斐波那契的题⽬够简单了吧,但昨天和今天可以使⽤⼀套⽅法分析出来的,这就是⽅法论!
所以不要轻视简单题,那种凭感觉就刷过去了,其实和没掌握区别不⼤,只有掌握⽅法论并说清⼀⼆三,才能触类旁通,举⼀反三哈!
11.3.1 拓展
这道题可以进一步优化:就是一步一个台阶、一步两个台阶,三个台阶,直至m个台阶,有多少种方法可以爬到n阶台阶。
这⼜有难度了,这其实是⼀个完全背包问题,但⼒扣上没有这种题⽬,所以后续我在讲解背包问题的时候,今天这道题还会拿从背包问题的⻆度上来再讲⼀遍。
这里先给出大致的代码:
class Solution {
public:
int climbStairs(int n) {
vector<int> dp(n + 1, 0);
dp[0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) { // 把m换成2,就可以AC爬楼梯这道题
if (i - j >= 0) dp[i] += dp[i - j];
}
}
return dp[n];
}
};
以上代码不能运⾏哈,我主要是为了体现只要把m换成2,粘过去,就可以AC爬楼梯这道题,不信你就粘⼀下试试,哈哈。
此时我就发现⼀个绝佳的⼤⼚⾯试题,第⼀道题就是单纯的爬楼梯,然后看候选⼈的代码实现,如果把dp[0]的定义成1了,就可以发难了,为什么dp[0]⼀定要初始化为1,此时可能候选⼈就要强⾏给dp[0]应该是1找各种理由。那这就是⼀个考察点了,对dp[i]的定义理解的不深⼊。然后可以继续发难,如果⼀步⼀个台阶,两个台阶,三个台阶,直到 m个台阶,有多少种⽅法爬到n阶楼顶。这道题⽬leetcode上并没有原题,绝对是考察候选⼈算法能⼒的绝佳好题。这⼀连套问下来,候选⼈算法能⼒如何,⾯试官⼼⾥就有数了。
其实⼤⼚⾯试最喜欢问的就是这种简单题,然后慢慢变化,在⼩细节上考察候选⼈。
11.4 使用最小花费爬楼梯
力扣题号: 746.使用最小花费爬楼梯
给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。
你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。
请你计算并返回达到楼梯顶部的最低花费。
示例 1:
输入:cost = [10,15,20]
输出:15
解释:你将从下标为 1 的台阶开始。
- 支付 15 ,向上爬两个台阶,到达楼梯顶部。
总花费为 15 。
示例 2:
输入:cost = [1,100,1,1,1,100,1,1,100,1]
输出:6
解释:你将从下标为 0 的台阶开始。
- 支付 1 ,向上爬两个台阶,到达下标为 2 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 4 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 6 的台阶。
- 支付 1 ,向上爬一个台阶,到达下标为 7 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 9 的台阶。
- 支付 1 ,向上爬一个台阶,到达楼梯顶部。
总花费为 6 。
提示:
2 <= cost.length <= 1000
0 <= cost[i] <= 999
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/min-cost-climbing-stairs
思路
这道题⽬可以说是爬楼梯的花费版本。注意题⽬描述:每当你爬上⼀个阶梯你都要花费对应的体⼒值,⼀旦⽀付了相应的体⼒值,你就可以选择向上爬⼀个阶梯或者爬两个阶梯。所以示例1中只花费⼀个15 就可以到阶梯顶,最后⼀步可以理解为下一步就到达目标台阶,到达目标台阶后不⽤再花费目标台阶对应的体力值了。读完题⼤家应该知道指定需要动态规划的,贪⼼是不可能了。
1.确定dp数组和下标的含义
dp[i]:到达第i个台阶所花费的最少体力(这里认为第一步是一定要花费的)。
2.确定递推公式
从上一节的题目我们可以知道,到达第i节台阶有两种方式(从第i-1和从第i-2),又因为我们定义dp[i]为最小花费,所以我们应该选dp[i-1]和dp[i-2]中最小的,再加上当前第i节的花费,因为题目中说了,每当你爬上一节台阶都要花费对应的体力值。即dp[i]=min(dp[i-1],dp[i-2])+cost[i];
3.dp数组如何初始化
根据dp数组的定义,dp数组初始化其实是⽐较难的,因为不可能初始化为第i台阶所花费的最少体⼒。那么看⼀下递归公式,dp[i]由dp[i-1],dp[i-2]推出,既然初始化所有的dp[i]是不可能的,那么只初始化dp[0]和dp[1]就够了,题目中说我们可以选择从第一节台阶或第二节台阶出发。其他的最终都是dp[0]dp[1]推出。dp[0]=cost[0];dp[1]=cost[1];
4.确定遍历顺序
本题的遍历顺序其实⽐较简单,简单到很多同学都忽略了思考这⼀步直接就把代码写出来了。因为是模拟台阶,⽽且dp[i]⼜dp[i-1]dp[i-2]推出,所以是从前到后遍历cost数组就可以了。但是稍稍有点难度的动态规划,其遍历顺序并不容易确定下来。例如:01背包,都知道两个for循环,⼀个for遍历物品嵌套⼀个for遍历背包容量,那么为什么不是⼀个for遍历背包容量嵌套⼀个for遍历物品呢? 以及在使⽤⼀维dp数组的时候遍历背包容量为什么要倒叙呢?这些都是遍历顺序息息相关。当然背包问题后续都会重点讲解的。
5.举例推导dp数组
拿示例2举例:
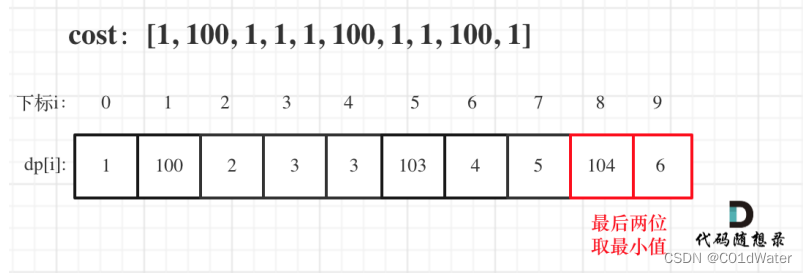
如果大家代码写出来有问题,可以把dp数组打印出来,看看和推导的是否一致。
整体代码如下:
题解
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
vector<int> dp(cost.size());
dp[0] = cost[0];
dp[1] = cost[1];
for (int i = 2; i < cost.size(); i++) {
dp[i] = min(dp[i - 1], dp[i - 2]) + cost[i];
}
return min(dp[cost.size() - 2], dp[cost.size() - 1]);//返回结果这行代码没加cost,是因为在这两节台阶上已经支付了体力,可以任意向上走
//dp[cost.size() - 2]代表目前在目标台阶的下一节台阶上,已经加上了cost[dp.size() - 2],代表再上一步就可以到达目标台阶,到达了目标台阶不用再支付目标台阶的体力值
//dp[cost.size() - 1]代表目前就在目标台阶上,已经加上了cost[dp.size() - 1] ,既然已经到达了目标台阶,就不用再次支付目标台阶的体力值
}
};
同样的我们依然可以优化空间复杂度,没必要维护整个dp数组,只需要维护两位即可。代码如下:
题解
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
int dp0 = cost[0];
int dp1 = cost[1];
for (int i = 2; i < cost.size(); i++) {
int temp = min(dp0, dp1) + cost[i];
dp0 = dp1;
dp1 = temp;
}
return min(dp0, dp1);
}
};
小结:⼤家可以发现这道题⽬相对于爬楼梯又难了⼀点,但整体思路是⼀样。从斐波那契数到 爬楼梯再到今天这道题⽬,感受到循序渐进的梯度了嘛。
就算是简单题,也是为了练习⽅法论,然后难度都是梯度上来的,⼀环扣⼀环。但我也可以随便选来⼀道难题讲呗,这其实是最省事的,不⽤管什么题⽬顺序,看⼼情找⼀道就讲。难的是把题⽬按梯度排好,循序渐进,再按照统⼀⽅法论把这些都串起来。
11.4.1 拓展
这道题描述也确实有点魔幻。
题⽬描述为:每当你爬上⼀个阶梯你都要花费对应的体⼒值,⼀旦⽀付了相应的体⼒值,你就可以选择向上爬⼀个阶梯或者爬两个阶梯。
示例1:
输⼊:cost = [10, 15, 20]
输出:15
从题⽬描述可以看出:要不是第⼀步不需要花费体⼒,要不就是第最后⼀步不需要花费体⼒,我个⼈理
解:题意说的其实是第⼀步是要⽀付费⽤的!。因为是当你爬上⼀个台阶就要花费对应的体⼒值!所以我定义的dp[i]意思是也是第⼀步是要花费体⼒的,最后⼀步不⽤花费体⼒了,因为已经⽀付了。当然也可以样,定义dp[i]为:第⼀步是不花费体⼒,最后⼀步是花费体⼒的。所以代码这么写:
题解
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
vector<int> dp(cost.size() + 1);
dp[0] = 0; // 默认第⼀步都是不花费体⼒的
dp[1] = 0;
for (int i = 2; i <= cost.size(); i++) {
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
}
return dp[cost.size()];
}
}
举例推导dp数组为:
| cost | 1 | 100 | 1 | 1 | 1 | 100 | 1 | 1 | 100 | 1 | # |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | # |
| dp[i] | 0 | 0 | 1 | 2 | 2 | 3 | 3 | 4 | 4 | 5 | 6 |
最后return[dp.size()]就是最后答案。这么写看上去⽐较顺,但是就是感觉和题⽬描述的不太符。哈哈,也没有必要这么细扣题意了,⼤家只要知道,题⽬的意思反正就是要不是第⼀步不花费,要不是最后⼀步不花费,都可以。
11.5 不同路径
力扣题号:62.不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
输入:m = 3, n = 7
输出:28
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
向右 -> 向下 -> 向下
向下 -> 向下 -> 向右
向下 -> 向右 -> 向下
示例 3:
输入:m = 7, n = 3
输出:28
示例 4:
输入:m = 3, n = 3
输出:6
提示:
1 <= m, n <= 100
题目数据保证答案小于等于 2 * 109
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/unique-paths
11.5.1 深度优先遍历
机器人每次只能走下或走右一步,只有这两种选择,这不是二叉树吗?我们把机器人走过的路径抽象为一棵二叉树,而叶子节点就是终点。
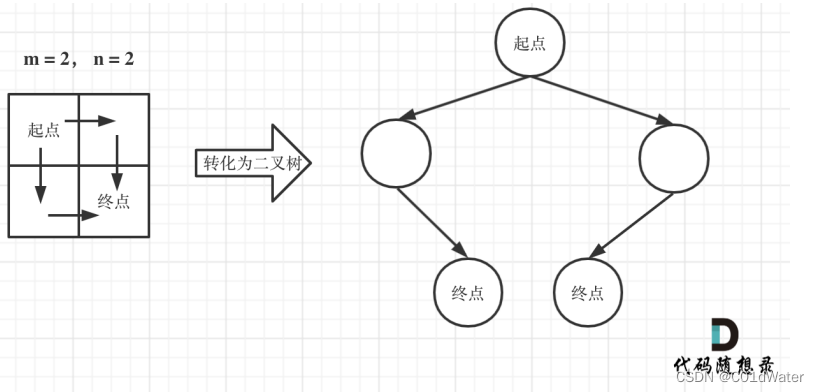
此时问题就可以转化成求二叉树的叶子节点个数。代码如下:
题解
class Solution {
int dfs(int i, int j, int m, int n) {
if (i > m || j > n) return 0;//终止条件
if (i == m && j == n) return 1;//找到一种方法
return dfs(i + 1, j, m, n) + dfs(i, j + 1, m, n);
}
public:
int uniquePaths(int m, int n) {
return dfs(1, 1, m, n);
}
};
不出意外的话超时了。分析一下时间复杂度,这棵树的深度为m+n-1,二叉树的节点为2^(m+n-1)-1,所以时间复杂度为指数量级。
11.5.2 动态规划
机器人从(0,0)出发,到(m-1,n-1)终点
1.确定dp数组和下标的含义
dp[i][j] 表示从(0,0)出发到(i,j)有多少种不同的路径。
2.确定递推公式
从题目和图中我们可以得知,dp[i][j]只有两种方向可以推导出来,一个是dp[i-1][j](向右移动一格),一个是dp[i][j-1](向下移动一格)。所以dp[i][j]=dp[i-1][j]+dp[i][j-1]。
3.dp数组的初始化
如何初始化呢?首先dp[i][0]=1,因为到(i,0)位置只有向下这一条路径。同理dp[0][j]=1。
4.确定遍历顺序
由递推公式可知,dp[i][j]是由左边和上边推导而来的,所以我们应该从左到右,从上到下遍历,即从左到右一层一层遍历。
5.举例推导dp数组,如图所示:
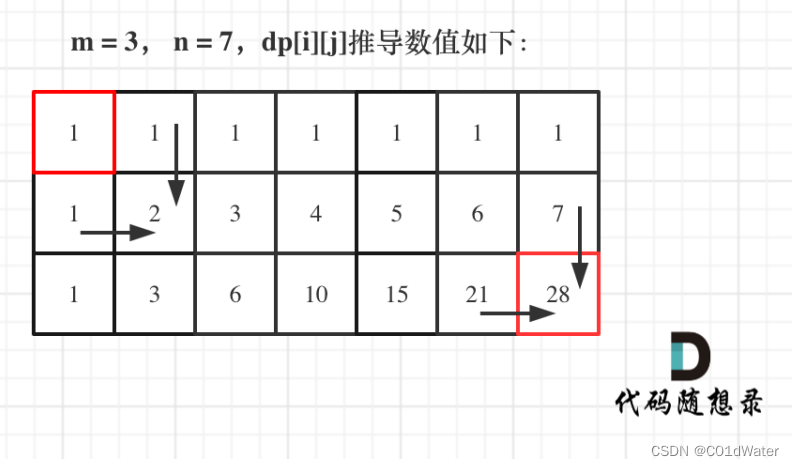
整体代码如下:
题解
class Solution {
public:
int uniquePaths(int m, int n) {
vector<vector<int>> dp(m, vector<int>(n, 0));//二维dp数组全部初始化为0
for (int i = 0; i < m; i++) dp[i][0] = 1;
for (int j = 0; j < n; j++) dp[0][j] = 1;
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {//i、j都要从1开始遍历否则(i-1)会越界
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
同样,我们仍不需要维护整个dp数组,只需维护一行(滚动数组)就可。
题解
class Solution {
public:
int uniquePaths(int m, int n) {
vector<int> dp(n, 1);//dp数组初始化为1(第一行)
for (int j = 1; j < m; j++) {//更新m-1次行
for (int i = 1; i < n; i++) {//更新每行
dp[i] += dp[i - 1];//等价于新dp[i]=旧dp[i](上面)+ dp[i-1](左边)
}
}
return dp[n - 1];
}
};
11.5.3 数论方法
从上图中,我们可以看出,我们从(0,0)走到(m,n)不管怎么走,都需要m+n-2步。而这m+n-2步一定有m-1步是要向下走的(或n-1步是向右走的)。于是我们可以抽象成组合问题,给你m+n-2个不同的数,随便取m-1个数,有几种取法。答案为C(m-1)(m+n-2)。
一想到这,估计有很多同学就立马把代码写出来了:
class Solution {
public:
int uniquePaths(int m, int n) {
int numerator = 1, denominator = 1;
int count = m - 1;
int t = m + n - 2;
while (count--) numerator *= (t--); // 计算分⼦,此时分⼦就会溢出
for (int i = 1; i <= m - 1; i++) denominator *= i; // 计算分⺟
return numerator / denominator;
}
};
很遗憾,这样不完全正确,因为求组合时,我们要防止int溢出。所以不能把算式中的分子分母算出来,再做除法。
正确的做法是,在计算分子时,应该不断除以分母。 代码如下:
题解
class Solution {
public:
int uniquePaths(int m, int n) {
long long numerator = 1;//分子
int denominator = m - 1;//分母
int count = m - 1;//分子需要乘m-1个
int t = m + n - 2;//从m+n-2开始乘
while (count--) {
numerator *= (t--);
while(denominator != 0 && numerator % denominator == 0) {//分母不为零且分子除以分母可以整除时做除法
numerator /= denominator;
denominator--;//除一次之后分母要减一
}
}
return numerator;//返回最后结果
}
};
