







目录
read()函数抛出UnicodeDecodeError异常的解决方法
readline()和readlines()函数:按行读取文件
Python 具有操作文件(I/O)的能力,比如打开文件、读取和追加数据、插入和删除数据、关闭文件、删除文件等。
除了提供文件操作基本的函数之外,Python 还提供了很多模块,例如 fileinput 模块、pathlib 模块等,通过引入这些模块,我们可以获得大量实现文件操作可用的函数和方法(类属性和类方法),大大提供编写代码的效率。
文件路径
关于文件,它有两个关键属性,分别是“文件名”和“路径”。其中,文件名指的是为每个文件设定的名称,而路径则用来指明文件在计算机上的位置。
在 Windows 上,路径书写使用反斜杠 "\" 作为文件夹之间的分隔符。但在 OS X 和 Linux 上,使用正斜杠 "/" 作为它们的路径分隔符。如果想要程序运行在所有操作系统上,在编写 Python 脚本时,就必须处理这两种情况。
好在,用 os.path.join() 函数来做这件事很简单。如果将单个文件和路径上的文件夹名称的字符串传递给它,os.path.join() 就会返回一个文件路径的字符串,包含正确的路径分隔符。
import os
print(os.path.join("pythonProject","hello"))
结果:
pythonProject\hello不仅如此,如果需要创建带有文件名称的文件存储路径,os.path.join() 函数同样很有用。例如,下面的例子将一个文件名列表中的名称,添加到文件夹名称的末尾:
import os
myFiles = ['accounts.txt', 'details.csv', 'invite.docx']
for filename in myFiles:
print(os.path.join('C:\\demo\\exercise', filename))
结果:
C:\demo\exercise\accounts.txt
C:\demo\exercise\details.csv
C:\demo\exercise\invite.docx绝对路径和相对路径
在 Python 中,利用 os.getcwd() 函数可以取得当前工作路径的字符串,还可以利用 os.chdir() 改变它。例如,在交互式环境中输入以下代码:
import os
print(os.getcwd())
print(os.chdir('C:\\Users\\HuYoo\\Desktop'))
print(os.getcwd())
结果:
D:\PycharmProjects\pythonProject
None
C:\Users\HuYoo\Desktop可以看到,原本当前工作路径为 'D:\PycharmProjects\pythonProject',通过 os.chdir() 函数,将其改成了 'C:\Users\HuYoo\Desktop'(也就是桌面)。
需要注意的是,如果使用 os.chdir() 修改的工作目录不存在,Python 解释器会报错
明确一个文件所在的路径,有 2 种表示方式,分别是:
- 绝对路径:总是从根文件夹开始,Window 系统中以盘符(C:、D:)作为根文件夹,而 OS X 或者 Linux 系统中以 / 作为根文件夹。
- 相对路径:指的是文件相对于当前工作目录所在的位置。例如,当前工作目录为 "C:\Windows\System32",若文件 demo.txt 就位于这个 System32 文件夹下,则 demo.txt 的相对路径表示为 ".\demo.txt"(其中 .\ 就表示当前所在目录)。
在使用相对路径表示某文件所在的位置时,除了经常使用 .\ 表示当前所在目录之外,还会用到 ..\ 表示当前所在目录的父目录。
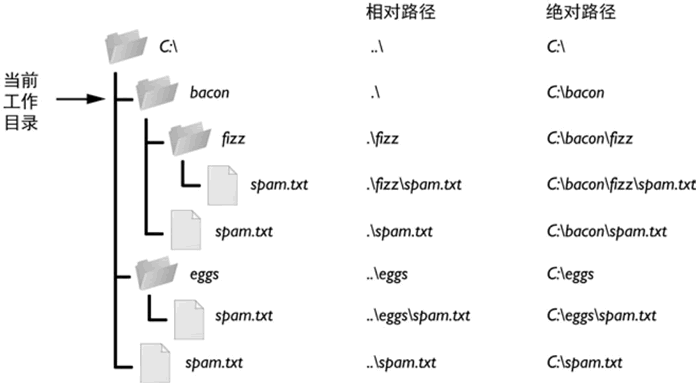
图 1 相对路径和绝对路径
以图 1 为例,如果当前工作目录设置为 C:\bacon,则这些文件夹和文件的相对路径和绝对路径,就对应为该图右侧所示的样子。
Python os.path 模块提供了一些函数,可以实现绝对路径和相对路径之间的转换,以及检查给定的路径是否为绝对路径,比如说:
- 调用 os.path.abspath(path) 将返回 path 参数的绝对路径的字符串,这是将相对路径转换为绝对路径的简便方法。
- 调用 os.path.isabs(path),如果参数是一个绝对路径,就返回 True,如果参数是一个相对路径,就返回 False。
- 调用 os.path.relpath(path, start) 将返回从 start 路径到 path 的相对路径的字符串。如果没有提供 start,就使用当前工作目录作为开始路径。
- 调用 os.path.dirname(path) 将返回一个字符串,它包含 path 参数中最后一个斜杠之前的所有内容;调用 os.path.basename(path) 将返回一个字符串,它包含 path 参数中最后一个斜杠之后的所有内容。
在交互式环境中尝试上面提到的函数:
import os
print(os.getcwd())
print(os.path.abspath(".\\pythonProject"))
print(os.path.isabs('D:\PycharmProjects\pythonProject'))
print(os.path.isabs(os.path.abspath('.')))
