







核心对象:
1、FileSystem类
首先,我们翻译一下FileSystem类的文档,从宏观上把控这个类:
An abstract base class for a fairly generic filesystem. It
may be implemented as a distributed filesystem, or as a "local"
one that reflects the locally-connected disk. The local version
exists for small Hadoop instances and for testing.
一个通用的文件系统的抽象基类,它可以被应用于一个分布式的文件系统,或者作为一个“本地的”反映了本地磁盘的文件系统而存在,本地化的版本一般比较适合应用于较小的Hadoop实例或用于测试环境
All user code that may potentially use the Hadoop Distributed
File System should be written to use a FileSystem object. The
Hadoop DFS is a multi-machine system that appears as a single
disk. It's useful because of its fault tolerance and potentially
very large capacity.
所有的可能会使用到HDFS的用户代码在进行编写时都应该使用FileSystem对象,HDFS文件系统是一个跨机器的系统,并且是一个单独的磁盘(即根目录)的形式出现的,这样的方式非常有用,是因为它的容错机制和海量的容量
2、DistributedFileSystem类
Implementation of the abstract FileSystem for the DFS system.
This object is the way end-user code interacts with a Hadoop
DistributedFileSystem.
在分布式文件系统上,抽象的FileSystem类的实现子类,这个对象是末端的用户代码用来与Hadoop分布式文件系统进行交互的一种方式
3、DFSClient类
DFSClient can connect to a Hadoop Filesystem and
perform basic file tasks. It uses the ClientProtocol
to communicate with a NameNode daemon, and connects
directly to DataNodes to read/write block data.
Hadoop DFS users should obtain an instance of
DistributedFileSystem, which uses DFSClient to handle
filesystem tasks.
DFSClient类可以连接到Hadoop文件系统并执行基本的文件任务,它使用ClientProtocal来与一个NameNode进程通讯,并且直接连接到DataNodes上来读取或者写入块数据,HDFS的使用者应该要获得一个DistributedFileSystem的实例,使用DFSClient来处理文件系统任务
4、DFSOutputStream类
DFSOutputStream creates files from a stream of bytes.
DFSOutputStream从字节流中创建文件
The client application writes data that is cached internally by
this stream. Data is broken up into packets, each packet is
typically 64K in size. A packet comprises of chunks. Each chunk
is typically 512 bytes and has an associated checksum with it.
客户端写被这个流缓存在内部的数据,数据被切分成packets的单位,每一个packet大小是64K,一个packet是由chunks组成的,每一个chunk为512字节大小并且伴随一个校验和
When a client application fills up the currentPacket, it is
enqueued into dataQueue. The DataStreamer thread picks up
packets from the dataQueue, sends it to the first datanode in
the pipeline and moves it from the dataQueue to the ackQueue.
The ResponseProcessor receives acks from the datanodes. When a
successful ack for a packet is received from all datanodes, the
ResponseProcessor removes the corresponding packet from the
ackQueue.
当一个客户端进程填满了当前的包时,它就会被排入数据队列(dataQueue),DataStreamer线程从数据队列中获取包并在管线将它发送到第一个datanode中去,然后把它从数据队列移动至确认队列(ackQueue),响应处理器(ResponseProcessor)从datanodes中接收确认回执,当一个包成功确认的回执被从所有的datanodes接收到时,响应处理器就会从确认队列中移除相应的数据包
In case of error, all outstanding packets are moved from
ackQueue. A new pipeline is setup by eliminating the bad
datanode from the original pipeline. The DataStreamer now
starts sending packets from the dataQueue.
如果出现错误,所有未完成的包都会从确认队列中移除(同时会将packet移动到数据队列的末尾),通过从原始的管线中消除坏掉的datanode,一个新的管线被重新架设起来,DataStreamer开始从数据队列中发送数据包
HDFS Create执行机制

进入create,返回FSDataOutputStream

1、文件缓冲大小:


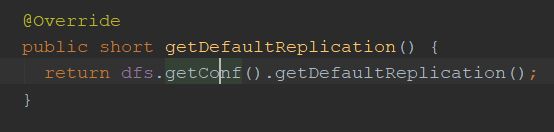
2、默认副本:

3、blockSize大小:


最终:
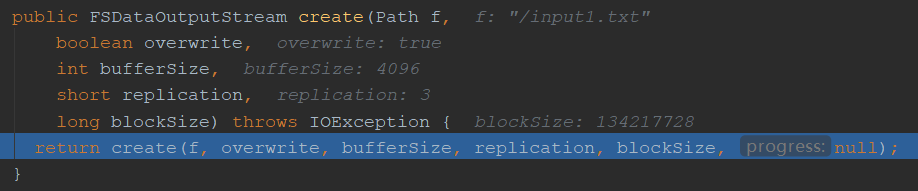
确定文件权限(默认的),是否可重写,副本,块大小等等








private HdfsFileStatus startFileInt(String src,
PermissionStatus permissions, String holder, String clientMachine,
EnumSet<CreateFlag> flag, boolean createParent, short replication,
long blockSize, CryptoProtocolVersion[] supportedVersions,
String ecPolicyName, boolean logRetryCache) throws IOException {
// 是否开启debug
if (NameNode.stateChangeLog.isDebugEnabled()) {
StringBuilder builder = new StringBuilder();
builder.append("DIR* NameSystem.startFile: src=").append(src)
.append(", holder=").append(holder)
.append(", clientMachine=").append(clientMachine)
.append(", createParent=").append(createParent)
.append(", replication=").append(replication)
.append(", createFlag=").append(flag)
.append(", blockSize=").append(blockSize)
.append(", supportedVersions=")
.append(Arrays.toString(supportedVersions));
NameNode.stateChangeLog.debug(builder.toString());
}
// 校验pathName是否等有效
if (!DFSUtil.isValidName(src) ||
FSDirectory.isExactReservedName(src) ||
(FSDirectory.isReservedName(src)
&& !FSDirectory.isReservedRawName(src)
&& !FSDirectory.isReservedInodesName(src))) {
throw new InvalidPathException(src);
}
// 是否建立副本
boolean shouldReplicate = flag.contains(CreateFlag.SHOULD_REPLICATE);
if (shouldReplicate &&
(!org.apache.commons.lang.StringUtils.isEmpty(ecPolicyName))) {
throw new HadoopIllegalArgumentException("SHOULD_REPLICATE flag and " +
"ecPolicyName are exclusive parameters. Set both is not allowed!");
}
INodesInPath iip = null;
boolean skipSync = true; // until we do something that might create edits
HdfsFileStatus stat = null;
BlocksMapUpdateInfo toRemoveBlocks = null;
checkOperation(OperationCategory.WRITE);
final FSPermissionChecker pc = getPermissionChecker();
// 对这段代码进行写锁
writeLock();
try {
checkOperation(OperationCategory.WRITE);
checkNameNodeSafeMode("Cannot create file" + src);
iip = FSDirWriteFileOp.resolvePathForStartFile(
dir, pc, src, flag, createParent);
// 校验block大小,不能小于minBlockSize
if (blockSize < minBlockSize) {
throw new IOException("Specified block size is less than configured" +
" minimum value (" + DFSConfigKeys.DFS_NAMENODE_MIN_BLOCK_SIZE_KEY
+ "): " + blockSize + " < " + minBlockSize);
}
// 是否建立副本,默认建立副本3个
if (shouldReplicate) {
blockManager.verifyReplication(src, replication, clientMachine);
} else {
// 建立擦除代码策略,默认为null,没看懂
final ErasureCodingPolicy ecPolicy = FSDirErasureCodingOp
.getErasureCodingPolicy(this, ecPolicyName, iip);
if (ecPolicy != null && (!ecPolicy.isReplicationPolicy())) {
checkErasureCodingSupported("createWithEC");
if (blockSize < ecPolicy.getCellSize()) {
throw new IOException("Specified block size (" + blockSize
+ ") is less than the cell size (" + ecPolicy.getCellSize()
+") of the erasure coding policy (" + ecPolicy + ").");
}
} else {
blockManager.verifyReplication(src, replication, clientMachine);
}
}
// 加密相关
FileEncryptionInfo feInfo = null;
if (!iip.isRaw() && provider != null) {
EncryptionKeyInfo ezInfo = FSDirEncryptionZoneOp.getEncryptionKeyInfo(
this, iip, supportedVersions);
// if the path has an encryption zone, the lock was released while
// generating the EDEK. re-resolve the path to ensure the namesystem
// and/or EZ has not mutated
if (ezInfo != null) {
checkOperation(OperationCategory.WRITE);
iip = FSDirWriteFileOp.resolvePathForStartFile(
dir, pc, iip.getPath(), flag, createParent);
feInfo = FSDirEncryptionZoneOp.getFileEncryptionInfo(
dir, iip, ezInfo);
}
}
skipSync = false; // following might generate edits
toRemoveBlocks = new BlocksMapUpdateInfo();
// 锁住目录
dir.writeLock();
try {
// 注意iip为,从路径上解析出来的InodeINfo(路径节点信息)
stat = FSDirWriteFileOp.startFile(this, iip, permissions, holder,
clientMachine, flag, createParent, replication, blockSize, feInfo,
toRemoveBlocks, shouldReplicate, ecPolicyName, logRetryCache);
} catch (IOException e) {
skipSync = e instanceof StandbyException;
throw e;
} finally {
dir.writeUnlock();
}
} finally {
writeUnlock("create");
// There might be transactions logged while trying to recover the lease.
// They need to be sync'ed even when an exception was thrown.
if (!skipSync) {
getEditLog().logSync();
if (toRemoveBlocks != null) {
removeBlocks(toRemoveBlocks);
toRemoveBlocks.clear();
}
}
}
return stat;
}
1、writeLock()
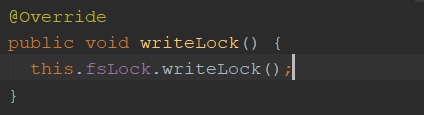