小结:本节分别给出了深搜,动规,数论三种⽅法。深搜当然是超时了,顺便分析了⼀下使⽤深搜的时间复杂度,就可以看出为什么超时了。然后在给出动规的⽅法,依然是使⽤动规五部曲,这次我们就要考虑如何正确的初始化了,初始化和遍历顺序其实也很重要。
11.6 不同路径Ⅱ
力扣题号: 63.不同路径Ⅱ
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用 1 和 0 来表示。
示例 1:
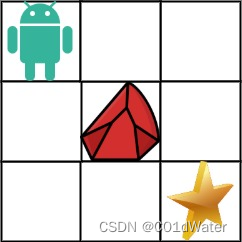
输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
输出:2
解释:3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
向右 -> 向右 -> 向下 -> 向下
向下 -> 向下 -> 向右 -> 向右
示例 2:

输入:obstacleGrid = [[0,1],[0,0]]
输出:1
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/unique-paths-ii
思路
上一节我们讲解了没有障碍的不同路径,这道题和那道题唯一的区别是有的地方会有障碍。(i,j)有障碍是什么意思呢?就是从(0,0)到达不了这个障碍节点,所以dp(i,j)=0。我们遇到障碍时不应该dp[i][j]=dp[i-1][j]+dp[i][j-1],而是应该保持dp[i][j]=0不变。
1.确定dp数组和下标的含义
dp[i][j表示从(0,0)出发到达(i,j)有dp[i][j]种不同的路径。
2.确定递推公式
递推公式和上一题一样,但是我们只有在obstacleGrid[i][j]=0时,才进行递推,否则就不变。
3.dp数组如何初始化
初始化和上一题有些不一样,当第一行和第一列有障碍后,其本身加上右方或下方的位置都应该初始化为0,而不是1。
4.确定遍历顺序
遍历顺序大体和上一题一样,只不过在遇到障碍节点时候应该跳过,让这个位置的dp数组值保持0不变。
5.举例推导dp数组
就拿示例1来推导:
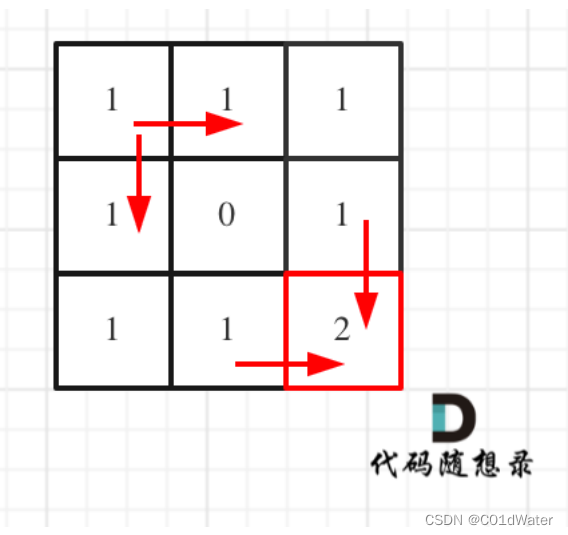
整体代码如下:
题解
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m = obstacleGrid.size();
int n = obstacleGrid[0].size();
vector<vector<int>> dp(m, vector<int>(n, 0));//全部初始为0
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) dp[i][0] = 1;//一旦遇到obstacleGrid[i][0]==1的情况就终止循环
for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++) dp[0][j] = 1;//最后的结果是只初始化为1障碍之左或之上的位置
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] == 1) continue;//跳过这个位置,让dp[i][j]保持0,代表这个位置不能到达
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
是不是接下来就要将不维护整个dp数组的解法了?可惜并不是。因为要考虑到障碍,如果把这些障碍都压缩到一行,结果一定就不一样了。
小结:本题是62.不同路径的障碍版,整体思路⼤体⼀致。但就算是做过62.不同路径,在做本题也会有感觉遇到障碍⽆从下⼿。其实只要考虑到,遇到障碍dp[i][j]保持0就可以了。也有⼀些⼩细节,例如:初始化的部分,很容易忽略了障碍之后应该都是0的情况。
11.7 整数拆分
力扣题号:343.整数拆分
给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k >= 2 ),并使这些整数的乘积最大化。
返回 你可以获得的最大乘积 。
示例 1:
输入: n = 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1。
示例 2:
输入: n = 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
提示:
2 <= n <= 58
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/integer-break
11.7.1 动态规划
思路
动态规划的精髓是把问题分解成几个子问题,这道题就可以。整数乘积的每个乘数可以看作是由几个数相乘得来,每个数又可以看作是几个数的乘积做得。。。
1.确定dp数组和下标的含义
分解整数i,可以得到的最大乘积为dp[i]。
2.确定递推公式
dp[i]的最大乘积如何得到呢?我们可以把i拆分成j和i-j。于是我们就有两种方式得到dp[i]了:一个是j*(i-j);一个是jdp[i-j],相当于再次拆分i-j。我们应该取这两个中的最大值。
有的同学会有疑问,为什么j不用再次拆分呢?比如说dp[j](i-j)和dp[j]dp[i-j]。这是因为j是从1开始遍历的,在遍历的过程中已经把拆分j的情况计算过了。
另外递推公式中不仅要取j(i-j),j*dp[i-j]的最大值,我们还要取dp[i]和这两个之中最大值的最大值。因为,我们是从j=1开始拆解的,要取各个拆解的最大值。即dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
3.dp数组如何初始化
有的题解给出了dp[0]和dp[1]的初始化值为1,解释比较牵强。严格意义上来说,这两个都不应该初始化,是没有意义的数值,我们应该直接从dp[2]=1开始初始化,从2往后递推。这是没有异议的。
4.确定遍历顺序
dp{i]的值依靠dp[i-j],所以我们的遍历顺序一定是从前往后。
5.举例推导dp数组
以n=10为例子:
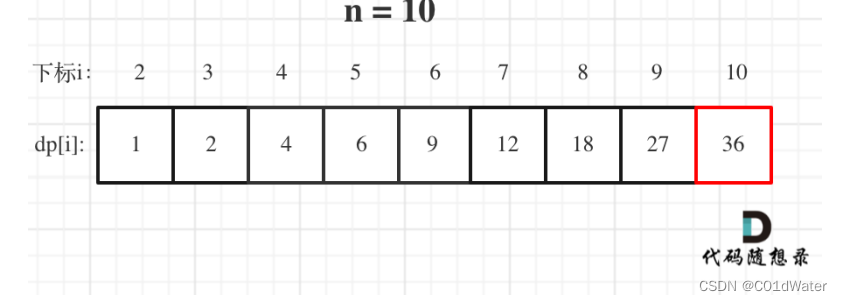
整体代码如下:
题解
class Solution {
public:
int integerBreak(int n) {
vector<int> dp(n + 1);
dp[2] = 1;
for (int i = 3; i <= n; i++) {
for (int j = 1; j < i; j++) {//将i拆解为i-j和j,j从1~i-2,为什么不到i-1呢?j到i-1也可以提交也可以通过
//因为j=i-1时,要求dp[1]*i-1,dp[1]是没有定义的(0)0*任何数都是0
dp[i] = max(dp[i],max(dp[i - j] * j, (i - j) * j));
}
}
return dp[n];
}
};
11.7.2 贪心
本题也可以用贪心算法,将n拆解为若干个3,如果剩下的是4,则保留4,然后相乘。
数学证明:
1.任何数都可拆解为若干个3和一个2或若干个3和一个1。
2.根据乘积不等式:
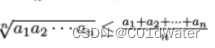
当且仅当a1=a2=a3…=an时等号成立,乘积取到最大值。根据1可知如果我们拆出来k个3和一个1,则应该取k-1个3和一个4。这样能保证a1…an尽量相等,取最大值。
整体代码如下:
题解
class Solution {
public:
int integerBreak(int n) {
if (n == 2) return 1;
if (n == 3) return 2;
if (n == 4) return 4;
int result = 1;
while (n > 4) {
result *= 3;
n -= 3;
}
//此时n<=4,n=4就直接乘,不再拆成3和1;另外n不会等于1,因为n要等于1,得从4再减3
return result *= n;//
}
};
小结:其实这道题⽬的递推公式并不好想,⽽且初始化的地⽅也很有讲究,本书作者在写本题的时候⼀开始写的代码是这样的:
class Solution {
public:
int integerBreak(int n) {
if (n <= 3) return 1 * (n - 1);
vector<int> dp(n + 1, 0);
dp[1] = 1;
dp[2] = 2;
dp[3] = 3;
for (int i = 4; i <= n ; i++) {
for (int j = 1; j < i - 1; j++) {
dp[i] = max(dp[i], dp[i - j] * dp[j]);
}
}
return dp[n];
}
};
这个代码也是可以过的!
在解释递推公式的时候,也可以解释通,dp[i] 就等于 拆解i - j的最⼤乘积 * 拆解j的最⼤乘积。 看起来没⽑病!
但是在解释初始化的时候,就发现⾃相⽭盾了,dp[1]为什么⼀定是1呢?根据dp[i]的定义,dp[2]也不应该是2啊。
但如果递归公式是 dp[i] = max(dp[i], dp[i - j] * dp[j]);,就⼀定要这么初始化。递推公式没⽑病,但初始化解释不通!
虽然代码在初始位置有⼀个判断if (n <= 3) return 1 * (n - 1);,保证n<=3 结果是正确的,但代码后⾯⼜要给dp[1]赋值1 和 dp[2] 赋值 2,这其实就是⾃相⽭盾的代码,违背了dp[i]的定义!
我举这个例⼦,其实就说做题的严谨性,上⾯这个代码也可以AC,⼤体上⼀看好像也没有⽑病,递推公式也说得过去,但是仅仅是恰巧过了⽽已。
11.8 不同的二叉搜索树
力扣题号:96.不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
示例 1:
输入:n = 3
输出:5
示例 2:
输入:n = 1
输出:1
提示:
1 <= n <= 19
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/unique-binary-search-trees
思路
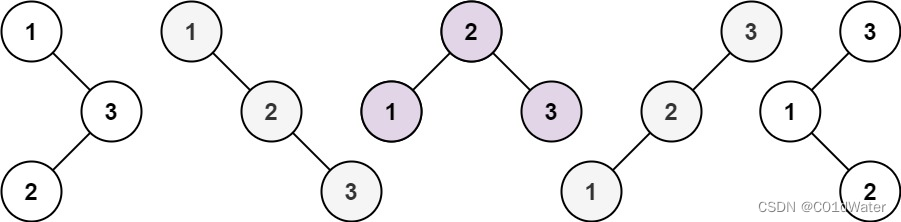
许多同学看完题目都是懵逼的状态,这要怎么统计啊。我们先举几个例子,画画图,看看有没有什么规律。
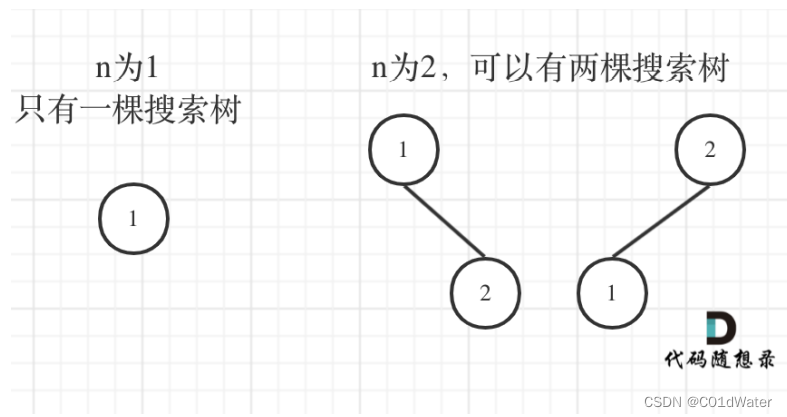
n为1时,只有一棵树;n为2时,由两颗树,很直观。
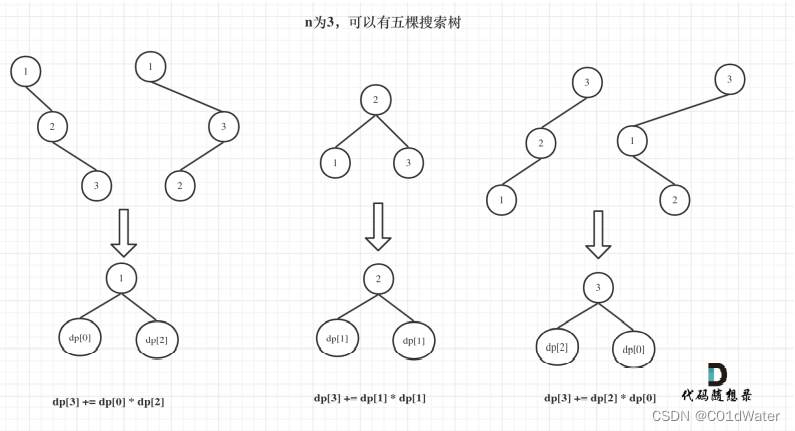
n为3时:
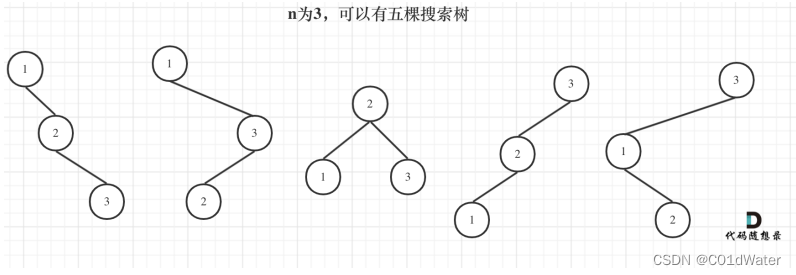
当1为头结点的时候,其右⼦树有两个节点,看这两个节点的布局,是不是和 n 为2的时候两棵树的布局是⼀样的啊!
(可能有同学问了,这布局不⼀样啊,节点数值都不⼀样。别忘了我们就是求不同树的数量,并不⽤把搜索树都列出来,所以不⽤关⼼其具体数值的差异)
当3为头结点的时候,其左⼦树有两个节点,看这两个节点的布局,是不是和n为2的时候两棵树的布局也是⼀样的啊!
当2位头结点的时候,其左右⼦树都只有⼀个节点,布局是不是和n为1的时候只有⼀棵树的布局也是⼀样的啊!
发现到这⾥,其实我们就找到的重叠⼦问题了,其实也就是发现可以通过dp[1] 和 dp[2] 来推导出来dp[3]的某种⽅式
思考到这⾥,这道题⽬就有眉⽬了。
dp[3],就是 元素1为头结点搜索树的数量 + 元素2为头结点搜索树的数量 + 元素3为头结点搜索树的数量
而元素1为头结点搜索树的数量 = 右⼦树有2个元素的搜索树数量 * 左⼦树有0个元素的搜索树数量
元素2为头结点搜索树的数量 = 右⼦树有1个元素的搜索树数量 * 左⼦树有1个元素的搜索树数量
元素3为头结点搜索树的数量 = 右⼦树有0个元素的搜索树数量 * 左⼦树有2个元素的搜索树数量
有2个元素的搜索树数量就是dp[2]。有1个元素的搜索树数量就是dp[1]。有0个元素的搜索树数量就是dp[0]。
所以dp[3] = dp[2] * dp[0] + dp[1] * dp[1] + dp[0] * dp[2] :
1.确定dp数组及下标的含义
dp[i]为1到i节点组成的二叉搜索树的个数。也可以理解为由1-i不同元素为头节点组成的二叉搜索树的个数。
2.确定递推公式
dp[i] += dp[以j为头节点左子树节点数量]*dp[以j为头节点右子树节点数量]。j相当于头节点元素值,应该从1遍历到i为止。所以递推公式:dp[i] += dp[j-1]*dp[i-j]。其中j-1是以j为头节点时左子树节点的数量(1、2、3、j-1),i-j是以j为头节点时右子树节点的数量(j+1、j+2、i)
3.dp数组如何初始化
初始化,只需初始化dp[0]即可,因为之后的推导,都是从dp[0]开始的。从定义上来说,空节点也是一棵二叉树,dp[0]=1;从递推公式上来说,如果左子树的节点数为0,实际计算的时候应该×1,而不是×0,否则结果就是0了。综上所述,dp[0]应该初始化为1。
4.确定遍历顺序
从递推公式可以看出,dp[i]的值是由i之前的dp[j-1]和dp[i-j]来推导的,所以应该从1开始往后遍历到n。
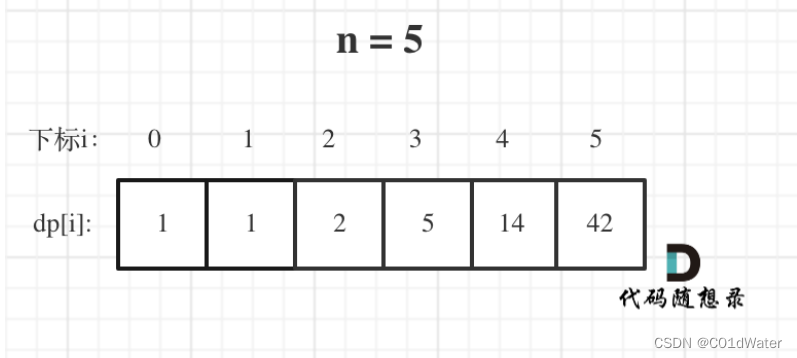
5.举例推导dp数组
以n=5时为例:
整体代码如下:
题解
class Solution {
public:
int numTrees(int n) {
vector<int> dp(n + 1, 0);
dp[0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= i; j++) {
dp[i] += dp[j - 1] * dp[i - j];
}
}
return dp[n];
}
};
小结:这道题⽬虽然在⼒扣上标记是中等难度,但可以算是困难了!⾸先这道题想到⽤动规的⽅法来解决,就不太好想,需要举例,画图,分析,才能找到递推的关系。然后难点就是确定递推公式了,如果把递推公式想清楚了,遍历顺序和初始化,就是⾃然⽽然的事情了。
可以看出我依然还是⽤动规五部曲来进⾏分析,会把题⽬的⽅⽅⾯⾯都覆盖到!
⽽且具体这五部分析是我⾃⼰平时总结的经验,找不出来第⼆个的,可能过⼀阵⼦ 其他题解也会有动规
五部曲了,哈哈。当时我在⽤动规五部曲讲解斐波那契的时候,⼀些录友和我反应,感觉讲复杂了。其实当时我⼀直强调简单题是⽤来练习⽅法论的,并不能因为简单我就代码⼀甩,简单解释⼀下就完事了。可能当时⼀些同学不理解,现在⼤家应该感受⽅法论的重要性了。
11.9 0-1背包理论基础
背包问题的经典资料当然是:背包九讲。在公众号「代码随想录」后台回复:背包九讲,就可以获得背包九讲的PDF。
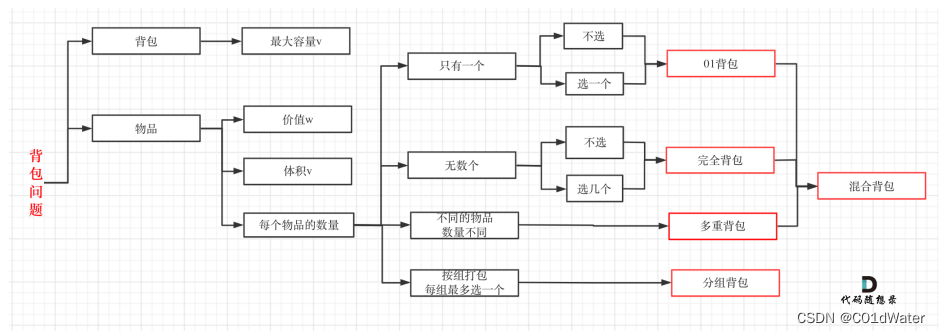
但说实话,背包九讲对于⼩⽩来说确实不太友好,看起来还是有点费劲的,⽽且都是伪代码理解起来也吃⼒,对于⾯试的话,其实掌握01背包,和完全背包,就够⽤了,最多可以再来⼀个多重背包。如果这⼏种背包,分不清,我这⾥画了⼀个图,如下:
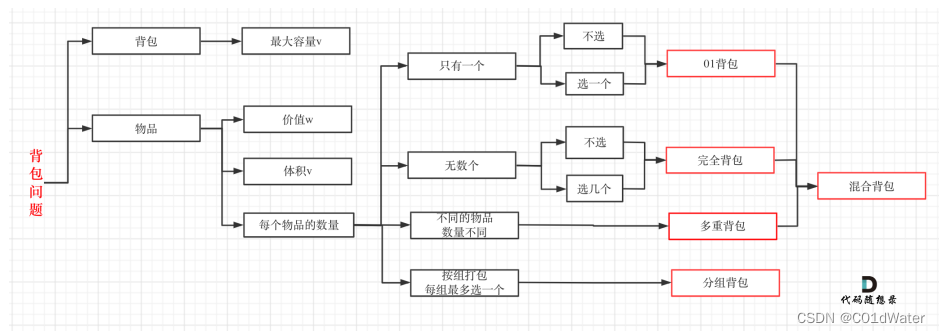
⾄于背包九讲其其他背包,⾯试⼏乎不会问,都是竞赛级别的了,leetcode上连多重背包的题⽬都没有,所以题库也告诉我们,01背包和完全背包就够⽤了。
⽽完全背包⼜是也是01背包稍作变化⽽来,即:完全背包的物品数量是⽆限的。所以背包问题的理论基础重中之重是01背包,⼀定要理解透!leetcode上没有纯01背包的问题,都是01背包应⽤⽅⾯的题⽬,也就是需要转化为01背包问题。所以我先通过纯01背包问题,把01背包原理讲清楚,后续再讲解leetcode题⽬的时候,重点就是讲解如何转化为01背包问题了。
11.9.0 0-1背包
有N件物品和⼀个最多能被重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能⽤⼀次,求解将哪些物品装⼊背包⾥物品价值总和最⼤。
这是标准的背包问题,以⾄于很多同学看了这个⾃然就会想到背包,甚⾄都不知道暴⼒的解法应该怎么解了。
这样其实是没有从底向上去思考,⽽是习惯性想到了背包,那么暴⼒的解法应该是怎么样的呢?