print(os.path.relpath('D:\PycharmProjects\pythonProject', 'D:\\'))
path = 'D:\\PycharmProjects\\pythonProject\\hello.py'
print(os.path.basename(path))
print(os.path.dirname(path))
结果:
D:\PycharmProjects\pythonProject
D:\PycharmProjects\pythonProject\pythonProject
True
True
PycharmProjects\pythonProject
hello.py
D:\PycharmProjects\pythonProject
除此之外,如果同时需要一个路径的目录名称和基本名称,就可以调用 os.path.split() 获得这两个字符串的元组,例如:
import os
path = 'D:\\PycharmProjects\\pythonProject\\hello.py'
print(os.path.split(path))
结果:
('D:\\PycharmProjects\\pythonProject', 'hello.py')注意,可以调用 os.path.dirname()和 os.path.basename(),将它们的返回值放在一个元组中,从而得到同样的元组。但使用 os.path.split() 无疑是很好的快捷方式。
同时,如果提供的路径不存在,许多 Python 函数就会崩溃并报错,但好在 os.path 模块提供了以下函数用于检测给定的路径是否存在,以及它是文件还是文件夹:
- 如果 path 参数所指的文件或文件夹存在,调用 os.path.exists(path) 将返回 True,否则返回 False。
- 如果 path 参数存在,并且是一个文件,调用 os.path.isfile(path) 将返回 True,否则返回 False。
- 如果 path 参数存在,并且是一个文件夹,调用 os.path.isdir(path) 将返回 True,否则返回 False。
下面是在交互式环境中尝试这些函数的结果:
import os
print(os.path.exists('C:\\Windows'))
print(os.path.exists('C:\\some_made_up_folder'))
print(os.path.isdir('C:\\Windows\\System32'))
print(os.path.isfile('C:\\Windows\\System32'))
print(os.path.isdir('C:\\Windows\\System32\\calc.exe'))
print(os.path.isfile('C:\\Windows\\System32\\calc.exe'))
结果:
True
False
True
False
False
True
文件基本操作
Python 中,对文件的操作有很多种,常见的操作包括创建、删除、修改权限、读取、写入等,这些操作可大致分为以下 2 类:
- 删除、修改权限:作用于文件本身,属于系统级操作。
- 写入、读取:是文件最常用的操作,作用于文件的内容,属于应用级操作。
其中,对文件的系统级操作功能单一,比较容易实现,可以借助 Python 中的专用模块(os、sys 等),并调用模块中的指定函数来实现。例如,假设如下代码文件的同级目录中有一个文件“a.txt”,通过调用 os 模块中的 remove 函数,可以将该文件删除,具体实现代码如下:
import os
os.remove("test.txt")而对于文件的应用级操作,通常需要按照固定的步骤进行操作,且实现过程相对比较复杂,同时也是本章重点要讲解的部分。
文件的应用级操作可以分为以下 3 步,每一步都需要借助对应的函数实现:
- 打开文件:使用 open() 函数,该函数会返回一个文件对象;
- 对已打开文件做读/写操作:读取文件内容可使用 read()、readline() 以及 readlines() 函数;向文件中写入内容,可以使用 write() 函数。
- 关闭文件:完成对文件的读/写操作之后,最后需要关闭文件,可以使用 close() 函数。
一个文件,必须在打开之后才能对其进行操作,并且在操作结束之后,还应该将其关闭,这 3 步的顺序不能打乱。
open()函数详解:打开指定文件
如果想要操作文件,首先需要创建或者打开指定的文件,并创建一个文件对象,而这些工作可以通过内置的 open() 函数实现。
open() 函数用于创建或打开指定文件,该函数的常用语法格式如下:
file = open("file_name" , mode='r' , buffering=-1 , encoding = None)
此格式中,用 [] 括起来的部分为可选参数,即可以使用也可以省略。其中,各个参数所代表的含义如下:
- file:表示要创建的文件对象。
- file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
- mode:可选参数,用于指定文件的打开模式。可选的打开模式如表 1 所示。如果不写,则默认以只读(r)模式打开文件。
- buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区。
- encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)。
open() 函数支持的文件打开模式如表 1 所示。
| 模式 | 意义 | 注意事项 |
|---|---|---|
| r | 只读模式打开文件,读文件内容的指针会放在文件的开头。 | 操作的文件必须存在。 |
| rb | 以二进制格式、采用只读模式打开文件,读文件内容的指针位于文件的开头,一般用于非文本文件,如图片文件、音频文件等。 | |
| r+ | 打开文件后,既可以从头读取文件内容,也可以从开头向文件中写入新的内容,写入的新内容会覆盖文件中等长度的原有内容。 | |
| rb+ | 以二进制格式、采用读写模式打开文件,读写文件的指针会放在文件的开头,通常针对非文本文件(如音频文件)。 | |
| w | 以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| wb | 以二进制格式、只写模式打开文件,一般用于非文本文件(如音频文件) | |
| w+ | 打开文件后,会对原有内容进行清空,并对该文件有读写权限。 | |
| wb+ | 以二进制格式、读写模式打开文件,一般用于非文本文件 | |
| a | 以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。 | |
| ab | 以二进制格式打开文件,并采用追加模式,对文件只有写权限。如果该文件已存在,文件指针位于文件末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| a+ | 以读写模式打开文件;如果文件存在,文件指针放在文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| ab+ | 以二进制模式打开文件,并采用追加模式,对文件具有读写权限,如果文件存在,则文件指针位于文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
文件打开模式,直接决定了后续可以对文件做哪些操作。例如,使用 r 模式打开的文件,后续编写的代码只能读取文件,而无法修改文件内容。
图 2 中,将以上几个容易混淆的文件打开模式的功能做了很好的对比:
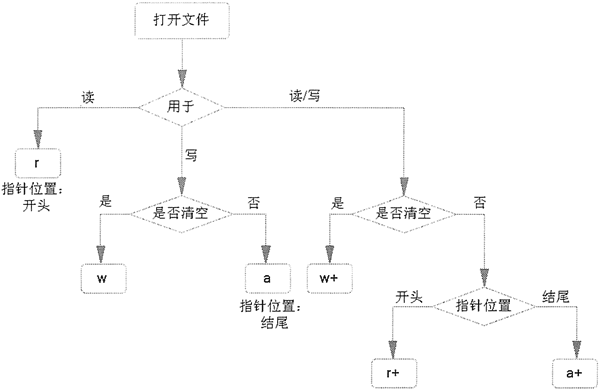
图 2 不同文件打开模式的功能
【例 1】默认打开 "a.txt" 文件。当以默认模式打开文件时,默认使用 r 权限
#当前程序文件同目录下没有 a.txt 文件
file = open("hello.py")
print(file)
结果:
<_io.TextIOWrapper name='hello.py' mode='r' encoding='cp936'>可以看到,当前输出结果中,输出了 file 文件对象的相关信息,包括打开文件的名称、打开模式、打开文件时所使用的编码格式。
使用 open() 打开文件时,默认采用 GBK 编码。但当要打开的文件不是 GBK 编码格式时,可以在使用 open() 函数时,手动指定打开文件的编码格式,例如:
file = open("hello.py",encoding="utf-8")
print(file)
结果:
<_io.TextIOWrapper name='hello.py' mode='r' encoding='utf-8'>注意,手动修改 encoding 参数的值,仅限于文件以文本的形式打开,也就是说,以二进制格式打开时,不能对 encoding 参数的值做任何修改,否则程序会抛出 ValueError 异常,如下所示:
ValueError: binary mode doesn't take an encoding argumentopen()是否需要缓冲区
通常情况下、建议大家在使用 open() 函数时打开缓冲区,即不需要修改 buffing 参数的值。
如果 buffing 参数的值为 0(或者 False),则表示在打开指定文件时不使用缓冲区;如果 buffing 参数值为大于 1 的整数,该整数用于指定缓冲区的大小(单位是字节);如果 buffing 参数的值为负数,则代表使用默认的缓冲区大小。
目前为止计算机内存的 I/O 速度仍远远高于计算机外设(例如键盘、鼠标、硬盘等)的 I/O 速度,如果不使用缓冲区,则程序在执行 I/O 操作时,内存和外设就必须进行同步读写操作,也就是说,内存必须等待外设输入(输出)一个字节之后,才能再次输出(输入)一个字节。这意味着,内存中的程序大部分时间都处于等待状态。
而如果使用缓冲区,则程序在执行输出操作时,会先将所有数据都输出到缓冲区中,然后继续执行其它操作,缓冲区中的数据会有外设自行读取处理;同样,当程序执行输入操作时,会先等外设将数据读入缓冲区中,无需同外设做同步读写操作。
open()文件对象常用的属性
成功打开文件之后,可以调用文件对象本身拥有的属性获取当前文件的部分信息,其常见的属性为:
- file.name:返回文件的名称;
- file.mode:返回打开文件时,采用的文件打开模式;
- file.encoding:返回打开文件时使用的编码格式;
- file.closed:判断文件是否己经关闭。
举个例子:
# 以默认方式打开文件
f = open('my_file.txt')
# 输出文件是否已经关闭
print(f.closed)
# 输出访问模式
print(f.mode)
#输出编码格式
print(f.encoding)
# 输出文件名
print(f.name)
结果:
False
r
cp936
my_file.txtread()函数:按字节(字符)读取文件
Python 提供了如下 3 种函数,它们都可以帮我们实现读取文件中数据的操作:
- read() 函数:逐个字节或者字符读取文件中的内容;
- readline() 函数:逐行读取文件中的内容;
- readlines() 函数:一次性读取文件中多行内容。
借助 open() 函数,并以可读模式(包括 r、r+、rb、rb+)打开的文件,可以调用 read() 函数逐个字节(或者逐个字符)读取文件中的内容。
如果文件是以文本模式(非二进制模式)打开的,则 read() 函数会逐个字符进行读取;反之,如果文件以二进制模式打开,则 read() 函数会逐个字节进行读取。
read() 函数的基本语法格式如下:
file.read([size])
其中,file 表示已打开的文件对象;size 作为一个可选参数,用于指定一次最多可读取的字符(字节)个数,如果省略,则默认一次性读取所有内容。
file = open("hello.py",encoding="utf-8")
print(file.read(30))
file.close()
结果:
"""
name 为名字
age 为年龄
"""
name除此之外,对于以二进制格式打开的文件,read() 函数会逐个字节读取文件中的内容。例如:
file = open("hello.py","rb+")
print(file.read(20))
file.close()
结果:
b'"""\r\nname \xe4\xb8\xba\xe5\x90\x8d\xe5\xad\x97\r'可以看到,输出的数据为 bytes 字节串。我们可以调用 decode() 方法,将其转换成我们认识的字符串。
想使用 read() 函数成功读取文件内容,除了严格遵守 read() 的语法外,其还要求 open() 函数必须以可读默认(包括 r、r+、rb、rb+)打开文件。举个例子,将上面程序中 open()的打开模式改为 w,程序会抛出io.UnsupportedOperation异常,提示文件没有读取权限
read()函数抛出UnicodeDecodeError异常的解决方法
在使用 read() 函数时,如果 Python 解释器提示UnicodeDecodeError异常,其原因在于,目标文件使用的编码格式和 open() 函数打开该文件时使用的编码格式不匹配。
举个例子,如果目标文件的编码格式为 GBK 编码,而我们在使用 open() 函数并以文本模式打开该文件时,手动指定 encoding 参数为 UTF-8。这种情况下,由于编码格式不匹配,当我们使用 read() 函数读取目标文件中的数据时,Python 解释器就会提示UnicodeDecodeError异常。
要解决这个问题,要么将 open() 函数中的 encoding 参数值修改为和目标文件相同的编码格式,要么重新生成目标文件(即将该文件的编码格式改为和 open() 函数中的 encoding 参数相同)。
除此之外,还有一种方法:先使用二进制模式读取文件,然后调用 bytes 的 decode() 方法,使用目标文件的编码格式,将读取到的字节串转换成认识的字符串。例如
file.decode('utf-8')readline()和readlines()函数:按行读取文件
如果想读取用 open() 函数打开的文件中的内容,除了可以使用 read() 函数,还可以使用 readline() 和 readlines() 函数。
和 read() 函数不同,这 2 个函数都以“行”作为读取单位,即每次都读取目标文件中的一行。对于读取以文本格式打开的文件,读取一行很好理解;对于读取以二进制格式打开的文件,它们会以“\n”作为读取一行的标志。
readline()函数
readline() 函数用于读取文件中的一行,包含最后的换行符“\n”。此函数的基本语法格式为:
file.readline([size])
其中,file 为打开的文件对象;size 为可选参数,用于指定读取每一行时,一次最多读取的字符(字节)数。
和 read() 函数一样,此函数成功读取文件数据的前提是,使用 open() 函数指定打开文件的模式必须为可读模式(包括 r、rb、r+、rb+ 4 种)。
file = open("log.txt")
print(file.readline(20))
file.close()
结果:
Traceback (most rece由于 readline() 函数在读取文件中一行的内容时,会读取最后的换行符“\n”,再加上 print() 函数输出内容时默认会换行,所以输出结果中会看到多出了一个空行。
readlines()函数
readlines() 函数用于读取文件中的所有行,它和调用不指定 size 参数的 read() 函数类似,只不过该函数返回是一个字符串列表,其中每个元素为文件中的一行内容。
和 readline() 函数一样,readlines() 函数在读取每一行时,会连同行尾的换行符一块读取。
readlines() 函数的基本语法格式如下:
file.readlines()
其中,file 为打开的文件对象。和 read()、readline() 函数一样,它要求打开文件的模式必须为可读模式(包括 r、rb、r+、rb+ 4 种)。
file = open("log.txt")
print(file.readlines())
file.close()
结果:
['Traceback (most recent call last):\n', ' File "D:/PycharmProjects/pythonProject/main.py", line 13, in <module>\n', ' main()\n', ' File "D:/PycharmProjects/pythonProject/main.py", line 5, in main\n', ' firstMethod()\n', ' File "D:/PycharmProjects/pythonProject/main.py", line 7, in firstMethod\n', ' secondMethod()\n', ' File "D:/PycharmProjects/pythonProject/main.py", line 9, in secondMethod\n', ' thirdMethod()\n', ' File "D:/PycharmProjects/pythonProject/main.py", line 11, in thirdMethod\n', ' raise SelfException("自定义异常信息")\n', 'SelfException: 自定义异常信息\n']
write()和writelines():向文件中写入数据
可以向文件中写入指定内容。该函数的语法格式如下:
file.write(string)
其中,file 表示已经打开的文件对象;string 表示要写入文件的字符串(或字节串,仅适用写入二进制文件中)。
注意,在使用 write() 向文件中写入数据,需保证使用 open() 函数是以 r+、w、w+、a 或 a+ 的模式打开文件,否则执行 write() 函数会抛出 io.UnsupportedOperation 错误。
例如,创建一个 a.txt 文件,该文件内容如下:
file = open("first.txt",'w')
file.write("123")
file.close()
如果打开文件模式中包含 w(写入),那么向文件中写入内容时,会先清空原文件中的内容,然后再写入新的内容。
如果打开文件模式中包含 a(追加),则不会清空原有内容,而是将新写入的内容会添加到原内容后边。
采用不同的文件打开模式,会直接影响 write() 函数向文件中写入数据的效果。
在写入文件完成后,一定要调用 close() 函数将打开的文件关闭,否则写入的内容不会保存到文件中。
除此之外,如果向文件写入数据后,不想马上关闭文件,也可以调用文件对象提供的 flush() 函数,它可以实现将缓冲区的数据写入文件中。
f = open("a.txt", 'w')
f.write("写入一行新数据")
f.flush()实例
通过爬取网页代码并转存成txt文件。
import requests #导入requests包
url = 'http://www.cntour.cn/'
strhtml = requests.get(url) #Get方式获取网页数据
file = open("测试文档.txt","w",encoding="utf8")
file.write(strhtml.text)
file.close()
writelines()函数
可以实现将字符串列表写入文件中。
注意,写入函数只有 write() 和 writelines() 函数,而没有名为 writeline 的函数。
f = open('a.txt', 'r')
n = open('b.txt','w+')
n.writelines(f.readlines())
n.close()
f.close()执行此代码,在 a.txt 文件同级目录下会生成一个 b.txt 文件,且该文件中包含的数据和 a.txt 完全一样。
需要注意的是,使用 writelines() 函数向文件中写入多行数据时,不会自动给各行添加换行符。上面例子中,之所以 b.txt 文件中会逐行显示数据,是因为 readlines() 函数在读取各行数据时,读入了行尾的换行符。
close()函数:关闭文件
close() 函数是专门用来关闭已打开文件的,其语法格式也很简单,如下所示:
file.close()
import os
f = open("my_file.txt",'w')
#...
