







去重操作
格式 select distinct 字段名 from 表名;
当字段名只有一个时,按照这个字段名去重,如果字段名有多个时,按照全部的字段名去重
先来看一下表格的全部内容 select * from stu;
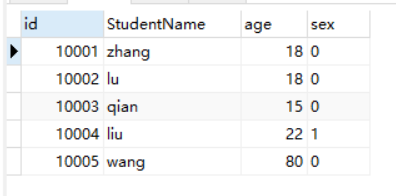
按照sex属性进行去重 select DISTINCT sex from stu;

去重后只剩两项
再来看看有多个字段名的情况 select DISTINCT sex,id from stu;
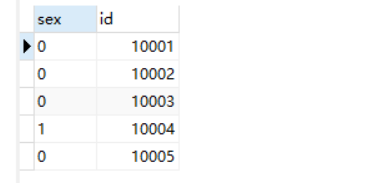
distinct后面有多个字段名时,所有字段名的值都相同才算重复。这里sex的值相同但是id的值不同,所以没有被去重。
聚合函数

例如
select count(age) from stu;
select count(*) from stu;
select max(age) from stu;
select min(age) from stu;
select sum(age) from stu;
select avg(age) from stu;
注意
- 括号里面的字段个数,应该只有一个字段或者是一个特殊符号,* 表示全部字段
- 聚合函数会默认忽视参数对应的值为null的行
比如count(*)查询到一共有10行,有一行的aga值为null,那么count(age)的结果为 9,忽略null值的那一行,结果减一 - 可以用distinct对括号里的字段去重
比如count(*)查询到一共有10行,有两行的aga值重复,那么count(distinct age)的结果为9,去重一行,结果减一 - 如果函数sum和avg括号内的字段类型不是数值,返回的结果都是0
在子查询中应用聚合函数
比如找到列表中所有年龄大于平均值的数据
select * from stu where age > (select avg(age) from stu);

concat 拼接函数
格式一:CONCAT(str1,str2,…)
select *,CONCAT(StudentName,'--',age) from stu;
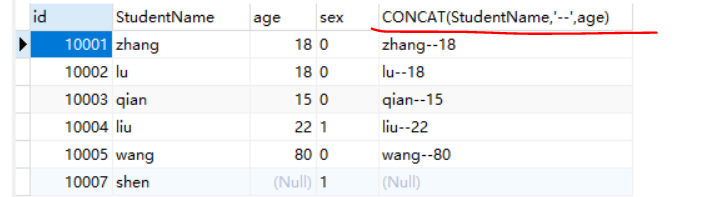
这里的列名太长可以取一个别名
select *,CONCAT(StudentName,'--',age) as info from stu;

格式二:CONCAT_WS(separator,str1,str2,…)
select *,CONCAT_WS('--',StudentName,age) as info from stu;
小数运算函数
- 四舍五入 round(x,d);
x:值
d:保留几位小数点
-- 四舍五入 结果为 1.3
select round(1.26,1);
- 向上取整 ceil(x); (直接向上取整,不会用四舍五入)
-- 向上取整 结果为 2
select ceil(1.4);
- 向下取整 floor(x);
-- 向下取整 结果为 1
select floor(1.6);
- 随机数 rand() (0-1之间)
-- 随机数(0-1之间)
select rand();
日期函数
-- 获取完整的日期时间 2021-11-05 23:12:21
select CURRENT_TIMESTAMP();
-- 只获取日期 2021-11-05
select CURRENT_DATE();
-- 只获取时间 23:12:36
select CURRENT_TIME();
时间的格式转换
date时间格式转字符串 date_format(date,format)
字符串转为date时间格式 str_to_date(str,formaat)
-- 时间格式转为字符串 2021-11-05 23:11:27
select date_format(CURRENT_TIMESTAMP(),'%Y-%m-%d %H:%m:%s');
-- 字符串转为时间格式 2021-11-05
select str_to_date('2021-11-05','%Y-%m-%d');
为什么要将字符串的时间数值转为date时间格式,因为类似于java的装箱拆箱,可以用特有的函数来操作date时间格式的数值
- 日期相减 DATEDIFF(expr1,expr2)
select DATEDIFF('2021-11-05','2021-11-01'); -- 结果为4
如果反过来 select DATEDIFF(‘2021-11-01’,‘2021-11-05’); 结果就会变成 -4
- 给日期添加指定的时间间隔
DATE_ADD(date,INTERVAL expr unit)
– INTERVAL关键字
– expr 是间隔的数值,正数是增加日期,负数是减少日期
– unit 是间隔的类型,可以是day,month,year
-- 在指定日期上增加 4 天,结果为2021-11-05
select DATE_ADD('2021-11-01',INTERVAL 4 day);
-- 在指定日期上减少 1 个月,结果为 2021-10-01
select DATE_ADD('2021-11-01',INTERVAL -1 month);
日期函数的典型例子
现在有一个列表dateTest,里面的值是这样的