FSNamesystemLock 类 注释
* Mimics a ReentrantReadWriteLock but does not directly implement the interface
* so more sophisticated locking capabilities and logging/metrics are possible.
* {@link org.apache.hadoop.hdfs.DFSConfigKeys#DFS_NAMENODE_LOCK_DETAILED_METRICS_KEY}
* to be true, metrics will be emitted into the FSNamesystem metrics registry
* for each operation which acquires this lock indicating how long the operation
* held the lock for. These metrics have names of the form
* FSN(Read|Write)LockNanosOperationName, where OperationName denotes the name
* of the operation that initiated the lock hold (this will be OTHER for certain
* uncategorized operations) and they export the hold time values in
* nanoseconds. Note that if a thread dies, metrics produced after the
* most recent snapshot will be lost due to the use of
* {@link MutableRatesWithAggregation}. However since threads are re-used
* between operations this should not generally be an issue.
模拟ReentrantReadWriteLock,但不直接实现该接口
因此,更复杂的锁定功能和日志记录/度量是可能的。
{@link org.apache.hadoop.hdfs.DFSConfigKeys # DFS_NAMENODE_LOCK_DETAILED_METRICS_KEY}
实际上,指标将被发送到FSNamesystem指标注册中心
对于每一个获得该锁的操作,该锁表示操作的时间
锁住了。 这些指标具有表单的名称
FSN(Read|Write)LockNanosOperationName,其中OperationName为名称
初始化锁持有的操作(这肯定是OTHER)
未分类操作),并导出保存时间值
纳秒。 注意,如果线程死亡,则在
最近的快照将会由于使用而丢失
{@link MutableRatesWithAggregation}。 然而,由于线程是可重用的
在操作之间,这通常不是一个问题。
2、Min-block-size大小


走完后,input.txt 就创建成功了,返回HdfsFileStatus



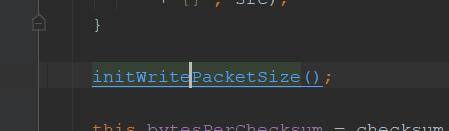



走完上述步骤后返回DataStreamer,然后开始start(),DataStramer相当于一个线程

DataStreamer作用
* The DataStreamer class is responsible for sending data packets to the
* datanodes in the pipeline. It retrieves a new blockid and block locations
* from the namenode, and starts streaming packets to the pipeline of
* Datanodes. Every packet has a sequence number associated with
* it. When all the packets for a block are sent out and acks for each
* if them are received, the DataStreamer closes the current block.
*
* The DataStreamer thread picks up packets from the dataQueue, sends it to
* the first datanode in the pipeline and moves it from the dataQueue to the
* ackQueue. The ResponseProcessor receives acks from the datanodes. When an
* successful ack for a packet is received from all datanodes, the
* ResponseProcessor removes the corresponding packet from the ackQueue.
*
* In case of error, all outstanding packets are moved from ackQueue. A new
* pipeline is setup by eliminating the bad datanode from the original
* pipeline. The DataStreamer now starts sending packets from the dataQueue.
DataStreamer类负责发送数据包到正在处理中的datanode。它检索一个新的block kid和block位置
从namenode,并开始流包到管道datanode。
每个包都有一个与之相关联的序列号。当一个块的所有包都被发送出去并对每个包进行ack
如果收到,则DataStreamer关闭当前块。
DataStreamer线程从dataQueue中获取数据包,并将其发送给dataQueue
管道中的第一个datanode,并将其从dataQueue移动到 ackQueue。
当一个客户端进程填满了当前的包时,它就会被排入数据队列(dataQueue),DataStreamer线程从数据队列中获取包并在管线将它发送到第一个datanode中去,然后把它从数据队列移动至确认队列(ackQueue),响应处理器(ResponseProcessor)从datanodes中接收确认回执,当一个包成功确认的回执被从所有的datanodes接收到时,响应处理器就会从确认队列中移除相应的数据包
















 4184
4184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











