







目录
简介
Data Query Language 数据查询语言
MySQL客户端(控制台) ,通过一系列的命令发送给MySQL服务器,查询(检索)指定的数据
特征:执行DQL之前和执行DQL之后数据库表中的数据不会发生任何变化
-- 语法
select -- 筛选列名称
from -- 确定表名称
where -- where后面的条件,进行行过滤,过滤掉不满足条件的行
group by -- 对列进行分组
having -- 行过滤
order by -- 排序
limit -- 返回限制的行数1.1 查询所有的数据
首先我们先建一张表
use study0824;
drop table if exists student;
create table student(
stuNumber int auto_increment primary key,
`name` varchar(50),
gender varchar(10),
age int,
major varchar(50)
)default charset=utf8;
insert into student values(default,'张三','男','20','计科');
insert into student values(default,'李四','女','19','土木');
insert into student values(default,'王五','男','19','数统');
insert into student values(default,'赵六','男','21','外院');
insert into student values(default,'萧炎','男','20','计科');
insert into student values(default,'李七夜','男','22','文院');
insert into student values(default,'安澜','女','22','体院');
insert into student values(default,'木婉清','女','20','土木');表的效果如下:

此时我们查询student表中的所有数据
select *
from student;
结果同上图
1.2 查询指定的列
场景: 查询student表中的学号和名字
select stuNumber,`name` from student;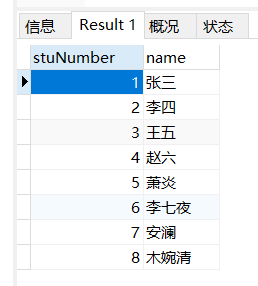
1.3 列别名
别名就是小名
使用别名的目的:让查询的结果更友好
列别名通常写在列名称的后面,列名称和列别名之间有一个空格
SELECT
stuNumber 学号,
`name` 姓名,
gender 性别,
age 年龄,
major 专业
FROM
student;
1.4 表别名
使用表别名目的:提高DQL的可读性,为后面学习多表联合查询做铺垫
表别名写在表名称的后面,表名称和表别名之间有一个空
SELECT
stuNumber 学号,
`name` 姓名,
gender 性别,
age 年龄,
major 专业
FROM
student 学生表;1.5 DQL的算术运算符
MySQL只支持4种算数运算符。
MySQL的算数运算符可以跟列名称一起使用,通常对某一列数数据进行算术运
场景: 把学生表的年龄都加1
-- 把学生表的年龄加1
SELECT
stuNumber,
`name`,
gender,
age + 1,
major
FROM
student;
1.6 DQL的比较运算符
> >= < <=
!=和<> 都表示不等于
= 表示等于 ,MySQL没有 == 运算符比较运算符用在from之后,不能用在from之前,对条件进行过滤,过滤掉不满足条件的记录。
场景: 查询年龄大于20的学生
-- 查询年龄大于20的学生
SELECT
*
FROM
student
WHERE
age > 20;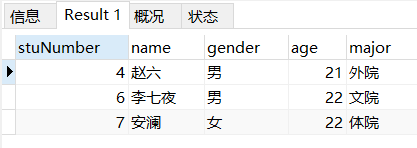
执行顺序:from(确定要查询哪张表)---> where(过滤不满足的条件) -----> select(选择结果集中的列)
小结:where必须写在from关键字的后面,作为from关键字的过滤条件
场景: 查询不是计科的所有学生的信息
-- 查询不是计科的所有学生的信息
SELECT
*
FROM
student
WHERE
major <> '计科';
1.7 DQL的逻辑运算符
Java: && | | !
