







排序算法:
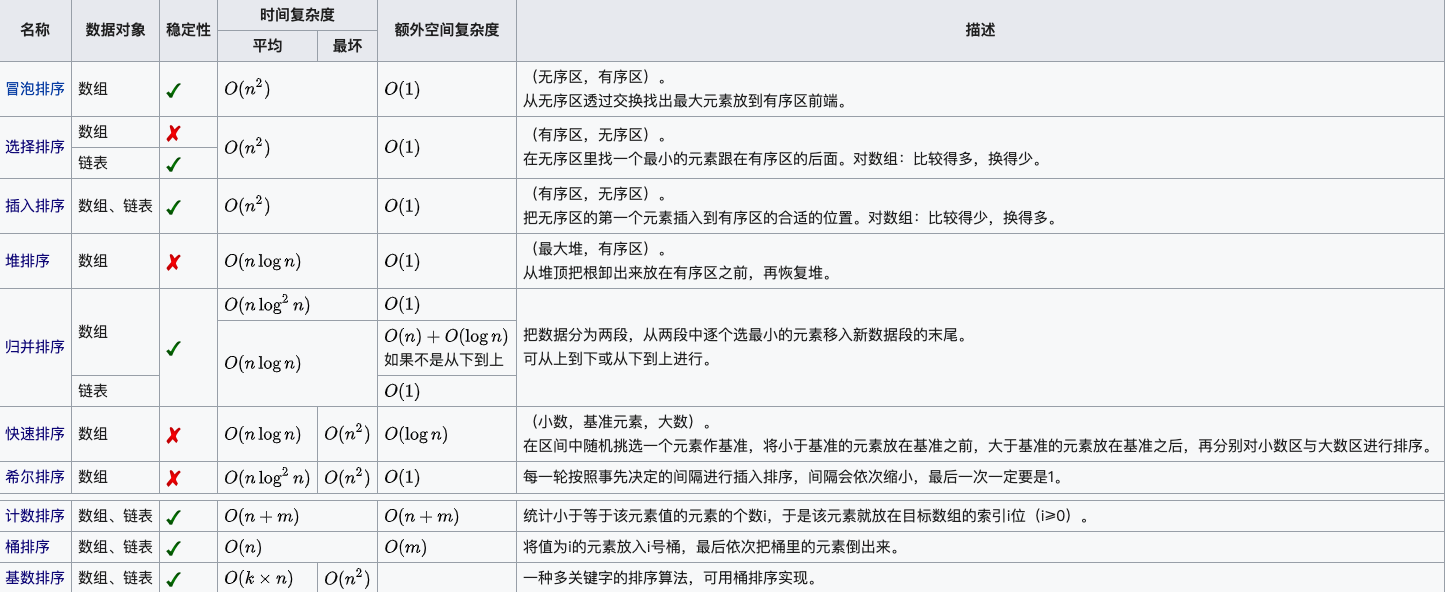
不同的排序方法的实现,通过Python代码进行复现。
定义待排数据为 num_list = [5,4,6,7,0,9,3,8,1,2]
https://leetcode-cn.com/leetbook/read/illustration-of-algorithm/ozzl1r/
1、冒泡排序
时间复杂度:O(N2)
空间复杂度:O(1)
稳定
描述:两两对比,数组的前一个与后一个进行对比,将更大的一个或者更小的一个进行传递,类似于🐟吐泡泡一样,故称为冒泡排序。
def bubble(nums):
for j in range(len(nums)):
for i in range(len(nums)-j-1):
if nums[i] > nums[i+1]:
nums[i], nums[i+1] = nums[i+1], nums[i]
return nums
2、选择排序
时间复杂度:O(N2)
空间复杂度:O(1)
不稳定
# 菜鸟小站给的样例
def select(num_list):
num = len(num_list)
for i in range(num-1):
minIndex = i
for j in range(i+1, num):
if num_list[j] < num_list[minIndex]:
minIndex = j
if i != minIndex:
num_list[i], num_list[minIndex] = num_list[minIndex], num_list[i]
return num_list
3、插入排序
时间复杂度:O(N2)
空间复杂度:O(1)
def insert(nums):
n = len(nums)
for i in range(1,n):
j = i - 1
key = nums[i]
while j >= 0 and key < nums[j]:
nums[j+1] = nums[j]
j -= 1
nums[j+1] = key
return nums
4、快速排序
时间复杂度:O(nlogn)
空间复杂度:O(N2)
def partition(nums, low, high):
i = low - 1
pivot = nums[high]
for j in range(low, high):
if nums[j] < pivot:
i+=1
nums[i],nums[j] = nums[j], nums[i]
nums[i+1], nums[high] = nums[high], nums[i+1]
return (i+1)
def quick(nums, low, high):
if low < high:
pi = partition(nums, low, high)
quick(nums, low, pi-1)
quick(nums, pi+1, high)
return nums
def quick(nums):
def quick_sort(l,r):
if l>=r:return
i,j = l,r
while i<j:
while i<j and nums[l] <= nums[j]: j-=1
while i<j and nums[l] >= nums[i]: i+=1
nums[i],nums[j] = nums[j],nums[i]
nums[i],nums[l] = nums[l],nums[i]
quick_sort(l,i-1)
quick_sort(i+1,r)
quick_sort(0,len(nums)-1)
return nums
5、希尔排序
时间复杂度:O(取决于增量数列)
空间复杂度:O(1)
def shell_sort(nums):
n = len(nums)
gap = n // 2
while gap:
for i in range(gap, n):
while i - gap >= 0 and nums[i - gap] > nums[i]:
nums[i - gap], nums[i] = nums[i], nums[i - gap]
i -= gap
gap //= 2
return nums
6、归并排序
稳定排序,外排序(占用额外内存),时间复杂度O(nlogn)O(nlogn)。
def merge_sort(nums):
if len(nums)<= 1:
return nums
mid = len(nums)//2
left = merge_sort(nums[:mid])
right = merge_sort(nums[mid:])
return merge(left,right)
def merge(left,right):
res = []
i, j = 0, 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
res.append(left[i])
i += 1
else:
res.append(right[j])
j += 1
res = res + left[i:]
res = res + right[j:]
return res
普通Leetcode
5、【动态规划】最长回文子串
class Solution:
def longestPalindrome(self, s: str) -> str:
n = len(s)
# 将一些异常状况抛出
if n<2:
return s
# 初始化DP数组
dp = [[False]*n for _ in range(n)]
# 对DP数据的内容进行调整
for i in range(n):
dp[i][i] = True
Left = 0
max_len = 1
for R in range(1,n):
for L in range(R):
# 如果不等于,证明LR无法作为最长回文子串的两端
if s[L] != s[R]:
dp[L][R] = False
# 如果长度小于2,即左右相等,中间无论是什么 都是回文串
else:
if R-L<=2:
dp[L][R] = True
else:
dp[L][R] = dp[L+1][R-1]
# 获取DP数组中的内容并保存
if dp[L][R] == True and R-L+1>max_len:
max_len = R-L+1
Left = L
return s[Left:Left+max_len]
27、【双指针】移除元素
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
i,j=0,0
for j in range(len(nums)):
if nums[j] == val:
j += 1
else:
nums[i] = nums[j]
j += 1
i += 1
return i
28、【KMP】实现 strStr()
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
n_hay = len(haystack)
n_ned = len(needle)
if n_ned == 0:
return 0
for i in range(n_hay-n_ned+1):
if haystack[i:i+n_ned] == needle:
return i
return -1
46、【回溯算法】全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
res = []
def backtrack(nums, track):
if (len(track)==len(nums)):
res.append(track[:])
return
for i in range(len(nums)):
if nums[i] in track:
continue
track.append(nums[i])
backtrack(nums,track)
track.pop()
backtrack(nums,[])
return res
47、【动态规划】剑指 Offer 47. 礼物的最大价值
在一个 m*n 的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于 0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格、直到到达棋盘的右下角。给定一个棋盘及其上面的礼物的价值,请计算你最多能拿到多少价值的礼物?
