







1、Callable&Future 接口
1.1、Callable 接口
目前我们学习了有两种创建线程的方法-一种是通过创建Thread类,另一种是 通过使用Runnable创建线程。但是,Runnable缺少的一项功能是,当线程 终止时(即run()完成时),我们无法使线程返回结果。为了支持此功能, Java中提供了Callable接口。
现在我们学习的是创建线程的第三种方案—Callable接口
Callable接口的特点如下:
(1)为了实现Runnable,需要实现不返回任何内容的run()方法,而对于 Callable,需要实现在完成时返回结果的call()方法。
(2)call()方法可以引发异常,而run()则不能。
(3) 为实现Callable而必须重写call方法
(4) 不能直接替换runnable,因为Thread类的构造方法根本没有Callable
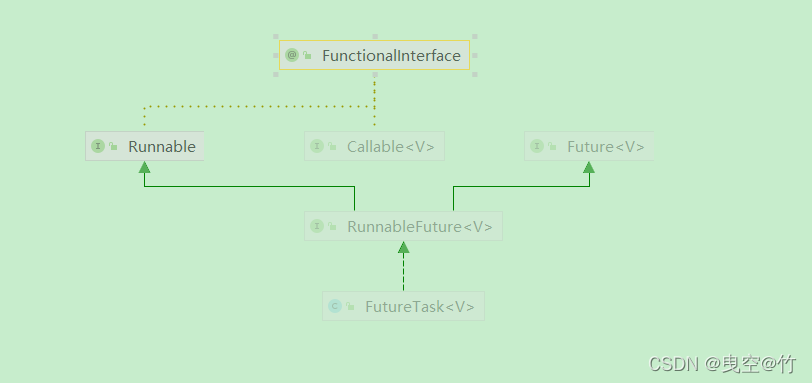
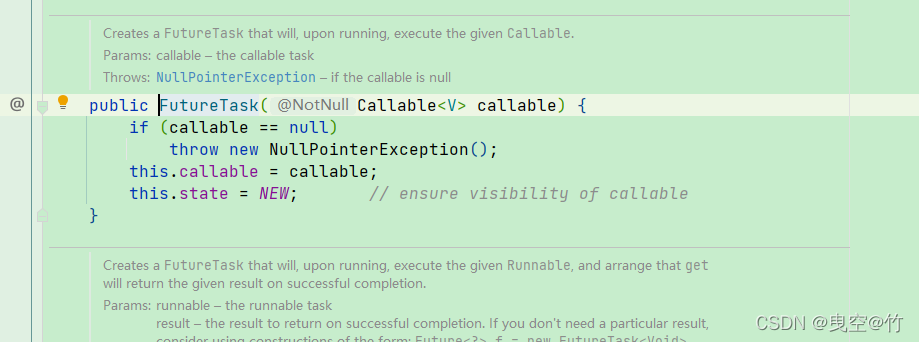
所以可以通过FutureTask来让Callable与new Thread产生联系,实现创建线程
package callable;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* @author Francis
* @create 2022-03-08 6:22
*/
public class MyThread {
public static void main(String[] args) throws ExecutionException, InterruptedException {
new Thread(new MyThread1(), "Runnable").start();
FutureTask<Integer> futureTask = new FutureTask<>(new MyThread2());
//lam表达式
FutureTask<Integer> lamTask = new FutureTask<>(() -> {
return 1024;
});
new Thread(futureTask, "Callable").start();
while (!futureTask.isDone()) {
System.out.println("wait");
}
System.out.println(futureTask.get());
//futureTask只会计算一次,后面调用直接返回结果
System.out.println(futureTask.get());
//new Thread(lamTask).start();
//System.out.println(lamTask.get());
}
}
/**
* 创建新类MyThread实现runnable接口
*/
class MyThread1 implements Runnable {
@Override
public void run() {
}
}
/**
* 新类MyThread2实现callable接口
*/
class MyThread2 implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return 200;
}
}
1.2、 Future 接口
当call()方法完成时,结果必须存储在主线程已知的对象中,以便主线程可 以知道该线程返回的结果。为此,可以使用Future对象。
将Future视为保存结果的对象–它可能暂时不保存结果,但将来会保存(一旦 Callable返回)。Future基本上是主线程可以跟踪进度以及其他线程的结果的 一种方式。要实现此接口,必须重写5种方法,这里列出了重要的方法,如下:
(1) public boolean cancel(boolean mayInterrupt):用于停止任务。
如果尚未启动,它将停止任务。如果已启动,则仅在mayInterrupt为true 时才会中断任务。
(2) public Object get()抛出InterruptedException,ExecutionException: 用于获取任务的结果。
==如果任务完成,它将立即返回结果,否则将等待任务完成,然后返回结果。 ==
(3)public boolean isDone():如果任务完成,则返回true,否则返回false
联系
可以看到Callable和Future做两件事-Callable与Runnable类似,因为它封装了要在另一个线程上运行的任务,而Future用于存储从另一个线程获得的结果。实际上,future也可以与Runnable一起使用。
要创建线程,需要Runnable。为了获得结果,需要future。
Java库具有具体的FutureTask类型,该类型实现Runnable和Future,并方 便地将两种功能组合在一起。 可以通过为其构造函数提供Callable来创建 FutureTask。然后,将FutureTask对象提供给Thread的构造函数以创建 Thread对象。因此,间接地使用Callable创建线程。
==核心原理:(重点) ==
在主线程中需要执行比较耗时的操作时,但又不想阻塞主线程时,可以把这些 作业交给Future对象在后台完成
(1) 当主线程将来需要时,就可以通过Future对象获得后台作业的计算结果或者执 行状态
(2) 一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去 获取结果。
(3) 仅在计算完成时才能检索结果;如果计算尚未完成,则阻塞 get 方法
(4)一旦计算完成,就不能再重新开始或取消计算
(5)get方法而获取结果只有在计算完成时获取,否则会一直阻塞直到任务转入完 成状态,然后会返回结果或者抛出异常
(6)get只计算一次,因此get方法放到最后
2、JUC 三大辅助类
JUC中提供了三种常用的辅助类,通过这些辅助类可以很好的解决线程数量过 多时Lock锁的频繁操作。这三种辅助类为:
(1) CountDownLatch: 减少计数
(2)CyclicBarrier: 循环栅栏
(3)Semaphore: 信号灯
2.1、减少计数 CountDownLatch
CountDownLatch类可以设置一个计数器,然后通过countDown方法来进行 减1的操作,使用await方法等待计数器不大于0,然后继续执行await方法 之后的语句。
(1)CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,这 些线程会阻塞