os.remove("my_file.txt")
结果:
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\demo.py", line 4, in <module>
os.remove("my_file.txt")
PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。: 'my_file.txt'代码中,我们引入了 os 模块,调用了该模块中的 remove() 函数,该函数的功能是删除指定的文件。但是,如果运行此程序,Python 解释器会报如下错误
显然,由于我们使用了 open() 函数打开了 my_file.txt 文件,但没有及时关闭,直接导致后续的 remove() 函数运行出现错误。因此,正确的程序应该是这样的:
import os
f = open("my_file.txt",'w')
f.close()
#...
os.remove("my_file.txt")当确定 my_file.txt 文件可以被删除时,再次运行程序,可以发现该文件已经被成功删除了。
如果我们不调用 close() 函数关闭已打开的文件,确定不影响读取文件的操作,但会导致 write() 或者 writeline() 函数向文件中写数据时,写入失败。这是因为,在向以文本格式(而不是二进制格式)打开的文件中写入数据时,Python 出于效率的考虑,会先将数据临时存储到缓冲区中,只有使用 close() 函数关闭文件时,才会将缓冲区中的数据真正写入文件中。
当然在某些实际场景中,我们可能需要在将数据成功写入到文件中,但并不想关闭文件。这也是可以实现的,调用 flush() 函数即可
f = open("my_file.txt", 'w')
f.write("http://c.biancheng.net/shell/")
f.flush()seek()和tell()函数
使用 open() 函数打开文件并读取文件中的内容时,总是会从文件的第一个字符(字节)开始读起。
自定指定读取的起始位置,这就需要移动文件指针的位置。
文件指针用于标明文件读写的起始位置。假如把文件看成一个水流,文件中每个数据(以 b 模式打开,每个数据就是一个字节;以普通模式打开,每个数据就是一个字符)就相当于一个水滴,而文件指针就标明了文件将要从文件的哪个位置开始读起。图 1 简单示意了文件指针的概念。

图 1 文件指针概念示意图
可以看到,通过移动文件指针的位置,再借助 read() 和 write() 函数,就可以轻松实现,读取文件中指定位置的数据(或者向文件中的指定位置写入数据)。
注意,当向文件中写入数据时,如果不是文件的尾部,写入位置的原有数据不会自行向后移动,新写入的数据会将文件中处于该位置的数据直接覆盖掉。
实现对文件指针的移动,文件对象提供了 tell() 函数和 seek() 函数。tell() 函数用于判断文件指针当前所处的位置,而 seek() 函数用于移动文件指针到文件的指定位置。
tell() 函数
tell() 函数用于判断文件指针当前所处的位置。
tell() 函数的用法很简单,其基本语法格式如下:
file.tell()
其中,file 表示文件对象。
例如,在同一目录下,编写如下程序对 a.txt 文件做读取操作,a.txt 文件中内容为:
file = open("first.txt",'r')
print(file.tell())
print(file.read(3))
print(file.tell())
结果:
0
123
3当使用 open() 函数打开文件时,文件指针的起始位置为 0,表示位于文件的开头处,
当使用 read() 函数从文件中读取 3 个字符之后,文件指针同时向后移动了 3 个字符的位置。
seek()函数
seek() 函数用于将文件指针移动至指定位置,该函数的语法格式如下:
file.seek(offset, whence)
其中,各个参数的含义如下:
- file:表示文件对象;
- whence:作为可选参数,用于指定文件指针要放置的位置,该参数的参数值有 3 个选择:0 代表文件头(默认值)、1 代表当前位置、2 代表文件尾。
- offset:表示相对于 whence 位置文件指针的偏移量,正数表示向后偏移,负数表示向前偏移。例如,当
whence == 0 &&offset == 3(即 seek(3,0) ),表示文件指针移动至距离文件开头处 3 个字符的位置;当whence == 1 &&offset == 5(即 seek(5,1) ),表示文件指针向后移动,移动至距离当前位置 5 个字符处。
注意,当 offset 值非 0 时,Python 要求文件必须要以二进制格式打开,否则会抛出 io.UnsupportedOperation 错误。
下面程序示范了文件指针操作:
f = open('a.txt', 'rb')
# 判断文件指针的位置
print(f.tell())
# 读取一个字节,文件指针自动后移1个数据
print(f.read(1))
print(f.tell())
# 将文件指针从文件开头,向后移动到 5 个字符的位置
f.seek(5)
print(f.tell())
print(f.read(1))
# 将文件指针从当前位置,向后移动到 5 个字符的位置
f.seek(5, 1)
print(f.tell())
print(f.read(1))
# 将文件指针从文件结尾,向前移动到距离 2 个字符的位置
f.seek(-1, 2)
print(f.tell())
print(f.read(1))
结果:
0
b'h'
1
5
b'/'
11
b'a'
21
b't'注意:由于程序中使用 seek() 时,使用了非 0 的偏移量,因此文件的打开方式中必须包含 b,否则就会报 io.UnsupportedOperation 错误,有兴趣的读者可自定尝试。
上面程序示范了使用 seek() 方法来移动文件指针,包括从文件开头、指针当前位置、文件结尾处开始计算。运行上面程序,结合程序输出结果可以体会文件指针移动的效果。
with as用法详解
文件的输入输出、数据库的连接断开等,都是很常见的资源管理操作。但资源都是有限的,在写程序时,必须保证这些资源在使用过后得到释放,不然就容易造成资源泄露,轻者使得系统处理缓慢,严重时会使系统崩溃。
但是,即便使用 close() 做好了关闭文件的操作,如果在打开文件或文件操作过程中抛出了异常,还是无法及时关闭文件。
为了更好地避免此类问题,对应的解决方式是使用 with as 语句操作上下文管理器(context manager),它能够帮助我们自动分配并且释放资源。
简单的理解,同时包含 __enter__() 和 __exit__() 方法的对象就是上下文管理器。常见构建上下文管理器的方式有 2 种,分别是基于类实现和基于生成器实现
使用 with as 操作已经打开的文件对象(本身就是上下文管理器),无论期间是否抛出异常,都能保证 with as 语句执行完毕后自动关闭已经打开的文件。
ith as 语句的基本语法格式为:
with 表达式 [as target]:
代码块
此格式中,用 [] 括起来的部分可以使用,也可以省略。其中,target 参数用于指定一个变量,该语句会将 expression 指定的结果保存到该变量中。with as 语句中的代码块如果不想执行任何语句,可以直接使用 pass 语句代替。
with open('first.txt', 'a') as f:
f.write("\nHello")
结果:
first.txt中增加了一行 Hello可以看到,通过使用 with as 语句,即便最终没有关闭文件,修改文件内容的操作也能成功。
pickle模块:实现Python对象的持久化存储
它能够实现任意对象与文本之间的相互转化,也可以实现任意对象与二进制之间的相互转化。也就是说,pickle 可以实现 Python 对象的存储及恢复。
值得一提的是,pickle 是 python 语言的一个标准模块,安装 python 的同时就已经安装了 pickle 库,因此它不需要再单独安装,使用 import 将其导入到程序中,就可以直接使用。
pickle 模块提供了以下 4 个函数供我们使用:
- dumps():将 Python 中的对象序列化成二进制对象,并返回;
- loads():读取给定的二进制对象数据,并将其转换为 Python 对象;
- dump():将 Python 中的对象序列化成二进制对象,并写入文件;
- load():读取指定的序列化数据文件,并返回对象。
以上这 4 个函数可以分成两类,其中 dumps 和 loads 实现基于内存的 Python 对象与二进制互转;dump 和 load 实现基于文件的 Python 对象与二进制互转。
pickle.dumps()函数
此函数用于将 Python 对象转为二进制对象,其语法格式如下:
dumps(obj, protocol=None, *, fix_imports=True)
此格式中各个参数的含义为:
- obj:要转换的 Python 对象;
- protocol:pickle 的转码协议,取值为 0、1、2、3、4,其中 0、1、2 对应 Python 早期的版本,3 和 4 则对应 Python 3.x 版本及之后的版本。未指定情况下,默认为 3。
- 其它参数:为了兼容 Python 2.x 版本而保留的参数,Python 3.x 中可以忽略。
import pickle
tup1 = ('Hello World', {1,2,3}, None)
#使用 dumps() 函数将 tup1 转成 p1
p1 = pickle.dumps(tup1)
print(p1)
结果:
b'\x80\x03X\x0b\x00\x00\x00Hello Worldq\x00cbuiltins\nset\nq\x01]q\x02(K\x01K\x02K\x03e\x85q\x03Rq\x04N\x87q\x05.'