输入:
[
[1,3,1],
[1,5,1],
[4,2,1]
]
输出: 12
解释: 路径 1→3→5→2→1 可以拿到最多价值的礼物
# 建立状态转移方程来操作,其中由于grid矩阵时候后不再有用,故在grid上建立dp矩阵即可。
class Solution:
def maxValue(self, grid: List[List[int]]) -> int:
for i in range(len(grid)):
for j in range(len(grid[0])):
if i==0 and j == 0:
continue
if i==0:
grid[i][j] = grid[i][j] + grid[i][j-1]
elif j==0:
grid[i][j] = grid[i][j] + grid[i-1][j]
else:
grid[i][j] = grid[i][j] + max(grid[i-1][j],grid[i][j-1])
return grid[-1][-1]
56、【双向队列】剑指 Offer 59 - II. 队列的最大值
请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value、push_back 和 pop_front 的均摊时间复杂度都是O(1)。
若队列为空,pop_front 和 max_value 需要返回 -1
输入:
["MaxQueue","push_back","push_back","max_value","pop_front","max_value"]
[[],[1],[2],[],[],[]]
输出: [null,null,null,2,1,2]
import queue
class MaxQueue:
def __init__(self):
self.queue = queue.Queue()
self.deque = collections.deque()
def max_value(self) -> int:
return self.deque[0] if self.deque else -1
def push_back(self, value: int) -> None:
self.queue.put(value)
while self.deque and self.deque[-1] < value:
self.deque.pop()
self.deque.append(value)
def pop_front(self) -> int:
if self.queue.empty():
return -1
val = self.queue.get()
if val == self.deque[0]:
self.deque.popleft()
return val
88、【尾指针】合并两个有序数组
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组。
初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。你可以假设 nums1 的空间大小等于 m + n,这样它就有足够的空间保存来自 nums2 的元素。
class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
"""
Do not return anything, modify nums1 in-place instead.
"""
k = m + n -1
while m > 0 and n > 0:
if nums1[m-1] > nums2[n-1]:
nums1[k] = nums1[m-1]
m -= 1
else:
nums1[k] = nums2[n-1]
n -= 1
k -= 1
nums1[:n] = nums2[:n]
100、【二叉树】相同的树
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
# DFS方法
# 1、特例处理,如果比较两个根节点:如果两个根节点都是空,就返回true,如果其中一个为空,或者他们的值不同则返回False
# 2、如果节点的值相同,则开启下一轮递归内容。
class Solution:
def isSameTree(self, p: TreeNode, q: TreeNode) -> bool:
if not p and not q:
return True
elif not p or not q:
return False
elif p.val != q.val:
return False
else:
return self.isSameTree(p.left, q.left) and self.isSameTree(p.right, q.right)
**108、【二叉树】将有序数组转换为二叉搜索树**
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def sortedArrayToBST(self, nums: List[int]) -> TreeNode:
# 没有nums数组,说明传入为空,排除异常情况。
if not nums:
return None
mid = len(nums)//2
node = TreeNode(nums[mid])
left = nums[:mid]
right = nums[mid+1:]
node.left = self.sortedArrayToBST(left)
node.right = self.sortedArrayToBST(right)
return node
110、【平衡树】平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
# 这是一种自底向上的方法进行,首先进行后序遍历,之后便是判断每一层的信息。
# 方法一
class Solution:
def isBalanced(self, root: TreeNode) -> bool:
return self.recur(root) != -1
def recur(self,root):
if not root:
return 0
left = self.recur(root.left)
if left == -1:
return -1
right = self.recur(root.right)
if right == -1:
return -1
return max(left,right)+1 if abs(left-right) < 2 else -1
# 这是自顶向下的方法,其中depth是用于求树的深度,方法比较有效
class Solution:
def isBalanced(self, root: TreeNode) -> bool:
if not root:
return True
return abs(self.depth(root.left)-self.depth(root.right))<= 1 and \
self.isBalanced(root.left) and self.isBalanced(root.right)
def depth(self,root):
if not root:
return 0
return max(self.depth(root.left), self.depth(root.right)) + 1
111、【BFS】二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量
# 由于是要求最小深度,利用广度优先可以更快的找到叶子节点。
class Solution:
def minDepth(self, root: TreeNode) -> int:
if not root:
return 0
dq = [root]
depth = 1
while dq:
for _ in range(len(dq)):
tmp = dq.pop(0)
if not tmp.left and not tmp.right:
return depth
if tmp.left:
dq.append(tmp.left)
if tmp.right:
dq.append(tmp.right)
depth += 1
return depth
112、【DFS和BFS】路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。
# DFS
class Solution:
def hasPathSum(self, root: TreeNode, targetSum: int) -> bool:
if not root:
return False
if not root.left and not root.right:
return targetSum == root.val
return self.hasPathSum(root.left, targetSum-root.val) or self.hasPathSum(root.right, targetSum - root.val)
# BFS
class Solution:
def hasPathSum(self, root: TreeNode, targetSum: int) -> bool:
if not root:
return False
que = collections.deque()
que.append((root,root.val))
while que:
node, path = que.popleft()
if not node.left and not node.right and path == targetSum:
return True
if node.left:
que.append((node.left, path + node.left.val))
if node.right:
que.append((node.right, path + node.right.val))
return False
179、【快排应用】最大数
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
输入:nums = [10,2]
输出:"210"
class Solution:
def largestNumber(self, nums: List[int]) -> str:
def quick_sort(l,r):
if l>=r: return
i,j = l,r
while i<j:
while strs[i] + strs[r] >= strs[r] + strs[i] and i < j: i+=1
while strs[j] + strs[r] <= strs[r] + strs[j] and i < j: j-=1
strs[i], strs[j] = strs[j], strs[i]
strs[i], strs[r] = strs[r], strs[i]
quick_sort(l, i-1)
quick_sort(i+1, r)
if len(set(nums))==1 and nums[0] == 0:
return "0"
strs = [str(n) for n in nums]
quick_sort(0,len(nums)-1)
return "".join(strs)
202、【快慢指针、哈希表】快乐数
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 true ;不是,则返回 false 。
# 利用hashmap的思路去做,防止卡在某一个循环中一直出不来了。
class Solution:
def sumcount(self, n):
sum = 0
while(n>0):
bit = n % 10
sum += bit*bit
n = n//10
return sum
def isHappy(self, n: int) -> bool:
seen = set()
while n!= 1 and n not in seen:
seen.add(n)
n = self.sumcount(n)
return n==1
# 利用快慢指针方式,可以破坏循环,跳出循环。
class Solution:
def sumcount(self, n):
sum = 0
while(n>0):
bit = n % 10
sum += bit*bit
n = n//10
return sum
def isHappy(self, n: int) -> bool:
fast = self.sumcount(n)
low = n
while low!= 1 and fast!=low:
low = self.sumcount(low)
fast = self.sumcount(fast)
fast = self.sumcount(fast)
return low==1
239、【动态规划】滑动窗口最大值
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回滑动窗口中的最大值。
# 动态规划问题,将函数分成两段,第一段可以认为未形成窗口、第二段可以是形成窗口后的对比。
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
if not nums or k==0: return []
# 未形成窗口
deque = collections.deque()
for i in range(k):
while deque and deque[-1] < nums[i]:
deque.pop()
deque.append(nums[i])
res = [deque[0]]
# 形成窗口
for i in range(k,len(nums)):
if deque[0] == nums[i-k]:
deque.popleft()
while deque and deque[-1] < nums[i]:
deque.pop()
deque.append(nums[i])
res.append(deque[0])
return res
283、【双指针】移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
class Solution:
def moveZeroes(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
i = -1
for j in range(len(nums)):
if nums[j] != 0:
i += 1
nums[i],nums[j] = nums[j],nums[i]
给定一个数组 nums,编写一个函数将所有 0 移动到数组的开始,同时保持非零元素的相对顺序。
class Solution:
def moveZeroes(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
i = len(nums)
for j in range(len(nums)-1,-1,-1):
if nums[j] != 0:
i -= 1
nums[i],nums[j] = nums[j],nums[i]
347、【hashmap+快排】前 K 个高频元素
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
"""
利用python自带的工具包实现!
