






哈喽,大家好,木易巷来啦!
假设我们有一个包含出生日期的Excel文件,需要计算每个人的年龄,你会怎么做呢?具体情况如下图:
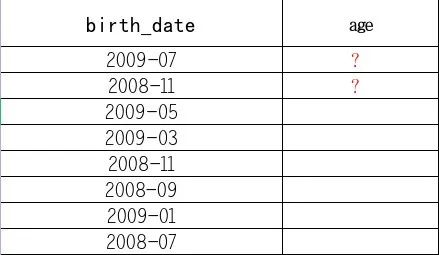
今天木易巷分享通过Python及其强大的pandas库,来实现从Excel文件中读取日期数据,计算年龄,并将结果存储回Excel文件中的过程。
话不多说,开干!
![]()
▍1、环境准备
在开始之前,请确保你的Python环境中已经安装了Pandas库。如果尚未安装,可以通过以下命令进行安装:
pip install pandas此外,为了处理Excel文件,您可能还需要安装openpyxl库(pandas用于读取.xlsx文件的引擎之一):
pip install openpyxl▍2、编写Python脚本
首先,我们需要导入必要的库,并定义一个函数来计算年龄:
import pandas as pdfrom datetime import datetime# 定义年龄计算函数def calculate_age(birth_date_series):# 获取当前日期today = pd.to_datetime(datetime.now())# 确保输入数据为datetime类型,错误则变为NaTbirth_date_series = pd.to_datetime(birth_date_series, errors='coerce')# 计算年龄,考虑是否已经过了生日ages = today.year - birth_date_series.dt.year# 使用布尔索引来调整年龄ages[(birth_date_series.dt.month > today.month) |((birth_date_series.dt.month == today.month) & (birth_date_series.dt.day > today.day))] -= 1# 处理NaT值,可以选择赋值为None或其他ages = ages.where(~birth_date_series.isna(), None)return ages
然后,我们读取Excel文件,并使用定义好的函数来计算年龄:
# 读取Excel文件file_name = 'birthdates.xlsx'try:df = pd.read_excel(file_name) # 确保文件名与您的Excel文件名一致except FileNotFoundError:print(f"文件 {file_name} 未找到,请检查文件路径和文件名。")exit()# 假设出生日期列名为'birth_date'if 'birth_date' in df.columns:df['age'] = calculate_age(df['birth_date'])else:print("出生日期列 'birth_date' 不存在于Excel文件中。")exit()# 查看前几行数据以验证结果print(df.head())
最后,我们将结果保存到一个新的Excel文件:
# 保存结果到新的Excel文件output_file_name = 'output_with_ages.xlsx'df.to_excel(output_file_name, index=False)print(f"结果已保存到 {output_file_name}")
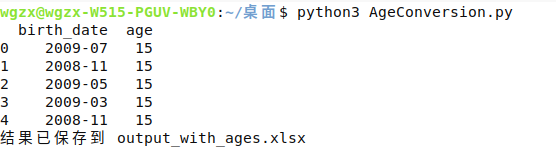
代码运行结果:
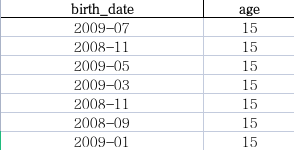
生成的“output_with_ages.xlsx”内容:
▍3、代码解析
首先定义了一个calculate_age函数,它接受一个包含日期的Pandas Series作为输入,并返回年龄Series。
使用pd.to_datetime确保所有日期都是datetime类型,错误则转换为NaT。
计算年龄时,我们考虑了是否已经过了生日,如果还没有到生日,则年龄减1。
使用where方法来处理NaT值,将它们替换为None。
读取Excel文件,检查出生日期列是否存在,然后计算年龄并保存结果。
好啦,今天的分享就到这里~
希望可以帮助到你!


















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