并且 或者 非
MySQL: and or not
场景: 查询专业为土木并且年龄为20的学生
-- 查询专业为土木并且年龄为20的学生
SELECT
*
FROM
student
WHERE
major = '土木'
AND age = '20';
场景: 查询专业为土木或者年龄为20的学生
-- 查询专业为土木或者年龄为20的学生
SELECT
*
FROM
student
WHERE
major = '土木'
OR age = '20'; 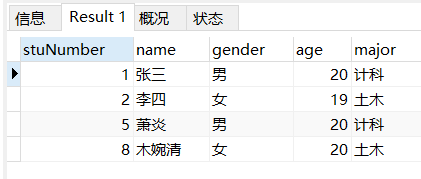
场景: 查询专业为土木并且年龄不为20的学生
-- 查询专业为土木并且年龄不为20的学生
SELECT
*
FROM
student
WHERE
major = '土木'
AND NOT age = '20';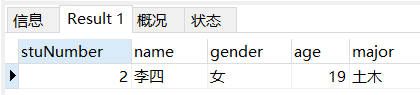
1.8 区间查询
between and 关键字 在.....之间
场景: 查询年龄在18-20岁之间所有学生的信息
-- 查询年龄在18-20岁之间所有学生的信息
SELECT
*
FROM
student
WHERE
age BETWEEN 18
AND 20;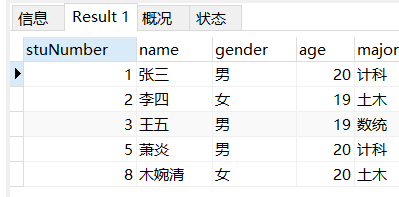
1.9 in集合查询
in 关键字 在.....里面
场景: 查询专业是计科、文院、外院的所有学生的信息
-- 查询专业是计科、文院、外院的所有学生的信息
SELECT
*
FROM
student
WHERE
major IN ( '计科', '文院', '外院' );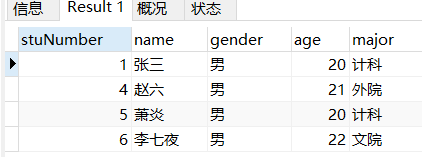
1.10 like模糊查询
like 关键字 像......一样
语法:where 字段名称 like '要查找的字符串%'
%表示模糊匹配多个字符
要查找的字符串必须写在一对半角单引号里面
模糊查询有三种场景:前面精确后面模糊、前面模糊后面精确、先后模糊中间精确
1.10.1 前面精确后面模糊
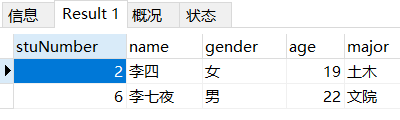
场景: 查询所有姓李的学生信息
-- 查询所有姓李的学生信息
SELECT
*
FROM
student
WHERE
`name` LIKE '李%';小结:like关键字通常用在where后面 like查询的数据类型通常是字符串类型
1.10.2 前面模糊后面精确
语法:where 字段名称 like '%要查找的字符串'
场景: 查询所有名字以三结尾的学生信息
-- 查询所有名字以三结尾的学生信息
SELECT
*
FROM
student
WHERE
`name` LIKE '%三';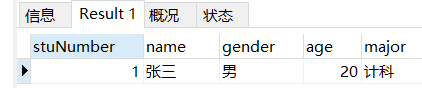
1.10.3 前后模糊中间精确
语法:where 字段名称 like '%要查找的字符串%'
场景: 查询名字中带有安的学生信息
-- 查询名字中带有安的学生信息
SELECT
*
FROM
student
WHERE
NAME LIKE '%安%';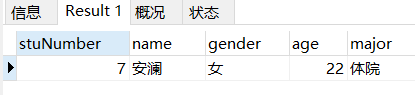
1.11 distinct过滤掉重复的行
场景: 查询所有学生的专业,不能重复
-- 查询所有学生的专业,不能重复
SELECT DISTINCT
major
FROM
student;
小结:distinct关键字表示过滤掉重复的行,后面跟列名称
MySQL的DQL查询默认都是大写,我们如果用小写定义DQL,那么在执行的时候统一转换为大写
1.12 聚合函数
MySQL支持5个聚合函数,用于对查询结果集做汇总
count(计数)、sum(求总和)、avg(求平均值)、max(计算最大值)、min(计算最小值)
特征:每个聚合函数查询结果只能是"单行单列"
列名称作为聚合函数的参数,参数类型最好使用数值类
1.12.1 count
通常获取结果集总行数
场景: 查询student表中有多少行数据
-- 查询student表中有多少行数据
SELECT
count( stuNumber )
FROM
