




 本文提出视觉语言建模网络VisionLAN,将视觉和语言信息作为整体,赋予视觉模型语言能力。训练时引入基于字符的遮挡特征图文本识别,测试时去掉部分模块,速度提高39%。还提出OST数据集评估性能,在多个基准测试中取得先进结果。
本文提出视觉语言建模网络VisionLAN,将视觉和语言信息作为整体,赋予视觉模型语言能力。训练时引入基于字符的遮挡特征图文本识别,测试时去掉部分模块,速度提高39%。还提出OST数据集评估性能,在多个基准测试中取得先进结果。
VisionLAN
摘要
该论文提出了一种视觉语言建模网络(VisionLAN),它将视觉和语言信息作为一个整体,直接直接赋予视觉模型语言的能力。在训练阶段引入了基于字符的遮挡特征图的文本识别,视觉模型在视觉线索被混淆时(遮挡、噪声等),利用字符的视觉纹理,还利用视觉语境的语言信息进行识别。由于语言信息与视觉特征一起获取,不需要额外的语言模型,因此VisionLAN的速度提高了39%,还自适应地考虑语言信息来增强视觉特征,实现准确的识别。提出了一个遮挡场景文本数据集评估确实特征视觉线索的情况下的性能。
介绍
视觉线索混乱的图像很难识别,场景文本图像包含视觉纹理和语言信息两层内容,受NLP启发,最近的研究重点转向获取语言信息辅助识别,视觉和语言模型的两步架构很流行。
存在的问题:一是额外的巨大计算成本,语言模型的成本随着单词长度的增加呈线性增长;二是聚合两个独立信息的难度。很难综合考虑和有效融合来自两个独立结构的视觉和语言信息来实现准确的识别。本文将两个问题归结为视觉模型缺乏语言能力,只关注字符的视觉纹理,而没主动学习语言信息。
受人类能够获得语言能力的认知过程的启发,我们使用视觉模型作为基础网络,在训练阶段引导其对遮挡字符进行推理。因此,训练视觉模型在视觉环境中主动学习语言信息。在测试阶段,视觉模型在视觉线索被混淆(如遮挡、噪声等)时,自适应地考虑视觉空间中的语言信息进行特征增强,有效地补充了被遮挡字符的特征,并正确突出了混淆字符的判别性视觉线索。据我们所知,这是在场景文本识别中首次赋予视觉模型感知语言能力的工作。我们把这种新的简单架构称为视觉语言建模网络(VisionLAN)。
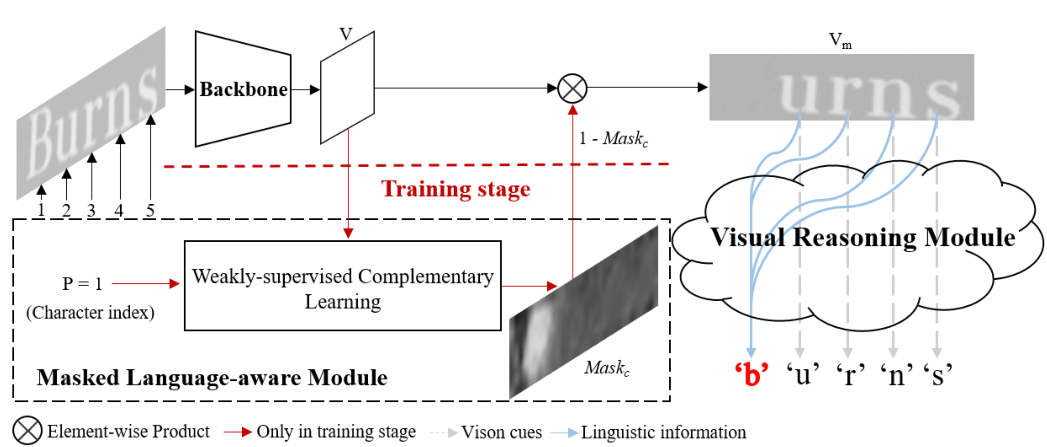
VisionLAN包括骨干网、掩码语言感知模块(mask Language-aware Module, MLM)和视觉推理模块(Visual Reasoning Module, VRM)三部分。
在训练阶段,首先从骨干网络中提取视觉特征V。然后MLM以视觉特征V和字符索引P作为输入,通过弱监督互补学习,在相应位置自动生成字符掩码映射Maskc。MLM的目的是通过在V中遮挡视觉信息来模拟缺失字符视觉线索的情况。为了在视觉纹理建模过程中考虑语言信息,提出了一种能够捕获视觉空间中远程依赖关系的VRM。VRM将被遮挡的特征映射Vm作为输入,并被引导进行词级预测。
在测试阶段,我们去掉了MLM,只使用VRM进行识别。由于语言信息是与视觉特征一起获取的,不需要额外的语言模型,因此VisionLAN引入了零计算成本来捕获语言信息,并且速度显著提高了39%(第4.4节)。
与以前的方法相比,VisionLAN在遮挡和低质量图像上获得了更强的鲁棒性,并在几个基准测试中获得了新的最先进的结果。此外,提出了一个遮挡场景文本(OST)数据集来评估缺失字符视觉线索情况下的性能。
本文的主要贡献如下:
1、提出了一种新的简单的场景文本识别体系结构。我们进一步可视化特征图,以说明VisionLAN如何主动使用语言信息来处理混淆的视觉线索(例如遮挡,噪声等)。
2、我们提出了一种弱监督互补学习方法,用于在仅单词级注释的MLM中生成准确的逐字符掩码映射。
3、提出了一种新的遮挡场景文本(OST)数据集来评估遮挡图像的识别性能。
与以前的方法相比,VisionLAN在七个基准(不规则和常规)和OST上实现了最先进的性能,并且具有简洁的管道。
相关工作
场景文本识别
场景文本识别(STR)一直是计算机视觉领域的一个长期研究课题。随着深度学习成为最有前途的机器学习工具,过去几年STR研究取得了重大进展。在本节中,我们根据是否使用语言规则将这些方法分为两类,即无语言方法和语言感知方法。
无语言方法将STR视为一种视觉分类任务,主要依靠视觉信息进行预测。CRNN通过结合CNN和RNN提取序列视觉特征,然后使用连接时间分类(Connectionist Temporal classification, CTC)解码器最大化所有路径的概率进行最终预测。Patel等自动为图像生成自定义词汇,从而大大提高了文本读取系统的性能。Zhang等人将文本识别视为一种视觉匹配任务,他们计算输入图像的视觉特征与预先定义的字母表之间的相似性映射,以预测文本序列。Liao等人将文本识别视为逐像素分类任务。类似地,Textscanner进一步提出了一个顺序映射,以确保从字符到单词的更准确的转录。一般来说,无语言方法在识别过程中忽略了语言规则,通常无法识别视觉线索混乱(如模糊、遮挡等)的图像。
语言感知方法试图利用语言规则来辅助识别过程。Lee等人使用RNN自动学习单词字符串中的顺序动态,而无需手动定义n -gram。Aster在识别前首先使用纠错模块,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9490
9490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









