







有存放在同一文件夹下的Excel数据表若干:

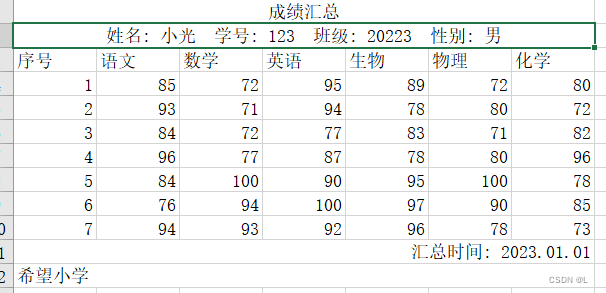
需要将它们整合成一张数据表
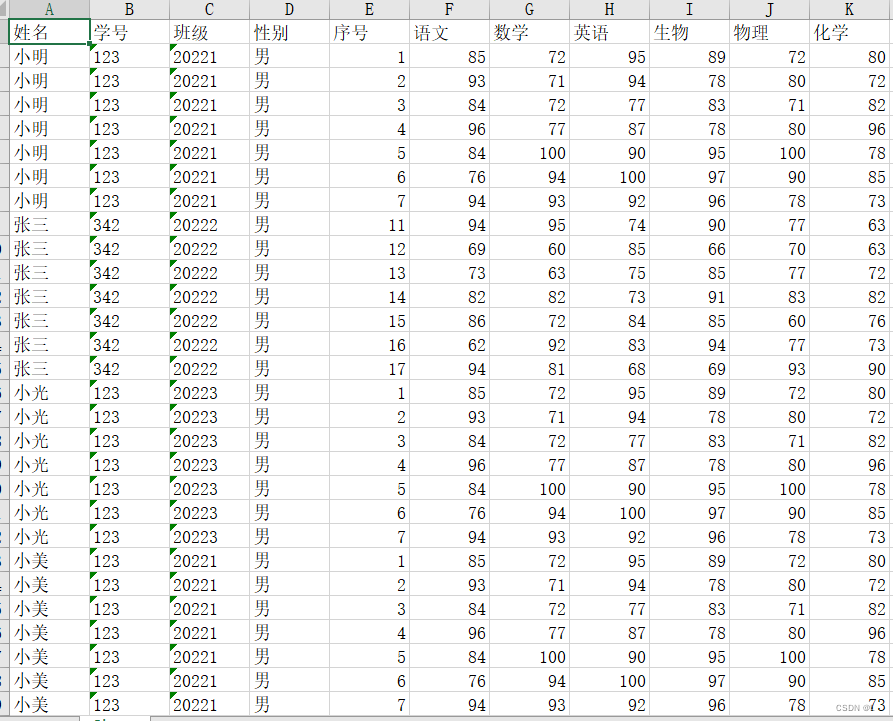
代码如下:
import heapq
import openpyxl as opx
import os
wb = opx.Workbook()
sheet_summary = wb.active
q = []
heapq.heapify(q)
# 将表格的数据以字典形式储存起来
def summaryData(sheet):
dic = dict()
list = [cell[1].value for cell in sheet1.columns]
s = list[0]
# 姓名,学号,班级,性别
for j in s.split(' '):
if j:
if j.find(':') > 0:
dic[j.replace(':', '')] = ''
k = j.replace(':', '')
else:
dic[k] = j
for k, v in enumerate([cell[2].value for cell in sheet.columns]):
list = [cell[k].value for cell in sheet.rows]
dic[v] = list[3:-2]
# 使用最小堆记录每张表关于成绩的最大行,python默认优先队列为最小堆,所以使用负数
heapq.heappush(q,-len(list[3:-2]))
return dic
# print(summaryData(sheet1))
start = 2
end = 1
count = 0
for file in os.listdir('C://Users/小碧宰治/Desktop/数据汇总'):
if file.endswith('.xlsx') and not file.startswith('~$'):
count += 1
file_path = os.path.join('C://Users/小碧宰治/Desktop/数据汇总', file)
wb1 = opx.load_workbook(file_path)
sheet1 = wb1['Sheet1']
dic = summaryData(sheet1)
# 开始行号
start = end + 1
# 结束行号
# -q[0]取每张表的成绩的最大行数
end += -q[0]
# print(q[0])
# 最大列号
mc = len(dic)
for k,v in enumerate([k for k in dic]):
sheet_summary.cell(1,k+1).value = v
for k,v in enumerate([k for k in dic]):
# c为列号
c = k + 1
v = dic[v]
index = 0
for r in range(start,end+1):
if type(v) == str:
sheet_summary.cell(r, c).value = v
elif type(v) == list :
sheet_summary.cell(r, c).value = v[index]
index += 1
wb.save('C://Users/小碧宰治/Desktop/汇总表.xlsx')















 1697
1697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









