






索引
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引, 并指定索引的类型,各类索引有各自的数据结构实现.
索引的作用:
设置了合适的索引之后,数据库利用各种快速的定位技术,能够大大加快查询速率,特别是当表很大时,或者查询涉及到多个表时,使用索引可使查询加快成千倍。
可以降低数据库的lo成本, 并且索引还可以降低数据库的排序成本。
通过创建唯一-性索引保证数据表数据的唯一性,可以加快表与表之间的连接。
在使用分组和排序时,可大大减少分组和排序时间。
这里先说一下特殊情况:
在创建主键(primary key) ,唯一约束(unique),外键(foreign key) 时会创建对应列的索引
索引分类:
普通索引:最基本的索引类型,而且没有唯一性之类的限制
唯一性索引:与普通索引基本相同,区别在于:索引列的所有值都只能出现一次,即必须唯一,但可为空。
主键:是一种特殊的唯一索引,必须指定为PRIMARY KEY,具有唯一性的同时不能为空
还有全文索引,单列索引,多列索引 这个顾名思义.
索引常用语句:
查看索引
show index 索引名 from 表名;
例:查看学生表已有的索引
show index from student;
创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引:
create index 索引名 on 表名(字段名);
例::创建班级表中,name字段的索引
create index idx_classes_name on classes(name);
删除索引
drop index 索引名 on 表名;
适合创建索引的情况:
1.主键自动建立唯一索引
2.频繁作为查询条件的字段应该创建索引
3.查询中与其它表关联的字段, 外键关系建立索引
4.单键/组合索引的选择问题, 组合索引性价比更高
5.查询中排序的字段, 排序字段若通过索引去访问将大大提高排序速度
6.查询中统计或者分组字段
不适合创建索引的情况:
1.表记录太少
2.经常增删改的表或者字段
3.Where 条件里用不到的字段不创建索引
4.过滤性不好的不适合建索引
事务(ACID)
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
事务的特点:
1.原子性(Atomicity)
2.一致性(Consistency)
3.隔离性(Isolation)
4.持久性(Durability)
原子性:事务是一个完整的操作,事务的各元素是不可分的(原子的),事务的所有元素必须作为一个整体提交或回滚。如果事务中的任何元素失败,则整个事务将失败。
一致性:当事务完成时,数据必须处于一致状态:在事务开始之前,数据库汇总存储的数据处于一致状态;在正在进行的事务中,数据可能处于不一致的状态;当事务完成时,数据必须再次回到已知的一致状态。
隔离性:对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应该以任何方式依赖于或影响其他事务。修改数据的事务可以在另一个使用相同数据的事务开始之前访问这些数据,或者在另一个使用相同数据的事务结束之后访问这些数据。
持久性:事务的持久性指不管系统是否发生了故障,事务处理的结果都是永久的。一旦事务被提交,事务的效果会被永久地保留在数据库中。
事务的使用:
1.开启事务:start transaction;/begin;
2.中间执行sql语句.
3.回滚或提交:rollback/commit;
rollback即是全部失败,commit即是全部成功
准备测试数据:
drop table if exists accout;
create table accout(
id int primary key auto_increment,
name varchar(20) comment '账户名称',
money decimal(11,2) comment '金额' );
insert into accout(name, money)
values ('阿里巴巴', 5000),
('四十大盗', 1000);开启事务:start transaction;

执行下列语句:
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗'; 
如果回滚(rollback)则之后提交的数据恢复原样:
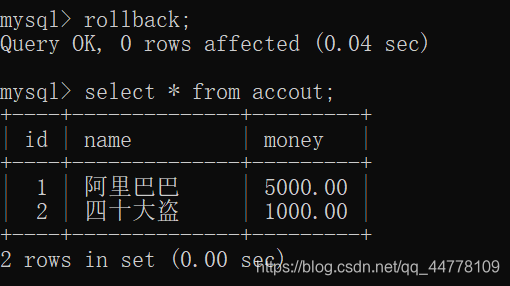
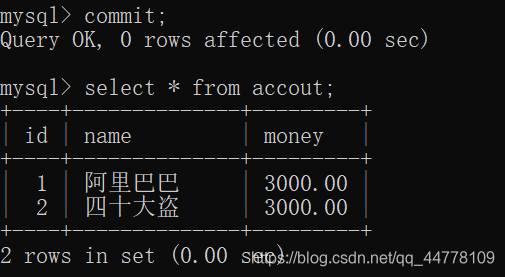
如果提交则数据就真正的更改掉:














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