pickle.loads()函数
此函数用于将二进制对象转换成 Python 对象,其基本格式如下:
loads(data, *, fix_imports=True, encoding='ASCII', errors='strict')
其中,data 参数表示要转换的二进制对象,其它参数只是为了兼容 Python 2.x 版本而保留的,可以忽略。
import pickle
tup1 = ('Hello World', {1,2,3}, None)
#使用 dumps() 函数将 tup1 转成 p1
p1 = pickle.dumps(tup1)
print(p1)
t1 = pickle.loads(p1)
print(t1)
结果:
b'\x80\x03X\x0b\x00\x00\x00Hello Worldq\x00cbuiltins\nset\nq\x01]q\x02(K\x01K\x02K\x03e\x85q\x03Rq\x04N\x87q\x05.'
('Hello World', {1, 2, 3}, None)在使用 loads() 函数将二进制对象反序列化成 Python 对象时,会自动识别转码协议,所以不需要将转码协议当作参数传入。并且,当待转换的二进制对象的字节数超过 pickle 的 Python 对象时,多余的字节将被忽略。
pickle.dump()函数
此函数用于将 Python 对象转换成二进制文件,其基本语法格式为:
dump (obj, file,protocol=None, *, fix mports=True)
其中各个参数的具体含义如下:
- obj:要转换的 Python 对象。
- file:转换到指定的二进制文件中,要求该文件必须是以"wb"的打开方式进行操作。
- protocol:和 dumps() 函数中 protocol 参数的含义完全相同,因此这里不再重复描述。
- 其他参数:为了兼容以前 Python 2.x版本而保留的参数,可以忽略。
import pickle
tup1 = ('Hello World', {1,2,3}, None)
#使用 dumps() 函数将 tup1 转成 p1
with open ("a.txt", 'wb') as f: #打开文件
pickle.dump(tup1, f) #用 dump 函数将 Python 对象转成二进制对象文件
运行完此程序后,会在该程序文件同级目录中,生成 a.txt 文件,但由于其内容为二进制数据,因此直接打开会看到乱码。
pickle.load()函数
此函数和 dump() 函数相对应,用于将二进制对象文件转换成 Python 对象。该函数的基本语法格式为:
load(file, *, fix_imports=True, encoding='ASCII', errors='strict')
其中,file 参数表示要转换的二进制对象文件(必须以 "rb" 的打开方式操作文件),其它参数只是为了兼容 Python 2.x 版本而保留的参数,可以忽略。
import pickle
tup1 = ('Hello World', {1,2,3}, None)
#使用 dumps() 函数将 tup1 转成 p1
with open ("a.txt", 'wb') as f: #打开文件
pickle.dump(tup1, f) #用 dump 函数将 Python 对象转成二进制对象文件
with open ("a.txt", 'rb') as f: #打开文件
t3 = pickle.load(f) #将二进制文件对象转换成 Python 对象
print(t3)
结果:
('Hello World', {1, 2, 3}, None)看似强大的 pickle 模块,其实也有它的短板,即 pickle 不支持并发地访问持久性对象,在复杂的系统环境下,尤其是读取海量数据时,使用 pickle 会使整个系统的I/O读取性能成为瓶颈。这种情况下,可以使用 ZODB。
ZODB 是一个健壮的、多用户的和面向对象的数据库系统,专门用于存储 Python 语言中的对象数据,它能够存储和管理任意复杂的 Python 对象,并支持事务操作和并发控制。并且,ZODB 也是在 Python 的序列化操作基础之上实现的,因此要想有效地使用 ZODB,必须先学好 pickle。
fileinput模块:逐行读取多个文件
但在某些场景中,可能需要读取多个文件的数据,Python 提供了 fileinput 模块,通过该模块中的 input() 函数,我们能同时打开指定的多个文件,还可以逐个读取这些文件中的内容。
fileinput 模块中 input() 该函数的语法格式如下:
fileinput.input(files="filename1, filename2, ...", inplace=False, backup='', bufsize=0, mode='r', openhook=None)
此函数会返回一个 FileInput 对象,它可以理解为是将多个指定文件合并之后的文件对象。其中,各个参数的含义如下:
- files:多个文件的路径列表;
- inplace:用于指定是否将标准输出的结果写回到文件,此参数默认值为 False;
- backup:用于指定备份文件的扩展名;
- bufsize:指定缓冲区的大小,默认为 0;
- mode:打开文件的格式,默认为 r(只读格式);
- openhook:控制文件的打开方式,例如编码格式等。
注意,和 open() 函数不同,input() 函数不能指定打开文件的编码格式,这意味着使用该函数读取的所有文件,除非以二进制方式进行读取,否则该文件编码格式都必须和当前操作系统默认的编码格式相同,不然 Python 解释器可能会提示 UnicodeDecodeError 错误。
和 open() 函数返回单个的文件对象不同,fileinput 对象无需调用类似 read()、readline()、readlines() 这样的函数,直接通过 for 循环即可按次序读取多个文件中的数据。
值得一提的是,fileinput 模块还提供了很多使用的函数(如表 1 所示),通过调用这些函数,可以帮我们更快地实现想要的功能。
| 函数名 | 功能描述 |
|---|---|
| fileinput.filename() | 返回当前正在读取的文件名称。 |
| fileinput.fileno() | 返回当前正在读取文件的文件描述符。 |
| fileinput.lineno() | 返回当前读取了多少行。 |
| fileinput.filelineno() | 返回当前正在读取的内容位于当前文件中的行号。 |
| fileinput.isfirstline() | 判断当前读取的内容在当前文件中是否位于第 1 行。 |
| fileinput.nextfile() | 关闭当前正在读取的文件,并开始读取下一个文件。 |
| fileinput.close() | 关闭 FileInput 对象。 |
文件描述符是一个文件的代号,其值为一个整数。后续章节将会介绍关于文件描述符的操作。