(2)其它线程调用countDown方法会将计数器减1(调用countDown方法的线程 不会阻塞)
(3) 当计数器的值变为0时,因await方法阻塞的线程会被唤醒,继续执行
package assist;
import java.util.concurrent.CountDownLatch;
/**
* @author Francis
* @create 2022-03-08 7:54
*/
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
//没有CountDownLatch的情况下,会导致子线程未全部结束,主线程就退出
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 0; i < 6; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"号同学走人了");
//让计数器减1
countDownLatch.countDown();
},String.valueOf(i)).start();
}
//计数器不等于0,一直等待,为0时执行之后的代码
countDownLatch.await();
System.out.println(Thread.currentThread().getName()+"班长锁门走人了");
}
}
2.2、 循环栅栏 CyclicBarrier
CyclicBarrier看英文单词可以看出大概就是循环阻塞的意思,在使用中 CyclicBarrier的构造方法第一个参数是目标障碍数,每次执行CyclicBarrier一 次障碍数会加一,如果达到了目标障碍数,才会执行cyclicBarrier.await()之后 的语句。可以将CyclicBarrier理解为加1操作
场景: 集齐7颗龙珠就可以召唤神龙
package assist;
import java.util.concurrent.CyclicBarrier;
/**
* @author Francis
* @create 2022-03-08 8:09
*/
public class CyclicBarrierDemo {
//定义神龙召唤需要的龙珠总数
private final static int NUMBER = 7;
/**
* 集齐7颗龙珠就可以召唤神龙
*
* @param args
*/
public static void main(String[] args) {
//定义循环栅栏
CyclicBarrier cyclicBarrier = new CyclicBarrier(NUMBER, () -> {
System.out.println("集齐" + NUMBER + "颗龙珠,现在召唤神龙!!!!!!!!!");
});
//定义7个线程分别去收集龙珠
for (int i = 1; i <= 7; i++) {
new Thread(() -> {
try {
if (Thread.currentThread().getName().equals("龙珠3号")) {
System.out.println("龙珠3号抢夺战开始,孙悟空开启超级赛亚人模式!");
Thread.sleep(5000);
System.out.println("龙珠3号抢夺战结束,孙悟空打赢了,拿到了龙珠3 号!");
} else {
System.out.println(Thread.currentThread().getName() + "收集到 了!!!!");
}
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
}, "龙珠" + i + "号").start();
}
System.out.println(Thread.currentThread().getName()+"结束");
}
}
2.3、信号灯 Semaphore
Semaphore的构造方法中传入的第一个参数是最大信号量(可以看成最大线 程池),每个信号量初始化为一个最多只能分发一个许可证。使用acquire方 法获得许可证,release方法释放许可
场景: 抢车位, 6部汽车3个停车位
package assist;
import java.util.concurrent.Semaphore;
/**
* @author Francis
* @create 2022-03-08 8:27
*/
public class SemaphoreDemo {
/**
* 抢车位, 10部汽车1个停车位
*
* @param args
*/
public static void main(String[] args) throws Exception {
//定义3个停车位
Semaphore semaphore = new Semaphore(3);
//模拟6辆汽车停车
for (int i = 1; i <= 6; i++) {
Thread.sleep(100);
//停车
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + "找车位ing");
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + "汽车停车成功!");
Thread.sleep(10000);
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + "溜了溜了");
semaphore.release();
}
}, "汽车" + i).start();
}
}
}
3、读写锁
3.1、读写锁介绍
现实中有这样一种场景:对共享资源有读和写的操作,且写操作没有读操作那 么频繁。在没有写操作的时候,多个线程同时读一个资源没有任何问题,所以 应该允许多个线程同时读取共享资源;但是如果一个线程想去写这些共享资源, 就不应该允许其他线程对该资源进行读和写的操作了。
针对这种场景,JAVA的并发包提供了读写锁ReentrantReadWriteLock, 它表示两个锁,一个是读操作相关的锁,称为共享锁;一个是写相关的锁,称 为排他锁
3.1.1、 线程进入读锁的前提条件:
(1) 没有其他线程的写锁
(2)没有写请求, 或者有写请求,但调用线程和持有锁的线程是同一个(可重入 锁)。
3.1.2、 线程进入写锁的前提条件:
(1)没有其他线程的读锁
(2)没有其他线程的写锁
3.1.3、读写锁有以下三个重要的特性:
(1)公平选择性:支持非公平(默认)和公平的锁获取方式,吞吐量还是非公 平优于公平。
(2)重进入:读锁和写锁都支持线程重进入。
(3)锁降级:遵循获取写锁、获取读锁再释放写锁的次序,写锁能够降级成为 读锁。
3.1.4、使用读写锁解决并发问题
不是用读写锁时存在的问题
package readwrite;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* @author Francis
* @create 2022-03-08 9:12
*/
public class ReadWriteLockDemo {
public static void main(String[] args) {
MyCache myCache = new MyCache();
for (int i = 0; i < 5; i++) {
final int num = i;
new Thread(() -> {
myCache.put(num + "", num + "");
}, num + "thread").start();
}
for (int i = 0; i < 5; i++) {
final int num = i;
new Thread(() -> {
Object o = myCache.get(num + "");
}, num + "thread").start();
}
}
}
class MyCache {
//创建map集合
private volatile Map<String, Object> map = new HashMap<>();
//放数据
public void put(String key, Object value) {
System.out.println(Thread.currentThread().getName() + "正在写操作" + key);
try {
TimeUnit.MICROSECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "写操作完成" + key);
}
public Object get(String key) {
System.out.println(Thread.currentThread().getName() + "正在读操作" + key);
try {
TimeUnit.MICROSECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
Object result = map.get(key);
System.out.println(Thread.currentThread().getName() + "已经读取完成" + result);
return result;
}
}
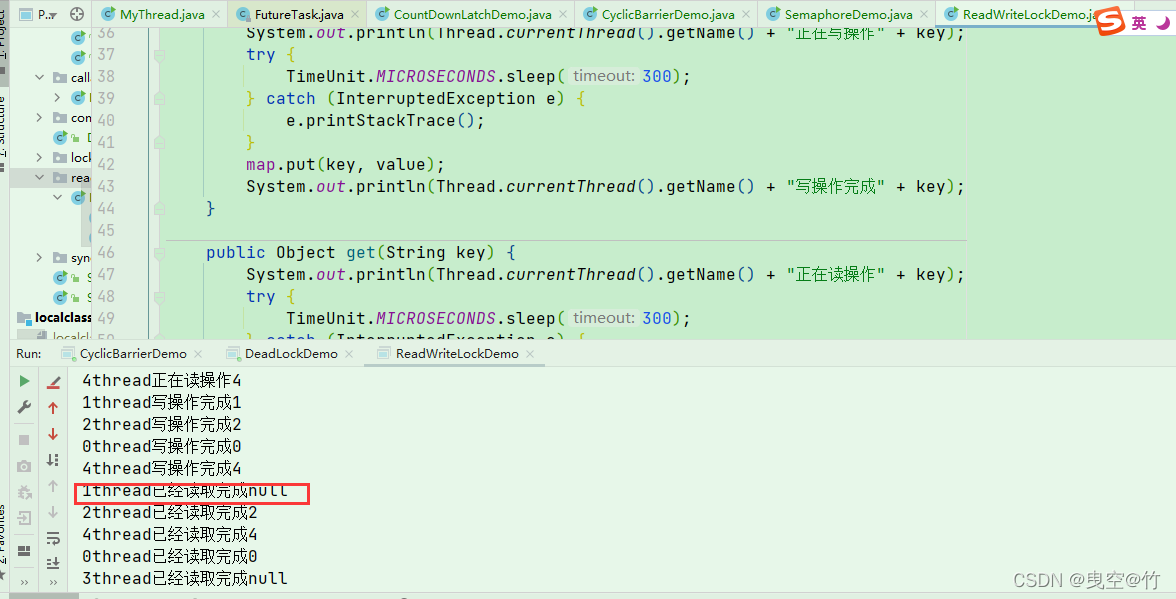
其中一个值还没有写完,其他线程就拥有了写的能力,然后进行读取没有写完的值,就为空
使用读写锁
package readwrite;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* @author Francis
* @create 2022-03-08 9:12
*/
public class ReadWriteLockDemo {
public static void main(String[] args) {
MyCache myCache = new MyCache();
for (int i = 0; i < 5; i++) {
final int num = i;
new Thread(() -> {
myCache.put(num + "", num + "");
}, num + "thread").start();
}
for (int i = 0; i < 5; i++) {
final int num = i;
new Thread(() -> {
Object o = myCache.get(num + "");
}, num + "thread").start();
}
}
}
class MyCache {
//创建map集合
private volatile Map<String, Object> map = new HashMap<>();
// 创 建 读写锁对 象
private ReadWriteLock rwLock = new ReentrantReadWriteLock();
//放数据
public void put(String key, Object value) {
rwLock.writeLock().lock();
System.out.println(Thread.currentThread().getName() + "正在写操作" + key);
try {
TimeUnit.MICROSECONDS.sleep(300);
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "写操作完成" + key);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 释 放 写锁
rwLock.writeLock().unlock();
}
}
public Object get(String key) {
// 添加 读锁
rwLock.readLock().lock();
Object result=null;
System.out.println(Thread.currentThread().getName() + "正在读操作" + key);
try {
TimeUnit.MICROSECONDS.sleep(300);
result = map.get(key);
System.out.println(Thread.currentThread().getName() + "已经读取完成" + result);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 释 放 读锁
rwLock.readLock().unlock();
}
return result;
}
}
只有拥有锁的线程写完了,其他线程才可以获取锁
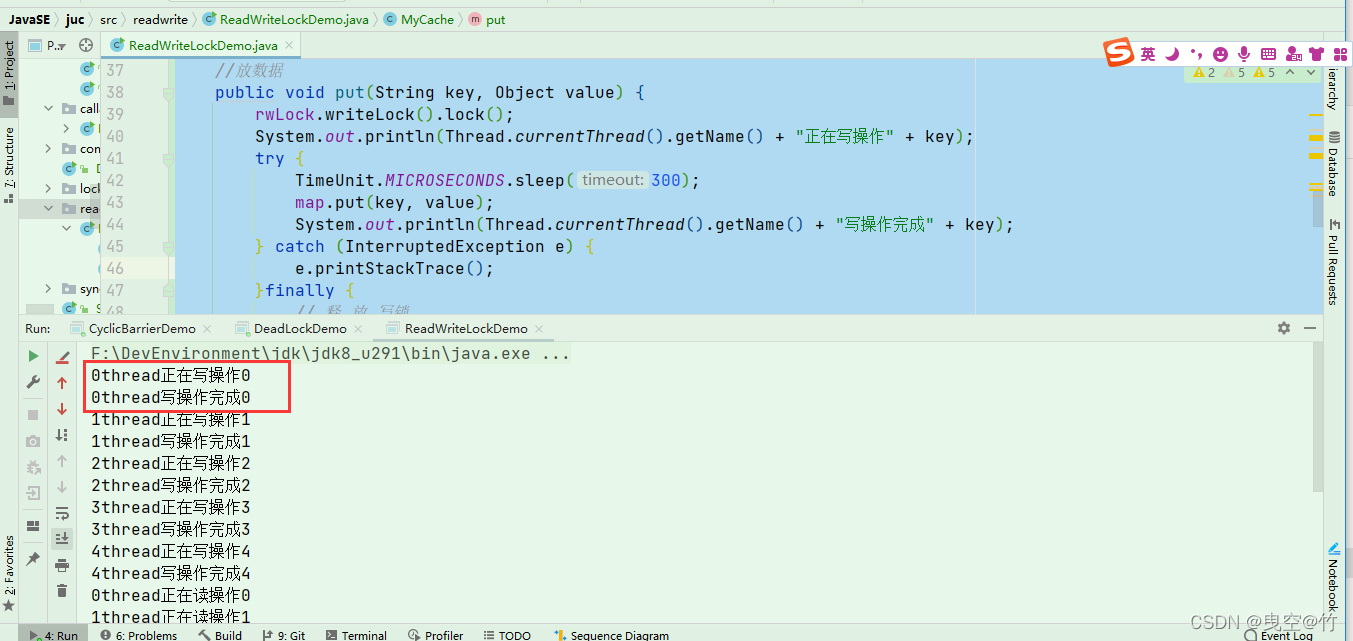
4、阻塞队列
4.1、BlockingQueue 简介
