






摘要
这是一个java爬虫入门的案例,可以简单的爬取商品的名称,价格,图片路径等。引入了两个依赖,jsoup可以直接对html解析,所采用的版本是---1.15.4。而另一个依赖lombok是简化,其作用方便后续扩展等。
关键词:爬虫,jsoup,lombo
目录
1 程序实现
1.1 爬取商品信息实现流程
- 爬取一个商品信息首先我们要知道,商品具体在哪个地方,通俗的来说就是网络路径,创建路径地址。如图1.1所示:

- 有了地址后,我们就需要对其进行解析,解析成---Document对象,文档的根节点,使用Jsoup.parse(生成一个URL对象(商品信息地址),解析不超过的毫秒数)。如图1.2所示:

图1.2解析URL - 获得文档的根节点后 ---Document后即可获得HTML页面中的元素,使用 document.getElementById(div的id名称),如图1.3所示:
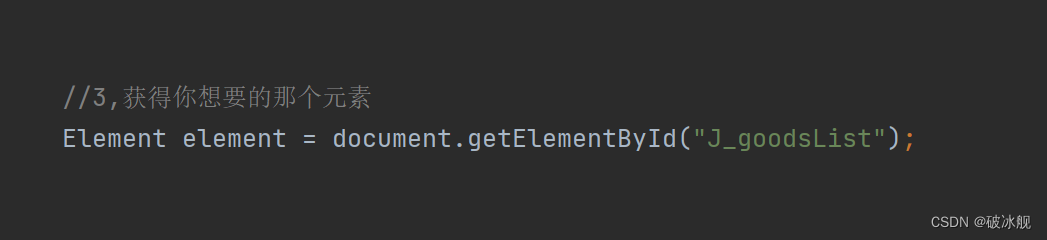
图1.3根据ID获取元素 - 由于我们是获取商品的图片,名称和价格,这个是在<li>列表下我们我们还需要进一步获取,方才可以获得我们需要的信息使用element.getElementByTag(需要获取的元素,包括这个元素下的元素和递归元素)如图1.3所示:
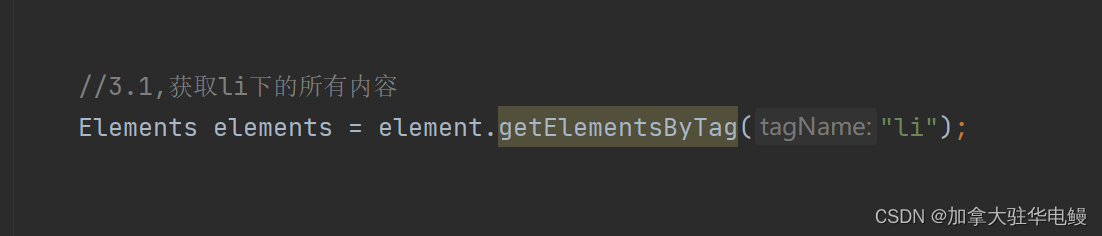
图1.3获取li列表和他包括下的元素 - 此时我们就可以获取,商品的图片,价格以及名称,但这里我们采用list集合存储有一定的扩展性,且图片的加载是使用懒加载,可以正常访问的速度,所用方法如3.1所示一样,不重复叙述,如图1.4所示:
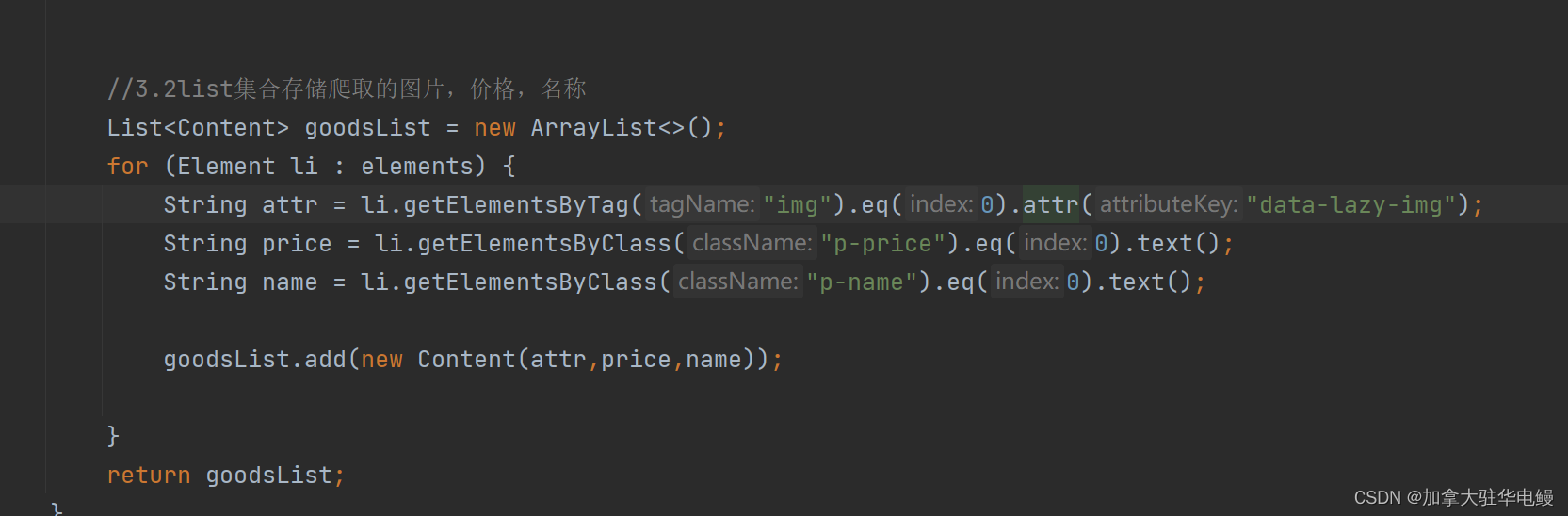
如图1.4所示:
1.2 完整代码
- 爬取代码方法块
public List<Content> parseJD(String key) throws IOException { //1,加载url路径 String url = "https://search.jd.com/Search?keyword="+key+"&enc=utf-8&wq=java&pvid=66f97edafd7e4bf48275bee26ed2abcd"; //2,解析url Document document = Jsoup.parse(new URL(url), 5000); //3,获得你想要的那个元素 Element element = document.getElementById("J_goodsList"); //3.1,获取li下的所有内容 Elements elements = element.getElementsByTag("li"); //3.2list集合存储爬取的图片,价格,名称 List<Content> goodsList = new ArrayList<>(); for (Element li : elements) { String attr = li.getElementsByTag("img").eq(0).attr("data-lazy-img"); String price = li.getElementsByClass("p-price").eq(0).text(); String name = li.getElementsByClass("p-name").eq(0).text(); goodsList.add(new Content(attr,price,name)); } return goodsList; } - 实体类 采用lombok注解,节简代码
@Data @NoArgsConstructor @AllArgsConstructor public class Content { private String attr; private String price; private String name; } - pom.xml引入Jsoup,lombok依赖以及版本
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.15.4</version> </dependency> <!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.24</version> <scope>provided</scope> </dependency>2 总结
本次使用Jsoup解析网页,对网页中的标签进行一步一步解析查找,获取想要的信息,在使用实体类进行扩展,但没有实现将其以文件形式持久化保存,和没有页面进行绑定简化操作,还有很多后续的优化。















 2068
2068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