"""
hashmap = {}
for num in nums:
if num not in hashmap:
hashmap[num] = 1
else:
hashmap[num] += 1
num_count = [[x,hashmap[x]] for x in hashmap]
topK = self.findT(num_count, k, 0, len(num_count)-1)
return [item[0] for item in topK]
"""
利用python自带的工具包实现!
"""
# count = collections.Counter(nums)
# return list(count.items())
# return [item[0] for item in count.most_common(k)]
def findT(self, num_count,k,low,high):
pivot = random.randint(low, high)
num_count[low], num_count[pivot] = num_count[pivot], num_count[low]
base = num_count[low][1]
i = low
for j in range(low+1, high+1):
if num_count[j][1] > base:
i += 1
num_count[i], num_count[j] = num_count[j], num_count[i]
num_count[low], num_count[i] = num_count[i], num_count[low]
if i == k - 1:
return num_count[:k]
elif i > k - 1:
return self.findT(num_count,k,low,i-1)
else:
return self.findT(num_count,k,i+1, high)
687、【栈】有效的括号字符串zha
class Solution:
def checkValidString(self, s: str) -> bool:
# 建立两个空的栈,用来存放(和*
stack_left = []
stack_star = []
# 遍历字符串s
for i in range(len(s)):
if s[i]=="(":
stack_left.append(i)
elif s[i]=="*":
stack_star.append(i)
elif s[i]==")":
if stack_left:
stack_left.pop()
elif stack_star:
stack_star.pop()
else:
return False
# 结束遍历后,如果左括号还有,查看是否还有*,有的话也要看(和*的出现顺序,所以在elif中对比了对应的index。
while stack_left:
if not stack_star:
return False
elif stack_left[-1] > stack_star[-1]:
return False
else:
stack_star.pop()
stack_left.pop()
return True
783、【二叉树】二叉搜索树节点最小距离
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
# 最笨的方法,先把书里面的所有值都保存出来,然后再进行下一步操作。
class Solution:
def minDiffInBST(self, root: TreeNode) -> int:
if not root: return
queue = collections.deque()
queue.append(root)
res = [root.val]
while queue:
for _ in range(len(queue)):
node = queue.popleft()
if node.left:
queue.append(node.left)
res.append(node.left.val)
if node.right:
queue.append(node.right)
res.append(node.right.val)
res.sort()
sub = []
for i in range(len(res)-1):
sub.append(res[i+1] - res[i])
return min(sub)
算法改进:对于二叉搜索树而言,中序遍历之后可以得到有序。
class Solution:
def minDiffInBST(self, root: TreeNode) -> int:
self.res = []
self.inOrder(root)
sub = []
for i in range(len(self.res)-1):
sub.append(self.res[i+1]- self.res[i])
return min(sub)
def inOrder(self, root):
if not root: return
self.inOrder(root.left)
self.res.append(root.val)
self.inOrder(root.right)
897、递增顺序搜索树
给你一棵二叉搜索树,请你 按中序遍历 将其重新排列为一棵递增顺序搜索树,使树中最左边的节点成为树的根节点,并且每个节点没有左子节点,只有一个右子节点。

# 利用中序访问节点,将节点保存或者将数值保存后放入参数中。
class Solution:
def __init__(self):
self.res = []
def increasingBST(self, root: TreeNode) -> TreeNode:
if not root:return
# self.res = []
self.inOrder(root)
dummy = TreeNode(-1)
cur = dummy
for value in self.res:
node = TreeNode(value)
cur.right = node
cur = cur.right
# node.left = node.right = None
# cur.right = node
# cur = cur.right
return dummy.right
def inOrder(self,root):
if not root: return
self.inOrder(root.left)
self.res.append(root.val)
self.inOrder(root.right)
剑指offer
03、【输出非重复数字】在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
# 利用hashmap方法进行解答
class Solution:
def findRepeatNumber(self, nums: List[int]) -> int:
hashmap = {}
for num in nums:
if num in hashmap:
return num
hashmap[num] = 1
改进:如果输出整个重复的列表呢?
# 结合set方法进行操作
class Solution:
def findRepeatNumber(self, nums: List[int]) -> int:
dup = list(set(nums))
for i in range(len(dup)):
nums.remove(dup[i])
out = list(set(nums))
return out
改进:如果输出不重复的元素呢?
# 利用数学知识巧妙解答
class Solution:
def singleNumber(self, nums: List[int]) -> int:
return 2*sum(set(nums))-sum(nums)
04、【二维数组查找】在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
# 利用矩阵特性进行操作
class Solution:
def findNumberIn2DArray(self, matrix: List[List[int]], target: int) -> bool:
i,j = len(matrix)-1,0
while i>=0 and j<len(matrix[0]):
if matrix[i][j] > target:
i = i -1
elif matrix[i][j] < target:
j += 1
else:
return True
return False
# 利用递归的方法进行查找,好理解但是不好操作。
class Solution:
def findNumberIn2DArray(self, matrix: List[List[int]], target: int) -> bool:
if not matrix:
return False
def search_backtrack(left, right, up, down):
if left > right or up > down:
return False
elif matrix[up][left] > target or matrix[down][right] < target:
return False
mid = (left+right)//2
row = up
while row <= down and matrix[row][mid] <= target:
if matrix[row][mid] == target:
return True
row += 1
return search_backtrack(left, mid-1, row, down) or search_backtrack(mid+1, right, up, row -1)
return search_backtrack(0, len(matrix[0])-1, 0 , len(matrix)-1)
05、【字符串内容替换】请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
# 利用取巧的办法
class Solution:
def replaceSpace(self, s: str) -> str:
s_out = s.replace(" ", '%20')
return s_out
# 由于字符串在python中属于不可变类型,所以新建一个s_out列表来保存,输出的时候将列表转换成对应的字符串进行输出
class Solution:
def replaceSpace(self, s: str) -> str:
s_out = []
for c in s:
if c==' ':
s_out.append('%20')
else:
s_out.append(c)
return ''.join(s_out)
06、【链表val逆向输出】输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
class Solution:
def reversePrint(self, head: ListNode) -> List[int]:
stack = []
out = []
while head:
stack.append(head.val)
head = head.next
for _ in range(len(stack)):