Concurrent包中,BlockingQueue很好的解决了多线程中,如何高效安全 “传输”数据的问题。通过这些高效并且线程安全的队列类,为我们快速搭建 高质量的多线程程序带来极大的便利。本文详细介绍了BlockingQueue 家庭 中的所有成员,包括他们各自的功能以及常见使用场景。
阻塞队列,顾名思义,首先它是一个队列, 通过一个共享的队列,可以使得数据由队列的一端输入,从另外一端输出;
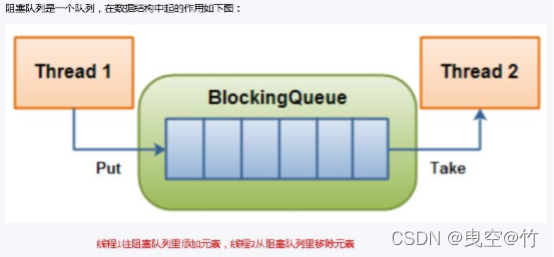
当队列是空的,从队列中获取元素的操作将会被阻塞
当队列是满的,从队列中添加元素的操作将会被阻塞
试图从空的队列中获取元素的线程将会被阻塞,直到其他线程往空的队列插入新的元素
试图向已满的队列中添加新元素的线程将会被阻塞,直到其他线程从队列中移除一个或多 个元素或者完全清空,使队列变得空闲起来并后续新增
常用的队列主要有以下两种:
(1) 先进先出(FIFO):先插入的队列的元素也最先出队列,类似于排队的功能。 从某种程度上来说这种队列也体现了一种公平性
(2) 后进先出(LIFO):后插入队列的元素最先出队列,这种队列优先处理最近发生的事件(栈)
在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起 的线程又会自动被唤起
为什么需要BlockingQueue
好处是我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切 BlockingQueue都给你一手包办了
在concurrent包发布以前,在多线程环境下,我们每个程序员都必须去自己控制这些细 节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。
多线程环境中,通过队列可以很容易实现数据共享,比如经典的“生产者”和 “消费者”模型中,通过队列可以很便利地实现两者之间的数据共享。假设我 们有若干生产者线程,另外又有若干个消费者线程。如果生产者线程需要把准 备好的数据共享给消费者线程,利用队列的方式来传递数据,就可以很方便地 解决他们之间的数据共享问题。但如果生产者和消费者在某个时间段内,万一 发生数据处理速度不匹配的情况呢?理想情况下,如果生产者产出数据的速度 大于消费者消费的速度,并且当生产出来的数据累积到一定程度的时候,那么 生产者必须暂停等待一下(阻塞生产者线程),以便等待消费者线程把累积的 数据处理完毕,反之亦然。
(1)当队列中没有数据的情况下,消费者端的所有线程都会被自动阻塞(挂起), 直到有数据放入队列
(2)当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起), 直到队列中有空的位置,线程被自动唤醒
4.2、 BlockingQueue 核心方法
4.2.1、放入数据
(1)offer(anObject):表示如果可能的话,将an Object加到BlockingQueue 里,即 如果BlockingQueue可以容纳,则返回true,否则返回false.(本方法不阻塞当 前执行方法的线程)
(2)offer(E o, long timeout, TimeUnit unit):可以设定等待的时间,如果在指定 的时间内,还不能往队列中加入BlockingQueue,则返回失败
(3) put(an Object):把an Object加到BlockingQueue 里,如果BlockQueue没有 空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
4.2.2、获取数据
(1) poll(time): 取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等 time参数规定的时间,取不到时返回null
(2) poll(long timeout, TimeUnit unit):从BlockingQueue取出一个队首的对象, 如果在指定时间内,队列一旦有数据可取,则立即返回队列中的数据。否则直到时间超时还没有数据可取,返回失败。
(3) take(): 取走BlockingQueue 里排在首位的对象,若BlockingQueue为空,阻断 进入等待状态直到BlockingQueue有新的数据被加入;
(4) drainTo(): 一次性从BlockingQueue获取所有可用的数据对象(还可以指定 获取数据的个数),通过该方法,可以提升获取数据效率;不需要多次分批加 锁或释放锁。
package queue;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Francis
* @create 2022-03-08 11:18
*/
public class BlockingQueueDemo {
public static void main(String[] args) throws InterruptedException {
// List list = new ArrayList();
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(3);
//第一组
// System.out.println(blockingQueue.add("a"));
// System.out.println(blockingQueue.add("b"));
// System.out.println(blockingQueue.add("c"));
// System.out.println(blockingQueue.element());
//System.out.println(blockingQueue.add("x"));
// System.out.println(blockingQueue.remove());
// System.out.println(blockingQueue.remove());
// System.out.println(blockingQueue.remove());
// System.out.println(blockingQueue.remove());
// 第二组
// System.out.println(blockingQueue.offer("a"));
// System.out.println(blockingQueue.offer("b"));
// System.out.println(blockingQueue.offer("c"));
// System.out.println(blockingQueue.offer("x"));