每⼀件物品其实只有两个状态,取或者不取,所以可以使⽤回溯法搜索(二叉树)出所有的情况,那么时间复杂度就是O(2^n),这⾥的n表示物品数量。所以暴⼒的解法是指数级别的时间复杂度。进⽽才需要动态规划的解法来进⾏优化!
在下⾯的讲解中,我举⼀个例⼦:背包最⼤重量为4。物品为: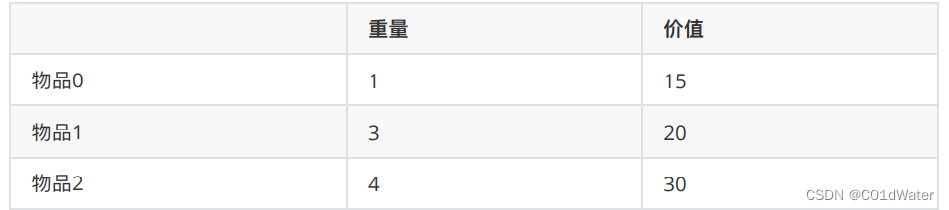
问背包能背的物品最⼤价值是多少?
11.9.1 二维dp数组
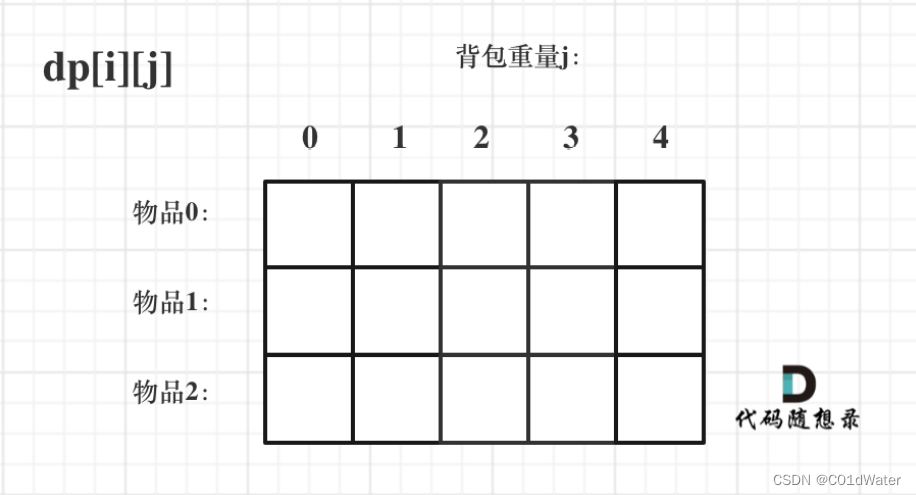
1.确定dp数组及下标的含义
对于背包问题,有⼀种写法, 是使⽤⼆维数组,即dp[i][j] 表示从下标为[0-i]的物品⾥任意取,放进容量为j的背包,价值总和最⼤是多少。
2.确定递推公式
再回顾⼀下dp[i][j]的含义:从下标为[0-i]的物品⾥任意取,放进容量为j的背包,价值总和最⼤是多少。那么可以有两个⽅向推出来dp[i][j]。
- 由dp[i - 1][j]推出,即背包容量为j,⾥⾯不放物品i的最⼤价值,此时dp[i][j]就是dp[i - 1][j]
- 由dp[i - 1][j - weight[i]]推出,dp[i - 1][j - weight[i]] 为背包容量为j - weight[i]的时候不放物品i的最⼤价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最⼤价值。
所以递归公式为:dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
3.dp数组如何初始化
关于初始化,⼀定要和dp数组的定义吻合,否则到递推公式的时候就会越来越乱。
⾸先从dp[i][j]的定义出发,如果背包容量j为0的话,即dp[i][0],⽆论是选取哪些物品,背包价值总和⼀定为0。如图:
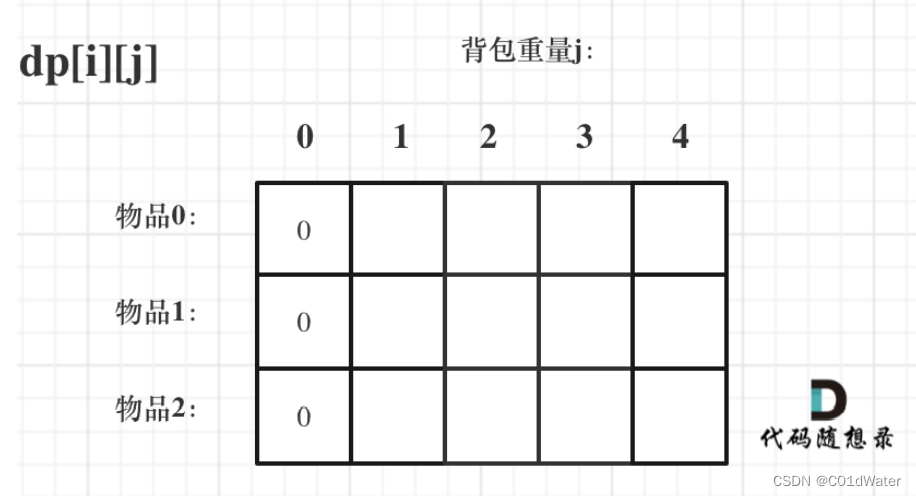
再看其他情况:状态转移⽅程 dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出i 是由 i-1 推导出来,那么i为0的时候就⼀定要初始化。dp[0][j],即:i为0,存放编号0的物品的时候,各个容量的背包所能存放的最⼤价值。
那么很明显当 j < weight[0]的时候,dp[0][j] 应该是 0,因为背包容量⽐编号0的物品重量还⼩。当j >= weight[0]时,dp[0][j] 应该是value[0],因为背包容量放⾜够放编号0物品。
此时dp数组初始化情况如图所示:
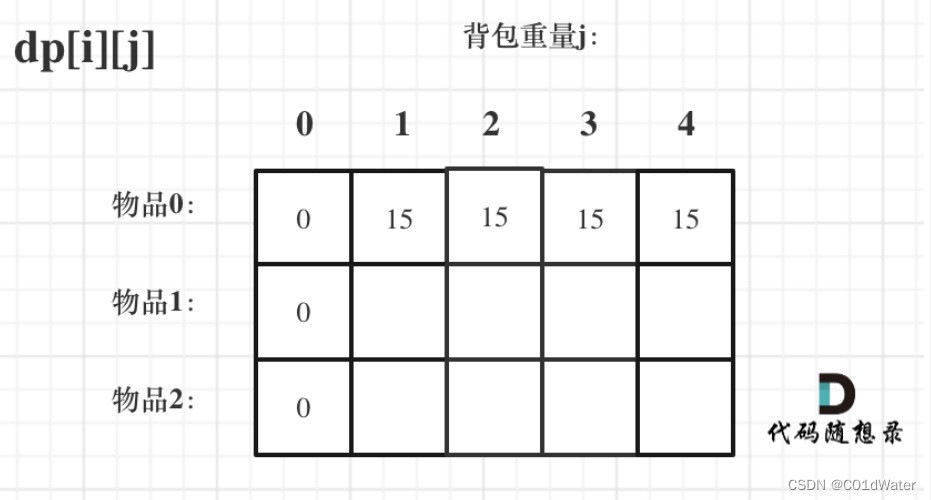
dp[0][j] 和 dp[i][0] 都已经初始化了,那么其他下标应该初始化多少呢?其实从递归公式: dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出dp[i][j] 是由左方和左上⽅数值推导出来了,那么 其他下标初始为什么数值都可以,因为都会被覆盖。初始-1,初始-2,初始100,都可以!但只不过⼀开始就统⼀把dp数组统⼀初始为0,更⽅便⼀些。如图:
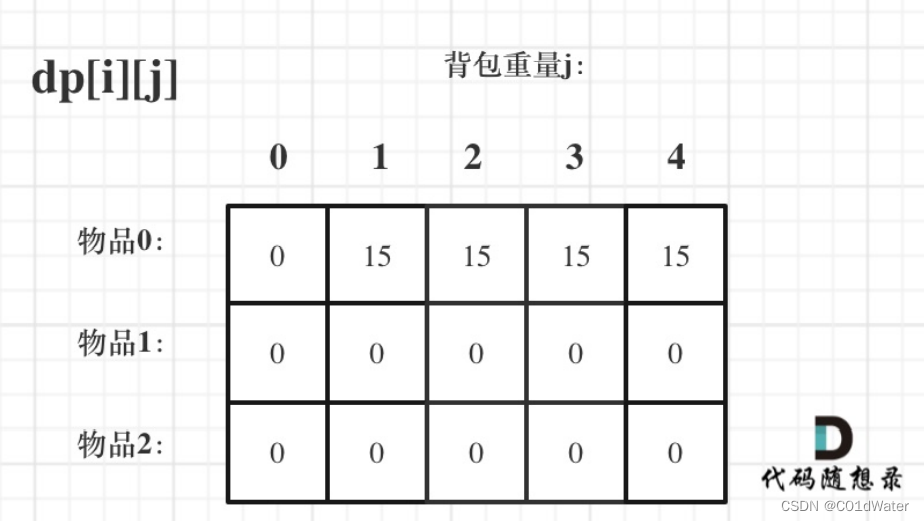
费了这么⼤的功夫,才把如何初始化讲清楚,相信不少同学平时初始化dp数组是凭感觉来的,但有时候感觉是不靠谱的。
4.确定遍历顺序
在上图中,可以看出,有两个遍历的维度:物品与背包重量。那么问题来了,先遍历 物品还是先遍历背包重量呢?其实都可以!! 但是先遍历物品更好理解。
// weight数组的⼤⼩ 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j]; // 这个是为了展现dp数组⾥元素的变化
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
先遍历背包,再遍历物品,也是可以的!
// weight数组的⼤⼩ 就是物品个数
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
for(int i = 1; i < weight.size(); i++) { // 遍历物品
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
为什么也是可以的呢?要理解递归的本质和递推的⽅向。
dp[i-1][j]和dp[i - 1][j - weight[i]] 都在dp[i][j]的左上⻆⽅向(包括正上⽅向),虽然两个for循环遍历的次序不同,但是dp[i][j]所需要的数据就是左上⻆,根本不影响dp[i][j]公式的推导!
但先遍历物品再遍历背包这个顺序更好理解。其实背包问题⾥,两个for循环的先后循序是⾮常有讲究的,理解遍历顺序其实⽐理解推导公式难多了。
5. 举例推导dp数组
来看⼀下对应的dp数组的数值,如图:
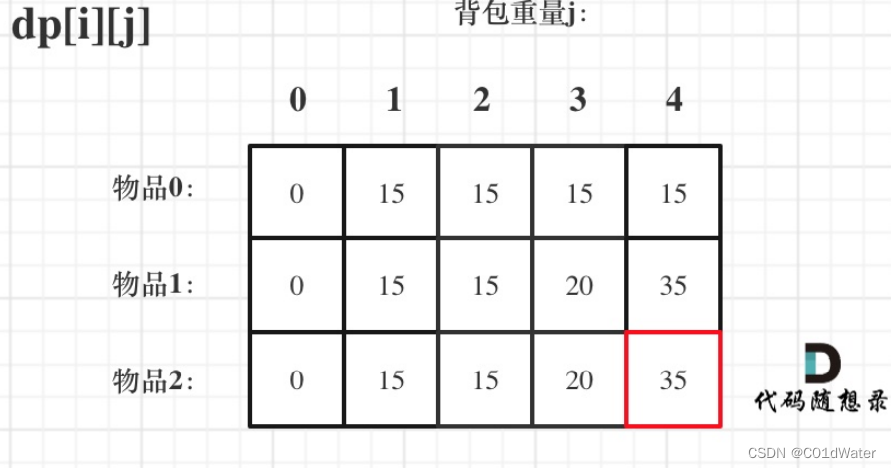
最终结果就是dp[2][4]。建议⼤家此时⾃⼰在纸上推导⼀遍,看看dp数组⾥每⼀个数值是不是这样的。
做动态规划的题⽬,最好的过程就是⾃⼰在纸上举⼀个例⼦把对应的dp数组的数值推导⼀下,然后在动⼿写代码!很多同学做dp题⽬,遇到各种问题,然后凭感觉东改改⻄改改,怎么改都不对,或者稀⾥糊涂就改过了。主要就是⾃⼰没有动⼿推导⼀下dp数组的演变过程,如果推导明⽩了,代码写出来就算有问题,只要把dp数组打印出来,对⽐⼀下和⾃⼰推导的有什么差异,很快就可以发现问题了。
完整代码如下:
#include <iostream>
#include <vector>
using namespace std;
void test_wei_beg_problem(vector<int>& weight, vector<int>& value, int begweight) {
vector<vector<int>> dp(weight.size() + 1, vector<int>(begweight + 1, 0));//dp数组初始化为0
for (int j = weight[0]; j <= begweight; j++) dp[0][j] = value[0];//dp数组第一行初始化,背包放入物品0的价值,容量小于物理0重量的则仍保持0(装不下)
for (int i = 1; i < weight.size(); i++) {
for (int j = 0; j < begweight + 1; j++) {
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
cout << dp[weight.size() - 1][begweight] << endl;
}
int main() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int begweight = 4;
test_wei_beg_problem(weight, value, begweight);
}
执行结果为:
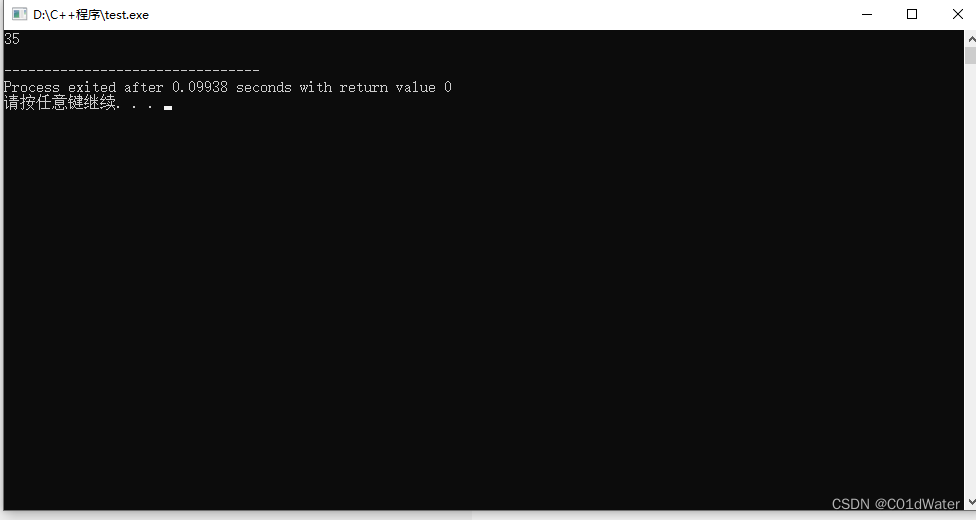
这样打印出来的dp数组是完全的。也可以换一种遍历方式,当j<weight[i]时,不做任何动作,让dp[i][j]还等于0:
// 遍历过程
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
if (j - weight[i] >= 0) {
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
}
这样打印出来的dp数组是不完全的,数组中的0是用不上的:
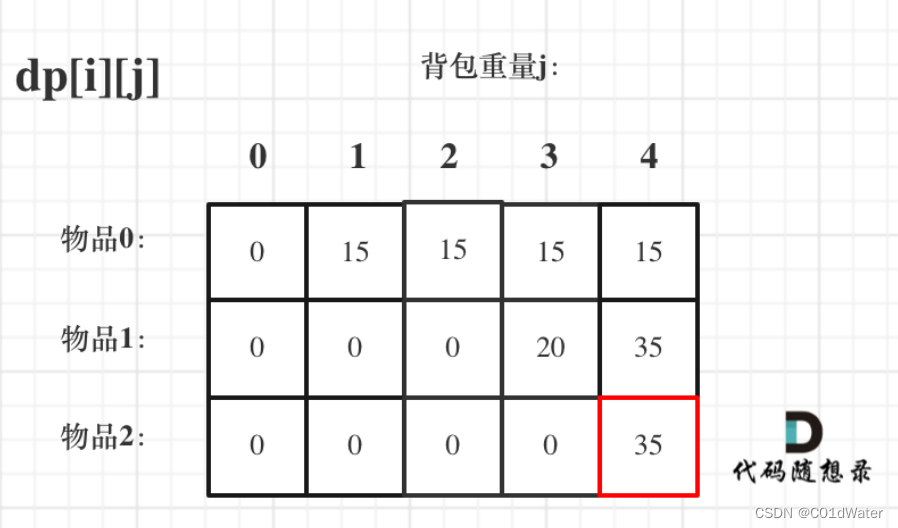
小结:讲了这么多才刚刚把⼆维dp的01背包讲完,这⾥⼤家其实可以发现最简单的是推导公式了,推导公式估计看⼀遍就记下来了,但难就难在如何初始化和遍历顺序上。可能有的同学并没有注意到初始化 和 遍历顺序的重要性,我们后⾯做⼒扣上背包⾯试题⽬的时候,⼤家就会感受出来了。
11.9.2 一维dp数组(滚动数组)
一维dp数组又叫滚动数组,其实在前⾯的题⽬中我们已经⽤到过滚动数组了,就是把⼆维dp降为⼀维dp,⼀些录友当时还表示⽐较困惑。那么我们通过01背包,来彻底讲⼀讲滚动数组!
接下来还是⽤如下这个例⼦来进⾏讲解,背包最⼤重量为4,物品为:
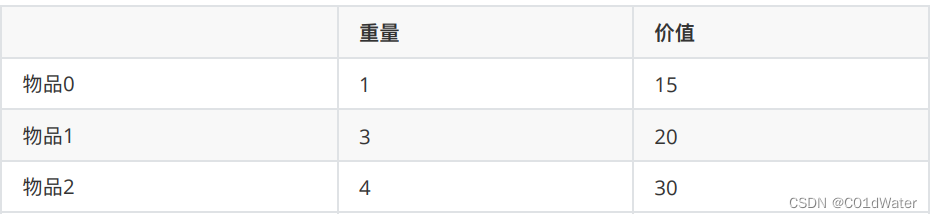
问背包能背的物品最⼤价值是多少?
