







DynamoDB调查
1.DynamoDB表含义
- NoSQL型
- 必须要有主键:和MongoDB型NoSQL不同,也和MySQL等SQL型数据库不同
- 主键有约束
- 查询有约束
- 其他字段可以变化(增加/减少)
2.DynamoDB的主键
主键可以有一个或者两个字段。
- 如果是1个字段主键,那么这个字段可以唯一定位记录。这个primary key也叫:partition key
- 如果有2个字段主键,那么第一个字段叫:partition key;第二个字段叫:sorted key
高效查询,即Query操作;不高效查询Scan
1.Query操作必须指定partition,sorted key即使存在,也可以不指定,查询条件必须指定Partition key,用的必须为等式,不支持大于小于等其他操作;sorted key可以支持大于小于,文字开头,包含字符等其他操作。
2.Scan操作,全表查询,官方不推荐使用
- 单个分区键组成的主键:由一个分区键属性组成,他标识了唯一的项目,同时也觉得项目存储到哪个分区。DynamoDB根据内部散列函数计算分区键的值,其结果用来决定将项目存储到哪个分区。
- 分区键 + 排序键:在单个分区键基础上加上排序键,由这两个属性组成复合主键。同样,分区键决定项目存储到哪个分区,排序键决定在同一个分区内相同分区键的项目的排列顺序。
3.DynamoDB的组成
- 表:表示用来存储DynamoDB数据,它类似于关系型数据库的“表”
- 项目:表中可以有0 到 N(N > 0)个项目,它类似于关系型数据库的“行”,在DynamoDB中,项目数量是没有限制的。
- 属性:多个属性组成了一个项目,它类似于关系型数据库中的“字段”。DynamoDB中表除了主键外都是无架构的,因此在项目里可以有不同的属性、大小、数据类型
4.DynamoDB的读写限制
在创建表时需指定表的读取、写入的吞吐量。在生产环境中如果实际吞吐量超过了当前为DynamoDB设置的吞吐量,在经过重试后(如果DynamoDB Client设置了重试机制)最终将会抛出异常。
- 读取吞吐量单位:读取吞吐量取决于项目的大小以及是需要最终一致性还是强一致性
最终一致性的读取容量单位 = 2次4KB项目读 / 秒
强一致性的读取容量单位 = 1次4KB读 / 秒
如果一次读取大于4KB的项目,DynamoDB要消耗额外的读取容量单位。- 写入吞吐量单位:写入容量单位取决于写入项目的大小。
一个写入容量单位 = 1次最多1KB的项目写入 / 秒
如果需要写入大于1KB的项目,DynamoDB需要消耗额外的写入容量单位。- 其他限制:DynamoDB规定一个项目大小上限为400KB,如果项目的大小超过了这个限制将会消耗更多的容量单位。
一旦超过DynamoDB的限制,那么请求会被限制,这种错误在程序中是无法自动恢复的,因此需要合理设置吞吐量和一个项目大小
5.DynamoDB吞吐量预置值计算
吞吐量在创建表时候可以指定,在运行中的线上业务也可以通过DynamoDB后台可视化界面或提供的API动态调整。API方式相对来说非常灵活。注意:DynamoDB每天每个表仅允许向下调整4次,向上调整无限制。
这个预置值有一套计算方式,如果您的业务读写量可预估那么请参考下面公式
- 强一致性读取容量计算:向上取整(项目大小 / 4KB) * 预计每秒读取个数
比如:强一致性读要求,一个项目大小为3KB,期望每秒读80个项目。
3KB / 4KB = 0.75 ,向上取整后 = 1
1 * 80 = 80个读取容量单位- 最终一致性读取容量计算:与强一致性读取容量计算方式一样,在最终结果上 * 2
- 写入容量计算:向上取整(项目大小 / 1KB) * 预计每秒写入个数
比如:项目大小为512字节,期望打到每秒写入100个项目。
512字节 / 1KB = 0.5 向上取整 = 1
1 * 100 = 100个写入容量单位
6.命令行操作表语句
1.创建表
aws dynamodb create-table \ --table-name table1 \ --attribute-definitions \ AttributeName=id,AttributeType=S \ --key-schema AttributeName=id,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1 \ --endpoint-url http://localhost:9999–attribute-definitions 定义主键字段,如果有2个字段,可以分2行定义
–key-schema 定义主键,如果有2个字段,另外一个KeyType就是RANGE
–endpoint-url http://localhost:9999 表示:本地dynamodb的连接地址注意:
在用ycsb测试数据库的时候,默认测试的数据库名为usertable所以建表的时候数据库名取为usertable
2.数据库表操作
开启数据库:
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDb/-inMemory -port 8000-sharedDb:将使用单个数据库文件,而不是针对每个证书和区域使用不同的文件。如果指定 -sharedDb,那么所有 DynamoDB 客户端都将与同一组表交互,无论其区域和证书配置如何。
-inMemory:将在内存中运行,而不使用数据库文件。停止 DynamoDB 时,不会保存任何数据。请注意,不能同时指定 -dbPath 和 -inMemory。
-port : 可自己指定端口,常规使用8000端口
查看所有表命令:
aws dynamodb list-tables --endpoint-url http://localhost:9999查询单一表结构命令:
aws dynamodb describe-table --table-name table1 --endpoint-url http://localhost:9999删除表命令:
aws dynamodb delete-table --table-name table1 --endpoint-url http://localhost:9999添加一条记录:
aws dynamodb put-item --table-name table1 \ --item '{ "id": {"S": "1" },"name":{"S":"Tom"},"age":{"N":"10"}}' \ --endpoint-url http://localhost:9999 \ --return-consumed-capacity TOTAL–item 列出添加的记录字段
官方支持的数据类型有:
S– StringN– NumberB– BinaryBOOL– BooleanNULL– NullM– MapL– ListSS– String SetNS– Number SetBS– Binary Set按主键条件查询记录:
aws dynamodb query --table-name table1 --key-conditions file://test/key-conditions.json --endpoint-url http://localhost:9999 # condition/key.json文件内容 { "id":{ "AttributeValueList":[ { "S":"1" } ], "ComparisonOperator":"EQ" } }–key-condition后面跟参数file://代表文件,后面的文件其实位置要在当前文件下开始计算。
全表查询命令(不需要条件)
aws dynamodb scan --table-name table1 --endpoint-url http://localhost:9999查询表行数:
aws dynamodb scan --table-name usertable --select "COUNT"按条件删除表记录:
aws dynamodb delete-item --table-name table1 --key file://test/key.json --endpoint-url http://localhost:9999 # condition/key_delete.json文件内容 { "id": {"S": "2"} }创建索引:
索引有全局二级索引和本地二级索引
aws dynamodb update-table --table-name test-table1 --cli-input-json file://condition/create-index.json --endpoint-url http://localhost:9999{ "TableName":"test-table1", "AttributeDefinitions":[ { "AttributeName":"age", "AttributeType":"N" }, { "AttributeName":"name", "AttributeType":"S" } ], "GlobalSecondaryIndexUpdates":[ { "Create":{ "IndexName":"AgeAndNameIndex", "KeySchema":[ { "AttributeName":"age", "KeyType":"HASH" }, { "AttributeName":"name", "KeyType":"RANGE" } ], "Projection":{ "ProjectionType":"ALL" }, "ProvisionedThroughput":{ "ReadCapacityUnits":1, "WriteCapacityUnits":1 } } } ] }添加索引时必须向 UpdateTable 提供以下参数:
- TableName – 索引将关联到的表。
- AttributeDefinitions – 索引的键架构属性的数据类型。
- GlobalSecondaryIndexUpdates – 有关要创建的索引的详细信息:
- IndexName - 索引的名称。
- KeySchema – 用于索引主键的属性。
- Projection - 表中要复制到索引的属性。在此情况下,ALL 意味着复制所有属性。
- ProvisionedThroughput – 每秒需对此索引执行的读取和写入次数。(它与表的预配置吞吐量设置是分开的。)
ycsb
1.背景
YCSB,全称为“Yahoo!Cloud Serving Benchmark”,是雅虎开发的用来对云服务进行基础测试的工具,其内部涵盖了常见的NoSQL数据库产品,如Cassandra、MongoDB、HBase、Redis等等。在运行YCSB的时候,可以配置不同的workload和DB,也可以指定线程数&并发数等其他参数。
2.安装测试
安装
wget https://github.com/brianfrankcooper/YCSB/releases/download/0.15.0/ycsb-0.15.0.tar.gz tar xfvz ycsb-0.15.0.tar.gz cd ycsb-0.15.0
测试是否能运行
bin/ycsb.sh load basic -P workloads/workloada bin/ycsb.sh run basic -P workloads/workloadaLoad:加载数据。该阶段主要用于构造测试数据,ycsb会基于参数设定,往db里面构造测试需要的数据,
Run: 进行压力测试
basic:为数据库名字,yscb支持多种数据库,具体可在ycsb文件夹下查看
其他参数:
Options: -P file Specify workload file //workload文件 -cp path Additional Java classpath entries -jvm-args args Additional arguments to the JVM -p key=value Override workload property // 一些设置 -s Print status to stderr // 把状态达到stderr中 -target n Target ops/sec (default: unthrottled) // 每秒总共操作的次数 -threads n Number of client threads (default: 1) // 客户端线程数注意:
因为dynamodb默认数据库为usertable,必须需要依赖主键,所以要建文件特殊标明它的主键,可以自己选择文件所在的位置:
# Benchmark $YCSB_HOME/bin/ycsb load dynamodb -P workloads/workloada -P dynamodb.properties $YCSB_HOME/bin/ycsb run dynamodb -P workloads/workloada -P dynamodb.properties # Properties $DYNAMODB_HOME/conf/dynamodb.properties $DYNAMODB_HOME/conf/AWSCredentials.propertiesYCSB_HOME:ycsb的安装路径下
DYNAMODB_HOME:dynamodb的安装路径下
Dynamodb.properties
# 表示令牌 dynamodb.awsCredentialsFile = dynamodb/conf/AWSCredentials.properties dynamodb.primaryKey = id # endpoint代表的是dynamodb的地址,本地就用http://localhost:8000 dynamodb.endpoint = http://dynamodb.cn-northwest-1.amazonaws.com.cnAWSCredentials.properties
accessKey = X secretKey = X其中workloads表示测试所要求的条件:
workloada:混合了50%的读和50%的写;
workloadb:Read mostly workload,混合了95%的读和5%的写,该workload侧重于测试集群的读能力;
workloadc:Read only,100%只读;
workloadd:Read latest workload,插入数据,接着就读取这些新插入的数据;
workloade:Short ranges,短范围scan,不同于随机读,每个测试线程都会去scan一段数据;
workloadf:Read-modiy-wirte,读改写,客户端读出一个记录,修改它并将被修改的记录返回;总的模版为ycsb下的workloads文件下的 workload_template,因此可以根据模版去按照自己的要求自定义workload文件。
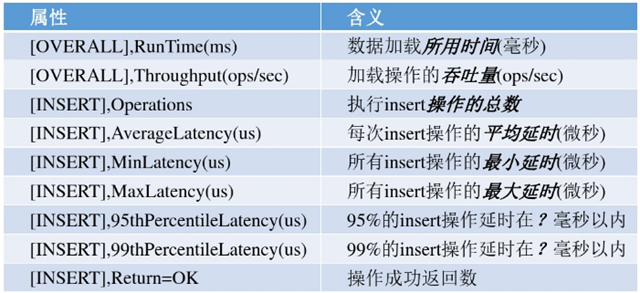
执行命令之后输出的常用的含义:
workload中常用参数的一些解释:
recordcount = 1000(表示load和run操作中,使用的YCSB实例记录数) operationcount = 1000(表示load和run操作中,使用的YCSB实例操作数) workload = com.yahoo.ycsb.workloads.CoreWorkload(要使用的工作负载类) readproportion = 0.5(默认是0.95,表示的是进行read的操作占所有操作的比例) updateproportion = 0.5(默认是0.05,表示的是进行update的操作占所有操作的比例) insertproportion = 0(默认是0,表示的是进行insert的操作占所有操作的比例) scanproportion = 0(默认是0,表示的是进行scan的操作占所有操作的比例) requestdistribution = zipfian(默认是uniform,应该使用什么分布来选择要操作的记录:uniform, zipfian, hotspot, sequential, exponential 和 latest) threadcount = 2(默认值是1,表示YCSB客户端线程数) readallfields = true(默认值是1,应该读取读取所有字段(true),只读取一个(false)) insertstart=0(第一个插入值的偏移量) writeallfields=false(在更新的时候写所有字段) fieldlengthdistribution=constant(字段长度分布形式,有constant,zipfian,uniform)insertorder=hashed(记录是按顺序插入还是伪随机插入,hashed还是ordered) hotspotdatafraction=0.2(构成热集的数据项的百分比) hotspotopnfraction=0.8(访问热集的操作百分比) table=usertable(要对其运行查询的数据库表的名称) #当measurementtype设置为raw时,测量将以以下csv格式输出为RAW数据点:“操作,测量的时间戳,我们的延迟”原始数据点在测试运行时收集在内存中。 每个数据点消耗大约50个字节(包括java对象开销)。 对于典型的100万到1000万次操作,大多数时候这应该适合存储器。 如果您计划每次运行执行数百万次操作,请考虑在使用RAW测量类型时配置具有更大RAM的计算机,或者将运行拆分为多次运行。 #(可选)可以指定输出文件以保存原始数据点。否则,原始数据点将写入stdout。如果输出文件已存在,将附加输出文件,否则将创建新的输出文件.measurement.raw.output_file =/tmp/ your_output_file_for_this_run measurementtype=histogram(如何呈现延迟测量timeseries,histogram,raw) measurement.histogram.verbose = false(使用直方图进行测量时是否发出单独的直方图桶) histogram.buckets=1000(直方图中要跟踪的延迟范围(毫秒)) timeseries.granularity=1000(时间序列的粒度(以毫秒为单位))
















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