现在要求,同一周的数据的date都统一替换为 ‘2021-11-01~2021-11-07’ 的格式
解题思路:
-- 先确定哪几天是在同一周里面,利用日期的间隔除以7,第一周的值都为0,第二周的值都为1,以此类推
select DATEDIFF(date,'2021-11-01')/7 from dateTest;
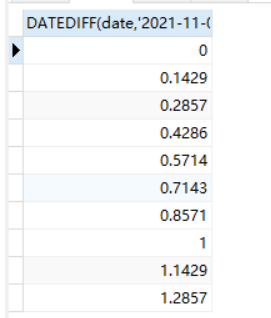
这样不方便使用,利用floor函数,取整
select FLOOR(DATEDIFF(date,'2021-11-01')/7) from dateTest;

格式里面要求的是每周的第一天与每周的最后一天之间用波浪线~连接
因此先求每周的第一天是什么,之前已经求出了每周的数字是多少,第一周的数字是0,第二周的数字是1,那么用这个数字乘上7,再加在第一周的第一天上,就可以得出每周的第一天为多少
-- 求每周的第一天
select DATE_ADD('2021-11-01',INTERVAL FLOOR(DATEDIFF(date,'2021-11-01')/7)*7 DAY) from dateTest;

然后是求每周的最后一天,既然已经知道了每周的第一天,那么加6天就是最后一天
-- 求每周的最后一天
select DATE_ADD('2021-11-01',INTERVAL FLOOR(DATEDIFF(date,'2021-11-01')/7)*7+6 DAY) from dateTest;

最后利用concat函数将第一天与最后一天连接起来
-- 合并为一周
select CONCAT(DATE_ADD('2021-11-01',INTERVAL FLOOR(DATEDIFF(date,'2021-11-01')/7)*7 DAY),
"~",
DATE_ADD('2021-11-01',INTERVAL FLOOR(DATEDIFF(date,'2021-11-01')/7)*7+6 DAY)),num from dateTest;

topn
先来看一下原先的数据集 select * from stu1;

现在希望分别求出男女中年龄最小的前三条数据
select * from stu1 as s1 where 3>
(select count(*) from stu1 as s2 where s1.sex=s2.sex and s1.age>s2.age)
order by sex;
分析一下这个代码
首先这个sql语句将stu1与其自身连接,即用了两张一样的表,都是stu1表,分别取了一个别名,s1和s2
先分组 s1.sex=s2.sex 后比较 s1.age > s2.age
where s1.sex=s2.sex 语句的作用是将表s1和s2中sex值相同的部分提出来连接,也就是sex为0时的两张表进行连接,然后sex为1时又另外进行连接,即达成下图这样的效果

s1.age > s2.age 语句的作用很特殊,返回的值是一串内容为 Yes 和 No 的字串
单看sex=0的情况(左边的表是s1,右边的表是s2)

首先是表s1中的第一条数据 ’zhang‘ 的age值12 与 表s2中的每一条数据的age值进行对比
如果s1,age > s2.age 那么给出一个 yes,否则给出一个 no,一共有四条sex为0的数据,因此返回的yes与no一共有四个。这里s1第一行age值12 的比较结果是 n 、n、n、n(将yes简写为y,no简写为n),都为n说明12不大于右边的任何一个age值,小于或等于都是n
然后比较表s1中的第二条数据的age值21,依旧是与s2表中的每一条数据的age值依次对比,比较结果是 y、n、y、n ,大于第一个age值12,不大于第二个age值21,以此类推
接着s1的第三条数据的age值18,与s2每条数据的age值比较,结果为 y、n、n、n
最后是s1的第四条数据的age值22,与s2每条数据的age值比较,结果为y、y、y、n
select count(*) 分析完s1.age > s2.age语句后,再回过来看count(*),这里的count是统计表s1每条数据的比较结果中,y的数量,从小到大进行排列
s1.age = 12 —— n 、n、n、n —— 0
s1.age = 18 —— y 、n、n、n —— 1
s1.age = 21 —— y 、n、y、n —— 2
s1.age = 22 —— y 、y、y、n —— 3
因此从小到大排列是12,18,21,22,只取前三条就是12,18,21
where 3>() 这里是限制了前三条数据
order by sex 是最终结果按sex进行排序
最后的结果为

按照sex进行分组后,里面又按照id的值进行了排序,因此是12,21,18的顺序
判断
if语句判断
格式为:if(判断条件,判断结果为true执行的语句,判断结果为false或null执行的语句)
例1:
select * from person1;
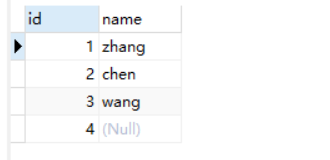
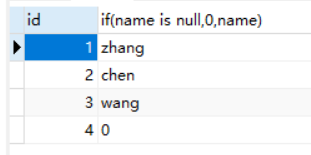
将第四行的空值替换为0
select id,if(name is null,0,name) as n from person1;

如果不加别名,列名就会显示完整的一条语句 select id,if(name is null,0,name) from person1;
条件判断 case
格式为:case when a then b else c end
当判断条件a为true时,显示b,否则显示c
例2:
select id,name,sex from student;

select id,name,case when sex='0' then '男' when sex='1' then '女' else '未知' end as s from student;
















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