对于背包问题其实状态都是可以压缩的。在使⽤⼆维数组的时候,递推公式:dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);其实可以发现如果把dp[i - 1]那⼀层拷⻉到dp[i]上,表达式完全可以是:dp[i][j] = max(dp[i][j], dp[i][j- weight[i]] + value[i]);
于其把dp[i - 1]这⼀层拷⻉到dp[i]上,不如只⽤⼀个⼀维数组了,只⽤dp[j](⼀维数组,也可以理解是⼀个滚动数组)。
这就是滚动数组的由来,需要满⾜的条件是上⼀层可以重复利⽤,直接拷⻉到当前层。
读到这⾥估计⼤家都忘了 dp[i][j]⾥的i和j表达的是什么了,i是物品,j是背包容量。dp[i][j] 表示从下标为[0-i]的物品⾥任意取,放进容量为j的背包,价值总和最⼤是多少。⼀定要时刻记住这⾥i和j的含义,要不然很容易看懵了。
1.确定dp数组及下标的含义
在一维dp数组中,dp[j]表示容量为j的背包,所背的 物品价值最大为dp[j]。
2.确定一维dp数组的递推公式
dp[j]为容量为j的背包所背的最⼤价值,那么如何推导dp[j]呢?dp[j]可以通过dp[j - weight[j]]推导出来,dp[j -weight[i]]表示容量为j - weight[i]的背包所背的最⼤价值。dp[j - weight[i]] + value[i] 表示 容量为 j - 物品i重量 的背包 加上 物品i的价值。(也就是容量为j的背包,放⼊物品i了之后的价值即:dp[j])此时dp[j]有两个选择,⼀个是取⾃⼰dp[j],⼀个是取dp[j - weight[i]] + value[i],指定是取最⼤的,毕竟是求最⼤价值,所以递归公式为:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);可以看出相对于⼆维dp数组的写法,就是把dp[i][j]中i的维度去掉了。
3.一维dp数组如何初始化
关于初始化,⼀定要和dp数组的定义吻合,否则到递推公式的时候就会越来越乱。dp[j]表示:容量为j的背包,所背的物品价值可以最⼤为dp[j],那么dp[0]就应该是0,因为背包容量为0所背的物品的最⼤价值就是0。那么dp数组除了下标0的位置,初始为0,其他下标应该初始化多少呢?看⼀下递归公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);dp数组在推导的时候⼀定是取价值最⼤的数,如果题⽬给的价值都是正整数那么⾮0下标都初始化为0就可以了,如果题⽬给的价值有负数,那么⾮0下标就要初始化为负⽆穷。这样才能让dp数组在递归公式的过程中取的最⼤的价值,⽽不是被初始值覆盖了。
4.一维dp数组遍历顺序
代码如下:
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
这⾥⼤家发现和⼆维dp的写法中,遍历背包的顺序是不⼀样的!⼆维dp遍历的时候,背包容量是从⼩到⼤,⽽⼀维dp遍历的时候,背包是从⼤到⼩。为什么呢?倒叙遍历是为了保证物品i只被放⼊⼀次!如果使用正序遍历,那么物品0就会被重复加入多次。
举⼀个例⼦:物品0的重量weight[0] = 1,价值value[0] = 15。如果正序遍历dp[1] = dp[1 - weight[0]] + value[0] = 15,dp[2] = dp[2 - weight[0]] + value[0] = 30,此时dp[2]就已经是30了,意味着物品0,被放⼊了两次,所以不能正序遍历。 为什么倒叙遍历,就可以保证物品只放⼊⼀次呢?倒叙就是先算dp[2],dp[2] = dp[2 - weight[0]] + value[0] = 15 (dp数组已经都初始化为0),dp[1] = dp[1 - weight[0]] + value[0] = 15,所以从后往前循环,每次取得状态不会和之前取得状态重合,这样每种物品就只取⼀次了。
那么问题⼜来了,为什么⼆维dp数组历的时候不⽤倒叙呢?因为对于⼆维dp,dp[i][j]都是通过上⼀层即dp[i - 1][j]计算⽽来,本层的dp[i][j]并不会被覆盖!(二维dp数组都是由上方或左上方得来的,而一维dp数组正序遍历是由正左方而来,左上方已经修改过了)
再来看看两个嵌套for循环的顺序,代码中是先遍历物品嵌套遍历背包容量,那可不可以先遍历背包容量嵌套遍历物品呢?不可以!因为⼀维dp的写法,背包容量⼀定是要倒序遍历(原因上⾯已经讲了),如果遍历背包容量放在上⼀层,那么每个dp[j]就只会放⼊⼀个物品,即:背包⾥只放⼊了⼀个物品。() 这⾥如果读不懂,就在回想⼀下dp[j]的定义,或者就把两个for循环顺序颠倒⼀下试试!所以⼀维dp数组的背包在遍历顺序上和⼆维其实是有很⼤差异的!这⼀点⼤家⼀定要注意。
5.举例推导dp数组,一维dp数组,分别用物品0,物品1,物品2来遍历背包,最终结果如下:
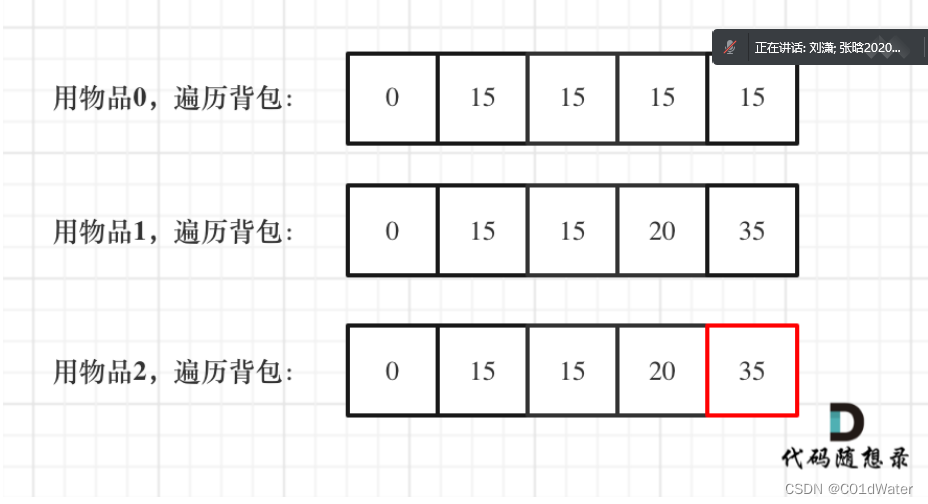
整体代码如下:
#include <iostream>
#include <vector>
using namespace std;
void test_wei_beg_problem(vector<int>& weight, vector<int>& value, int begweight) {
vector<int> dp(begweight + 1);
for (int i = 0; i < weight.size(); i++) {
for (int j = begweight; j >= weight[i]; j--) {
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
for (int k : dp) cout<< k << " ";//打印每遍历一个物品时的dp数组
cout << endl;
}
cout << dp[begweight] << endl;//打印最终结果
}
int main() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int begweight = 4;
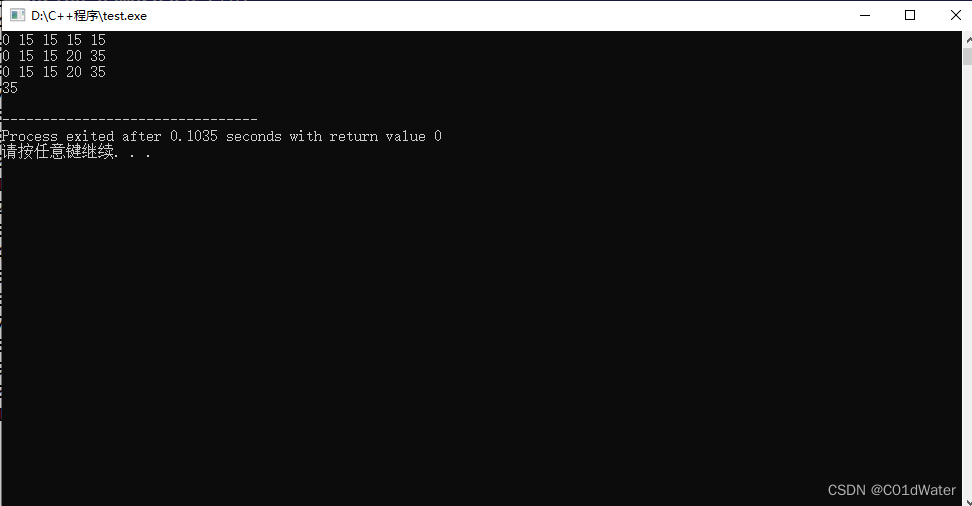
test_wei_beg_problem(weight, value, begweight);
}
结果如下:
假如我们先遍历背包容量,再遍历物品,那么每个dp[j]代表的就是只放一个物品,其最大价值是多少。代码如下:
#include <iostream>
#include <vector>
using namespace std;
void test_wei_beg_problem(vector<int>& weight, vector<int>& value, int begweight) {
vector<int> dp(begweight + 1);
for (int j = begweight; j >= 0; j--) {//先遍历背包
for (int i = 0; i < weight.size(); i++) {//后遍历物品
if(j >= weight[i]) dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
for (int k : dp) cout << k << " ";
cout << endl;
}
cout << dp[begweight] << endl;
}
int main() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int begweight = 4;
test_wei_beg_problem(weight, value, begweight);
}
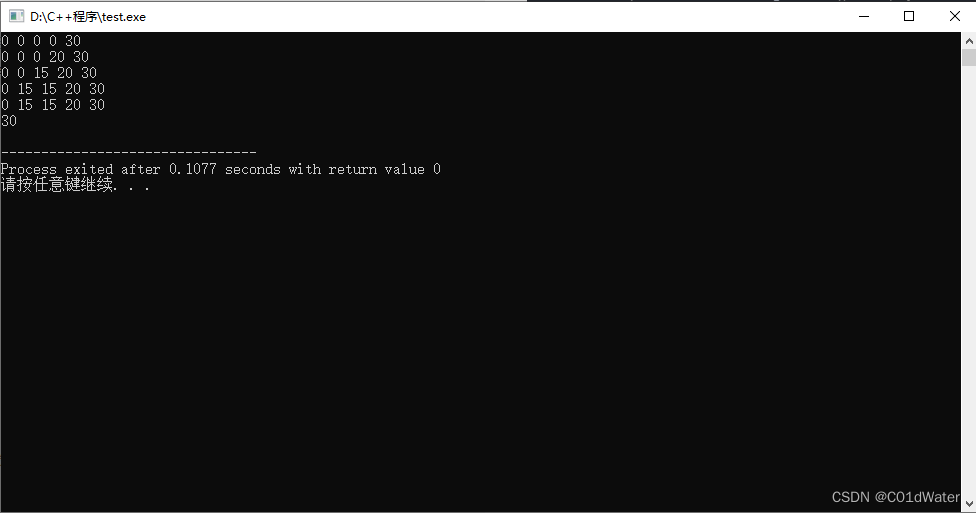
通过打印每遍历一个背包容量的dp数组我们可以得知,dp[j]对应的就是j容量背包只放一个物品时,最大价值是多少。这与我们要求的dp[j]:j容量背包放若干个物品后,其最大价值是多少并不一样。所以只能先遍历物品后遍历背包。
可以看出,⼀维dp 的01背包,要⽐⼆维简洁的多! 初始化 和 遍历顺序相对简单了。所以我倾向于使⽤⼀维dp数组的写法,⽐较直观简洁,⽽且空间复杂度还降了⼀个数量级!在后⾯背包问题的讲解中,我都直接使⽤⼀维dp数组来进⾏推导。
小结:以上的讲解可以开发⼀道⾯试题⽬(毕竟⼒扣上没原题)。就是本⽂中的题⽬,要求先实现⼀个纯⼆维的01背包,如果写出来了,然后再问 为什么两个for循环的嵌套顺序这么写?反过来写⾏不⾏?再讲⼀讲初始化的逻辑。然后要求实现⼀个⼀维数组的01背包,最后再问,⼀维数组的01背包,两个for循环的顺序反过来写⾏不⾏?为什么? 注意以上问题都是在候选⼈把代码写出来的情况下才问的。
就是纯01背包的题⽬,都不⽤考01背包应⽤类的题⽬就可以看出候选⼈对算法的理解程度了。相信⼤家读完这篇⽂章,应该对以上问题都有了答案!此时01背包理论基础就讲完了,我⽤了两篇⽂章把01背包的dp数组定义、递推公式、初始化、遍历顺序从⼆维数组到⼀维数组统统深度剖析了⼀遍,没有放过任何难点。⼤家可以发现其实信息量还是挺⼤的。如果本篇的内容都理解了,后⾯我们在做01背包的题⽬,就会发现⾮常简单了。不⽤再凭感觉或者记忆去写背包,⽽是有⾃⼰的思考,了解其本质,代码的⽅⽅⾯⾯都在⾃⼰的掌控之中。即使代码没有通过,也会有⾃⼰的逻辑去debug,这样就思维清晰了。
11.10 分割等和子集
力扣题号:416.分割等和子集
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
示例 1:
输入:nums = [1,5,11,5]
输出:true
解释:数组可以分割成 [1, 5, 5] 和 [11] 。
示例 2:
输入:nums = [1,2,3,5]
输出:false
解释:数组不能分割成两个元素和相等的子集。
提示:
1 <= nums.length <= 200
1 <= nums[i] <= 100
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/partition-equal-subset-sum
11.10.1 暴力解法
思路
只要求分为两个等和子集,我们可以先将nums总和算出来sum然后sum/2就是每个子集的和。那么只要找到集合⾥能够出现 sum / 2 的⼦集总和,就算是可以分割成两个相同元素和⼦集了。本题是可以⽤回溯暴⼒搜索出所有答案的,但最后超时了,也不想再优化了,放弃回溯,直接上01背包吧。
另外这道题目初看,和如下两道题几乎是一样的,大家可以用回溯法,解决如下两题:698.划分为k个相等的⼦集、473.⽕柴拼正⽅形。
11.10.2 0-1背包
回顾一些背包问题:有N件物品和⼀个最多能被重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能⽤⼀次,求解将哪些物品装⼊背包⾥物品价值总和最⼤。
背包问题有多种背包⽅式,常⻅的有:01背包、完全背包、多重背包、分组背包和混合背包等等。
首先要分清是什么背包:即⼀个商品如果可以重复多次放⼊是完全背包,⽽只能放⼊⼀次是01背包,写法还是不⼀样的。要明确本题中我们要使⽤的是01背包,因为元素我们只能⽤⼀次。
回归主题:⾸先,本题要求集合⾥能否出现总和为 sum / 2 的⼦集。那么来⼀⼀对应⼀下本题,看看背包问题如果来解决。只有确定了如下四点,才能把01背包问题套到本题上来。
- 背包的体积为sum / 2
- 背包要放⼊的物品(集合⾥的元素)重量为 元素的数值,价值也为元素的数值
- 背包如果正好装满,说明找到了总和为 sum / 2 的⼦集。
- 背包中每⼀个元素是不可重复放⼊。
1.确定dp数组及下标含义
dp[j]表示:容量为j的背包,所装的物品价值最大为dp[j]。套到本题上就是,dp[j]表示:子集和容量为j,最大可以凑成j的子集总和。
2.确定递推公式
01背包的递推公式为:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]); 本题,相当于背包⾥放⼊数值,那么物品i的重量是nums[i],其价值也是nums[i]。所以递推公式:dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
3.dp数组如何初始化
在01背包,⼀维dp如何初始化,已经讲过,从dp[j]的定义来看,⾸先dp[0]⼀定是0。**如果如果题⽬给的价值都是正整数那么⾮0下标都初始化为0就可以了,如果题⽬给的价值有负数,那么⾮0下标就要初始化为负⽆穷。这样才能让dp数组在递归公式的过程中取的最⼤的价值,⽽不是被初始值覆盖了。**本题题⽬中 只包含正整数的⾮空数组,所以⾮0下标的元素初始化为0就可以了。代码如下:
// 题⽬中说:每个数组中的元素不会超过 100,数组的⼤⼩不会超过 200
// 总和不会⼤于20000,背包最⼤只需要其中⼀半,所以10001⼤⼩就可以了
vector<int> dp(10001, 0);
4.确定遍历顺序
上节我们已经说明,如果使用一维dp数组,则遍历顺序一定是先遍历物品后遍历背包容量,且遍历背包容量要倒序遍历。
5.举例推导dp数组
dp[j]的数值一定是小于等于j的,如果dp[i] == i 说明,集合中的⼦集总和正好可以凑成总和i,理解这⼀点很重要。⽤例1,输⼊[1,5,11,5] 为例,如图:

抽象为0-1背包问题:当容量为target=sum/2的背包的dp值为target时(target容量的背包最大价值为target时),对应此题的背景:可以装总和(重量)为target的子集(背包),其最大价值(子集和)为target时,说明子集可以凑成总和target。
整体代码如下:
题解
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = 0;
for (int num : nums) sum += num;
if (sum % 2 == 1) return false;
int target = sum / 2;
vector<int> dp(10001);
for (int i = 0; i < nums.size(); i++) {
for (int j = target; j >= nums[i]; j--) {
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
}
}
if (dp[target] == target) return true;
return false;
}
};
//时间复杂度:O(n^2)
//空间复杂度:O(n),虽然dp数组⼤⼩为⼀个常数,但是⼤常数
小结:这道题⽬就是⼀道01背包应⽤类的题⽬,需要我们拆解题⽬,然后套⼊01背包的场景。01背包相对于本题,主要要理解,题⽬中物品是nums[i],重量是nums[i]i,价值也是nums[i],背包体积是sum/2。看代码的话,就可以发现,基本就是按照01背包的写法来的。
11.11 目标和
力扣题号: 494.目标和
给你一个整数数组 nums 和一个整数 target 。
向数组中的每个整数前添加 ‘+’ 或 ‘-’ ,然后串联起所有整数,可以构造一个 表达式 :
例如,nums = [2, 1] ,可以在 2 之前添加 ‘+’ ,在 1 之前添加 ‘-’ ,然后串联起来得到表达式 “+2-1” 。
返回可以通过上述方法构造的、运算结果等于 target 的不同 表达式 的数目。
示例 1:
输入:nums = [1,1,1,1,1], target = 3
输出:5
解释:一共有 5 种方法让最终目标和为 3 。
-1 + 1 + 1 + 1 + 1 = 3
+1 - 1 + 1 + 1 + 1 = 3
+1 + 1 - 1 + 1 + 1 = 3
+1 + 1 + 1 - 1 + 1 = 3
+1 + 1 + 1 + 1 - 1 = 3
示例 2:
输入:nums = [1], target = 1
输出:1
提示:
1 <= nums.length <= 20
0 <= nums[i] <= 1000
0 <= sum(nums[i]) <= 1000
-1000 <= target <= 1000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/target-sum
11.11.1 回溯法
本题用回溯法暴力搜索是比较容易想到的解法,可以套组合总和的回溯算法的模板,几乎不用改变。
首先计算nums中所有元素的总和sum,假设加法的总和为x,那么减法对应的总和就是sum - x。所以我们要求的是 x - (sum - x) = target。x = (target + sum) / 2。⼤家看到(target + sum) / 2 应该担⼼计算的过程中向下取整有没有影响。这么担⼼就对了,例如sum 是5,S是2的话其实就是⽆解的,另外如果target>sum,也是无解的。 我们还需担心两个int相加是否会溢出,看看题目,0 <= sum(nums[i]) <= 1000,所以不会溢出。
1.确定回溯函数参数及返回值
返回值为void,参数我们首先 想到应该有给定nums,其次应该有target即目标和,再之后应该有sum记录当前总和,最后应该有startIndex控制递归开始的位置。
2.确定回溯函数终止条件
当路径总和sum == target时,我们应该将结果加入结果集,此时返回吗?不返回,因为题目中说nums[i]范围为[0,1000],后续还可能会有0加入,使sum仍等于target。当sum>target时,由于nums是排序过的,所以之后也不会满足target,所以应该返回。
3.确定单层搜索的逻辑
for循环从startIndex开始遍历,本题不可重复选取,所以startIndex应该+1。整体代码如下:
题解
class Solution {
private:
vector<int> path;
vector<vector<int>> result;
void backtracking(vector<int>& nums, int target, int sum, int startIndex) {
if (sum > target) return;
if (sum == target) {
result.push_back(path);
//return;
}
for (int i = startIndex; i < nums.size(); i++) {
sum += nums[i];
path.push_back(nums[i]);
backtracking(nums, target, sum, i + 1);
path.pop_back();
sum -= nums[i];
}
}
public:
int findTargetSumWays(vector<int>& nums, int target) {
int sum = 0;
for (int num : nums) sum += num;
if (target > sum) return 0;
if ((target + sum) % 2 == 1) return 0;
int bagSize = (target + sum) / 2;
sort(nums.begin(), nums.end());
backtracking(nums, bagSize, 0, 0);
return result.size();
}
};
不出意外的话是超时了,我们试试剪枝。上面我们讲解终止条件的时候提到有两种情况,sum大于target和sum等于target。事实上当我们对nums数组进行从小到大排序后,当sum大于target时,就没必要进入循环了,因此我们可以在for循环搜索范围上设置条件。
题解
class Solution {
private:
vector<int> path;
vector<vector<int>> result;
void backtracking(vector<int>& nums, int target, int sum, int startIndex) {
if (sum == target) {
result.push_back(path);
//return;
}
for (int i = startIndex; i < nums.size() && sum + nums[i] <= target; i++) {
sum += nums[i];
path.push_back(nums[i]);
backtracking(nums, target, sum, i + 1);
path.pop_back();
sum -= nums[i];
}
}
public:
int findTargetSumWays(vector<int>& nums, int target) {
int sum = 0;
for (int num : nums) sum += num;
if (target > sum) return 0;
if ((target + sum) % 2 == 1) return 0;
int bagSize = (target + sum) / 2;
sort(nums.begin(), nums.end());
backtracking(nums, bagSize, 0, 0);
return result.size();
}
};
哈哈哈,通过了,时间1716ms,击败百分之5的用户,笑死了。也可以使用记忆化回溯,但是目前我还不会,就不在回溯上下功夫了,直接看动规吧。
11.11.2 动态规划 0-1背包
这道题如何转化成0-1背包呢?为什么是0-1背包呢?因为nums中的一个元素只能使用一次。这次和之前遇到的背包问题不⼀样了,之前都是求容量为j的背包,最多能装多少(或价值最多多少)。本题则是装满有⼏种⽅法。其实这就是⼀个组合问题了。
在提交代码后,发现有一个测试用例为nums= [100],target = -200。则begSize = (sum + target) / 2,我们在初始化dp数组时候,vector<int> dp(begSize + 1);,则会出错,超过了vector的max_size。所以我们还要加一个判断,当begSize + 1 < 0时候,此时无解。
1.确定dp数组及下标的含义
dp[j]表示:填满j(包括j)容量的背包,有多少方法。用二维dp数组来求解就是dp[i][j]:使用下标为[0,i]的nums[i]能够装满容量为j的背包有多少种方法。
2.确定递推公式
有哪些来源可以推出dp[j]呢?不考虑nums[i]的情况下,填满容量为j - nums[i]的背包,有dp[j - nums[i]]中⽅法。那么只要搞到nums[i]的话,凑成dp[j]就有dp[j - nums[i]] 种⽅法。举⼀个例⼦,nums[i] = 2: dp[3],填满背包容量为3的话,有dp[3]种⽅法。那么只需要搞到⼀个2(nums[i]),有dp[3]⽅法可以凑⻬容量为3的背包,相应的就有多少种⽅法可以凑⻬容量为5的背包。那么需要把 这些⽅法累加起来就可以了,dp[j] += dp[j - nums[i]];。所以求组合类问题的公式,都是类似这种。这个公式在后⾯在讲解背包解决排列组合问题的时候还会⽤到!
