








每日一题
SQL 优化的步骤
在工作中经常会遇到sql执行效率低的问题,在面试中也经常被问到查询效率低该如何优化,在下面较少几种优化的技巧与方式
慢sql的定位
可以通过下面几种方式进行慢sql的定位
- 启动慢sql查询日志定位执行效率较低的sql语句
- Druid监控统计功能
- 云数据库厂商提供的监测功能
分析执行计划
通过 explain 分析执行计划
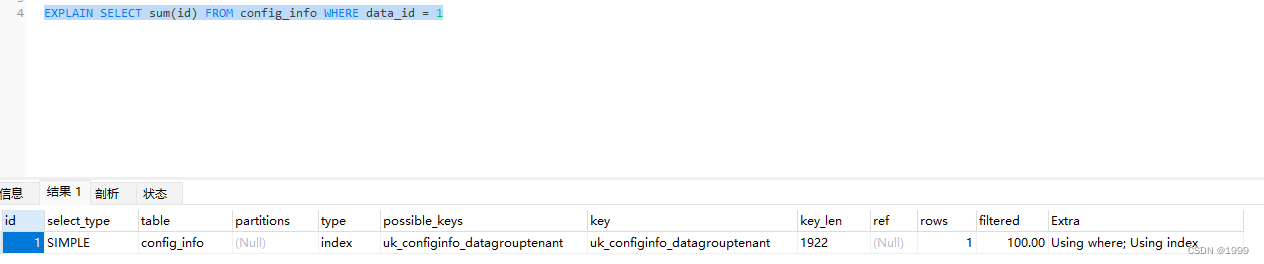
其中 type 表示表的连接类型
- system:表中只有一行,即常量表
- const :单表中最多只有一个匹配行,例如 主键和唯一索引
- eq_ref : 多表连接中使用 主键或唯一索引
- ref:多表连接中使用 普通索引
- range:单表中的范围查询 一般是带有 between 或者 where > 的查询, in() 和 or 列表 也会显示为范围查找。然而两者是不同的访问类型
- index: 对于前面的每一行,都通过查询索引来得到数据
- ALL:对于前面的每一行,通过全表扫描来得到数据
通过分析执行计划可以对sql进行相关优化,比如:
- sql 是否按照预期执行,是否有索引失效的存在
- 索引创建的是否合理,应优先考虑索引覆盖的场景
- sql 书写是否存在问题
等等
sql 层面优化技巧
- 不推荐使用 select * 导致 多余的io操作
- 使用小表驱动大表
- 使用 limit 代替 min 、 max
- in 和 exist 正确选择
- 通过索引过滤进行高效的分页
- 使用连接查询代替子查询
- join表的数量不应该超过三个 特殊情况可以在业务逻辑中处理 , 因为 join 不需要创建临时表
- 使用 or 时 保证 or 的每一列上都有独立的索引 或者使用 in 代替
- 如果查询包括 GROUP BY 但用户想要避免排序结果的消耗,则可以指定 ORDER BY NULL禁止排序
- 大批量插入数据 使用batch 操作,从同一客户插入很多行,尽量使用多个值表的 INSERT 语句,这种方式将大大 缩减客户端与数据库之间的连接、关闭等消耗
- 设计索引和写sql 优先考虑索引覆盖
数据库对象的优化
- 表的拆分
- 垂直拆分:将主键和一些常用的列放入一张表中,将主键和不常用的列放在另一张表中,这样一个数据页就可以存放更多数据较少 i/o 次数
- 水平拆分:根据一列数据将一张表的数据拆分成两个或多个相同的表,水平的拆分缺点就是会增加复杂度,使用 union 操作,在特定的场景下会发挥很大作用
- 大表的差分:降低了查询需要读的数据和索引的页数
- 表中的数据具有独立性: 例如 按照 地区、不同时期差分 ,每次查询只涉及拆分出的一张小表
- 把数据放在多个介质上: 例如 最近三个月的数据存放在一张表上 , 三个月前的放在另一张表上,超过一年的单独存储或者数据仓库或者不保留
- 合理的数据冗余
- 冗余列:多个表中的相同列,查询可以避免连接操作
- 派生列:增加的列来自于其他的表,由其他表中的数据经过计算生成,增加的派生列其作用是在查询时减少连接操作,避免使用集函数
- 重新组表:很多需要查看两个表连接出来的结果数据,则把这两个 表重新组成一个表来减少连接而提高性能
- 分割表 : 表的拆分
- 中间表:对于数据量较大的表,在其上进行统计查询通常会效率很低,使用中间表可以提高统计查询的效率
定期检查表
- 表存储是否存在大量硬盘碎片导致查询变慢
















 4282
4282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