讲了这么多,接下来举个例子。假设使用 input() 读取 2 个文件,分别为 my_file.txt 和 file.txt,它们位于同一目录,且各自包含的内容如下所示:
import fileinput
#使用for循环遍历 fileinput 对象
for line in fileinput.input(files=('my_file.txt', 'file.txt')):
# 输出读取到的内容
print(line)
# 关闭文件流
fileinput.close()读取文件内容的次序,取决于 input() 函数中文件名的先后次序。
linecache模块用法:随机读取文件指定行
除了可以借助 fileinput 模块实现读取文件外,Python 还提供了 linecache 模块。linecache 模块擅长读取指定文件中的指定行。
如果我们想读取某个文件中指定行包含的数据,就可以使用 linecache 模块。
linecache 模块常用来读取 Python 源文件中的代码,它使用的是 UTF-8 编码格式来读取文件内容。这意味着,使用该模块读取的文件,其编码格式也必须为 UTF-8,否则要么读取出来的数据是乱码,要么直接读取失败(Python 解释器会报 SyntaxError 异常)。
| 函数基本格式 | 功能 |
|---|---|
| linecache.getline(filename, lineno, module_globals=None) | 读取指定模块中指定文件的指定行(仅读取指定文件时,无需指定模块)。其中,filename 参数用来指定文件名,lineno 用来指定行号,module_globals 参数用来指定要读取的具体模块名。注意,当指定文件以相对路径的方式传给 filename 参数时,该函数以按照 sys.path 规定的路径查找该文件。 |
| linecache.clearcache() | 如果程序某处,不再需要之前使用 getline() 函数读取的数据,则可以使用该函数清空缓存。 |
| linecache.checkcache(filename=None) | 检查缓存的有效性,即如果使用 getline() 函数读取的数据,其实在本地已经被修改,而我们需要的是新的数据,此时就可以使用该函数检查缓存的是否为新的数据。注意,如果省略文件名,该函数将检车所有缓存数据的有效性。 |
举个例子:
import linecache
import string
#读取string模块中第 3 行的数据
print(linecache.getline(string.__file__, 3))
# 读取普通文件的第2行
print(linecache.getline('hello.py', 2))
结果:
Public module variables:
name 为名字pathlib模块用法详解
pathlib 模块中包含的是一些类,它们的继承关系如图 1 所示。
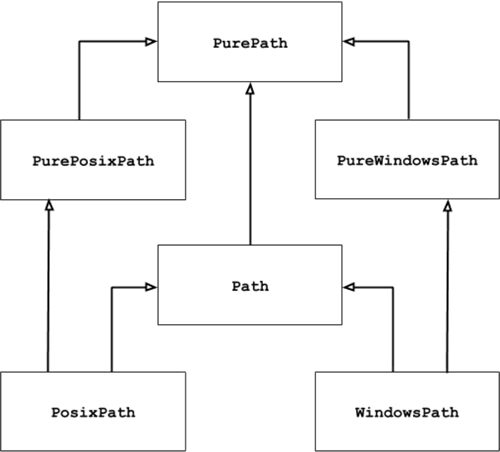
图 1 pathlib模块中类的组织结构
图 1 中,箭头连接的是有继承关系的两个类,以 PurePosixPath 和 PurePath 类为例,PurePosizPath 继承自 PurePath,即前者是后者的子类。
pathlib 模块的操作对象是各种操作系统中使用的路径(例如指定文件位置的路径,包括绝对路径和相对路径)。这里简单介绍一下图 1 中包含的几个类的具体功能:
- PurePath 类会将路径看做是一个普通的字符串,它可以实现将多个指定的字符串拼接成适用于当前操作系统的路径格式,同时还可以判断任意两个路径是否相等。注意,使用 PurePath 操作的路径,它并不会关心该路径是否真实有效。
- PurePosixPath 和 PureWindowsPath 是 PurePath 的子类,前者用于操作 UNIX(包括 Mac OS X)风格的路径,后者用于操作 Windows 风格的路径。
- Path 类和以上 3 个类不同,它操作的路径一定是真实有效的。Path 类提供了判断路径是否真实存在的方法。
- PosixPath 和 WindowPath 是 Path 的子类,分别用于操作 Unix(Mac OS X)风格的路径和 Windows 风格的路径。
注意,UNIX 操作系统和 Windows 操作系统上,路径的格式是完全不同的,主要区别在于根路径和路径分隔符,UNIX 系统的根路径是斜杠(/),而 Windows 系统的根路径是盘符(C:);UNIX 系统路径使用的分隔符是斜杠(/),而 Windows 使用的是反斜杠(\)。
PurePath 类的用法
PurePath 类(以及 PurePosixPath 类和 PureWindowsPath 类)都提供了大量的构造方法、实例方法以及类实例属性,供我们使用。
PurePath类构造方法
需要注意的是,在使用 PurePath 类时,考虑到操作系统的不同,如果在 UNIX 或 Mac OS X 系统上使用 PurePath 创建对象,该类的构造方法实际返回的是 PurePosixPath 对象;反之,如果在 Windows 系统上使用 PurePath 创建对象,该类的构造方法返回的是 PureWindowsPath 对象。
当然,我们完全可以直接使用 PurePosixPath 类或者 PureWindowsPath 类创建指定操作系统使用的类对象。
例如,在 Windows 系统上执行如下语句:
from pathlib import *
# 创建PurePath,实际上使用PureWindowsPath
path = PurePath('a.txt')
print(type(path))
结果:
<class 'pathlib.PureWindowsPath'>显然,在 Windows 操作系统上,使用 PurePath 类构造函数创建的是 PureWindowsPath 类对象。
读者可
除此之外,PurePath 在创建对象时,也支持传入多个路径字符串,它们会被拼接成一个路径格式的字符串。例如:
from pathlib import *
# 创建PurePath,实际上使用PureWindowsPath
path = PurePath('http:','www.baiducom','zhidao')
print(path)
结果:
http:\www.baiducom\zhidao可以看到,由于本机为 Windows 系统,因此这里输出的是适用于 Windows 平台的路径。如果想在 Windows 系统上输出 UNIX 风格的路径字符串,就需要使用 PurePosixPath 类。
值的一提的是,如果在使用 PurePath 类构造方法时,不传入任何参数,则等同于传入点‘.’(表示当前路径)作为参数。例如:
from pathlib import *
path = PurePath()
print(path)
path = PurePath('.')
print(path)
结果:
.