3.dp数组该如何初始化
从递推公式可以看出,dp[j]需要dp[j-nums[i]],在初始化的时候dp[0]一定要初始化为0,因为dp[0]是公式中一切递推结果的起源,如果dp[0]是0的话,递归结果将都是0。dp[0] = 1,理论上也很好解释,装满容量为0的背包,有1种⽅法,就是装0件物品。dp[j]其他下标对应的数值应该初始化为0,从递归公式也可以看出,dp[j]要保证是0的初始值,才能正确的由dp[j -nums[i]]推导出来。
4.确定遍历顺序
我们之前讲过,对于0-1背包问题一维dp的遍历,要先遍历nums(物品),后遍历target(背包容量)且倒序遍历。
5.举例推导dp数组
输⼊:nums: [1, 1, 1, 1, 1], target = 3。bagSize = (target + sum) / 2 = (3 + 5) / 2 = 4。dp数组状态变化如下:
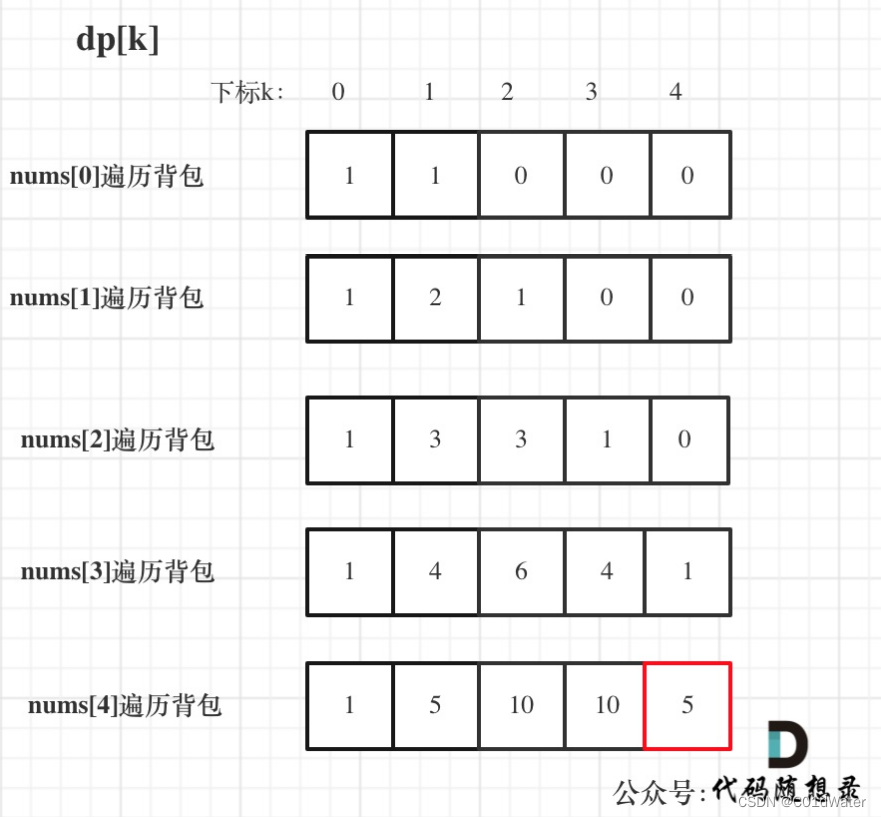
整体代码如下:
题解
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
int sum = 0;
for (int num : nums) sum += num;
if (sum < target) return 0;
if ((sum + target) % 2 == 1) return 0;
int begSize = (sum + target) / 2;
if (begSize + 1 < 0) return 0;
vector<int> dp(begSize + 1);
dp[0] = 1;
for (int i = 0; i < nums.size(); i++) {
for (int j = begSize; j >= nums[i]; j--) {
dp[j] += dp[j - nums[i]];
}
}
return dp[begSize];
}
};
//时间复杂度O(n * m),n为正数个数,m为背包容量
//空间复杂度:O(m) m为背包容量
现在我们来试试二维dp数组,
1.确定dp数组及下标含义
定义二维数组dp[i][j]:在nums中的前i个数中选取元素,使得这些元素之和等于j(装满)的方案数。最终答案就是dp[n][neg]。
2.确定递推公式
当背包容量j装不下nums[i]时,不能选nums[i],dp[i][j]=dp[i-1][j],如果可以装下,则分为两种方式:1.不装nums[i],dp[i][j]=dp[i-1][j];2.装nums[i],dp[i][j]= dp[i-1][j-nums[i]]。所以dp[i][j]= dp[i-1][j]+dp[i-1][j-nums[i]].
3.dp数组如何初始化
当没有任何元素选取时,元素和只能是0,对应的方案数1,所以我们要初始化dp[0][0]= 1。注意这里我们的i表示第i个元素,不存在第0个元素,就表示没有任何元素选取。
4.确定遍历顺序
我们应该先遍历物品,后遍历背包,不用倒序遍历。
举例推导dp数组。
整体代码如下:
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
int sum = 0;
for (int num : nums) sum += num;
if (sum < target) return 0;
if ((sum + target) % 2 == 1) return 0;
int begSize = (sum + target) / 2;
if (begSize + 1 < 0) return 0;
vector<vector<int>> dp(nums.size() + 1, vector<int>(begSize + 1));
dp[0][0] = 1;
for (int i = 1; i <= nums.size(); i++) {
for (int j = 0; j <= begSize; j++) {
dp[i][j] = dp[i - 1][j];
if (j >= nums[i-1]) dp[i][j] += dp[i-1][j - nums[i-1]];
}
}
return dp[nums.size()][begSize];
}
};
小结:此时 ⼤家应该不仅想起,我们之前讲过的回溯算法:39. 组合总和是不是应该也可以⽤dp来做啊?**是的,如果仅仅是求个数的话,就可以⽤dp,但回溯算法:39. 组合总和要求的是把所有组合列出来,还是要使⽤回溯法爆搜的。**本题还是有点难度,⼤家也可以记住,在求装满背包有⼏种⽅法的情况下,递推公式⼀般为:后⾯我们在讲解完全背包的时候,还会⽤到这个递推公式!
11.12 一和零
力扣题号: 474.一和零
给你一个二进制字符串数组 strs 和两个整数 m 和 n 。
请你找出并返回 strs 的最大子集的长度,该子集中 最多 有 m 个 0 和 n 个 1 。
如果 x 的所有元素也是 y 的元素,集合 x 是集合 y 的 子集 。
示例 1:
输入:strs = [“10”, “0001”, “111001”, “1”, “0”], m = 5, n = 3
输出:4
解释:最多有 5 个 0 和 3 个 1 的最大子集是 {“10”,“0001”,“1”,“0”} ,因此答案是 4 。
其他满足题意但较小的子集包括 {“0001”,“1”} 和 {“10”,“1”,“0”} 。{“111001”} 不满足题意,因为它含 4 个 1 ,大于 n 的值 3 。
示例 2:
输入:strs = [“10”, “0”, “1”], m = 1, n = 1
输出:2
解释:最大的子集是 {“0”, “1”} ,所以答案是 2 。
提示:
1 <= strs.length <= 600
1 <= strs[i].length <= 100
strs[i] 仅由 ‘0’ 和 ‘1’ 组成
1 <= m, n <= 100
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/ones-and-zeroes
思路
这道题⽬,还是⽐较难的,也有点像程序员⾃⼰给⾃⼰出个脑筋急转弯,程序员何苦为难程序员呢哈
哈。来说题,本题不少同学会认为是多重背包,⼀些题解也是这么写的。其实本题并不是多重背包,再来看⼀下这个图,捋清⼏种背包的关系。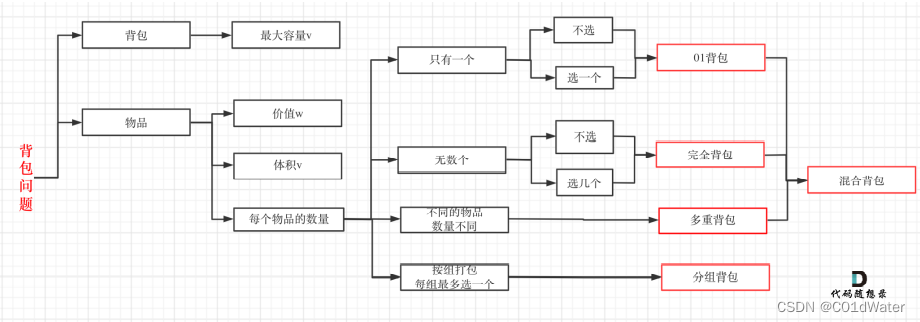
多重背包是每个物品,数量不同的情况。本题中strs 数组⾥的元素就是物品,每个物品都是⼀个!⽽m 和 n相当于是⼀个背包,两个维度的背包。理解成多重背包的同学主要是把m和n混淆为物品了,感觉这是不同数量的物品,所以以为是多重背包。但本题其实是01背包问题!这不过这个背包有两个维度,⼀个是m ⼀个是n,⽽不同⻓度的字符串就是不同⼤⼩的待装物品。
1.确定dp数组及下标的含义
dp[i][j]:最多有i个0和j个1的strs的最大子集大小。也就是说装满有两个维度的背包其物品最大数目。
2.确定递推公式
dp[i][j] 可以由前⼀个strs⾥的字符串推导出来,strs⾥的字符串有zeroNum个0,oneNum个1。dp[i][j] 就可以是 dp[i - zeroNum][j - oneNum] + 1。然后我们在遍历的过程中,取dp[i][j]的最⼤值。所以递推公式:dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);此时⼤家可以回想⼀下01背包的递推公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);对⽐⼀下就会发现,字符串的zeroNum和oneNum相当于物品的重量(weight[i]),字符串本身的个数相当于物品的价值(value[i])。这就是⼀个典型的01背包! 只不过物品的重量有了两个维度⽽已。
3.dp数组如何初始化
在之前的讲解中,我们提到,01背包的dp数组初始化为0就行了,因为物品价值不会是负数,初始化为0可以保证递推过程中dp[i][j]不会被初始化覆盖。
4.确定遍历顺序
我们讲到了01背包为什么⼀定是外层for循环遍历物品,内层for循环遍历背包容量且从后向前遍历!那么本题也是,物品就是strs⾥的字符串,背包容量就是题⽬描述中的m和n。有同学可能想,那个遍历背包容量的两层for循环先后循序有没有什么讲究?没讲究,都是物品重量的⼀个维度,先遍历那个都⾏!
5.举例推导dp数组
以输⼊:[“10”,“0001”,“111001”,“1”,“0”],m = 3,n = 3为例。最后dp数组的状态如下所示:
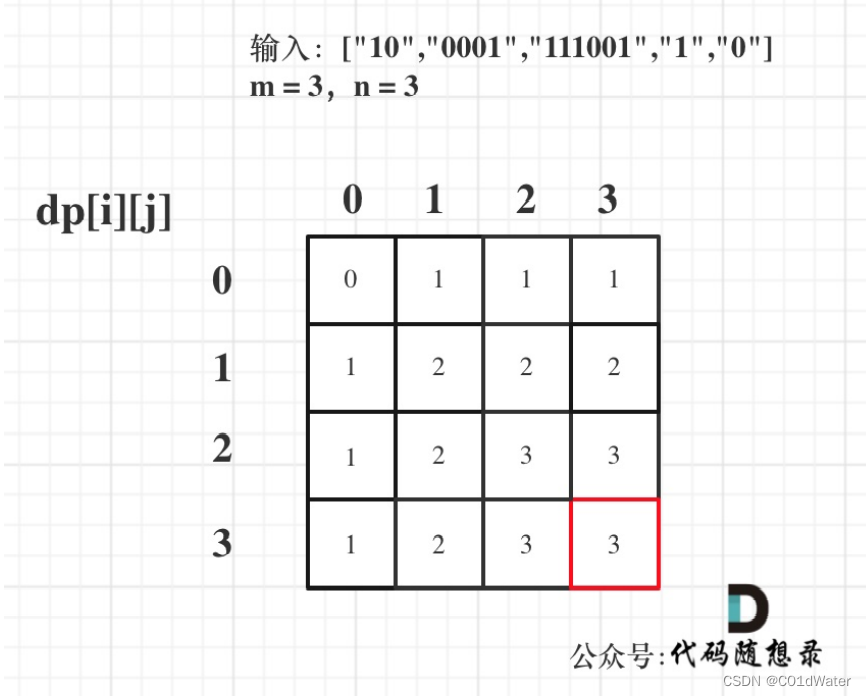
整体代码如下:
题解
class Solution {
public:
int findMaxForm(vector<string>& strs, int m, int n) {
vector<vector<int>> dp(m + 1, vector<int>(n + 1));//初始化为0即可
for (string str : strs) {//遍历物品
int zeroNum = 0, oneNum = 0;
for (char c : str) {
if (c == '0') zeroNum++;
if (c == '1') oneNum++;
}
for (int i = m; i >= zeroNum; i--) {//倒序遍历二维背包容量
for (int j = n; j >= oneNum; j--) {
dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
}
}
}
return dp[m][n];
}
};
小结:不少同学刷过这道题,可能没有总结这究竟是什么背包。这道题的本质是有两个维度的01背包,如果⼤家认识到这⼀点,对这道题的理解就⽐较深⼊了。
11.13 完全背包理论基础
有N种物品和⼀个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有⽆限个(也就是可以放⼊背包多次),求解将哪些物品装⼊背包⾥物品价值总和最⼤。**完全背包和01背包问题唯⼀不同的地⽅就是,每种物品有⽆限件。**同样leetcode上没有纯完全背包问题,都是需要完全背包的各种应⽤,需要转化成完全背包问题,所以我这⾥还是以纯完全背包问题进⾏讲解理论和原理。
在下⾯的讲解中,我依然举这个例⼦:背包最⼤重量为4。物品为:
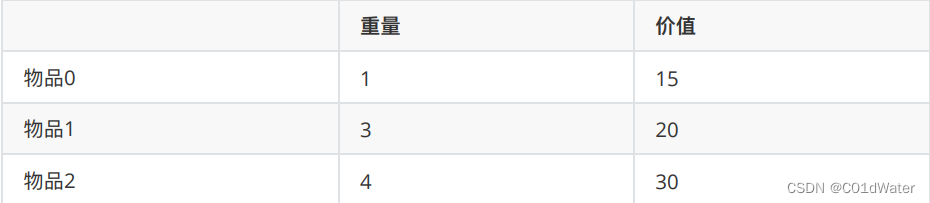
每件商品都有⽆限个!问背包能背的物品最⼤价值是多少?