out.append(stack.pop())
return out
算法改进:
class Solution:
def reversePrint(self, head: ListNode) -> List[int]:
stack = []
while head:
stack.append(head.val)
head = head.next
return stack[::-1]
07、【树】重建二叉树。
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
# 方法一
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
def recur(root, left, right):
# 首先指定跳出循环的条件
if left > right:
return None
# 建立根节点并用于后期回溯操作
node = TreeNode(preorder[root])
i = dic[preorder[root]]
# 在提前建立好的hash表中进行寻址操作,根据前序中根节点找到对应中序的位置
node.left = recur(root+1, left, i-1)
# 建立左连接与右连接
node.right = recur(root+1+i-left, i+1, right)
return node
dic, preorder = {}, preorder
for i in range(len(inorder)):
dic[inorder[i]] = i
return recur(0, 0, len(inorder)-1)
# 方法二
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
def myBuildTree(preorder_left: int, preorder_right: int, inorder_left: int, inorder_right: int):
if preorder_left > preorder_right:
return None
# 前序遍历中的第一个节点就是根节点
preorder_root = preorder_left
# 在中序遍历中定位根节点
inorder_root = index[preorder[preorder_root]]
# 先把根节点建立出来
root = TreeNode(preorder[preorder_root])
# 得到左子树中的节点数目
size_left_subtree = inorder_root - inorder_left
# 递归地构造左子树,并连接到根节点
# 先序遍历中「从 左边界+1 开始的 size_left_subtree」个元素就对应了中序遍历中「从 左边界 开始到 根节点定位-1」的元素
root.left = myBuildTree(preorder_left + 1, preorder_left + size_left_subtree, inorder_left, inorder_root - 1)
# 递归地构造右子树,并连接到根节点
# 先序遍历中「从 左边界+1+左子树节点数目 开始到 右边界」的元素就对应了中序遍历中「从 根节点定位+1 到 右边界」的元素
root.right = myBuildTree(preorder_left + size_left_subtree + 1, preorder_right, inorder_root + 1, inorder_right)
return root
n = len(preorder)
# 构造哈希映射,帮助我们快速定位根节点
index = {element: i for i, element in enumerate(inorder)}
return myBuildTree(0, n - 1, 0, n - 1)
9、[用栈实现队列]用两个栈实现一个队列。
队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
输入:
["CQueue","deleteHead","appendTail","appendTail","deleteHead","deleteHead"]
[[],[],[5],[2],[],[]]
输出:[null,-1,null,null,5,2]
# 分别用两个栈实现队列的效果
class CQueue:
def __init__(self):
self.stack1 = []
self.stack2 = []
def appendTail(self, value: int) -> None:
self.stack1.append(value)
def deleteHead(self) -> int:
if not self.stack2:
if not self.stack1:
return -1
while self.stack1:
self.stack2.append(self.stack1.pop())
return self.stack2.pop()
10、【斐波那契数列】写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N))。
斐波那契数列的定义如下:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
# 在leetcode上会出现超时情况,这是因为每种运算都会被执行至少两次。
class Solution:
def fib(self, n: int) -> int:
if n == 1:
return 1
if n == 0:
return 0
return (self.fib(n-1) + self.fib(n-2))%1000000007
# 利用dp方法进行,运算
class Solution:
def fib(self, n: int) -> int:
a,b = 0,1
for _ in range(n):
a,b = b, a+b
return a%1000000007
11、【数组】把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。
输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。
# 自己做的方法比较简单
class Solution:
def minArray(self, numbers: List[int]) -> int:
if len(numbers) == 0:
return numbers[0]
for i in range(len(numbers)-1):
if numbers[i+1] < numbers[i]:
return numbers[i+1]
return numbers[0]
12、【搜索和回溯】矩阵中的路径
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。

class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
def dfs(i,j,k):
# 所有的dfs深度遍历算法,都可以拆分成如下几个步骤
# 1、判断跳出迭代或者搜索的步骤
# 2、将遍历过的数据进行摸出
# 3、开启dfs算法
# 4、返回值
if not 0<=i<len(board) or not 0<=j<len(board[0]) or board[i][j] != word[k]: return False
if k == len(word)-1: return True
board[i][j] = ''
res = dfs(i-1,j,k+1) or dfs(i+1,j,k+1) or dfs(i,j-1,k+1) or dfs(i,j+1,k+1)
board[i][j] = word[k]
return res
for i in range(len(board)):
for j in range(len(board[0])):
if dfs(i,j,0):
return True
return False
13、【搜索与回溯】机器人的运动范围
地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格 [35, 37] ,因为3+5+3+7=18。但它不能进入方格 [35, 38],因为3+5+3+8=19。请问该机器人能够到达多少个格子?

class Solution:
def movingCount(self, m: int, n: int, k: int) -> int:
def dfs(i,j,si,sj):
if i>=m or j>=n or k < si+sj or (i,j) in visited:
return 0
visited.add((i,j))
return 1+dfs(i+1,j,si+1 if (i+1)%10 else si-8,sj)+dfs(i,j+1,si,sj+1 if (j+1)%10 else sj-8)
visited = set()
return dfs(0,0,0,0)
宽度优先遍历
class Solution:
def movingCount(self, m: int, n: int, k: int) -> int:
queue,visited = [(0,0,0,0)], set()
while queue:
i,j,si,sj = queue.pop(0)
if i >= m or j >= n or k < si+sj or (i,j) in visited: continue
visited.add((i,j))
queue.append((i+1,j,si+1 if (i+1)%10 else si-8, sj))
queue.append((i,j+1,si,sj+1 if (j+1)%10 else sj-8))
return len(visited)
15、【二进制】二进制中数1的个数?
请实现一个函数,输入一个整数(以二进制串形式),输出该数二进制表示中 1 的个数。例如,把 9 表示成二进制是 1001,有 2 位是 1。因此,如果输入 9,则该函数输出 2。
# 利用python语言的特性进行取巧,
# 存在几点不足,将二进制前无用的0给抹去,例如将00000000000000001010 -> 0b1010
class Solution:
def hammingWeight(self, n: int) -> int:
return bin(n).count('1')
# 若题目中提出求0的个数
return len(n) - bin(n).count('1')
# 利用位运算方法对
class Solution:
def hammingWeight(self, n: int) -> int:
res = 0
while n:
res += n & 1
n >>= 1
return res
17、【数组、幂次】打印从1到最大的n位数?
输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。
# 最简单的方法,利用幂次构造然后排列行程数组
class Solution:
def printNumbers(self, n: int) -> List[int]:
return list(range(1, 10 ** n))
改进:如果返回的要求不再限制范围,而是通过str进行输出?