student;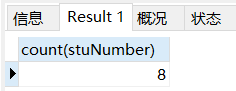
1.12.2 sum
计算某一列的和
场景: 查询所有学生年龄的总和
-- 查询所有学生年龄的总和
SELECT
sum( age )
FROM
student;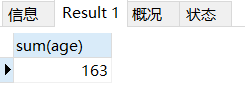
1.12.4 max
计算某一列的最大值
场景: 查询学生表的最大年龄
-- 查询学生表的最大年龄
SELECT
max( age )
FROM
student;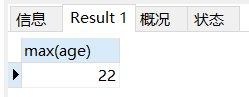
1.12.4 min
计算某一列的最小值
和max用法相同,不再赘述
1.12.5 avg
计算某一列的平均值
场景: 查询所有学生的平均年龄
-- 查询所有学生的平均年龄
SELECT
avg( age )
FROM
student;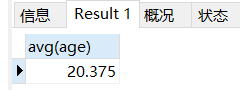
1.13 group by分组和汇总查询
分组关键字: group by
group by 将表中的数据分成若干组
语法:
select 列名称,聚合函数
from 表
group by 列名称[列别名];
场景: 查询每个专业的年龄总和
-- 查询每个专业的年龄总和
SELECT
major,
sum( age )
FROM
student
GROUP BY
major;
注意:如果一个select查询语句有where和group by,那么group by必须写在where的后面。
场景: 查询每个专业的年龄总和,但不包括学号为5的学生
-- 查询每个专业的年龄总和,但不包括学号为5的学生
SELECT
major,
sum( age )
FROM
student
WHERE
stuNumber <> 5
GROUP BY
major;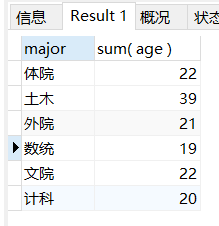
1.14 having
having跟where关键字一样都用于行过滤,但是where不支持聚合函数,如果对聚合函数进行过滤此时使用having关键字。
场景: 在上一个场景的基础上统计年龄大于20的年龄总和
-- 在上一个场景的基础上统计年龄大于20的年龄总和
SELECT
major,
sum( age )
FROM
student
WHERE
stuNumber <> 5
GROUP BY
major
HAVING
sum( age ) > 20;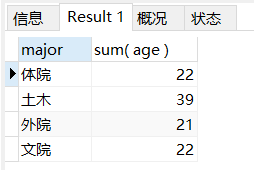
1.15 order by排序
排序关键字: order by
语法 : order by 列名称 或者 列别名 asc 或者 desc
asc 升序排序
desc 降序排序
场景: 在上一个场景的基础上对年龄总和进行降序排序
-- 在上一个场景的基础上对年龄总和进行降序排序
SELECT
major,
sum( age )
FROM
student
WHERE
stuNumber <> 5
GROUP BY
major
HAVING
sum( age ) > 20
ORDER BY
sum( age ) DESC;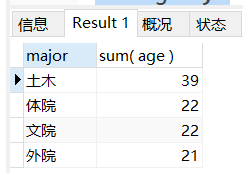
1.16 limit返回最大限制的行数
关键字 limit
limit限制最多返回的行数,工作中通常用户分页查询
limit n; 此时n表示最多返回n表
limit m , n ; 此时m表示下标,n表示最多返回n条
场景: 查询第三行后面三行的学生信息
-- 查询第三行后面三行的学生信息
SELECT
*
FROM
student
LIMIT 3,
3;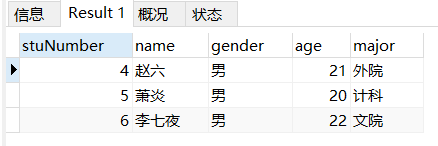
1.17 多表联合查询
将多个表数据合并成一张表(内存表),简称:化零为整。常用的多表联合查询:内连接(inner join)、左外连接(left join)、右外连接(right join)、自连接、全连接(union union all)。
1.17.1 内连接
A∩B:A表与B表的交集
关键字 inner join on