01背包和完全背包唯⼀不同就是体现在遍历顺序上,所以本⽂就不去做动规五部曲了,我们直接针对遍历顺序经⾏分析!
⾸先在回顾⼀下0-1背包(一维dp数组)的核⼼代码:
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
dp状态图如下:
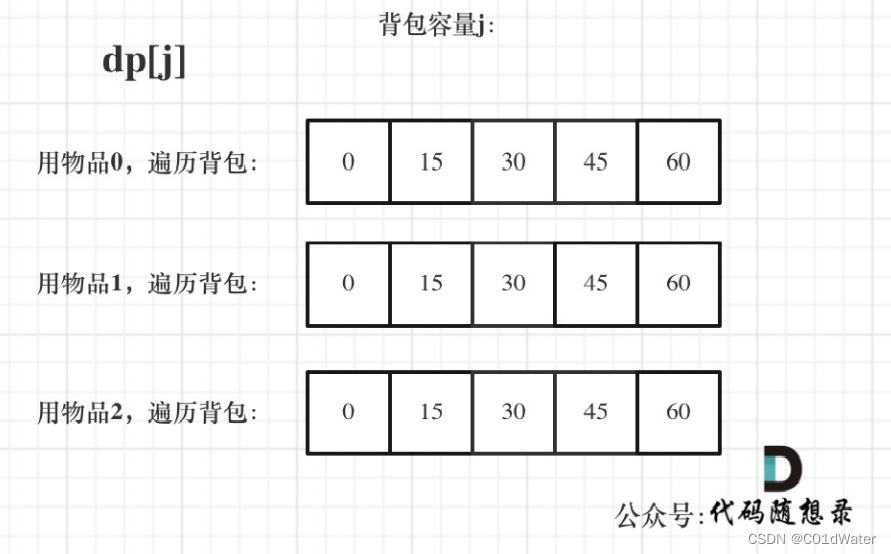
相信很多同学看⽹上的⽂章,关于完全背包介绍基本就到为⽌了。其实还有⼀个很重要的问题,为什么遍历物品在外层循环,遍历背包容量在内层循环?这个问题很多题解关于这⾥都是轻描淡写就略过了,⼤家都默认 遍历物品在外层,遍历背包容量在内层,好像本应该如此⼀样,那么为什么呢?难道就不能遍历背包容量在外层,遍历物品在内层?
看过之前的讲解就知道了:01背包中⼆维dp数组的两个for遍历的先后循序是可以颠倒了,⼀维dp数组的两个for循环先后循序⼀定是先遍历物品,再遍历背包容量(倒序)。在完全背包中,对于⼀维dp数组来说,其实两个for循环嵌套顺序同样⽆所谓! 先遍历背包后遍历物品正序遍历实际上是求背包只放一种物品(数量不限)其最大价值?。
因为dp[j] 是根据 下标j之前所对应的dp[j]计算出来的。 只要保证下标j之前的dp[j]都是经过计算的就可以了。
先遍历物品再遍历背包容量代码和执行结果如下:
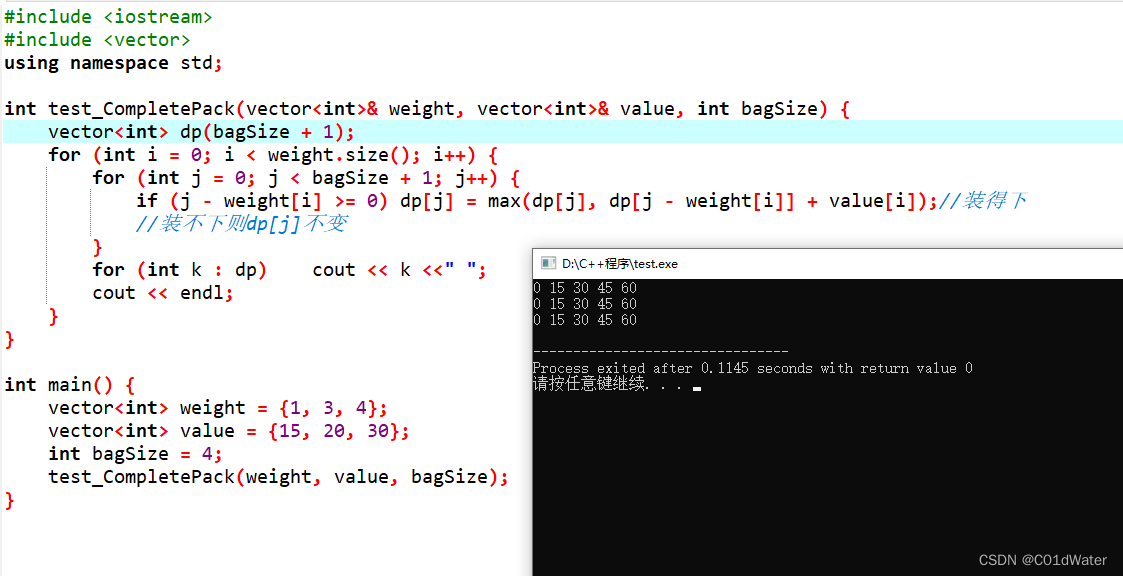
先遍历背包容量再遍历物品代码和执行结果如下:
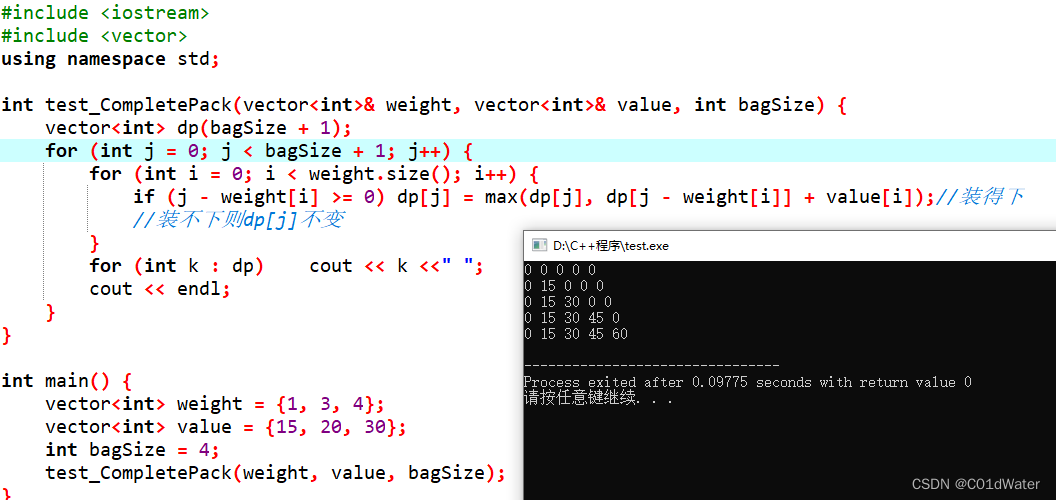
看了这两个执行结果,⼤家就会理解,完全背包中,两个for循环的先后循序,都不影响计算dp[j]所需要的值(这个值就是下标j之前所对应的dp[j])。
总结一下:0-1背包二维dp数组两个for循环顺序可以颠倒,完全背包二维dp数组两个for循环顺序也可以颠倒。
0-1背包一维dp数组只能是先遍历物品后遍历背包容量且背包容量要倒序遍历。(先物品后背包保证可以装多种物品,倒序保证每种物品只装一个)
如果先遍历背包容量后遍历物品且背包容量倒序遍历,求的就是背包只装一种物品的一个,其最大价值是多少(不伦不类)。如果先遍历背包容量后遍历物品且背包容量正序遍历,求的就是背包只装一种物品(可以多个),其最大价值是多少(完全背包)。
完全背包一维dp数组两个for循环顺序可以颠倒,且遍历背包要正序遍历。如果是倒序遍历就成了背包只装一种物品的一个,就不是完全背包了。
最后,⼜可以出⼀道⾯试题了,就是纯完全背包,要求先⽤⼆维dp数组实现,然后再⽤⼀维dp数组实现,最后在问,两个for循环的先后是否可以颠倒?为什么?这个简单的完全背包问题,估计就可以难住不少候选⼈了。
细⼼的同学可能发现,全⽂我说的都是对于纯完全背包问题,其for循环的先后循环是可以颠倒的!但如果题⽬稍稍有点变化,就会体现在遍历顺序上。如果问装满背包有⼏种⽅式的话? 那么两个for循环的先后顺序就有很⼤区别了,⽽leetcode上的题⽬都是这种稍有变化的类型。这个区别,我将在后⾯讲解具体leetcode题⽬中给⼤家介绍,因为这块如果不结合具题⽬,单纯的介绍原理估计很多同学会越看越懵!
11.14 零钱兑换(一)
力扣题号: 518.零钱兑换
给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。
请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。
假设每一种面额的硬币有无限个。
题目数据保证结果符合 32 位带符号整数。
示例 1:
输入:amount = 5, coins = [1, 2, 5]
输出:4
解释:有四种方式可以凑成总金额:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
示例 2:
输入:amount = 3, coins = [2]
输出:0
解释:只用面额 2 的硬币不能凑成总金额 3 。
示例 3:
输入:amount = 10, coins = [10]
输出:1
提示:
1 <= coins.length <= 300
1 <= coins[i] <= 5000
coins 中的所有值 互不相同
0 <= amount <= 5000
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/coin-change-2
思路
这是⼀道典型的背包问题,⼀看到钱币数量不限,就知道这是⼀个完全背包。但本题和纯完全背包不⼀样,纯完全背包是能否凑成总⾦额,⽽本题是要求凑成总⾦额的个数!注意题⽬描述中是凑成总⾦额的硬币组合数,为什么强调是组合数呢?例如示例⼀:
5 = 2 + 2 + 1
5 = 2 + 1 + 2
这是⼀种组合,都是 2 2 1。如果问的是排列数,那么上⾯就是两种排列了。组合不强调元素之间的顺序,排列强调元素之间的顺序。 其实这⼀点我们在讲解回溯算法专题的时候就讲过了哈。
那我为什么要介绍这些呢,因为这和下⽂讲解遍历顺序息息相关!
1.确定dp数组及下标的含义
dp[j]:用各个面值的coins凑成总金额j的方法数
2.确定递推公式
dp[j] (考虑coins[i]的组合总和) 就是所有的dp[j - coins[i]](不考虑coins[i])相加。所以递推公式:dp[j] += dp[j - coins[i]];这个递推公式⼤家应该不陌⽣了,我在讲解01背包题⽬的时候:⽬标和!中就讲解了,求装满背包有⼏种⽅法,⼀般公式都是:dp[j] += dp[j - nums[i]];
3.dp数组如何初始化
由于dp[j]都是由j之前的dp[]确定的,所以dp[0]是一切递推的基础,那么dp[0]应该初始化为多少呢?从实际意义上来看,dp[0]应该为1,因为凑成总金额为0的组合数为1(就是什么面值的coin都不用)。从递推公式来看,dp[0]如果为0,那么所有dp[j]都为0了。下标非0的dp[j]应该初始化为0,这样累计加dp[j-coins[i]]时才不会影响真正的dp[j]。
4.确定遍历顺序
本题中我们是外层for循环遍历物品(钱币),内层for遍历背包(⾦钱总额),还是外层for遍历背包(⾦钱总额),内层for循环遍历物品(钱币)呢?之前我们讲过完全背包的两个for循环的先后顺序都是可以的。但本题就不⾏了!因为纯完全背包求得是能否凑成总和(凑满背包其最大价值),和凑成总和的元素有没有顺序没关系,即:有顺序也⾏,没有顺序也⾏!⽽本题要求凑成总和的组合数,元素之间要求没有顺序。所以纯完全背包是能凑成总和就⾏,不⽤管怎么凑的。本题是求凑出来的⽅案个数,且每个⽅案个数是为组合数。那么本题,两个for循环的先后顺序可就有说法了。
我们先来看 外层for循环遍历物品(钱币),内层for遍历背包(⾦钱总额)的情况。代码如下:
for (int i = 0; i < coins.size(); i++) { // 遍历物品
for (int j = coins[i]; j <= amount; j++) { // 遍历背包容量
dp[j] += dp[j - coins[i]];
}
}
假设:coins[0] = 1,coins[1] = 5。amount=6。那么就是先把1加⼊计算,然后再把5加⼊计算,得到的⽅法数量只有{1, 5}这种情况。⽽不会出现{5, 1}的情况。所以这种遍历顺序中dp[j]⾥计算的是组合数!
如果把两个for交换顺序,代码如下:
for (int j = 0; j <= amount; j++) { // 遍历背包容量
for (int i = 0; i < coins.size(); i++) { // 遍历物品
if (j - coins[i] >= 0) dp[j] += dp[j - coins[i]];
}
}
背包容量的每⼀个值,都是经过 1 和 5 的计算,包含了{1, 5} 和 {5, 1}两种情况。此时dp[j]⾥算出来的就是排列数!
可能这⾥很多同学还不是很理解,建议动⼿把这两种⽅案的dp数组数值变化打印出来,对⽐看⼀看!(实践出真知)
5.举例推导dp数组
输⼊: amount = 5, coins = [1, 2, 5] ,dp状态图如下:

整体代码如下:
题解
class Solution {
public:
int change(int amount, vector<int>& coins) {
vector<int> dp(amount + 1);
dp[0] = 1;
for (int i = 0; i < coins.size(); i++) {
for (int j = coins[i]; j < amount + 1; j++) {
dp[j] += dp[j - coins[i]];
}
}
return dp[amount];
}
};
小结:本题的递推公式,其实我们在动态规划:⽬标和!中就已经讲过了,⽽难点在于遍历顺序!在求装满背包有⼏种⽅案的时候,认清遍历顺序是⾮常关键的。如果求组合数就是外层for循环遍历物品,内层for遍历背包。如果求排列数就是外层for遍历背包,内层for循环遍历物品。 可能说到排列数录友们已经有点懵了,后⾯还会安排求排列数的题⽬,到时候在对⽐⼀下,⼤家就会发现神奇所在。
11.15 拼凑一个正整数
力扣题号:377.组合总和Ⅳ
给你一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请你从 nums 中找出并返回总和为 target 的元素组合的个数。
题目数据保证答案符合 32 位整数范围。
示例 1:
输入:nums = [1,2,3], target = 4
输出:7
解释:
所有可能的组合为:
(1, 1, 1, 1)
(1, 1, 2)
(1, 2, 1)
(1, 3)
(2, 1, 1)
(2, 2)
(3, 1)
请注意,顺序不同的序列被视作不同的组合。
示例 2:
输入:nums = [9], target = 3
输出:0
提示:
1 <= nums.length <= 200
1 <= nums[i] <= 1000
nums 中的所有元素 互不相同
1 <= target <= 1000
进阶:如果给定的数组中含有负数会发生什么?问题会产生何种变化?如果允许负数出现,需要向题目中添加哪些限制条件?
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/combination-sum-iv
思路
本题题⽬描述说是求组合,但⼜说是可以元素相同顺序不同的组合算两个组合,其实就是求排列!弄清什么是组合,什么是排列很重要。组合不强调顺序,(1,5)和(5,1)是同⼀个组合。排列强调顺序,(1,5)和(5,1)是两个不同的排列。⼤家在公众号⾥学习回溯算法专题的时候,⼀定做过这两道题⽬回溯算法:39.组合总和和回溯算法:40.组合总和II会感觉这两题和本题很像!
但其本质是本题求的是排列总和,⽽且仅仅是求排列总和的个数,并不是把所有的排列都列出来。还记得上节说要求排列该怎么办吗?如果求排列数就是外层for遍历背包,内层for循环遍历物品。 如果本题要把排列都列出来的话,只能使⽤回溯算法爆搜。
1.确定dp数组及下标的含义
dp[i]:表示target为i时,用nums中的元素凑够i的方法数。
2.确定递推公式
dp[i](考虑nums[j])可以由 dp[i - nums[j]](不考虑nums[j]) 推导出来。只需将不同的nums[j]对应的dp[i-nums[j]]累加即可。在动态规划:494.⽬标和 和 动态规划:518.零钱兑换II中我们已经讲过了,求装满背包有⼏种⽅法,递推公式⼀般都是dp[i] += dp[i - nums[j]];本题也⼀样。
3.dp数组如何初始化
dp[0] = 1.因为递推公式dp[i] += dp[i - nums[j]]的缘故,dp[0]要初始化为1,这样递归其他dp[i]的时候才会有数值基础。⾄于dp[0] = 1 有没有意义呢?其实没有意义,所以我也不去强⾏解释它的意义了,因为题⽬中也说了:给定⽬标值是正整数! 所以dp[0] = 1是没有意义的,仅仅是为了推导递推公式。⾄于⾮0下标的dp[i]应该初始为多少呢?初始化为0,这样才不会影响dp[i]累加所有的dp[i - nums[j]]。
4.确定遍历顺序
个数可以不限使⽤,说明这是⼀个完全背包。得到的集合是排列,说明需要考虑元素之间的顺序。本题要求的是排列,那么这个for循环嵌套的顺序可以有说法了。在动态规划:518.零钱兑换II 中就已经讲过了。如果求组合数就是外层for循环遍历物品,内层for遍历背包。如果求排列数就是外层for遍历背包,内层for循环遍历物品。如果把遍历nums(物品)放在外循环,遍历target的作为内循环的话,举⼀个例⼦:计算dp[4]的时候,结果集只有 {1,3} 这样的集合,不会有{3,1}这样的集合,因为nums遍历放在外层,3只能出现在1后⾯!如果遍历targetr放在外循环,遍历nums放在内循环,举一个例子:计算dp[4]时,结果集有{1,3}和{3,1}。因为背包容量的每一个值(4)都经过1和3的计算,包含上述两种情况。所以本题遍历顺序最终遍历顺序:target(背包)放在外循环,将nums(物品)放在内循环,内循环从前到后遍历。此时dp[j]⾥算出来的就是排列数!可能这⾥很多同学还不是很理解,建议动⼿把这两种⽅案的dp数组数值变化打印出来,对⽐看⼀看!(实践出真知)
5.举例推导dp数组
输⼊: amount = 5, coins = [1, 2, 5] ,dp状态图如下:

整体代码如下:
题解
class Solution {
public:
int combinationSum4(vector<int>& nums, int target) {
vector<int> dp(target + 1);
dp[0] = 1;
for (int i = 0; i < target + 1; i++) {
for (int j = 0; j < nums.size(); j++) {
//因为C++测试用例有超过两个数相加超过int的数据,所以需要在if里加上dp[i] < INT_MAX - dp[i - num]。
if (i >= nums[j] && dp[i] < INT_MAX - dp[i - nums[j]]) dp[i] += dp[i - nums[j]];
}
}
return dp[target];
}
};
C++测试⽤例有超过两个树相加超过int的数据,所以需要在if⾥加上dp[i] < INT_MAX - dp[i - num]。但java就不⽤考虑这个限制,java⾥的int也是四个字节吧,也有可能leetcode后台对不同语⾔的测试数据不⼀样。
小结:求装满背包有⼏种⽅法,递归公式都是⼀样的,没有什么差别,但关键在于遍历顺序!本题与动态规划:518.零钱兑换II就是⼀个鲜明的对⽐,⼀个是求排列,⼀个是求组合,遍历顺序完全不同。如果对遍历顺序没有深度理解的话,做这种完全背包的题⽬会很懵逼,即使题⽬刷过了可能也不太清楚具体是怎么过的。此时⼤家应该对动态规划中的遍历顺序⼜有更深的理解了。
11.16 多步爬楼梯
⼀步⼀个台阶,两个台阶,三个台阶,…,直到 m个台阶。问有多少种不同的⽅法可以爬到n层台阶呢?
