






目录
2、 FCN具体实现过程
FCN与CNN的核心区别就是FCN将CNN末尾的全连接层转化成了卷积层:以Alexnet为例,输入是2272273的图像,前5层是卷积层,第5层的输出是256个特征图,大小是66,即25666,第6、7、8层分别是长度是4096、4096、1000的一维向量。如下图所示:
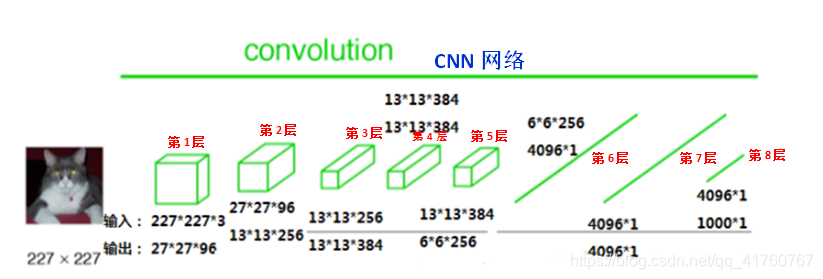
在FCN中第6、7、8层都是通过卷积得到的,卷积核的大小全部是1 * 1,第6层的输出是4096 * 7 * 7,第7层的输出是4096 * 7 * 7,第8层的输出是1000 * 7 * 7(7是输入图像大小的1/32),即1000个大小是77的特征图(称为heatmap),如下图所示: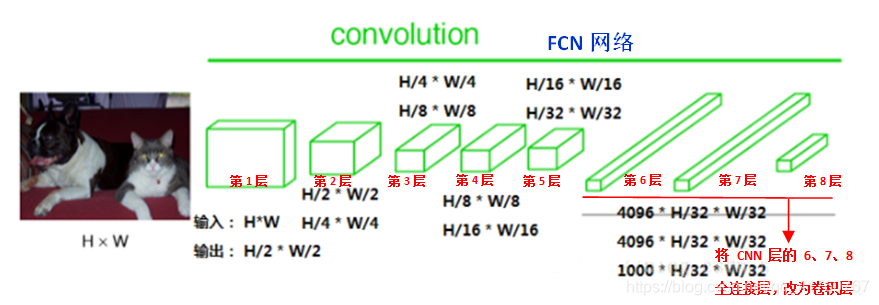
经过多次卷积后,图像的分辨率越来越低,为了从低分辨率的热图heatmap恢复到原图大小,以便对原图上每一个像素点进行分类预测,需要对热图heatmap进行反卷积,也就是上采样。论文中首先进行了一个上池化操作,再进行反卷积(上述所提到的上池化操作和反卷积操作,其实可以理解为上卷积操作),使得图像分辨率提高到原图大小。如下图所示:
跳级(strip)结构:对第5层的输出执行32倍的反卷积得到原图,得到的结果不是很精确,论文中同时执行了第4层和第3层输出的反卷积操作(分别需要16倍和8倍的上采样),再把这3个反卷积的结果图像融合,提升了结果的精确度:
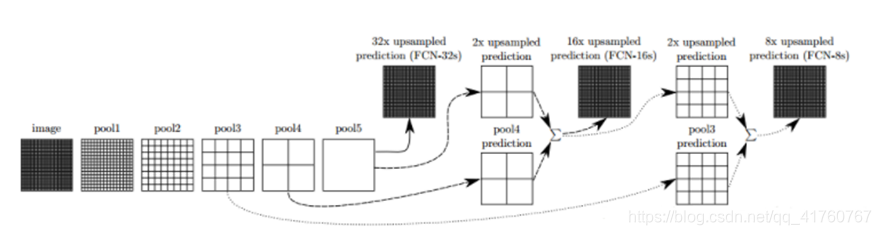
最后像素的分类按照该点在1000张上采样得到的图上的最大的概率来定。FCN可以接受任意大小的输入图像,但是FCN的分类结果还是不够精细,对细节不太敏感,再者没有考虑到像素与像素之间的关联关系,丢失了部分空间信息。
3、 FCN模型实现过程
3.1、模型训练
• 用AlexNet,VGG16或者GoogleNet训练好的模型做初始化,在这个基础上做fine-tuning,只需在末尾加上upsampling,参数的学习还是利用CNN本身的反向传播原理。
• 采用全图做训练,不进行局部抽样。实验证明直接用全图已经很高效。
FCN例子: 输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21,模型基于AlexNet。
• 蓝色:卷积层。
• 绿色:Max Pooling层。
• 黄色: 求和运算, 使用逐数据相加,把三个不同深度的预测结果进行融合:较浅的结果更为精细,较深的结果更为鲁棒。