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
// 第三组
// blockingQueue.put("a");
// blockingQueue.put("b");
// blockingQueue.put("c");
// blockingQueue.put("x");
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take());
// 第四组
System.out.println(blockingQueue.offer("a"));
System.out.println(blockingQueue.offer("b"));
System.out.println(blockingQueue.offer("c"));
System.out.println(blockingQueue.offer("a",3L, TimeUnit.SECONDS));
}
}
4.3、常见的 BlockingQueue
4.3.1、ArrayBlockingQueue(常用)
基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数 组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数 组外,ArrayBlockingQueue 内部还保存着两个整形变量,分别标识着队列的 头部和尾部在数组中的位置。
ArrayBlockingQueue在生产者放入数据和消费者获取数据,都是共用同一个 锁对象,由此也意味着两者无法真正并行运行,这点尤其不同于 LinkedBlockingQueue;按照实现原理来分析,ArrayBlockingQueue 完全可 以采用分离锁,从而实现生产者和消费者操作的完全并行运行。Doug Lea之 所以没这样去做,也许是因为ArrayBlockingQueue的数据写入和获取操作已 经足够轻巧,以至于引入独立的锁机制,除了给代码带来额外的复杂性外,其 在性能上完全占不到任何便宜。 ArrayBlockingQueue和 LinkedBlockingQueue 间还有一个明显的不同之处在于,前者在插入或删除 元素时不会产生或销毁任何额外的对象实例,而后者则会生成一个额外的 Node对象。这在长时间内需要高效并发地处理大批量数据的系统中,其对于 GC的影响还是存在一定的区别。而在创建ArrayBlockingQueue时,我们还 可以控制对象的内部锁是否采用公平锁,默认采用非公平锁。
一句话总结: 由数组结构组成的有界阻塞队列。
4.3.2、 LinkedBlockingQueue(常用)
基于链表的阻塞队列,同ArrayListBlockingQueue 类似,其内部也维持着一 个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据 时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回; 只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过 构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。 而LinkedBlockingQueue 之所以能够高效的处理并发数据,还因为其对于生 产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发 的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列 的并发性能。
ArrayBlockingQueue和LinkedBlockingQueue是两个最普通也是最常用 的阻塞队列,一般情况下,在处理多线程间的生产者消费者问题,使用这两个 类足矣。
一句话总结: 由链表结构组成的有界(但大小默认值为 integer.MAX_VALUE)阻塞队列。
4.3.3、 DelayQueue
DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取到 该元素。DelayQueue是一个没有大小限制的队列,因此往队列中插入数据的 操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻 塞。
一句话总结: 使用优先级队列实现的延迟无界阻塞队列。
4.3.4、 PriorityBlockingQueue
基于优先级的阻塞队列(优先级的判断通过构造函数传入的Compator对象来 决定),但需要注意的是PriorityBlockingQueue并不会阻塞数据生产者,而 只会在没有可消费的数据时,阻塞数据的消费者。 因此使用的时候要特别注意,生产者生产数据的速度绝对不能快于消费者消费 数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。 在实现PriorityBlockingQueue 时,内部控制线程同步的锁采用的是公平锁。
一句话总结: 支持优先级排序的无界阻塞队列。
4.3.5、 SynchronousQueue
一种无缓冲的等待队列,类似于无中介的直接交易,有点像原始社会中的生产 者和消费者,生产者拿着产品去集市销售给产品的最终消费者,而消费者必须 亲自去集市找到所要商品的直接生产者,如果一方没有找到合适的目标,那么 对不起,大家都在集市等待。相对于有缓冲的BlockingQueue来说,少了一 个中间经销商的环节(缓冲区),如果有经销商,生产者直接把产品批发给经 销商,而无需在意经销商最终会将这些产品卖给那些消费者,由于经销商可以 库存一部分商品,因此相对于直接交易模式,总体来说采用中间经销商的模式 会吞吐量高一些(可以批量买卖);但另一方面,又因为经销商的引入,使得 产品从生产者到消费者中间增加了额外的交易环节,单个产品的及时响应性能 可能会降低。
声明一个SynchronousQueue 有两种不同的方式,它们之间有着不太一样的 行为。
==公平模式和非公平模式的区别: ==
• 公平模式:SynchronousQueue 会采用公平锁,并配合一个FIFO队列来阻塞 多余的生产者和消费者,从而体系整体的公平策略;
• 非公平模式(SynchronousQueue 默认):SynchronousQueue采用非公平 锁,同时配合一个LIFO队列来管理多余的生产者和消费者,而后一种模式, 如果生产者和消费者的处理速度有差距,则很容易出现饥渴的情况,即可能有 某些生产者或者是消费者的数据永远都得不到处理。