# 需要考虑大数问题,防止出现大数越界问题。
18、【链表】删除链表的节点
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
# 利用双指针的方法进行操作,
class Solution:
def deleteNode(self, head: ListNode, val: int) -> ListNode:
if not head:
return None
if head.val == val:
return head.next
pre,cur = head,head.next
while cur and cur.val != val:
pre, cur = cur, cur.next
if cur:
pre.next = cur.next
return head
21、【列表】奇偶分离
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。
# 利用两个数组对内容进行整合,一个存放奇数,一个放偶数。
class Solution:
def exchange(self, nums: List[int]) -> List[int]:
odd = []
even = []
for num in nums:
if num % 2 == 0:
even.append(num)
else:
odd.append(num)
return odd + even
# 利用双指针的方法进行操作。
class Solution:
def exchange(self, nums: List[int]) -> List[int]:
i, j = 0, len(nums)-1
while i < j:
while i < j and nums[i]%2==1:
i += 1
while i < j and nums[j]%2==0:
j -= 1
nums[i], nums[j] = nums[j], nums[i]
return nums
22、【链表】链表中倒数第K个节点
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。
例如,一个链表有 6 个节点,从头节点开始,它们的值依次是 1、2、3、4、5、6。这个链表的倒数第 3 个节点是值为 4 的节点。
# 1、遍历全部链表得到总长度
# 2、然后得到位置
# 3、输出对应的链表头
class Solution:
def getKthFromEnd(self, head: ListNode, k: int) -> ListNode:
value = []
oth = ListNode(None)
oth = head
while oth:
value.append(oth.val)
oth = oth.next
up = len(value) - k
for _ in range(up):
head = head.next
return head
# 利用双指针进行操作
class Solution:
def getKthFromEnd(self, head: ListNode, k: int) -> ListNode:
before, after = head, head
for _ in range(k):
if not after:
return None
after = after.next
while after:
before, after = before.next, after.next
return before
24、【链表】反转链表
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
# 利用栈的方法将链表中的值取出,然后再一一赋值。
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
if not head:
return None
stack = []
while head:
stack.append(head.val)
head = head.next
pre = ListNode(stack.pop())
cur = pre
while stack:
p = ListNode(stack.pop())
cur.next = p
cur = cur.next
return pre
# 利用链表本身的概念去操作,比较难理解。三个指针变量相互表示,将进入函数的链表调换位置。
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
cur,pre = head, None
while cur:
tmp = cur.next
cur.next = pre
pre = cur
cur = tmp
return pre
# 利用魔法糖的方法使得有效减少空间复杂度
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
cur, pre = head, None
while cur:
cur.next, cur, pre = pre, cur.next, cur
return pre
25、【链表】合并连个排序的链表
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
# 建立一个新的链表进行操作,数值交替保存
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
basic = ListNode(None)
node = basic
while l1 and l2:
if l1.val >= l2.val:
basic.next = l2
l2 = l2.next
else:
basic.next = l1
l1 = l1.next
basic = basic.next
if l1:
basic.next = l1
if l2:
basic.next = l2
return node.next
# 通过递归的方法进行调用,难理解
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
if not l1:
return l2
if not l2:
return l1
if l1.val < l2.val:
l1.next = self.mergeTwoLists(l1.next, l2)
return l1
else:
l2.next = self.mergeTwoLists(l1, l2.next)
return l2
26、【搜索,二叉树】树的子结构

# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
def recur(a,b):
# 成功条件
if not b:
return True
# 失败条件
if not a or a.val != b.val:
return False
# 进入迭代
return recur(a.left,b.left) and recur(a.right, b.right)
# 返回bool值,AB是否都存在,开启递归,判断B的开头在哪,开始A和B的相同对比
return bool(A and B) and (recur(A,B) or self.isSubStructure(A.left,B) or self.isSubStructure(A.right, B))
27、【二叉树】二叉树的镜像
请完成一个函数,输入一个二叉树,该函数输出它的镜像。
# 采用递归的方法进行调用
class Solution:
def mirrorTree(self, root: TreeNode) -> TreeNode:
if not root: return # 判断对应的root节点在不在
root.left, root.right = root.right, root.left # 采用python的平行赋值方法进行
self.mirrorTree(root.left) # 分别调用左右节点
self.mirrorTree(root.right)
return root
# 采用辅助栈的方法进行调用
class Solution:
def mirrorTree(self, root: TreeNode) -> TreeNode:
if not root: return
stack = [root]
while stack:
node = stack.pop()
if node.left:
stack.append(node.left)
if node.right:
stack.append(node.right)
node.left, node.right = node.right, node.left
return root
28、【二叉树】对称二叉树
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
# 利用递归的方法不断优化
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
def isequ(a, b):
if not a and not b: return True
if not a or not b or a.val != b.val: return False
return isequ(a.left, b.right) and isequ(b.left, a.right)
return isequ(root.left, root.right) if root else True
# 辅助栈法,精妙绝伦
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
if not root: return True
q = []
q.append(root.left)
q.append(root.right)
while len(q)>0:
A = q.pop(0)
B = q.pop(0)
if not A and not B: continue
if not A or not B or A.val != B.val:
return False
q.append(A.left)
q.append(B.right)
q.append(A.right)
q.append(B.left)
return True
29、【二维矩阵】顺时针打印矩阵
# 找到边界制约条件后,再继续处理
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
if not matrix: return []
top, left = 0, 0
bottom, right = len(matrix)-1, len(matrix[0])-1
res = []
while True:
for i in range(left,right+1):
res.append(matrix[top][i])
top += 1
if top > bottom: break
for i in range(top,bottom+1):
res.append(matrix[i][right])
right -= 1
if right < left: break
for i in range(right, left-1, -1):
res.append(matrix[bottom][i])
bottom -= 1
if bottom < top: break
for i in range(bottom,top-1,-1):
res.append(matrix[i][left])
left += 1
if left > right: break
return res
32、【二叉树】从上到下打印二叉树
Leetcode:从上到下打印二叉树
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印,最后仅输出一个列表表示全部的内容。
# 利用辅助栈的方法去尝试,第一次利用递归方法,但是递归方法的回溯条件问题导致代码会优先DFS操作,不太好实现本题中的BFS。
class Solution:
def levelOrder(self, root: TreeNode) -> List[int]:
if not root: return []
res = [root.val]
que = [root]
while que:
node = que.pop(0)
if node.left:
que.append(node.left)
res.append(node.left.val)
if node.right:
que.append(node.right)
res.append(node.right.val)
return res
改进:
# 要求输出格式为
[
[3],
[9,20],
[15,7]
]
# 同上内容,利用辅助栈的方法去操作。
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root: return []
res = []
res.append([root.val])
# 相对于list.pop(0)他的时间复杂度为O(n),通过collections.deque底层是通过链表的方式表示,速度会更快。
queue = collections.deque()
queue.append(root)
while queue:
tmp = []
for _ in range(len(queue)):
node = queue.popleft()
if node.left:
queue.append(node.left)
tmp.append(node.left.val)
if node.right:
queue.append(node.right)
tmp.append(node.right.val)
if tmp:
res.append(tmp)
return res
改进:
# 要求输出格式中,奇数行正向输出,偶数行逆向输出
# 在第二个上做点基础调整,主要利用flag标签为进行调整,输出顺序
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root: return []
res = []
queue = collections.deque()
queue.append(root)
res.append([root.val])
flag = -1
while queue:
tmp = []
for _ in range(len(queue)):
node = queue.popleft()
if node.left:
queue.append(node.left)
tmp.append(node.left.val)
if node.right:
queue.append(node.right)
tmp.append(node.right.val)
flag *= -1
if tmp:
if flag < 0:
res.append(tmp)
else:
res.append(tmp[::-1])
return res
35、【链表】复杂链表的复制
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
# 方法一:这个思路主要是通过字典,第一次遍历将每一个节点都保存在字典中,第二次遍历将各类关系进行保存即可。
"""
# Definition for a Node.
class Node:
def __init__(self, x: int, next: 'Node' = None, random: 'Node' = None):
self.val = int(x)
self.next = next
self.random = random
"""
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
if not head: return
dic = {}
cur = head
while cur:
dic[cur] = Node(cur.val)
cur = cur.next
cur = head
while cur:
dic[cur].next = dic.get(cur.next)
dic[cur].random = dic.get(cur.random)
cur = cur.next
return dic[head]