思路
1阶,2阶,… m阶就是物品,楼顶就是背包。每⼀阶可以重复使⽤,例如跳了1阶,还可以继续跳1阶。问跳到楼顶有⼏种⽅法其实就是问装满背包有⼏种⽅法。此时⼤家应该发现这就是⼀个完全背包问题了!和昨天的题⽬动态规划:377. 组合总和 Ⅳ基本就是⼀道题了。
1.确定dp数组及下标的含义
dp[i]:爬到有i个台阶的楼顶,有dp[i]种方法。
2.确定递推公式
在动态规划:494.⽬标和 、 动态规划:518.零钱兑换II、动态规划:377. 组合总和 Ⅳ中我们都讲过了,求装满背包有⼏种⽅法,递推公式⼀般都是dp[i] += dp[i - nums[j]];本题呢,dp[i]有⼏种来源,dp[i - 1],dp[i - 2],dp[i - 3] 等等,即:dp[i - j]那么递推公式为:dp[i] += dp[i - j];
3.dp数组如何初始化
既然递归公式是 dp[i] += dp[i - j],那么dp[0] ⼀定为1,dp[0]是递归中⼀切数值的基础所在,如果dp[0]是0的话,其他数值都是0了。下标⾮0的dp[i]初始化为0,因为dp[i]是靠dp[i-j]累计上来的,dp[i]本身为0这样才不会影响结果。
4.确定遍历顺序
这是背包⾥求排列问题,即:1、2 步 和 2、1 步都是上三个台阶,但是这两种⽅法不⼀样!所以需将target放在外循环,将nums放在内循环。每⼀步可以⾛多次,这是完全背包,内循环需要从前向后遍历。
5.举例推导dp数组
介于本题和动态规划:377. 组合总和 Ⅳ⼏乎是⼀样的,这⾥我就不再重复举例了。
整体代码如下:
题解
class Solution {
public:
int climbStairs(int n) {
vector<int> dp(n + 1);
dp[0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (i - j >= 0) dp[i] += dp[i - j];
}
}
return dp[n];
}
};
代码中m表示最多可以爬m个台阶,代码中把m改成2就是本题70.爬楼梯可以AC的代码了。
小结:本题看起来是⼀道简单题⽬,稍稍进阶⼀下其实就是⼀个完全背包!
如果我来⾯试的话,我就会先给候选⼈出⼀个 本题原题,看其表现,如果顺利写出来,进⽽在要求每次可以爬[1 - m]个台阶应该怎么写。顺便再考察⼀下两个for循环的嵌套顺序,为什么target放外⾯,nums放⾥⾯(排列数)。这就能考察对背包问题本质的掌握程度,候选⼈是不是刷题背公式,⼀眼就看出来了。这么⼀连套下来,如果候选⼈都能答出来,相信任何⼀位⾯试官都是⾮常满意的。
本题代码不⻓,题⽬也很普通,但稍稍⼀进阶就可以考察完全背包,⽽且题⽬进阶的内容在leetcode上并没有原题,⼀定程度上就可以排除掉刷题党了,简直是⾯试题⽬的绝佳选择!
11.17 零钱兑换(二)
力扣题号: 322.零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
示例 2:
输入:coins = [2], amount = 3
输出:-1
示例 3:
输入:coins = [1], amount = 0
输出:0
提示:
1 <= coins.length <= 12
1 <= coins[i] <= 231 - 1
0 <= amount <= 104
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/coin-change
思路
在动态规划:518.零钱兑换II中我们已经兑换⼀次零钱了,这次⼜要兑换,套路不⼀样!题⽬中说每种硬币的数量是⽆限的,可以看出是典型的完全背包问题。
1.确定dp数组及下标含义
dp[j]:为凑够总金额amount所需最少钱币数。
2.确定递推公式
得到dp[j](考虑coins[i]),只有⼀个来源,dp[j - coins[i]](没有考虑coins[i])。凑⾜总额为j - coins[i]的最少个数为dp[j - coins[i]],那么只需要加上⼀个钱币coins[i]即dp[j - coins[i]] +1就是dp[j](考虑coins[i])。所以dp[j] 要取所有 dp[j - coins[i]] + 1 中最⼩的。递推公式:dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
3.dp数组如何初始化
⾸先凑⾜总⾦额为0所需钱币的个数⼀定是0,那么dp[0] = 0;其他下标对应的数值呢?考虑到递推公式的特性,dp[j]必须初始化为⼀个最⼤的数,否则就会在min(dp[j - coins[i]] + 1, dp[j])⽐较的过程中被初始值覆盖。 所以下标⾮0的元素都是应该是最⼤值。
4.确定遍历顺序
本题求钱币最⼩个数,那么钱币有顺序和没有顺序都可以,都不影响钱币的最⼩个数。所以本题并不强调集合是组合还是排列。如果求组合数就是外层for循环遍历物品,内层for遍历背包。如果求排列数就是外层for遍历背包,内层for循环遍历物品。在动态规划专题我们讲过了求组合数是动态规划:518.零钱兑换II,求排列数是动态规划:377. 组合总和 Ⅳ。所以本题的两个for循环的关系是:外层for循环遍历物品,内层for遍历背包或者外层for遍历背包,内层for循环遍历物品都是可以的! 那么我采⽤coins放在外循环,target在内循环的⽅式。本题钱币数量可以⽆限使⽤,那么是完全背包。所以遍历的内循环是正序。综上所述,遍历顺序为:coins(物品)放在外循环,target(背包)在内循环。且内循环正序。
5.举例推导dp数组

整体代码如下:
题解
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
for (int i = 0; i < coins.size(); i++) {
for (int j = coins[i]; j <= amount; j++) {
//如果dp[j-coins[i]]是初始值,则跳过
if (dp[j - coins[i]] != INT_MAX) dp[j] = min(dp[j], dp[j - coins[i]] + 1);
}
}
if (dp[amount] == INT_MAX) return -1;//表示没有任何一种硬币组合可以凑成总金额
return dp[amount];
}
};
对于遍历⽅式遍历背包放在外循环,遍历物品放在内循环也是可以的,我就直接给出代码了
题解
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, INT_MAX);
dp[0] = 0;
for (int i = 1; i <= amount; i++) {
for (int j = 0; j < coins.size(); j++) {
if (i - coins[j] >= 0 && dp[i - coins[j]] != INT_MAX) dp[i] = min(dp[i], dp[i - coins[j]] + 1);
}
}
if (dp[amount] == INT_MAX) return -1;//表示没有任何一种硬币组合可以凑成总金额
return dp[amount];
}
};
小结:细⼼的同学看⽹上的题解,可能看⼀篇是遍历背包的for循环放外⾯,看⼀篇⼜是遍历背包的for循环放⾥⾯,看多了都看晕了,到底两个for循环应该是什么先后关系。能把遍历顺序讲明⽩的⽂章⼏乎找不到!这也是⼤多数同学学习动态规划的苦恼所在,有的时候递推公式很简单,难在遍历顺序上!但最终⼜可以稀⾥糊涂的把题⽬过了,也不知道为什么这样可以过,反正就是过了,哈哈。那么这篇⽂章就把遍历顺序分析的清清楚楚。动态规划:518.零钱兑换II中求的是组合数,动态规划:377. 组合总和 Ⅳ中求的是排列数。⽽本题是要求最少硬币数量,硬币是组合数还是排列数都⽆所谓!所以两个for循环先后顺序怎样都可以!这也是我为什么要先讲518.零钱兑换II 然后再讲本题即:322.零钱兑换,良苦⽤⼼那。相信⼤家看完之后,对背包问题中的遍历顺序⼜了更深的理解了。
11.18 完全平方数
力扣题号: 279.完全平方数
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
示例 2:
输入:n = 13
输出:2
解释:13 = 4 + 9
提示:
1 <= n <= 10^4
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/perfect-squares
思路
可能刚看这种题感觉没啥思路,⼜平⽅和的,⼜最⼩数的。我来把题⽬翻译⼀下:完全平⽅数就是物品(可以⽆限件使⽤),凑个正整数n就是背包,问凑满这个背包最少有多少物品?感受出来了没,这么浓厚的完全背包氛围,⽽且和昨天的题⽬动态规划:322. 零钱兑换就是⼀样⼀样的。
1.确定dp数组及下标的含义
dp[j]:凑够j所需完全平方数的最小数量
2.确定递推公式
dp[j]可由dp[j-ii]推出,,dp[j-ii]+1便是dp[j]。但此时我们要选取最小的dp[j],所以递推公式为:dp[j] = min(dp[j], dp[j - i * i] + 1);。
3.dp数组如何初始化
dp[0] 表示凑成0所需完全平方数最小数,所以应该初始化为0。但有同学就会问了,0=0*0啊,为什么dp[0]不是1?我们再看题目描述,给出一个正整数n,所以dp[0]是没有意义的,只是为了递推公式。那么非0下标的dp[j]应该是多少呢?应该设置为最大值,因为每次dp[j]都要选最小的,这样才不会被初始值覆盖。
4.确定遍历顺序
题目描述只要求出最小数量,没有对组合或排列做要求,所以我们先遍历物品和先遍历背包容量是一样的。例如12=4+4+4,我们只需求出最少需要3个完全平方数,而不用管这3个4是如何排列的(与方法数不同)。
5.举例推导dp数组
已输⼊n为5例,dp状态图如下:

整体代码如下:
题解
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int j = 0; j < n + 1; j++) {//背包
for (int i = 1; i * i <= j; i++) {//物品
dp[j] = min(dp[j], dp[j - i * i] + 1);
}
}
return dp[n];
}
};
class Solution {
public:
int numSquares(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[0] = 0;
for (int i = 1; i * i <= n; i++) {//物品
for (int j = 1; j < n + 1; j++) {//背包
if (j - i * i >= 0) {
dp[j] = min(dp[j], dp[j - i * i] + 1);
}
}
}
return dp[n];
}
};
小结:如果⼤家认真做了昨天的题⽬动态规划:322. 零钱兑换,今天这道就⾮常简单了,⼀样的套路⼀样的味道。但如果没有按照「代码随想录」的题⽬顺序来做的话,做动态规划或者做背包问题,上来就做这道题,那还是挺难的!经过前⾯的训练这道题已经是简单题了,哈哈哈。
11.19 单词拆分
力扣题号: 139.单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = “leetcode”, wordDict = [“leet”, “code”]
输出: true
解释: 返回 true 因为 “leetcode” 可以由 “leet” 和 “code” 拼接成。
示例 2:
输入: s = “applepenapple”, wordDict = [“apple”, “pen”]
输出: true
解释: 返回 true 因为 “applepenapple” 可以由 “apple” “pen” “apple” 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = “catsandog”, wordDict = [“cats”, “dog”, “sand”, “and”, “cat”]
输出: false
提示:
1 <= s.length <= 300
1 <= wordDict.length <= 1000
1 <= wordDict[i].length <= 20
s 和 wordDict[i] 仅有小写英文字母组成
wordDict 中的所有字符串 互不相同
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/word-break
11.19.1 回溯算法
思路
看到这道题⽬的时候,⼤家应该回想起我们之前讲解回溯法专题的时候,讲过的⼀道题⽬回溯算法:分割回⽂串,就是枚举字符串的所有分割情况。回溯算法:分割回⽂串:是枚举分割后的所有⼦串,判断是否回⽂。本道是枚举分割所有字符串,判断是否在字典⾥出现过。
1.确定回溯函数返回值和参数
返回值肯定不能是void,因为我们要判断切割的所有字符串是否都在字典中;参数首先要传入string s,其次,我们应该把字典(unordered_set<string>)传入,因为分割之和要对比是否在字典里,最后还要传入startIndex,确定每次递归开始的位置。
2.确定终止条件
当startIndex大于等于s.size()时,说明已经遍历到字符串结尾(切割到最后),返回true。
3.确定回溯搜索的遍历过程
每次从startIndex开始遍历,直到字符串结尾。如果当前切割的字符串在字典中且从下一个startIndex开始切割的字符串也在字典(深层递归)返回true,否则返回false。
整体代码如下:
题解
class Solution {
private:
bool backtracking(const string& s, unordered_set<string>& wordSet, int startIndex) {
if (startIndex >= s.size()) return true;
for (int i = startIndex; i < s.size(); i++) {
string word = s.substr(startIndex, i - startIndex + 1);//本轮切割的字符串
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, i + 1)) return true;
}
return false;
}
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
return backtracking(s, wordSet, 0);
}
};
不出意外的话,此代码会超时,因为我们切割字符串时,每个字符都有两种状态,切割和不切割,所以时间复杂度为O(2^n).
递归的过程中有很多重复计算,可以使⽤数组保存⼀下递归过程中计算的结果。这个叫做记忆化递归,这种⽅法我们之前已经提过很多次了。使⽤memory数组保存每次计算的以startIndex起始的计算结果,如果memory[startIndex]⾥已经被赋值了,直接⽤memory[startIndex]的结果。

整体代码如下:
题解
class Solution {
private:
bool backtracking(const string& s, unordered_set<string>& wordSet, vector<int>& memory, int startIndex) {
if (startIndex >= s.size()) return true;
// 如果memory[startIndex]不是初始值了,直接使?memory[startIndex]的结果
if (memory[startIndex] != -1) return memory[startIndex];
for (int i = startIndex; i < s.size(); i++) {
string word = s.substr(startIndex, i - startIndex + 1);//本轮切割的字符串
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, memory, i + 1)) {
// 记录以startIndex开始的子串是可以被拆分的
memory[startIndex] = 1;
return true;
}
}
memory[startIndex] = 0; // 记录以startIndex开始的子串是不可以被拆分的
return false;
}
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<int> memory(s.size(), -1);//初始化
return backtracking(s, wordSet, memory, 0);
}
};
11.19.2 动态规划
单词就是物品,字符串s就是背包,单词能否组成字符串s,就是问物品能不能把背包装满。拆分时可以重复使⽤字典中的单词,说明就是⼀个完全背包!
1.确定dp数组及下标的含义
字符串长度为j时,dp[j]=true,说明字符串长度为i时可以拆分为一个或多个字典中出现的单词。
2.确定递推公式
如果dp[i]是true,且[i,j]这个区间的子串出现在字典里,则dp[j]一定是true。(j<i)所以递推公式就是:
if ([i,j]这个区间的子串出现在字典里&&dp[i]为true)则dp[j]=true。
3.dp数组如何初始化
从递推公式可以看出,dp[j]依赖于dp[i],所以dp[0]就是递推的起点,dp[0]一定得是true,否则后面就都是false了。那么dp[0]有没有意义呢?dp[0]表示如果字符串为空的话,说明出现在字典⾥。但题⽬中说了“给定⼀个⾮空字符串 s” 所以测试数据中不会出现i为0的情况,那么dp[0]初始为true完全就是为了推导公式。下标⾮0的dp[i]初始化为false,只要没有被覆盖说明都是不可拆分为⼀个或多个在字典中出现的单词。
4.确定遍历顺序
题目中说是拆分为一个或多个字典里出现的单词,拆分出来的字符串可以重复是字典中的单词,所以是完全背包。完全背包内层循环就要正序,保证一个物品可以被使用多次。另外还要确定先背包还是先物品,本题并不在意是排列还是组合,并不在意字典的单词装入字符串时的顺序,只要能够凑成字符串就行。所以那么本题使⽤求排列的⽅式,还是求组合的⽅式都可以。即:外层for循环遍历物品,内层for遍历背包 或者 外层for遍历背包,内层for循环遍历物品 都是可以的。但本题还有特殊性,因为是要求⼦串,最好是遍历背包放在外循环,将遍历物品放在内循环。如果要是外层for循环遍历物品,内层for遍历背包,就需要把所有的⼦串都预先放在⼀个容器⾥。 (如果不理解的话,可以⾃⼰尝试这么写⼀写就理解了)不理解
5.举例推导dp数组
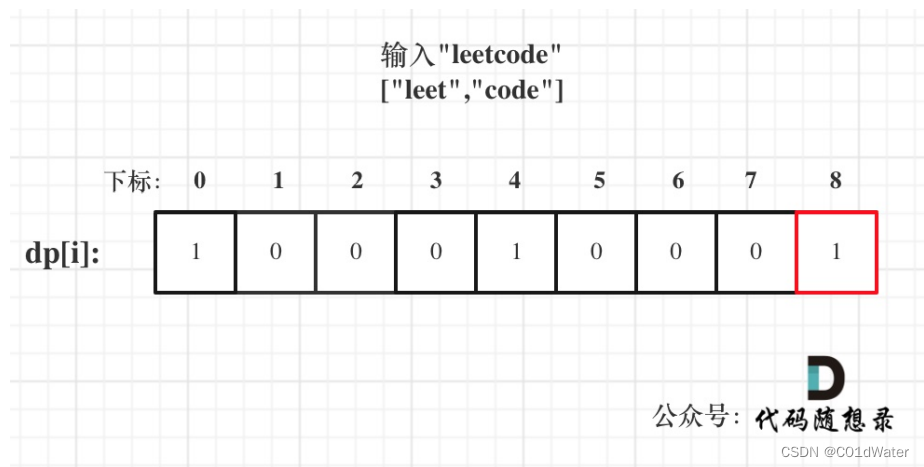
整体代码如下:
题解
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> dp(s.size() + 1, false);
dp[0] = true;
for (int j = 0; j <= s.size(); j++) {//遍历背包
for (int i = 0; i < j; i++) {//遍历物品
string word = s.substr(i, j - i);//从i起始,截取j-i个字符即[i,j]子串 //复杂度为O(n)
if (wordSet.find(word) != wordSet.end() && dp[i]) dp[j] = true;//找到[i,j]这个子串,且dp[i]=true
}
}
return dp[s.size()];
}
};
先遍历物品再遍历背包(不是)不理解啊。
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> dp(s.size() + 1, false);
dp[0] = true;
for (int i = 0; i <= s.size(); i++) {//遍历物品
for (int j = i; j <= s.size(); j++) {//遍历背包
string word = s.substr(i, j - i);//从i起始,截取j-i个字符即[i,j]子串 //复杂度为O(n)
if (wordSet.find(word) != wordSet.end() && dp[i]) dp[j] = true;//找到[i,j]这个子串,且dp[i]=true
}
}
return dp[s.size()];
}
};
小结:本题和我们之前讲解回溯专题的回溯算法:分割回⽂串⾮常像,所以我也给出了对应的回溯解法。稍加分析,便可知道本题是完全背包,⽽且是求能否组成背包,所以遍历顺序理论上来讲 两层for循环谁先谁后都可以!但因为分割⼦串的特殊性,遍历背包放在外循环,将遍历物品放在内循环更⽅便⼀些。
11.20 多重背包理论基础
对于多重背包,我在⼒扣上还没发现对应的题⽬,所以这⾥就做⼀下简单介绍,⼤家⼤概了解⼀下。有N种物品和⼀个容量为V 的背包。第i种物品最多有Mi件可⽤,每件耗费的空间是Ci ,价值是Wi 。求解将哪些物品装⼊背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最⼤。多重背包和01背包是⾮常像的, 为什么和01背包像呢?每件物品最多有Mi件可⽤,把Mi件摊开,其实就是⼀个01背包问题了。
例如:背包最⼤重量为10。物品为:
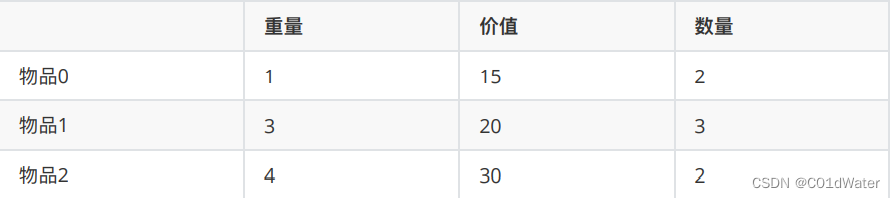
问背包能背的物品最⼤价值是多少?和如下情况有区别么?