一句话总结: 不存储元素的阻塞队列,也即单个元素的队列。
4.3.6、 LinkedTransferQueue
LinkedTransferQueue 是一个由链表结构组成的无界阻塞TransferQueue队 列。相对于其他阻塞队列,LinkedTransferQueue 多了tryTransfer和 transfer方法。
LinkedTransferQueue 采用一种预占模式。意思就是消费者线程取元素时,如 果队列不为空,则直接取走数据,若队列为空,那就生成一个节点(节点元素 为null)入队,然后消费者线程被等待在这个节点上,后面生产者线程入队时 发现有一个元素为null的节点,生产者线程就不入队了,直接就将元素填充到该节点,并唤醒该节点等待的线程,被唤醒的消费者线程取走元素,从调用的 方法返回。
一句话总结: 由链表组成的无界阻塞队列。
4.3.7、 LinkedBlockingDeque
LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列,即可以从队 列的两端插入和移除元素。
对于一些指定的操作,在插入或者获取队列元素时如果队列状态不允许该操作 可能会阻塞住该线程直到队列状态变更为允许操作,这里的阻塞一般有两种情 况
• 插入元素时: 如果当前队列已满将会进入阻塞状态,一直等到队列有空的位置时 再讲该元素插入,该操作可以通过设置超时参数,超时后返回 false 表示操作 失败,也可以不设置超时参数一直阻塞,中断后抛出InterruptedException异 常
• 读取元素时: 如果当前队列为空会阻塞住直到队列不为空然后返回元素,同样可 以通过设置超时参数
一句话总结: 由链表组成的双向阻塞队列
4.3.8、 小结
(1) 在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件 满足,被挂起的线程又会自动被唤起
(2)为什么需要BlockingQueue? 在concurrent包发布以前,在多线程环境下, 我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全, 而这会给我们的程序带来不小的复杂度。使用后我们不需要关心什么时候需要 阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue都给你一手 包办了
5、ThreadPool 线程池
5.1、线程池简介
线程池(英语:thread pool):一种线程使用模式。线程过多会带来调度开销, 进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理 者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代 价。线程池不仅能够保证内核的充分利用,还能防止过分调度。
例子: 10年前单核CPU电脑,假的多线程,像马戏团小丑玩多个球,CPU需 要来回切换。 现在是多核电脑,多个线程各自跑在独立的CPU上,不用切换 效率高。
线程池的优势: 线程池做的工作只要是控制运行的线程数量,处理过程中将任 务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量, 超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
==它的主要特点为: ==
(1)降低资源消耗: 通过重复利用已创建的线程降低线程创建和销毁造成的销耗。
(2) 提高响应速度: 当任务到达时,任务可以不需要等待线程创建就能立即执行。
(3)提高线程的可管理性: 线程是稀缺资源,如果无限制的创建,不仅会销耗系统资 源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
(4)Java 中的线程池是通过 Executor 框架实现的,该框架中用到了 Executor,Executors, ExecutorService,ThreadPoolExecutor这几个类 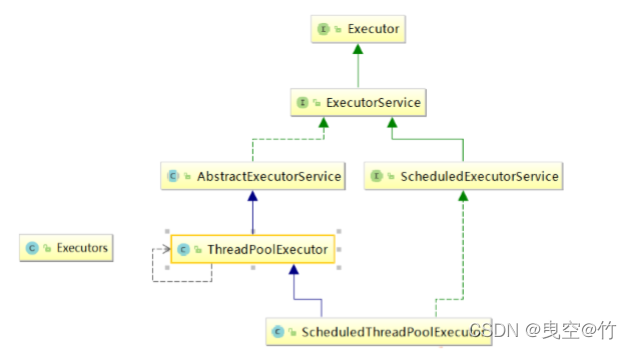
5.2、线程池参数说明
5.2.1、常用参数(重点)
(1)corePoolSize线程池的核心线程数
(2)maximumPoolSize能容纳的最大线程数
(3) keepAliveTime空闲线程存活时间
(4)unit 存活的时间单位
(5)workQueue 存放提交但未执行任务的队列
(6) threadFactory 创建线程的工厂类
(7) handler 等待队列满后的拒绝策略
线程池中,有三个重要的参数,决定影响了拒绝策略:corePoolSize - 核心线 程数,也即最小的线程数。workQueue - 阻塞队列 。 maximumPoolSize - 最大线程数 当提交任务数大于 corePoolSize 的时候,会优先将任务放到 workQueue 阻 塞队列中。当阻塞队列饱和后,会扩充线程池中线程数,直到达到 maximumPoolSize 最大线程数配置。此时,再多余的任务,则会触发线程池 的拒绝策略了。
==总结起来,也就是一句话,当提交的任务数大于(workQueue.size() + maximumPoolSize ),就会触发线程池的拒绝策略。 ==
5.2.2、拒绝策略(重点)
CallerRunsPolicy: 当触发拒绝策略,只要线程池没有关闭的话,则使用调用 线程直接运行任务。一般并发比较小,性能要求不高,不允许失败。但是,由 于调用者自己运行任务,如果任务提交速度过快,可能导致程序阻塞,性能效 率上必然的损失较大
==AbortPolicy: ==丢弃任务,并抛出拒绝执行 RejectedExecutionException 异常 信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执 行流程,影响后续的任务执行。
==DiscardPolicy: ==直接丢弃,其他啥都没有
DiscardOldestPolicy: 当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞 队列 workQueue 中最老的一个任务,并将新任务加入
5.2.3、 线程池的种类与创建 (Executors工具类的方法)
5.2.3.1、newCachedThreadPool(常用)
作用:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空 闲线程,若无可回收,则新建线程.