# 方法二:这个方法比较困难,难以理解。可以尝试一下!
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
if not head: return
cur = head
while cur:
tmp = Node(cur.val)
tmp.next = cur.next
cur.next = tmp
cur = tmp.next
cur = head
while cur:
if cur.random:
cur.next.random = cur.random.next
cur = cur.next.next
cur = res = head.next
pre = head
while cur.next:
pre.next = pre.next.next
cur.next = cur.next.next
pre = pre.next
cur = cur.next
return res
39、【数组】数组中出现次数超过一半的数字
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
# 方法一:hashmap
# hashmap字典完成,建立字典,然后判断列表中的字符是否出现在字典中,然后进行判断。
class Solution:
def majorityElement(self, nums: List[int]) -> int:
hashmap = {}
n = len(nums)
if n==1:
return nums[0]
for i in nums:
if i not in hashmap:
hashmap[i] = 1
else:
hashmap[i] += 1
if hashmap[i] > n//2:
return i
# 方法二:利用双指针与排序的方法
class Solution:
def majorityElement(self, nums: List[int]) -> int:
n = len(nums)
if n==1:
return nums[0]
nums.sort()
i,j = 0,1
while True:
if nums[i] == nums[j]:
j += 1
if j - i >= n//2+1:
return nums[i]
else:
i += 1
# 方法三:利用众投方式,类似多人攻擂,最后的获胜者就是众数,这样的方法只适用于众数。
class Solution:
def majorityElement(self, nums: List[int]) -> int:
votes = 0
for num in nums:
if votes == 0:
x = num
if x == num:
votes += 1
else:
votes -= 1
return x
40、【数组】最小的k个数
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
class Solution:
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
arr.sort()
res = []
for _ in range(k):
res.append(arr.pop(0))
return res
这题可以认为是快排
# 利用快排的思路解决问题,快速选择算法
class Solution:
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
n = len(arr)
if k >= n:
return arr
def quick_sort(l,r):
i,j = l,r
while i < j:
while i < j and arr[j]>=arr[l]:
j -= 1
while i < j and arr[i] <= arr[l]:
i += 1
arr[i],arr[j] = arr[j],arr[i]
arr[l], arr[i] = arr[i], arr[l]
if k < i:
return quick_sort(l, i-1)
if k > i:
return quick_sort(i+1, r)
return arr[:k]
return quick_sort(0, n-1)
42、【动态规划】连续子数组的最大和
输入一个整型数组,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
for i in range(1, len(nums)):
nums[i] += max(nums[i-1],0)
return max(nums)
49、【三指针】丑数丑数
我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。(1也是)
# 将三个指针指向默认的1地址,然后不断输出最小的那个
class Solution:
def nthUglyNumber(self, n: int) -> int:
i2,i3,i5 = 0,0,0
res = [1]
for _ in range(n-1):
ugly = min(res[i2]*2, res[i3]*3, res[i5]*5)
if ugly == res[i2]*2:
i2 += 1
if ugly == res[i3]*3:
i3 += 1
if ugly == res[i5]*5:
i5 += 1
res.append(ugly)
return res[-1]
【附加题】丑数
给你一个整数 n ,请你判断 n 是否为 丑数 。如果是,返回 true ;否则,返回 false 。
丑数 就是只包含质因数 2、3 或 5 的正整数。
class Solution:
def isUgly(self, n: int) -> bool:
if n <= 0:
return False
while(n%2==0):
n //= 2
while(n%3==0):
n //= 3
while(n%5==0):
n //= 5
return n==1
50、【哈希表】第一个只出现一次的字符
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。
# 利用哈希表完成任务
class Solution:
def firstUniqChar(self, s: str) -> str:
if not s: return ' '
hashmap = {}
for a in s:
if a not in hashmap:
hashmap[a] = 0
if a in hashmap:
hashmap[a] += 1
for a in s:
if hashmap[a] == 1:
return a
return ' '
52、【链表】两个链表的第一个公共子节点
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
node1, node2 = headA, headB
while node1 != node2:
if node1:
node1 = node1.next
else:
node1 = headB
if node2:
node2 = node2.next
else:
node2 = headA
return node1
53、【二分法、数组】在排序数组中查找数字
# 定义两个二分函数,一个寻找左边界,一个寻找右边界。
class Solution:
def search(self, nums: List[int], target: int) -> int:
def left_search(nums,target):
l,r = 0, len(nums)-1
while l <= r:
mid = (l+r)//2
if nums[mid] == target:
r = mid -1
if nums[mid] < target:
l = mid + 1
if nums[mid] > target:
r = mid -1
return l
def right_search(nums,target):
l,r = 0, len(nums)-1
while l <= r:
mid = (l+r)//2
if nums[mid] == target:
l = mid + 1
if nums[mid] < target:
l = mid + 1
if nums[mid] > target:
r = mid -1
return r
return right_search(nums,target) - left_search(nums, target) + 1
# 优化二叉树
class Solution:
def search(self, nums: List[int], target: int) -> int:
l,r = 0, len(nums)-1
# 寻找右边界
while l<=r:
m = (l+r)//2
if nums[m] <= target:
l = m + 1
else:
r = m -1
rihgt = l
l = 0
while l <= r:
m = (l+r)//2
if nums[m] >= target:
r = m -1
else:
l = m + 1
left = r
return rihgt-left -1
54、【二叉树】二叉搜索树的第K大节点
# 方法一:还是利用树转数组的方法,在对数组进行排序
class Solution:
def kthLargest(self, root: TreeNode, k: int) -> int:
if not root: return 0
res = []
res.append(root.val)
queue = collections.deque()
queue.append(root)
while queue:
for _ in range(len(queue)):
node = queue.popleft()
if node.left:
queue.append(node.left)
res.append(node.left.val)
if node.right:
queue.append(node.right)
res.append(node.right.val)
res.sort()
return res[-k]
# 方法二:利用逆序中序遍历操作
class Solution:
def kthLargest(self, root: TreeNode, k: int) -> int:
res = []
def dfs(root):
if not root: return
dfs(root.right)
res.append(root.val)
dfs(root.left)
dfs(root)
return res[k-1]
# 方法三:提前结束搜索过程,只需要排前k个就足够了
class Solution:
def kthLargest(self, root: TreeNode, k: int) -> int:
def bfs(root):
if not root: return
bfs(root.right)
if self.k == 0: return
self.k -= 1
if self.k == 0:
self.val = root.val
bfs(root.left)
self.k = k
bfs(root)
return self.val
55-I、【二叉树】输出二叉树的深度
# 利用之前学的输出二叉树的val,然后看有多少个一维数组就可以了,但是方法比较蠢
class Solution:
def maxDepth(self, root: TreeNode) -> int:
if not root: return 0
res = []
res.append([root.val])
# 相对于list.pop(0)他的时间复杂度为O(n),通过collections.deque底层是通过链表的方式表示,速度会更快。
queue = collections.deque()
queue.append(root)
while queue:
tmp = []
for _ in range(len(queue)):
node = queue.popleft()
if node.left:
queue.append(node.left)
tmp.append(node.left.val)
if node.right:
queue.append(node.right)
tmp.append(node.right.val)
if tmp:
res.append(tmp)
return len(res)
# 二叉树的后序遍历,DFS,深度优先便利(Depth First Search),主要采用递归的思路完成任务
class Solution:
def maxDepth(self, root: TreeNode) -> int:
if not root: return 0
return max(self.maxDepth(root.left), self.maxDepth(root.right)) + 1
# 可以认为是第一种方法的简单变化,层序遍历,BFS(bidth frist search)
class Solution:
def maxDepth(self, root: TreeNode) -> int:
if not root: return 0
count = 1
# 相对于list.pop(0)他的时间复杂度为O(n),通过collections.deque底层是通过链表的方式表示,速度会更快。
queue = collections.deque()
queue.append(root)
while queue:
tmp = []
for _ in range(len(queue)):
node = queue.popleft()
if node.left:
queue.append(node.left)
tmp.append(node.left.val)
if node.right:
queue.append(node.right)
tmp.append(node.right.val)
if tmp:
count += 1
return count
55-II、【二叉树】平衡二叉树
输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。
class Solution:
def depth(self, root):
if not root: return 0
return max(self.depth(root.left), self.depth(root.right)) + 1
def isBalanced(self, root: TreeNode) -> bool:
if not root: return True
return abs(self.depth(root.left)-self.depth(root.right)) <= 1 /
and self.isBalanced(root.left) and self.isBalanced(root.right)
class Solution:
def isBalanced(self, root: TreeNode) -> bool:
def recur(root):
if not root: return 0
left = recur(root.left)
if left == -1:
return -1
right = recur(root.right)
if right == -1:
return -1
if abs(left - right) <= 1:
return max(left,right) + 1
else:
return -1
return recur(root) != -1
56、【哈希表】剑指 Offer 56 - I. 数组中数字出现的次数
class Solution:
def singleNumbers(self, nums: List[int]) -> List[int]:
hashmap = {}
for num in nums:
if num not in hashmap:
hashmap[num] = 1
elif num in hashmap:
hashmap[num] += 1
res = []
for key,value in hashmap.items():
if value == 1:
res.append(key)
return res
class Solution:
def singleNumbers(self, nums: List[int]) -> List[int]:
x, y, n, m = 0, 0, 0, 1
for num in nums: # 1. 遍历异或
n ^= num
while n & m == 0: # 2. 循环左移,计算 m
m <<= 1
for num in nums: # 3. 遍历 nums 分组
if num & m: x ^= num # 4. 当 num & m != 0
else: y ^= num # 4. 当 num & m == 0
return x, y # 5. 返回出现一次的数字
56、【哈希表】数组中数字出现的次数 II
在一个数组 nums 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。
# 方法一,用hashmap方法完成
class Solution:
def singleNumber(self, nums: List[int]) -> int:
hashmap = {}
for num in nums:
if num not in hashmap:
hashmap[num] = 0
if num in hashmap:
hashmap[num] += 1
for num in nums:
if hashmap[num] == 1:
return num
# 还是hashmap进一步优化
class Solution:
def singleNumber(self, nums: List[int]) -> int:
hashmap = {}
for num in nums: # 不用双重的if判断,可能减少了操作
if num not in hashmap:
hashmap[num] = 1
elif num in hashmap:
hashmap[num] += 1
for key,value in hashmap.items(): # 不再是遍历原来的数组,而是遍历新的字典
if value==1:
return key
57-I、【数组】和为s的两数
# 利用指针对撞的方法寻找对应的两数和
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
i,j = 0, len(nums)-1
while i < j:
s = nums[i] + nums[j]
if s > target:
j -= 1
elif s < target:
i += 1
else:
return [nums[i], nums[j]]
return False
57-II、【数组】和为s的连续正数序列
输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。
序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。
# 方法二,利用多指针方式进行操作解答。
class Solution:
def findContinuousSequence(self, target: int) -> List[List[int]]:
i,j,s,res = 1,2,3,[]
while i < j:
if s == target:
res.append(list(range(i,j+1)))
if s >= target:
s -= i
i += 1
else:
j += 1
s += j
return res
# 还是双指针方法
class Solution:
def findContinuousSequence(self, target: int) -> List[List[int]]:
i,j,sum,res = 1,1,0,[]
while i <= target//2:
if sum < target:
sum += j
j += 1
elif sum > target:
sum -= i
i += 1
else:
res.append(list(range(i,j)))
sum -= i
i += 1
return res
58、【字符串】翻转单词顺序
可能会出现多个空格,在句子前、后、中等三个位置
# 用python自带的内容去完成
class Solution:
def reverseWords(self, s: str) -> str:
s = s.strip()
a = s.split()
return ' '.join(a[::-1])
# 用双指针的方法完成任务
class Solution:
def reverseWords(self, s: str) -> str:
s = s.strip()
res = []
n = len(s)
i,j = n-1, n-1
while i>=0:
while i>=0 and s[i]!=' ':
i -= 1
res.append(s[i+1:j+1])
while s[i]==' ':
i -= 1
j = i
return " ".join(res)
61、【数组】扑克牌中的顺子
从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的。2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视为 14。
# 方法一
class Solution:
def isStraight(self, nums: List[int]) -> bool:
nums.sort()
for i in range(len(nums)):
if nums[i] != 0:
break
if len(nums[i:]) != len(set(nums[i:])):
return False
if nums[-1] - nums[i] >= 5:
return False
return True
# 方法二
class Solution:
def isStraight(self, nums: List[int]) -> bool:
repeat = []
for num in nums:
if num == 0:
continue
if num in repeat:
return False
repeat.append(num)
return max(repeat) - min(repeat) < 5
62、【动态规划】圆圈中最后剩下的数字
0,1,···,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字(删除后从下一个数字开始计数)。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
# 其他的题解看不懂,这有用全真模拟比较容易理解
class Solution:
def lastRemaining(self, n: int, m: int) -> int:
res = list(range(n))
i = 0
while len(res)>1:
i = (i+m-1) % (len(res))
res.pop(i)
return res[0]
64、【阶乘、位运算】求1到n的阶乘
# 利用数学中的等差数列求和
class Solution:
def sumNums(self, n: int) -> int:
return int((1+n)/2*n)
65、【位运算】不用加减乘除做加法
利用位运算方法操作:1、python没有int类型的数值,所以存储数字会特别大。
2、如果出现负数应该如何解决,在python中负数的补码也很大。
观察可以发现如果两个数字不发生进位问题,利用异或^运算可以完成;发生进位问题可以通过与运算&并左移一位完成问题,跳出循环的条件是当b!=0.
最后得到的数据可以判断,如果数值大于0x7fffffff,说明这个数是负数。那么就可以对齐进行取反操作。
所以上述问题可以进行优化:
class Solution:
def add(self, a: int, b: int) -> int:
x = 0xffffffff
a,b = a&x,b&x
while b!=0:
a,b = a^b,(a&b)<<1&x
return a if a<=0x7fffffff else ~(a^x)
68、【二叉树】二叉搜索树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4],本题与下题为共生题,可以采用相同的处理方式,但是z
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if p.val > q.val:
p,q = q,p
while root:
if root.val < p.val:
root = root.right
elif root.val > q.val:
root = root.left
else:
break
return root
68、【二叉树】二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
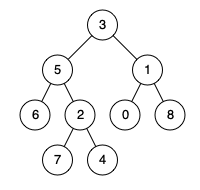
class Solution:
def lowestCommonAncestor(self, root: TreeNode, p: TreeNode, q: TreeNode) -> TreeNode:
# 如果根节点不存在或者root=p、q其中一个,返回root
if not root or root == p or root == q:
return root
# 开启递归,相当于do-while结构
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if not left: # 如果没有left,就说明p,q都在right中
return right
if not right:# 如果没有right,就说明p,q都在left中
return left
return root
70、【二叉树】判断一个树是不是二叉搜索树?