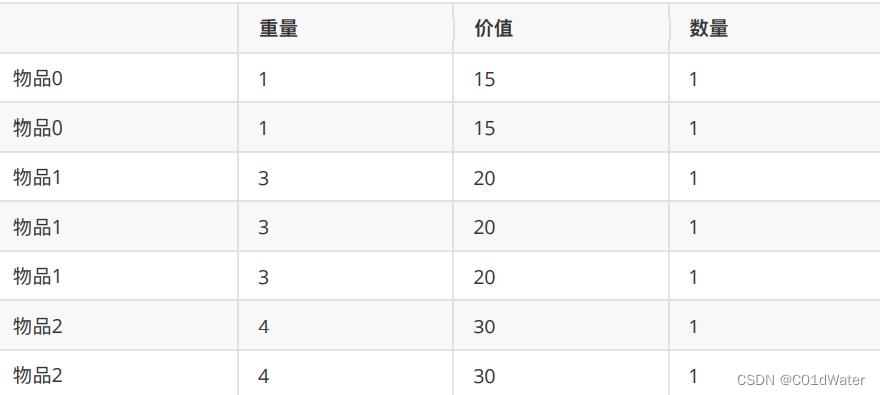
毫⽆区别,这就转成了⼀个01背包问题了,且每个物品只⽤⼀次。这种⽅式来实现多重背包的代码如下:
void test_multi_pack() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
vector<int> nums = {2, 3, 2};
int bagWeight = 10;
for (int i = 0; i < nums.size(); i++) {
while (nums[i] > 1) { // nums[i]保留到1,把其他物品都展开
weight.push_back(weight[i]);
value.push_back(value[i]);
nums[i]--;
}
}
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
for (int j = 0; j <= bagWeight; j++) {
cout << dp[j] << " ";
}
cout << endl;
}
cout << dp[bagWeight] << endl;
}
int main() {
test_multi_pack();
}
也有另⼀种实现⽅式,就是把每种商品遍历的个数放在01背包⾥⾯在遍历⼀遍。整体代码如下:
void test_multi_pack() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
vector<int> nums = {2, 3, 2};
int bagWeight = 10;
vector<int> dp(bagWeight + 1, 0);
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
// 以上为01背包,然后加⼀个遍历个数
for (int k = 1; k <= nums[i] && (j - k * weight[i]) >= 0; k++) { //遍历个数
dp[j] = max(dp[j], dp[j - k * weight[i]] + k * value[i]);
}
}
// 打印⼀下dp数组
for (int j = 0; j <= bagWeight; j++) {
cout << dp[j] << " ";
}
cout << endl;
}
cout << dp[bagWeight] << endl;
}
int main() {
test_multi_pack();
}
从代码⾥可以看出是01背包⾥⾯在加⼀个for循环遍历⼀个每种商品的数量。 和01背包还是如出⼀辙
的。当然还有那种⼆进制优化的⽅法,其实就是把每种物品的数量,打包成⼀个个独⽴的包。和以上在循环遍历上有所不同,因为是分拆为各个包最后可以组成⼀个完整背包,具体原理我就不做过多解释了,⼤家了解⼀下就⾏,⾯试的话基本不会考完这个深度了,感兴趣可以⾃⼰深⼊研究⼀波。
11.21 打家劫舍
力扣题号:198.打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1]
输出:4
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入:[2,7,9,3,1]
输出:12
解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 400
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/house-robber
思路
打家劫舍是dp解决的经典问题,动规五部曲分析如下:
1.确定dp数组及下标的含义
dp[i]:表示考虑下标[0,i]内的房间,最多可以偷窃的金额。
2.确定递推公式
决定dp[i]的因素就是第i个房间偷还是不偷。
- 如果偷第i个房间(一定偷),那么第i-1个房间一定是不偷的,所以最多可以偷窃的金额就由考虑第[0,i - 2]个房间确定,即dp[i-2]+nums[i]确定,即
dp[i] = dp[i - 2] + nums[i]; - 如果不偷第i个房间(一定不偷),那么就是要考虑偷(而不是一定偷)第i-1个房间,也就是dp[i-1]。
- 这两个情况要取最大值,即
max(dp[i - 2] + nums[i], dp[i -1]);
3.dp数组如何初始化
由递推公式可以得出,dp[0]和dp[1]是一定要初始化的。dp[0]意思是考虑第0个房间最大可以偷窃的金额,一定是nums[i]。而dp[1]是考虑[0,1]内房间最大可以偷窃的金额,因为不能连偷,所以dp[1]=max(nums[0], nums[1]);
4.确定遍历顺序
从递推公式可以看出,一定是从前往后遍历。
5.举例推导dp数组
 {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
vector<int> dp(nums.size(), 0);
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < nums.size(); i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[nums.size() - 1];
}
};
空间复杂度还可以优化,因为只用到dp[i-2]和dp[i-1],所以我们只定义大小 为2 的dp数组。代码如下:
题解
class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
vector<int> dp(2, 0);
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < nums.size(); i++) {
int temp = dp[1];
dp[1] = max(dp[0] + nums[i], dp[1]);
dp[0] = temp;
}
return dp[1];
}
};
11.22 打家劫舍Ⅱ
力扣题号:213.打家劫舍Ⅱ
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
示例 1:
输入:nums = [2,3,2]
输出:3
解释:你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。
示例 2:
输入:nums = [1,2,3,1]
输出:4
解释:你可以先偷窃 1 号房屋(金额 = 1),然后偷窃 3 号房屋(金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 3:
输入:nums = [1,2,3]
输出:3
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 1000
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/house-robber-ii
思路
这道题和上一题不同的就是要考虑首尾房间,不能同时偷,所以有三种情况:1.不考虑首尾房间;2.只考虑首房间;3.只考虑尾房间;注意我这里是用考虑这个词,考虑意味着在我们的计算中会计算到这种情况,但最终的结果并不一定是这种情况。 所以我们的情况二、三就都包含了情况一。分析到这,本题就比较简单了,我们把上一题的代码逻辑抽离出来,使其接受一个数组nums和一对起始位置,并返回在这对起始位置上按规则进行盗窃,所能得到的最大金额。整体代码如下:
题解
class Solution {
private:
int robRange(vector<int>& nums, int start, int end) {
if (start == end) return nums[start];//只有一个元素
vector<int> dp(nums.size(), 0);
dp[start] = nums[start];
dp[start + 1] = max(nums[start], nums[start + 1]);
for (int i = start + 2; i <= end; i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[end];
}
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
int result1 = robRange(nums, 0, nums.size() - 2);//去尾
int result2 = robRange(nums, 1, nums.size() - 1);//去头
return max(result1, result2);
}
};
同样的我们,优化空间复杂度。整体代码如下:
题解
class Solution {
private:
int robRange(vector<int>& nums, int start, int end) {
if (start == end) return nums[start];//只有一个元素
vector<int> dp(2, 0);
dp[0] = nums[start];
dp[1] = max(nums[start], nums[start + 1]);
for (int i = start + 2; i <= end; i++) {
int temp = dp[1];
dp[1] = max(dp[0] + nums[i], temp);
dp[0] = temp;
}
return dp[1];
}
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
int result1 = robRange(nums, 0, nums.size() - 2);//去尾
int result2 = robRange(nums, 1, nums.size() - 1);//去头
return max(result1, result2);
}
};
小结:成环之后还是难了⼀些的, 不少题解没有把“考虑房间”和“偷房间”说清楚。这就导致⼤家会有这样的困惑:情况三怎么就包含了情况⼀了呢? 本⽂图中最后⼀间房不能偷啊,偷了⼀定不是最优结果。所以我在本⽂重点强调了情况⼀⼆三是“考虑”的范围,⽽具体房间偷与不偷交给递推公式去抉择。这样⼤家就不难理解情况⼆和情况三包含了情况⼀了。
11.23 打家劫舍Ⅲ
力扣题号:337.打家劫舍Ⅲ
小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。
除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
给定二叉树的 root 。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。
示例 1:
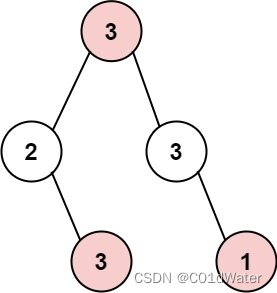
输入: root = [3,2,3,null,3,null,1]
输出: 7
解释: 小偷一晚能够盗取的最高金额 3 + 3 + 1 = 7
示例 2:
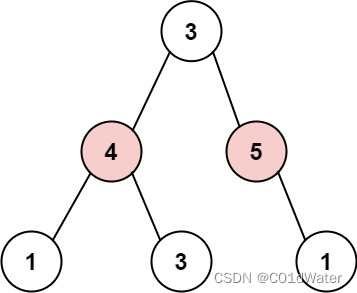
输入: root = [3,4,5,1,3,null,1]
输出: 9
解释: 小偷一晚能够盗取的最高金额 4 + 5 = 9
提示:
树的节点数在 [1, 104] 范围内
0 <= Node.val <= 104
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/house-robber-iii
11.23.1 暴力解法
思路
这道题⽬和 198.打家劫舍,213.打家劫舍II也是如出⼀辙,只不过这个换成了树。如果对树的遍历不够熟悉的话,那本题就有难度了。对于树的话,⾸先就要想到遍历⽅式,前中后序(深度优先搜索)还是层序遍历(⼴度优先搜索)。本题⼀定是要后序遍历,因为通过递归函数的返回值来做下⼀步计算。与198.打家劫舍,213.打家劫舍II⼀样,关键是要讨论当前节点抢还是不抢。如果抢了当前节点,两个孩⼦就不是动,如果没抢当前节点,就可以考虑抢左右孩⼦(注意这⾥说的是“考虑”)。
整体代码如下,当然是超时的。这个递归的过程中其实是有重复计算了。我们计算了root的四个孙⼦(左右孩⼦的孩⼦)为头结点的⼦树的情况,⼜计算了root的左右孩⼦为头结点的⼦树的情况,计算左右孩⼦的时候其实⼜把孙⼦计算了⼀遍。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int rob(TreeNode* root) {
if (root == NULL) return 0;//无节点
if (root->left == NULL && root->right == NULL) return root->val;//只有一个节点
//偷父节点
int val1 = root->val;
if (root->left) val1 += rob(root->left->left) + rob(root->left->right);//跳过root的左孩子
if (root->right) val1 += rob(root->right->left) + rob(root->right->right);//跳过root的右孩子
//不偷父节点
int val2 = rob(root->left) + rob(root->right);
return max(val1, val2);
}
};
11.23.2 记忆化递推
我们可以使用一个map把计算过的结果保存一下,如果计算过孙子,那么再计算孙子时就可以复用孙子节点的结果。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
unordered_map<TreeNode*, int> umap;//记录计算的结果
int rob(TreeNode* root) {
if (root == NULL) return 0;//无节点
if (root->left == NULL && root->right == NULL) return root->val;//只有一个节点
if (umap[root]) return umap[root];//如果umap里面已经有结果,则可以直接使用
//偷父节点
int val1 = root->val;
if (root->left) val1 += rob(root->left->left) + rob(root->left->right);//跳过root的左孩子
if (root->right) val1 += rob(root->right->left) + rob(root->right->right);//跳过root的右孩子
//不偷父节点
int val2 = rob(root->left) + rob(root->right);
umap[root] = max(val1, val2);
return max(val1, val2);
}
};
11.23.3 动态规划
在上⾯两种⽅法,其实对⼀个节点 投与不投得到的最⼤⾦钱都没有做记录,⽽是需要实时计算。⽽动态规划其实就是使⽤状态转移容器来记录状态的变化,这⾥可以使⽤⼀个⻓度为2的数组,记录当前节点偷与不偷所得到的的最⼤⾦钱。这道题⽬算是树形dp的⼊⻔题⽬,因为是在树上进⾏状态转移,我们在讲解⼆叉树的时候说过递归三部曲,那么下⾯我以递归三部曲为框架,其中融合动规五部曲的内容来进⾏讲解。
1.确定递归函数的参数和返回值
这里我们要计算一个节点偷与不偷的两个状态所得到的金钱,那么返回值就是一个长度为2的数组。参数为当前节点。
vector<int> robTree(TreeNode* cur) {}
其实这里返回的数组就是dp数组。所以dp数组(dp table)以及下标的含义:下标为0记录不偷该节点所得到的的最⼤⾦钱,下标为1记录偷该节点所得到的的最⼤⾦钱。所以本题dp数组就是⼀个⻓度为2的数组!那么有同学可能疑惑,⻓度为2的数组怎么标记树中每个节点的状态呢?别忘了在递归的过程中,系统栈会保存每⼀层递归的参数。如果还不理解的话,就接着往下看,看到代码就理解了哈。
2.确定终止条件
再遍历过程中如果遇到空节点,无论偷不偷都是0,就返回{0,0}。这也相当于dp数组的初始化。
3.确定遍历顺序
一定是使用后序遍历,因为递归函数的返回值被用作下一步的计算。通过递归左节点,得到左节点偷与不偷的金钱;通过递归右节点,得到右节点偷与不偷的金钱。
4.确定单层递归的逻辑
如果是偷当前节点,那么左右孩⼦就不能偷,val1 = cur->val + left[0] + right[0]; (如果对下标含义不理解就在回顾⼀下dp数组的含义)。如果不偷当前节点,那么左右孩⼦就可以偷,⾄于到底偷不偷⼀定是选⼀个最⼤的,所以:val2 = max(left[0], left[1]) + max(right[0], right[1]);最后当前节点的状态就是{val2, val1}; 即:{不偷当前节点得到的最⼤⾦钱,偷当前节点得到的最⼤⾦钱}
5.举例推导dp数组
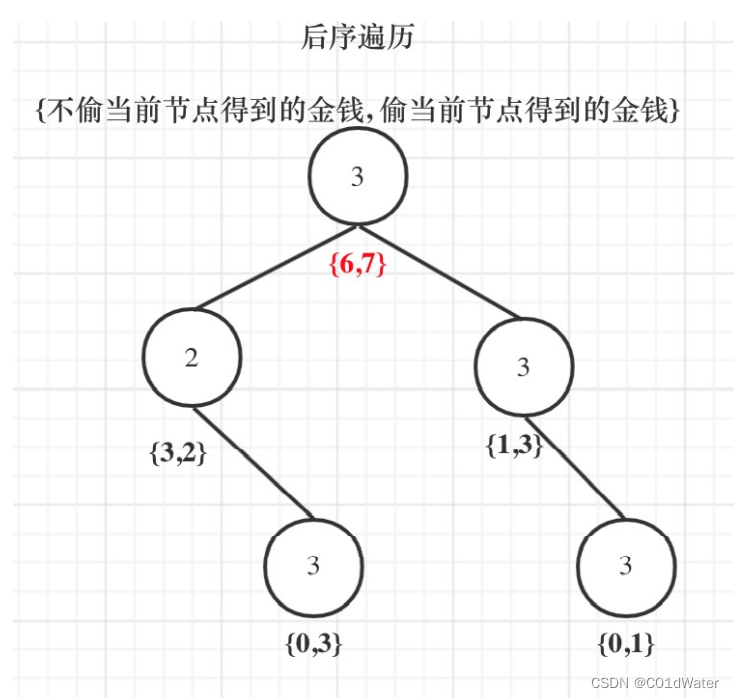
最后头节点就是取下标0和下标1的最大值就是最大金钱。
整体代码如下:
题解
class Solution {
public:
int rob(TreeNode* root) {
vector<int> result = robTree(root);
return max(result[0], result[1]);
}
//长度为2的数组,0:不偷,1:偷
vector<int> robTree(TreeNode* cur) {
if (cur == NULL) return vector<int>{0, 0};
vector<int> left = robTree(cur->left);
vector<int> right = robTree(cur->right);
// 偷cur
int val1 = cur->val + left[0] + right[0];
// 不偷cur
int val2 = max(left[0], left[1]) + max(right[0], right[1]);
return {val2, val1};
}
};
总结:这道题是树形DP的⼊⻔题⽬,通过这道题⽬⼤家应该也了解了,所谓树形DP就是在树上进⾏递归公式的
推导。所以树形DP也没有那么神秘!只不过平时我们习惯了在⼀维数组或者⼆维数组上推导公式,⼀下⼦换成了树,就需要对树的遍历⽅式⾜够了解!⼤家还记不记得我在讲解贪⼼专题的时候,讲到这道题⽬:贪⼼算法:我要监控⼆叉树!,这也是贪⼼算法在树上的应⽤。那我也可以把这个算法起⼀个名字,叫做树形贪⼼。















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