• 灰色: 裁剪, 在融合之前,使用裁剪层统一两者大小, 最后裁剪成和输入相同尺寸输出。
• 对于不同尺寸的输入图像,各层数据的尺寸(height,width)相应变化,深度(channel)不变。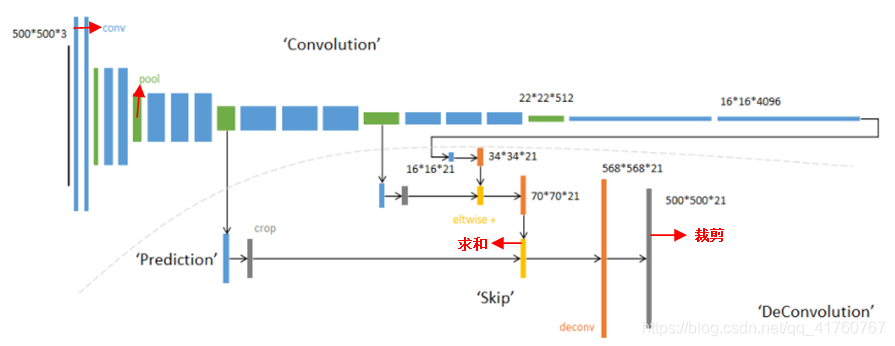
• 全卷积层部分进行特征提取, 提取卷积层(3个蓝色层)的输出来作为预测21个类别的特征。
• 图中虚线内是反卷积层的运算, 反卷积层(3个橙色层)可以把输入数据尺寸放大。和卷积层一样,升采样的具体参数经过训练确定。
1、 以经典的AlexNet分类网络为初始化。最后两级是全连接(红色),参数弃去不用。
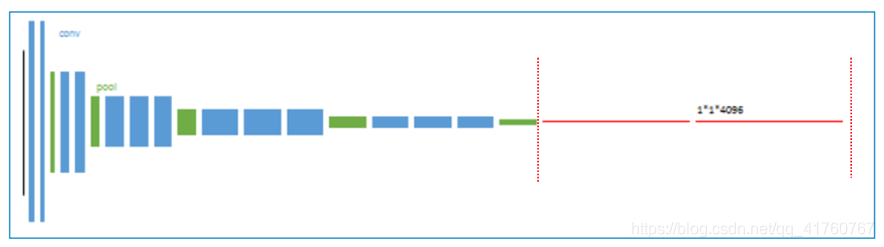
2、 反卷积(橙色)的步长为32,这个网络称为FCN-32s
从特征小图()预测分割小图(),之后直接升采样为大图。
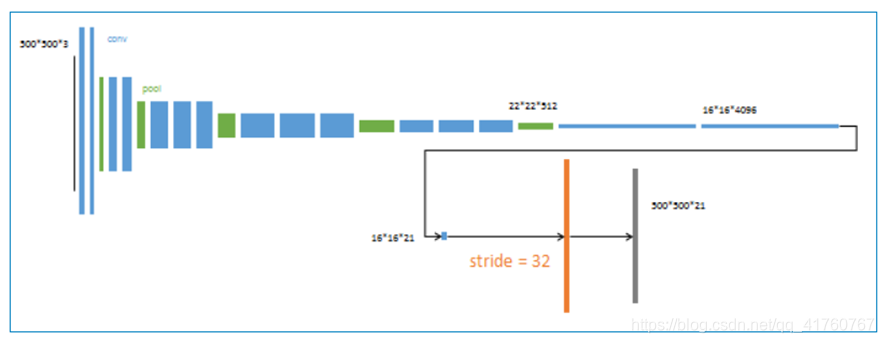
3、 第二次反卷积步长为16,这个网络称为FCN-16s
升采样分为两次完成(橙色×2), 在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。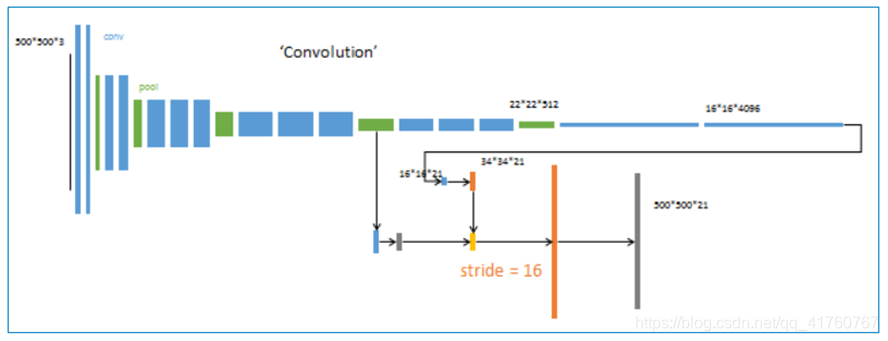
4、 第三次反卷积步长为8,记为FCN-8s。
升采样分为三次完成(橙色×3), 进一步融合了第3个pooling层的预测结果。
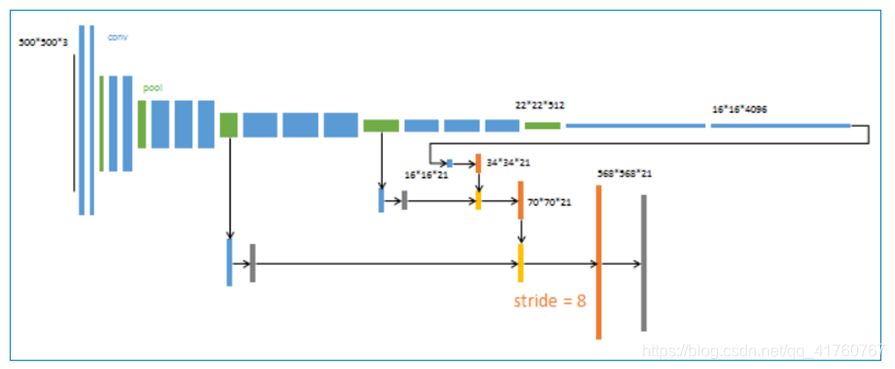
其他参数:
• minibatch:20张图片
• learning rate:0.001
• 初始化:分类网络之外的卷积层参数初始化为0
• 反卷积参数初始化为bilinear插值。最后一层反卷积固定位bilinear插值不做学习

总体来说,本文的逻辑如下:
• 想要精确预测每个像素的分割结果
• 必须经历从大到小,再从小到大的两个过程
• 在升采样过程中,分阶段增大比一步到位效果更好
• 在升采样的每个阶段,使用降采样对应层的特征进行辅助
缺点:
得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感
对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性
参考自:原文链接:https://blog.csdn.net/qq_41760767/article/details/97521397
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