.另外,如果传入 PurePath 构造方法中的多个参数中,包含多个根路径,则只会有最后一个根路径及后面的子路径生效。例如:
from pathlib import *
path = PurePath('C://','D://','my_file.txt')
print(path)
结果:
D:\my_file.txt需要注意的是,如果传给 PurePath 构造方法的参数中包含有多余的斜杠或者点( . ,表示当前路径),会直接被忽略( .. 不会被忽略)。举个例子:
from pathlib import *
path = PurePath('C://./my_file.txt')
print(path)
结果:
C:\my_file.txtPurePath 类还重载各种比较运算符,多余同种风格的路径字符串来说,可以判断是否相等,也可以比较大小(实际上就是比较字符串的大小);对于不同种风格的路径字符串之间,只能判断是否相等(显然,不可能相等),但不能比较大小。
举个例子:
from pathlib import *
# Unix风格的路径区分大小写
print(PurePosixPath('C://my_file.txt') == PurePosixPath('c://my_file.txt'))
# Windows风格的路径不区分大小写
print(PureWindowsPath('C://my_file.txt') == PureWindowsPath('c://my_file.txt'))
结果:
False
True比较特殊的是,PurePath 类对象支持直接使用斜杠(/)作为多个字符串之间的连接符,例如:
from pathlib import *
path = PurePosixPath('C://')
print(path / 'my_file.txt')
结果:
C:/my_file.txt通过以上方式构建的路径,其本质上就是字符串,因此我们完全可以使用 str() 将 PurePath 对象转换成字符串。例如:
from pathlib import *
# Unix风格的路径区分大小写
path = PurePosixPath('C://','my_file.txt')
print(str(path))
结果:
C:/my_file.txtPurePath类实例属性和实例方法
表 1 中罗列出了常用的以下 PurePath 类实例方法和属性。由于从本质上讲,PurePath 的操作对象是字符串,因此表 1 中的这些实例属性和实例方法,实质也是对字符串进行操作。
| 类实例属性和实例方法名 | 功能描述 |
|---|---|
| PurePath.parts | 返回路径字符串中所包含的各部分。 |
| PurePath.drive | 返回路径字符串中的驱动器盘符。 |
| PurePath.root | 返回路径字符串中的根路径。 |
| PurePath.anchor | 返回路径字符串中的盘符和根路径。 |
| PurePath.parents | 返回当前路径的全部父路径。 |
| PurPath.parent | 返回当前路径的上一级路径,相当于 parents[0] 的返回值。 |
| PurePath.name | 返回当前路径中的文件名。 |
| PurePath.suffixes | 返回当前路径中的文件所有后缀名。 |
| PurePath.suffix | 返回当前路径中的文件后缀名。相当于 suffixes 属性返回的列表的最后一个元素。 |
| PurePath.stem | 返回当前路径中的主文件名。 |
| PurePath.as_posix() | 将当前路径转换成 UNIX 风格的路径。 |
| PurePath.as_uri() | 将当前路径转换成 URL。只有绝对路径才能转换,否则将会引发 ValueError。 |
| PurePath.is_absolute() | 判断当前路径是否为绝对路径。 |
| PurePath.joinpath(*other) | 将多个路径连接在一起,作用类似于前面介绍的斜杠(/)连接符。 |
| PurePath.match(pattern) | 判断当前路径是否匹配指定通配符。 |
| PurePath.relative_to(*other) | 获取当前路径中去除基准路径之后的结果。 |
| PurePath.with_name(name) | 将当前路径中的文件名替换成新文件名。如果当前路径中没有文件名,则会引发 ValueError。 |
| PurePath.with_suffix(suffix) | 将当前路径中的文件后缀名替换成新的后缀名。如果当前路径中没有后缀名,则会添加新的后缀名。 |
对于表 1 中的这些实例属性和实例方法的用法,这里不再举例演示,有兴趣的读者可自行尝试它们的功能。
Path类的功能和用法
和 PurPath 类相比,Path 类的最大不同,就是支持对路径的真实性进行判断。
从图 1 可以轻易看出,Path 是 PurePath 的子类,因此 Path 类除了支持 PurePath 提供的各种构造函数、实例属性以及实例方法之外,还提供甄别路径字符串有效性的方法,甚至还可以判断该路径对应的是文件还是文件夹,如果是文件,还支持对文件进行读写等操作。
和 PurePath 一样,Path 同样有 2 个子类,分别为 PosixPath(表示 UNIX 风格的路径)和 WindowsPath(表示 Windows 风格的路径)。
os.path模块常见函数用法
os.path 模块不仅提供了一些操作路径字符串的方法,还包含一些或者指定文件属性的一些方法,如表 1 所示。
| 方法 | 说明 |
|---|---|
| os.path.abspath(path) | 返回 path 的绝对路径。 |
| os.path.basename(path) | 获取 path 路径的基本名称,即 path 末尾到最后一个斜杠的位置之间的字符串。 |
| os.path.commonprefix(list) | 返回 list(多个路径)中,所有 path 共有的最长的路径。 |
| os.path.dirname(path) | 返回 path 路径中的目录部分。 |
| os.path.exists(path) | 判断 path 对应的文件是否存在,如果存在,返回 True;反之,返回 False。和 lexists() 的区别在于,exists()会自动判断失效的文件链接(类似 Windows 系统中文件的快捷方式),而 lexists() 却不会。 |
| os.path.lexists(path) | 判断路径是否存在,如果存在,则返回 True;反之,返回 False。 |
| os.path.expanduser(path) | 把 path 中包含的 "~" 和 "~user" 转换成用户目录。 |
| os.path.expandvars(path) | 根据环境变量的值替换 path 中包含的 "$name" 和 "${name}"。 |
| os.path.getatime(path) | 返回 path 所指文件的最近访问时间(浮点型秒数)。 |
| os.path.getmtime(path) | 返回文件的最近修改时间(单位为秒)。 |
| os.path.getctime(path) | 返回文件的创建时间(单位为秒,自 1970 年 1 月 1 日起(又称 Unix 时间))。 |
| os.path.getsize(path) | 返回文件大小,如果文件不存在就返回错误。 |
| os.path.isabs(path) | 判断是否为绝对路径。 |
| os.path.isfile(path) | 判断路径是否为文件。 |
| os.path.isdir(path) | 判断路径是否为目录。 |
| os.path.islink(path) | 判断路径是否为链接文件(类似 Windows 系统中的快捷方式)。 |
| os.path.ismount(path) | 判断路径是否为挂载点。 |
| os.path.join(path1[, path2[, ...]]) | 把目录和文件名合成一个路径。 |
| os.path.normcase(path) | 转换 path 的大小写和斜杠。 |
| os.path.normpath(path) | 规范 path 字符串形式。 |
| os.path.realpath(path) | 返回 path 的真实路径。 |
| os.path.relpath(path[, start]) | 从 start 开始计算相对路径。 |
| os.path.samefile(path1, path2) | 判断目录或文件是否相同。 |
| os.path.sameopenfile(fp1, fp2) | 判断 fp1 和 fp2 是否指向同一文件。 |
| os.path.samestat(stat1, stat2) | 判断 stat1 和 stat2 是否指向同一个文件。 |
| os.path.split(path) | 把路径分割成 dirname 和 basename,返回一个元组。 |
| os.path.splitdrive(path) | 一般用在 windows 下,返回驱动器名和路径组成的元组。 |
| os.path.splitext(path) | 分割路径,返回路径名和文件扩展名的元组。 |