输入一棵树,判断这棵树是否为二叉搜索树。首先要知道什么是排序二叉树,二叉排序树是这样定义的,二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:
(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3)左、右子树也分别为二叉排序树;
(4)没有键值相等的节点
# 直接判断法
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def isValidBST(self, root):
"""
:type root: TreeNode
:rtype: bool
"""
if not root:
return True
def isBSTHelper(node, lower_limit, upper_limit):
#节点值应大于下限,小于上限
if lower_limit is not None and node.val <= lower_limit:
return False
if upper_limit is not None and upper_limit <= node.val:
return False
#随着向下遍历,对于左子树,被不断更新的是上限值(必须小于其父节点),对于右子树,被不断更新的是下限值(必须大于其父节点)
left = isBSTHelper(node.left, lower_limit, node.val) if node.left else True
if left:
right = isBSTHelper(node.right, node.val, upper_limit) if node.right else True
return right
else:
return False
return isBSTHelper(root, None, None)
# 利用中序方法
def isbst(node):
lastvalue=float('-inf') #遍历的前一个节点的值
def isbst2(node):
nonlocal lastvalue
if node==None:
return True
if isbst2(node.left) is not True:
return False
if node.val<lastvalue:
return False
lastvalue=node.val#更新
if isbst2(node.right) is not True:
return False
return True
return isbst2(node)
程序员面试经典
【字典操作】01. 判定字符是否唯一
实现一个算法,确定一个字符串 s 的所有字符是否全都不同。
# 第一想法就是利用hashmap操作,用于判断,重复、个数这种题目比较有效
class Solution:
def isUnique(self, astr: str) -> bool:
hash_map = {}
for char in astr:
if char in hash_map:
return False
else:
hash_map[char] = 1
return True
【HashMap】02. 判定是否互为字符重排
给定两个字符串 s1 和 s2,请编写一个程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串。
# 第一想法就是利用hashmap操作,用于判断,重复、个数这种题目比较有效
class Solution:
def CheckPermutation(self, s1: str, s2: str) -> bool:
hashmap = {}
for i in s1:
if i not in hashmap:
hashmap[i] = 1
else:
hashmap[i] += 1
for j in s2:
if j not in hashmap:
return False
else:
hashmap[j] -= 1
if hashmap[j] == 0:
hashmap.pop(j)
return True
【HashMap】面试题 04. 回文排列
给定一个字符串,编写一个函数判定其是否为某个回文串的排列之一。
class Solution:
def canPermutePalindrome(self, s: str) -> bool:
hashmap = {}
for i in s:
if i not in hashmap:
hashmap[i] = 1
else:
hashmap.pop(i)
flag = 0
for value in hashmap.values():
if value == 1:
flag += 1
if flag > 1:
return False
return True
牛客刷题
1、【阿里巴巴】完美对
有[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fo7jxXbQ-1632553534321)(https://www.nowcoder.com/equation?tex=\ n)]个物品,每个物品有[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uSjNkMIR-1632553534322)(https://www.nowcoder.com/equation?tex=\ k)]个属性,第[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1inNfFCf-1632553534322)(https://www.nowcoder.com/equation?tex=\ i)]件物品的第[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WeeaQb4u-1632553534323)(https://www.nowcoder.com/equation?tex=\ j)]个属性用一个正整数表示记为[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pgvPpUrq-1632553534323)(https://www.nowcoder.com/equation?tex=a_{i%2Cj})],两个不同的物品[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0rfMBlV1-1632553534324)(https://www.nowcoder.com/equation?tex=\ i%2Cj)]被称为是完美对的当且仅当[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Em0KZDwx-1632553534324)(https://www.nowcoder.com/equation?tex=a_{i%2C1}%2Ba_{j%2C1} %3D a_{i%2C2}%2Ba_{j%2C2}%3D\dots%3Da_{i%2Ck}%2Ba_{j%2Ck})],求完美对的个数。

n,k = map(int, input().split(" ")) # 数据读取操作,将第一行数据通过空格进行分离
if n == 1: # 跳出异常情况
print(0)
exit() # 提前跳出,类似于函数中的return
res = 0 # 初始化完美对的数量
hashmap = {} # 定义hash表
for i in range(n): # 遍历n的长度
n_lst = list(map(int, input().split(" "))) # 读取所有数字变成一个列表,例如["2","11","21"]
for j in range(1,k): # 遍历一行中除了首字母外元素
n_lst[j] -= n_lst[0] # 对每个元素减去首字母
n_lst = n_lst[1:] # 建立一个新的数组存储新的裂变
p_str = ''.join(map(str,n_lst)) # 将新数组变成一个字符串,例如919,-9-19
n_str = ''.join(map(str, [-num for num in n_lst])) # 反向输出到一个字符串
if n_str in hashmap: # 判断反向的完美对是否存在
res += hashmap[n_str] # 输出数为完美对个数
if p_str in hashmap:
hashmap[p_str] += 1
else:
hashmap[p_str] = 1
print(res)
2、【富途】LRU实现算法
逻辑很简单,get和put两种操作,其中get时如果元素存在则将节点从当前位置移到链表头部,表示最近被访问到的节点;put时也是,不管节点之前存不存在都要移动到链表头部。同样通过一个map来实现查找时的O(1)复杂度。
class LRUCache(object):
def __init__(self, capacity=0xffffffff):
"""
LRU缓存置换算法 最近最少使用
:param capacity:
"""
self.capacity = capacity
self.size = 0
self.map = {}
self.list = DoubleLinkedList(capacity)
def get(self, key):
"""
获取元素
获取元素不存在 返回None
获取元素已存在 将节点从当前位置删除并添加至链表头部
:param key:
:return:
"""
# 元素不存在
if key not in self.map:
return None
node = self.map.get(key)
self.list.remove(node)
self.list.append_front(node)
return node.value
def put(self, key, value):
"""
添加元素
被添加的元素已存在 更新元素值并已到链表头部
被添加的元素不存在
链表容量达到上限 删除尾部元素
链表容量未达上限 添加至链表头部
:param key:
:param value:
:return:
"""
if key in self.map:
node = self.map.get(key)
node.value = value
self.list.remove(node)
self.list.append_front(node)
else:
if self.size >= self.capacity:
old_node = self.list.remove()
del self.map[old_node.key]
self.size -= 1
node = Node(key, value)
self.map[key] = node
self.list.append_front(node)
self.size += 1
return node
def print(self):
"""
打印当前链表
:return:
"""
self.list.print()
测试逻辑:
if __name__ == '__main__':
lru_cache = LRUCache(3)
lru_cache.put(1, 1)
lru_cache.print()
lru_cache.put(2, 2)
lru_cache.print()
print(lru_cache.get(1))
lru_cache.print()
lru_cache.put(3, 3)
lru_cache.print()
lru_cache.put(1, 100)
lru_cache.print()
lru_cache.put(4, 4)
lru_cache.print()
print(lru_cache.get(1))
lru_cache.print()
做题模板(参考labuladong)
1、二分法
Java
//简单二分法
int binary_search(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while(left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if(nums[mid] == target) {
// 直接返回
return mid;
}
}
// 直接返回
return -1;
}
//左边界
int left_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// 别返回,锁定左侧边界
right = mid - 1;
}
}
// 最后要检查 left 越界的情况
if (left >= nums.length || nums[left] != target)
return -1;
return left;
}
//右边界
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// 别返回,锁定右侧边界
left = mid + 1;
}
}
// 最后要检查 right 越界的情况
if (right < 0 || nums[right] != target)
return -1;
return right;
}
Python
# 基本二分搜索
def binarySearch(nums, target):
l, r = 0, len(nums)-1
while l <= r:
mid = (l+r)//2
if nums[mid] == target:
return mid
elif nums[mid] < target:
l = mid + 1
elif nums[mid] > target:
r = mid - 1
return -1
# 左边界
def left_search(nums, target):
l, r = 0, len(nums) - 1
while(l<=r):
mid = l + (r-l)//2
if(nums[mid] < target):
l = mid + 1
elif(nums[mid] > target):
r = mid - 1
elif(nums[mid]==target):
r = mid - 1
return l
# 右边界
def right_search(nums, target):
l, r = 0, len(nums) - 1
while(l<=r):
mid = l + (r-l)//2
if(nums[mid] < target):
l = mid + 1
elif(nums[mid] > target):
r = mid - 1
elif(nums[mid]==target):
l = mid + 1
return r
问题1:r = len(nums)-1?
回答1:其中r是以下表的形式出现,表示[l,r]这个闭区间,如果没有+1,会出现地址越界情况,因为nums[len(nums)]是不存在的。
问题2:while l<=r 还是 l<r?
回答二:可以具体到break条件,其中在<=情况下,退出while语句的条件为l-1等于r,即[l,r]是区间不存在的,也就说已经没有搜索空间了,
但是在<的情况下,l=r作为退出语句的条件,[l,r]是有一个l还在区间内没有考虑到,会造成丢失的情况。
例题、实现 int sqrt(int x) 函数。计算并返回 x 的平方根,其中 x 是非负整数。由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
class Solution:
def mySqrt(self, x: int) -> int:
l, r = 0, x
while r >= l:
mid = (l+r)//2
temp = mid**2
if temp > x:
r = mid - 1
elif temp < x:
l = mid + 1
elif temp == x:
return mid
return r














 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