inner join查询多张表条件都满足的数据(A表和B表的交集)
on 条件过滤,过滤掉不满足条件的语
此时再创建一个院系表
drop table if exists departments;
create table departments(
id int auto_increment primary key,
major varchar(50)
)default charset=utf8;插入若干条记录
insert into departments values(default,'计科');
insert into departments values(default,'土木');
insert into departments values(default,'数统');
insert into departments values(default,'外院');
insert into departments values(default,'文院');
insert into departments values(default,'体院');场景: 查询学生学号、学生姓名、学生专业编号
-- 查询学生学号、学生姓名、学生专业编号
SELECT
student.stuNumber,
student.`name`,
departments.id
FROM
student
INNER JOIN departments ON student.major = departments.major;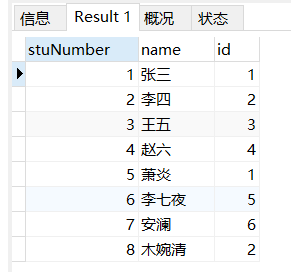
此外还可以在where上指定条件
SELECT
student.stuNumber,
student.`name`,
departments.id
FROM
student,
departments
WHERE
student.major = departments.major;结果同上
上面的场景,使用表名称.列名称指定查询哪个表的列,除此之外还可以使用表别名.列名称,这样做的好处让DQL更加简洁
SELECT
s.stuNumber,
s.`name`,
d.id
FROM
student s,
departments d
WHERE
s.major = d.major;小结:多表联合查询在指定列时必须使用"表名称".列名称,或者"表别名".列名称。因为必须告诉MySQL服务器你的列属于那张表。
1.17.2 左外连接
A - A∩B 查询两张表都满足的数据,以及左边表(A表)独有的数据(以左边表为主查询表)。
A - A∩B A表的数据 - A交B的数据
关键字:left join on
1.17.3 右外连接
B - A∩B 查询两张表都满足的数据,以及右边表独有的数据(以右边表为主查询表)。
关键字:right join on
1.17.4 合并查询
概念:将多个DQL语句合并成一个结果集
关键字:union all 和 union
union all 将多个DQL语句合并成一个结果集,不会去掉重复的数据
union 将多个DQL语句合并成一个结果集,会去掉重复的数据
-- 查询院系是计科的所有学生信息
-- 查询所有年龄为18的学生信息
SELECT
*
FROM
student
WHERE
major = '计科' UNION ALL
SELECT
*
FROM
student
WHERE
age = '20';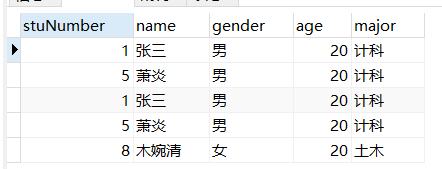
可以看到其中有相同的结果,当不想要相同的结果时就用union即可。
小结:union能够去掉多个结果集中重复的数据
union all由于没有去重,所以效率高于union
分布式:会学习分库分表,通常将多个查询结果集组装为一个结果
1.17.5 自连接
多个关联查询的表是同一张表,通过取别名的方式生成两张虚拟表
语法:
select 列名称
from 表名称 表别名1 inner/left/right join 表别名 表别名2;
















 3495
3495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