特点:
(1)线程池中数量没有固定,可达到最大(Interger.MAX_VALUE)
(2) 线程池中的线程可进行缓存重复利用和回收(回收默认时间为1分钟)
(3)当线程池中,没有可用线程,会重新创建一个线程
场景: 适用于创建一个可无限扩大的线程池,服务器负载压力较轻,执行时间较 短,任务多的场景
5.2.3.2、 newFixedThreadPool(常用)
作用:创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这 些线程。在任意点,在大多数线程会处于处理任务的活动状态。如果在所有线 程处于活动状态时提交附加任务,则在有可用线程之前,附加任务将在队列中 等待。如果在关闭前的执行期间由于失败而导致任何线程终止,那么一个新线 程将代替它执行后续的任务(如果需要)。在某个线程被显式地关闭之前,池 中的线程将一直存在。
特征:
(1)线程池中的线程处于一定的量,可以很好的控制线程的并发量 (2)线程可以重复被使用,在显示关闭之前,都将一直存在
(3)超出一定量的线程被提交时候需在队列中等待
场景: 适用于可以预测线程数量的业务中,或者服务器负载较重,对线程数有严 格限制的场景
package pool;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @author Francis
* @create 2022-03-08 14:44
*/
public class ThreadPoolDemo01 {
public static void main(String[] args) {
ExecutorService threadPool1 = Executors.newFixedThreadPool(5);
try {
for (int i = 0; i < 10; i++) {
threadPool1.execute(() -> {
System.out.println(Thread.currentThread().getName() + "办理业务");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool1.shutdown();
}
}
}
5.2.3.3、 newSingleThreadExecutor(常用)
作用:创建一个使用单个 worker 线程的 Executor,以无界队列方式来运行该 线程。(注意,如果因为在关闭前的执行期间出现失败而终止了此单个线程, 那么如果需要,一个新线程将代替它执行后续的任务)。可保证顺序地执行各 个任务,并且在任意给定的时间不会有多个线程是活动的。与其他等效的 newFixedThreadPool不同,可保证无需重新配置此方法所返回的执行程序即 可使用其他的线程。
特征: 线程池中最多执行1个线程,之后提交的线程活动将会排在队列中以此 执行
场景: 适用于需要保证顺序执行各个任务,并且在任意时间点,不会同时有多个 线程的场景
5.2.3.4、newScheduleThreadPool(了解)
作用: 线程池支持定时以及周期性执行任务,创建一个corePoolSize为传入参 数,最大线程数为整形的最大数的线程池**
特征:
(1)线程池中具有指定数量的线程,即便是空线程也将保留 (2)可定时或者 延迟执行线程活动
场景: 适用于需要多个后台线程执行周期任务的场景
5.2.3.5、newWorkStealingPool
jdk1.8提供的线程池,底层使用的是ForkJoinPool实现,创建一个拥有多个 任务队列的线程池,可以减少连接数,创建当前可用cpu核数的线程来并行执 行任务
场景: 适用于大耗时,可并行执行的场景
5.3、线程池底层工作原理(重要)
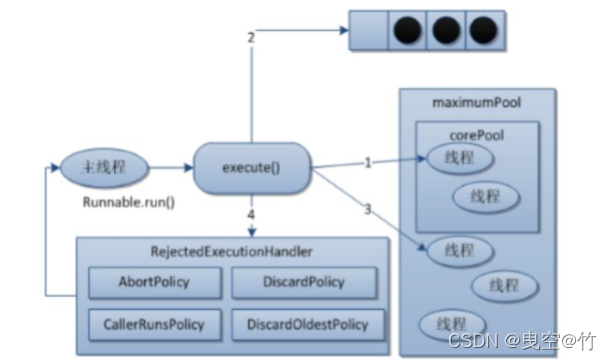
- 在创建了线程池后,线程池中的线程数为零
- 当调用execute()方法添加一个请求任务时,线程池会做出如下判断:
2.1 如 果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
2.2 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入 队列;
2.3 如果这个时候队列满了且正在运行的线程数量还小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
2.4 如 果队列满了且正在运行的线程数量大于或等于maximumPoolSize,那么线程 池会启动饱和拒绝策略来执行。 - 当一个线程完成任务时,它会从队列中取下一个任务来执行
- 当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
4.1 如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。
4.2 所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小。

5.4、注意事项(重要)
- 项目中创建多线程时,使用常见的三种线程池创建方式,单一、可变、定长都 有一定问题,原因是FixedThreadPool和SingleThreadExecutor底层都是用 LinkedBlockingQueue 实现的,这个队列最大长度为Integer.MAX_VALUE, 容易导致OOM。所以实际生产一般自己通过ThreadPoolExecutor的7个参 数,自定义线程池
- 创建线程池推荐适用ThreadPoolExecutor及其7个参数手动创建 o corePoolSize线程池的核心线程数 o maximumPoolSize能容纳的最大线程数 o keepAliveTime空闲线程存活时间 o unit 存活的时间单位 o workQueue 存放提交但未执行任务的队列 o threadFactory 创建线程的工厂类 o handler 等待队列满后的拒绝策略
- 为什么不允许适用不允许Executors.的方式手动创建线程池,如下图

package pool;
import java.util.concurrent.*;
/**
* @author Francis
* @create 2022-03-08 16:03
*/
public class ThreadPoolDemo02 {
public static void main(String[] args) {
ExecutorService threadPoolExecutor = new ThreadPoolExecutor(2,
5,
2L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
try {
for (int i = 0; i < 8; i++) {
threadPoolExecutor.execute(() -> {
System.out.println(Thread.currentThread().getName() + "完成体检");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}
}
6、Fork/Join
6.1、 Fork/Join框架简介
Fork/Join它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子 任务结果合并成最后的计算结果,并进行输出。Fork/Join框架要完成两件事 情:
Fork:把一个复杂任务进行分拆,大事化小
Join:把分拆任务的结果进行合并

- 任务分割:首先Fork/Join框架需要把大的任务分割成足够小的子任务,如果 子任务比较大的话还要对子任务进行继续分割
- 执行任务并合并结果:分割的子任务分别放到双端队列里,然后几个启动线程 分别从双端队列里获取任务执行。子任务执行完的结果都放在另外一个队列里, 启动一个线程从队列里取数据,然后合并这些数据。
在Java的Fork/Join框架中,使用两个类完成上述操作
• ForkJoinTask:我们要使用 Fork/Join 框架,首先需要创建一个 ForkJoin 任务。 该类提供了在任务中执行fork和join的机制。通常情况下我们不需要直接集 成ForkJoinTask类,只需要继承它的子类,Fork/Join框架提供了两个子类:
a.RecursiveAction:用于没有返回结果的任务
b.RecursiveTask:用于有返回结果的任务
• ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行 • RecursiveTask: 继承后可以实现递归(自己调自己)调用的任务
Fork/Join框架的实现原理
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成, ForkJoinTask数组负责将存放以及将程序提交给ForkJoinPool,而 ForkJoinWorkerThread负责执行这些任务。
6.2、Fork方法的实现原理:
当我们调用ForkJoinTask的fork方法时,程序会把 任务放在ForkJoinWorkerThread的pushTask的workQueue中,异步地 执行这个任务,然后立即返回结果
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ((ForkJoinWorkerThread)t).workQueue.push(this);
else ForkJoinPool.common.externalPush(this);
return this; }
pushTask方法把当前任务存放在ForkJoinTask数组队列里。然后再调用 ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行任务。代 码如下:
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) {
// ignore if queue removed
int m = a.length - 1;
// fenced write for task visibility
U.putOrderedObject(a,
((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this);//执行
}
else if (n >= m) growArray(); }
}
6.3、 join方法
在doJoin()方法流程如下:
- 首先通过查看任务的状态,看任务是否已经执行完成,如果执行完成,则直接 返回任务状态;
- 如果没有执行完,则从任务数组里取出任务并执行。
- 如果任务顺利执行完成,则设置任务状态为NORMAL,如果出现异常,则记 录异常,并将任务状态设置为EXCEPTIONAL。
6.4、Fork/Join框架的异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接 捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查 任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的 getException方法获取异常。
getException方法返回Throwable对象,如果任务被取消了则返回 CancellationException。如果任务没有完成或者没有抛出异常则返回null
6.5、入门案例
场景: 生成一个计算任务,计算1+2+3…+1000,每100个数切分一个 子任务
package forkjoin;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
/**
* @author Francis
* @create 2022-03-09 7:55
*/
public class ForkJoinDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建MyTask对象
MyTask myTask = new MyTask(0, 100);
//创建合并分支池对象
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> submit = forkJoinPool.submit(myTask);
Integer result = submit.get();
System.out.println(result);
//关闭池对象
forkJoinPool.shutdown();
}
}
class MyTask extends RecursiveTask<Integer> {
//拆分值不能超过10
private static final Integer VALUE = 10;
//拆分开始值
private int begin;
//拆分结束值
private int end;
//合并结果
private int result;
public MyTask(int begin,int end){
this.begin=begin;
this.end= end;
}
//拆分合并过程
@Override
protected Integer compute() {
if ((end-begin)<=VALUE){
for (int i =begin;i<=end;i++) {
result=result+i;
}
}else{//进一步拆分
//获取中间值
int middle= (begin+end)/2;
//拆分左边
MyTask myTaskLeft = new MyTask(begin, middle);
MyTask myTaskRight = new MyTask(middle+1, end);
//调用拆分方法
myTaskLeft.fork();
myTaskRight.fork();
//合并结果
result= myTaskLeft.join()+ myTaskRight.join();
}
return result;
}
}
7、异步调用 CompletableFuture
7.1、CompletableFuture简介
CompletableFuture在Java里面被用于异步编程,异步通常意味着非阻塞, 可以使得我们的任务单独运行在与主线程分离的其他线程中,并且通过回调可 以在主线程中得到异步任务的执行状态,是否完成,和是否异常等信息。
CompletableFuture实现了Future, CompletionStage接口,实现了Future 接口就可以兼容现在有线程池框架,而CompletionStage接口才是异步编程 的接口抽象,里面定义多种异步方法,通过这两者集合,从而打造出了强大的 CompletableFuture类。
7.2、 使用CompletableFuture
package completable;
import java.util.concurrent.CompletableFuture;
/**
* @author Francis
* @create 2022-03-09 8:29
*/
public class CompletableFutureDemo {
public static void main (String[] args) throws Exception{
//异步调用,没有返回值
CompletableFuture<Void> completableFuture1 =
CompletableFuture.runAsync(()->{
System.out.println(Thread.currentThread().getName()+
"没有返回值的异步调用");
});
completableFuture1.get();
//有返回值的异步调用
CompletableFuture<Integer> completableFuture12=
CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName()+
"有返回值的异步调用");
return 1024;
});
//t是返回值,u是异常
completableFuture12.whenComplete((t,u)->{
System.out.println("----t----"+t);
System.out.println("----u----"+u);
}).get();
}
}














 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









