






【学习笔记】一些postgreSQL常用sql语句
- 1、序列自增id
- 2、将从一个表中查出来的数据插入到另一个表中
- 3、sql更新替换字段中某个字
- 4、统计一个字段多个值的次数
- 5、统计某个字段重复项:
- 6、用id标识删除重复字段
- 7、if not exists
- 8、数据库执行完update或者insert之后数据库体积增长
- 9、获取当前时间
- 10、将一个select结果作为另一个检索的条件
- 11、(树形结构)检索某一节点及其所有叶子结点
最近一直在做后端项目,接触了postgreSQL数据库以及需要处理很多零碎的sql语句,在这里做个总结。
1、序列自增id
postgre中自增id方式通过构建序列进行实现,序列名一般为表名_字段名_sql,创建序列通用语句如下:
create sequence [序列名] increment by 1 minvalue 1 no maxvalue start with 1;
例如:
create sequence t_users_id_seq increment by 1 minvalue 1 no maxvalue start with 1;
以上语句表示新建一个名为t_users_id_seq的序列,最小值为1,无最大值,并从1开始。
之后,在设计表中,对需要进行自增的字段中添加nextval('t_users_id_seq'::regclass),表示对该字段应用序列。
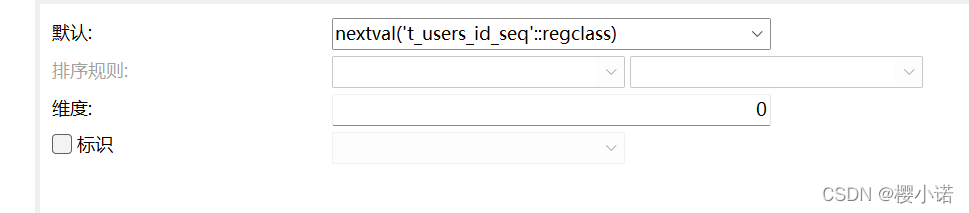
如果想要重置序列,使用alert语句:
alter sequence [序列名] restart with 1
例如:
alter sequence t_users_id_seq restart with 33
应用:
在项目中使用JDBC进行数据插入时,设置了自增id后不需要指定id值,自增序列会预先生成一个id主键再进行插入。需要获取插入的结果,通过Statement.RETURN_GENERATED_KEYS的方式返回主键id,并通过stmt.getGeneratedKeys拿到ResultSet。
PreparedStatement stmt = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
ResultSet rs = stmt.getGeneratedKeys();
2、将从一个表中查出来的数据插入到另一个表中
insert into "T_FeatureUpdate" select * from "T_FeatureModify" where state = 10
3、sql更新替换字段中某个字
update [表名] set [字段1] = REPLACE([字段1],[原值],[替换后的值])
其中原值为字段中现有的值。例如:字段word中值为生产作物,其中需要将作物一词替换为粮食作物,变为生产粮食作物,使用下面语句:
update my_table set word = REPLACE(word,'作物','粮食作物') where county = 'beijing'
如果需要模糊匹配,即字段1中存在xx值就进行替换,例子如下:
update my_table set word = REPLACE(word,'LQYD','林区用地')where word like '%LQYD%'
若将表中某一字段中的一个值完全替换为另一个值:
UPDATE my_table SET county = '北京市' WHERE county = 'beijing';
即:将county字段中的beijing替换为北京市;
4、统计一个字段多个值的次数
county字段中有多个值,想统计每个值出现的次数,用以下语句:
SELECT county as 县,COUNT(*) as 次数 FROM "my_table" GROUP BY county
5、统计某个字段重复项:
统计my_table中BSM字段为重复的记录:
select BSM,count(*) from "my_table" group by BSM having(count(*)) >1
6、用id标识删除重复字段
确保id为主键唯一且不重复,但是该方法删除之后id不连续了,对于除了id其他完全一样的记录,保留id大的那个;
delete from "my_table" where id in (select * from (select max(id) from "my_table" group by BSM having count(BSM) > 1) as b);
但是如果遇到完全相同的两条记录,没有id进行区分,则该方法会同时删除。
7、if not exists
当表中如果不存在某行数据,则插入;
INSERT [表名] ([字段1], [字段2], [字段3]) SELECT '值1', '值2', '值3' WHERE NOT EXISTS (SELECT * FROM [表名] WHERE [字段1] = '值1' AND [字段2] = '值2')
8、数据库执行完update或者insert之后数据库体积增长
排除中文字段储存大问题的以外,可能还有数据库内存不释放的原因。
解决方法:sqlite操作全部完成后,执行VACUUM命令。
9、获取当前时间
在sql 语句中,将字段类型为TIMESMAP的字段值设置为current_timestamp,例如:
INSERT INTO "my_table"(id,name,create_time) VALUES (1,'张三',current_timestamp)
同理,若为Date类型字段,值为current_date.
10、将一个select结果作为另一个检索的条件
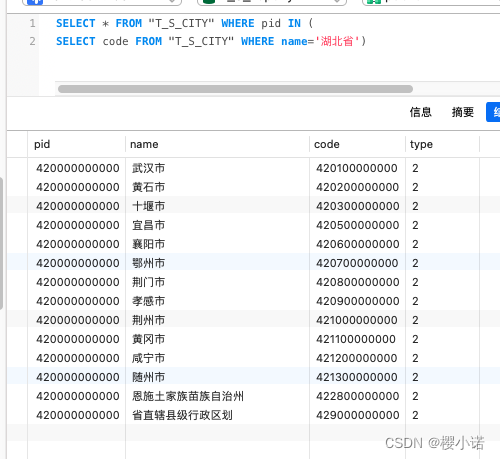
SELECT * FROM "T_S_CITY" WHERE pid IN (
SELECT code FROM "T_S_CITY" WHERE name='湖北省')
该语句将name为湖北省时检索出来的code值作为下一个查询pid值的条件,该语句适用于数据库树形结构,例如储存行政区划分级时。
数据库树形结构构建:

可用于实现Java中省市县镇村五级联动,使用postgreSQL数据库,结构格式为:
(1)pid字段:上级行政区划代码
(2)name字段:行政区名称;
(3)code:行政区代码;
(4)type字段:类型,其中1代表省级;2代表市级;3代表区县级;4代表乡镇或者街道;5代表村或者社区。
五级联动查询sql语句为:
SELECT * FROM "T_S_CITY" WHERE pid IN (
SELECT code FROM "T_S_CITY" WHERE pid IN (
SELECT code FROM "T_S_CITY" WHERE pid IN (
SELECT code FROM "T_S_CITY" WHERE pid IN (
SELECT code FROM "T_S_CITY" WHERE name= #{province})
and name = #{city})
and name = #{district})
and name = #{township})
and name = #{village}
11、(树形结构)检索某一节点及其所有叶子结点
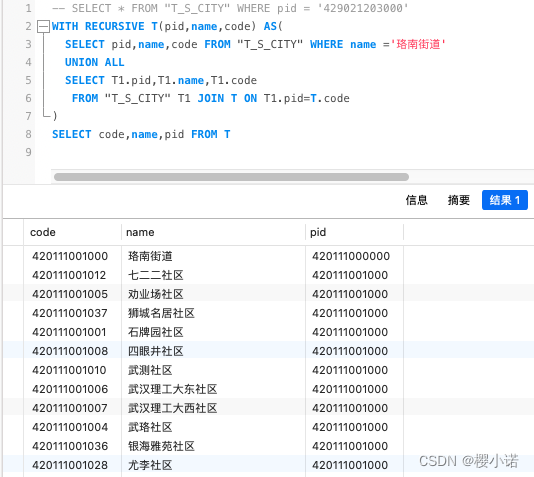
WITH RECURSIVE T(pid,name,code) AS(
SELECT pid,name,code FROM "T_S_CITY" WHERE name ='珞南街道'
UNION ALL
SELECT T1.pid,T1.name,T1.code
FROM "T_S_CITY" T1 JOIN T ON T1.pid=T.code
)
SELECT code,name,pid FROM T
检索结果:当该结点为根节点时候,会返回完整树结构


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