| os.path.splitunc(path) | 把路径分割为加载点与文件。 |
| os.path.walk(path, visit, arg) | 遍历path,进入每个目录都调用 visit 函数,visit 函数必须有 3 个参数(arg, dirname, names),dirname 表示当前目录的目录名,names 代表当前目录下的所有文件名,args 则为 walk 的第三个参数。 |
| os.path.supports_unicode_filenames | 设置是否可以将任意 Unicode 字符串用作文件名。 |
下面程序演示了表 1 中部分函数的功能和用法:
from os import path
# 获取绝对路径
print(path.abspath("first.txt"))
# 获取共同前缀
print(path.commonprefix(['C://first.txt', 'C://a.txt']))
# 获取共同路径
print(path.commonpath(['http://www.biadu.com/zhidao/', 'http://www.biadu.com/picture/']))
# 获取目录
print(path.dirname('C://first.txt'))
# 判断指定目录是否存在
print(path.exists('first.txt'))
结果:
D:\PycharmProjects\pythonProject\first.txt
C://
http:\www.biadu.com
C://
Truefnmatch模块:用于文件名的匹配
fnmatch 模块主要用于文件名称的匹配,其能力比简单的字符串匹配更强大,但比使用正则表达式相比稍弱。如果在数据处理操作中,只需要使用简单的通配符就能完成文件名的匹配,则使用 fnmatch 模块是不错的选择。
fnmatch 模块中,常用的函数及其功能如表 1 所示。
| 函数名 | 功能 |
|---|---|
| fnmatch.filter(names, pattern) | 对 names 列表进行过滤,返回 names 列表中匹配 pattern 的文件名组成的子集合。 |
| fnmatch.fnmatch(filename, pattern) | 判断 filename 文件名,是否和指定 pattern 字符串匹配 |
| fnmatch.fnmatchcase(filename, pattern) | 和 fnmatch() 函数功能大致相同,只是该函数区分大小写。 |
| fnmatch.translate(pattern) | 将一个 UNIX shell 风格的 pattern 字符串,转换为正则表达式 |
fnmatch 模块匹配文件名的模式使用的就是 UNIX shell 风格,其支持使用如下几个通配符:
- *:可匹配任意个任意字符。
- ?:可匹配一个任意字符。
- [字符序列]:可匹配中括号里字符序列中的任意字符。该字符序列也支持中画线表示法。比如 [a-c] 可代表 a、b 和 c 字符中任意一个。
- [!字符序列]:可匹配不在中括号里字符序列中的任意字符。
例如,下面程序演示表 1 中一些函数的用法及功能:
import fnmatch
#filter()
print(fnmatch.filter(['dlsf', 'ewro.txt', 'te.py', 'youe.py'], '*.txt'))
#fnmatch()
for file in ['word.doc','index.py','first.txt']:
if fnmatch.fnmatch(file,'*.txt'):
print(file)
#fnmatchcase()
print([addr for addr in ['word.doc','index.py','first.txt','a.TXT'] if fnmatch.fnmatchcase(addr, '*.txt')])
#translate()
print(fnmatch.translate('a*b.txt'))
结果:
['ewro.txt']
first.txt
['first.txt']
(?s:a.*b\.txt)\Ztempfile模块:生成临时文件和临时目录
tempfile 模块专门用于创建临时文件和临时目录,它既可以在 UNIX 平台上运行良好,也可以在 Windows 平台上运行良好。
tempfile 模块中常用的函数,如表 1 所示。
| tempfile 模块函数 | 功能描述 |
|---|---|
| tempfile.TemporaryFile(mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None) | 创建临时文件。该函数返回一个类文件对象,也就是支持文件 I/O。 |
| tempfile.NamedTemporaryFile(mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None, delete=True) | 创建临时文件。该函数的功能与上一个函数的功能大致相同,只是它生成的临时文件在文件系统中有文件名。 |
| tempfile.SpooledTemporaryFile(max_size=0, mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None) | 创建临时文件。与 TemporaryFile 函数相比,当程序向该临时文件输出数据时,会先输出到内存中,直到超过 max_size 才会真正输出到物理磁盘中。 |
| tempfile.TemporaryDirectory(suffix=None, prefix=None, dir=None) | 生成临时目录。 |
| tempfile.gettempdir() | 获取系统的临时目录。 |
| tempfile.gettempdirb() | 与 gettempdir() 相同,只是该函数返回字节串。 |
| tempfile.gettempprefix() | 返回用于生成临时文件的前缀名。 |
| tempfile.gettempprefixb() | 与 gettempprefix() 相同,只是该函数返回字节串。 |
提示:表中有些函数包含很多参数,但这些参数都具有自己的默认值,因此如果没有特殊要求,可以不对其传参。
tempfile 模块还提供了 tempfile.mkstemp() 和 tempfile.mkdtemp() 两个低级别的函数。上面介绍的 4 个用于创建临时文件和临时目录的函数都是高级别的函数,高级别的函数支持自动清理,而且可以与 with 语句一起使用,而这两个低级别的函数则不支持,因此一般推荐使用高级别的函数来创建临时文件和临时目录。
此外,tempfile 模块还提供了 tempfile.tempdir 属性,通过对该属性赋值可以改变系统的临时目录。
下面程序示范了如何使用临时文件和临时目录:
import tempfile
# 创建临时文件
fp = tempfile.TemporaryFile()
print("fp.name :"+fp.name)
fp.write('两情若是久长时,'.encode('utf-8'))
fp.write('又岂在朝朝暮暮。'.encode('utf-8'))
# 将文件指针移到开始处,准备读取文件
fp.seek(0)
print(fp.read().decode('utf-8')) # 输出刚才写入的内容
# 关闭文件,该文件将会被自动删除
fp.close()
# 通过with语句创建临时文件,with会自动关闭临时文件
with tempfile.TemporaryFile() as fp:
# 写入内容
fp.write(b'Hello World!')
# 将文件指针移到开始处,准备读取文件
fp.seek(0)
# 读取文件内容
print(fp.read()) # b'Hello World!'
# 通过with语句创建临时目录
with tempfile.TemporaryDirectory() as tmpdirname:
print('创建临时目录', tmpdirname)
结果:
fp.name :C:\Users\HuYoo\AppData\Local\Temp\tmpjmfipe8l
两情若是久长时,又岂在朝朝暮暮。
b'Hello World!'
创建临时目录 C:\Users\HuYoo\AppData\Local\Temp\tmp1nyhjp76上面程序以两种方式来创建临时文件:
- 第一种方式是手动创建临时文件,读写临时文件后需要主动关闭它,当程序关闭该临时文件时,该文件会被自动删除。
- 第二种方式则是使用 with 语句创建临时文件,这样 with 语句会自动关闭临时文件。
上面程序最后还创建了临时目录。由于程序使用 with 语句来管理临时目录,因此程序也会自动删除该临时目录。
上面第一行输出结果就是程序生成的临时文件的文件名,最后一行输出结果就是程序生成的临时目录的目录名。需要注意的是,不要去找临时文件或临时文件夹,因为程序退出时该临时文件和临时文件夹都会被删除。
















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











