







5.6 指针数组及指向指针的指针
3.5 while循环和for循环 —— 插入排序insertionSort函数
3.5 while循环和for循环 —— 希尔排序shellsort函数
对可变长度文本行数据排序后按次序打印。
程序分为三个部分:
(1)读取所有输入行
(2)对文本进行排序
(3)按次序打印文本行
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 /*进行排序的最大文本行数。超过限定的最大行数时,返回-1*/
char* lineptr[MAXLINES]; /* 指向文本行的指针数组。
每行的行换行符被替换为结束符后,变成字符串常量,被保存在指针数组lineptr的每个元素中。
每个字符串都是一个不可分割的整体,且在程序中,每个都生成“指向字符串的常量指针”。
该声明写在函数外面并且是最前面,main函数与readlines函数中都使用了该变量,为外部变量(又称全局变量),在各函数源文件中共享。 */
int readlines(char* lineptr[], int maxlines); /*输入函数,收集和保存每个文本行中的字符,统计输入的行数*/
void qsort(char* a[], int low, int high);
void writelines(char* lineptr[], int nlines); /*输出函数,按照指针数组中的次序依次打印这些文本行即可*/
int main()
{
int nlines;
if ((nlines = readlines(lineptr, MAXLINES)) >= 0)
{
qsort(lineptr, 0, nlines - 1);
writelines(lineptr, nlines);
return 0;
}
else //函数readlines的返回值是-1,小于0
{
printf("error: input too big to sort\n");
return 1;
}
}
//main函数版本2,在排序前重新写入
int main()
{
int nlines;
int i,j;
if ((nlines = readlines(lineptr, MAXLINES)) >= 0)
{
for (i = 0; i < nlines; i++)
{
for (j = 0; j = i; j++)
{
lineptr1[j] = lineptr[i];
}
}
qsort(lineptr1, 0, nlines - 1);
/* 读取每行后直接进行排序时,只会将每个元素的首个字符进行排序,不能将后面的字符一起排序。
所以上面采用了重新将每个元素写入的办法,保证每个元素是其原本的所有行字符作为一个整体,然后再进行排序。
代码没报错,暂时运行不出结果。*/
writelines(lineptr1, nlines);
return 0;
}
else //函数readlines的返回值是-1,小于0
{
printf("error: input too big to sort\n");
return 1;
}
}
//(1)读取所有输入行
#define MAXLEN 1000 /*每行的最大字符数*/
int getline(char, int); //使用int getline(char*, int);下面不变,也不会报错,但是没必要,用了反而会引起概念混乱
int getline(char x[], int limit) /* 收集和保存每个文本行中的字符,并返回行长度*/
{
int c, i;
c = 0;
i = 0;
for (i = 0; i < limit - 1 && (c = getchar()) != EOF && c != '\n'; ++i)
{
x[i] = c;
}
if (c == '\n')
{
x[i] = c; //x[i++] = c;
i++;
}
x[i] = '\0';
return i;
}
char* alloc(int);
#define ALLOCSIZE 10000 /*可用空间大小*/
static char allocbuf[ALLOCSIZE]; /*alloc使用的存储区*/
static char* allocp = allocbuf; /*指针allocp指向下一个空闲位置,此处为初始化,防止指针成为野指针。*/
char* alloc(int n)
{
if (allocbuf + ALLOCSIZE - allocp >= n) /* 有足够的空闲空间*/
{
allocp += n; /*申请n个字符的内存空间*/
return allocp - n; /* 返回指向n个字符的(第一个字符的)指针*/
}
else /*空闲空间不够*/
return 0;
}
int readlines(char* lineptr[], int maxlines)
{
int len, nlines;
char* p;
char line[MAXLEN]; /* p为指向字符数组的指针数组,line为普通字符数组*/
nlines = 0;
/* 收集和保存每个文本行中的字符,统计输入的行数*/
while ((len = getline(line, MAXLEN)) > 0)
{
if (nlines >= maxlines || (p = alloc(len)) == NULL) /* 指向每行的第一个字符的指针不为空无意义的0地址处的指针 */
return -1;
else
{
line[len - 1] = '\0';
/* 删除每行中的换行符,将其替换为字符串结束符。
每行的行换行符被替换为结束符后,变成字符串常量。*/
strcpy_s(p, strlen(line) + 1, line);
/*line中每个字符串都是一个不可分割的整体,且将该字符串常量作为实参时,在程序中,每个都生成“指向字符串的常量指针”。
因此将该指针作为实参,传递给strcpy_s函数的第二个指针类型的形参。
如此将line中的指向字符串的常量指针,复制到字符指针数组p中。
函数strcpy_s的第二个参数为标识长度,为每行的字符串长度加1,包含了结束符。strlen求出的字符串长度不包含结束符。*/
lineptr[nlines++] = p;
/* 此时p的类型(“指向字符串的常量指针”)与指针数组lineptr的每个元素的类型一致,都是指针类型。
因此可将p写进lineptr的元素中,并将该指针数组lineptr的下标nlines加1.
后面的writelines打印指针数组lineptr中保存到每个“指向字符串的常量指针”元素时,直接使用格式符"%s"打印元素,没有用取值运算*,就可将该字符串常量指针指向的常量字符串打印出来。 */
}
}
return nlines; /* 返回行数 */
}
//(2)对文本进行排序
/*定义qsort函数时,因为该程序中要进行快速排序的是将每个字符串常量生成的“指向字符串的常量指针”作为元素的指针数组lineptr,因此qsort函数中的形式参数必须是指针类型,函数定义中的命令也都必须使用*运算符取指针指向位置的值进行赋值交换排序。*/
void qsort(char* a[], int low, int high) //快速排序法
{
int i = low; //第一位
int j = high; //最后一位
char key = *(a[i]); //将第一个数作为基准值-- 先找到一个基准值
//进行排序---> 最终结果就是 左面的 都比基准值小 ,右面的都比 基准值大,所以这是所有循环的结束条件
while (i < j)
{
while (i < j && *(a[j]) >= key)
{
j--;//继续走
}
*(a[i]) = *(a[j]);
while (i < j && *(a[i]) <= key) //i仍为初始值low,但a[i]的值已经发生改变了
{
i++;
}
*(a[j]) = *(a[i]);
}
//i和j在中间相遇了就跳出循环,将基准值放入数据a[i]中
*(a[i]) = key;
//对基准值左边 的所有数据 再次进行快速查找(递归)
if (i - 1 > low)
{
qsort(a, low, i - 1);
}
//对基准值右边的所有数据再次进行快速查找(递归)
if (i + 1 < high)
{
qsort(a, i + 1, high);
}
}
//(3)按次序打印文本行
void writelines(char* lineptr[], int nlines) /*输出函数,按照指针数组中的次序依次打印这些文本行,并在每行末尾加上换行符即可*/
{
int i;
for (i = 0; i < nlines; i++)
printf("%s\n", lineptr[i]);
/* 指针数组lineptr中保存的每个元素是“指向字符串的常量指针”。
格式符"%s"表示的是输出的整个lineptr[i]元素的类型是字符串类型,整形i不是规定符要规定的对象。
不需要用取值运算*(lineptr[i]),就可将该字符串常量指针lineptr[i]指向的常量字符串打印出来。*/
}
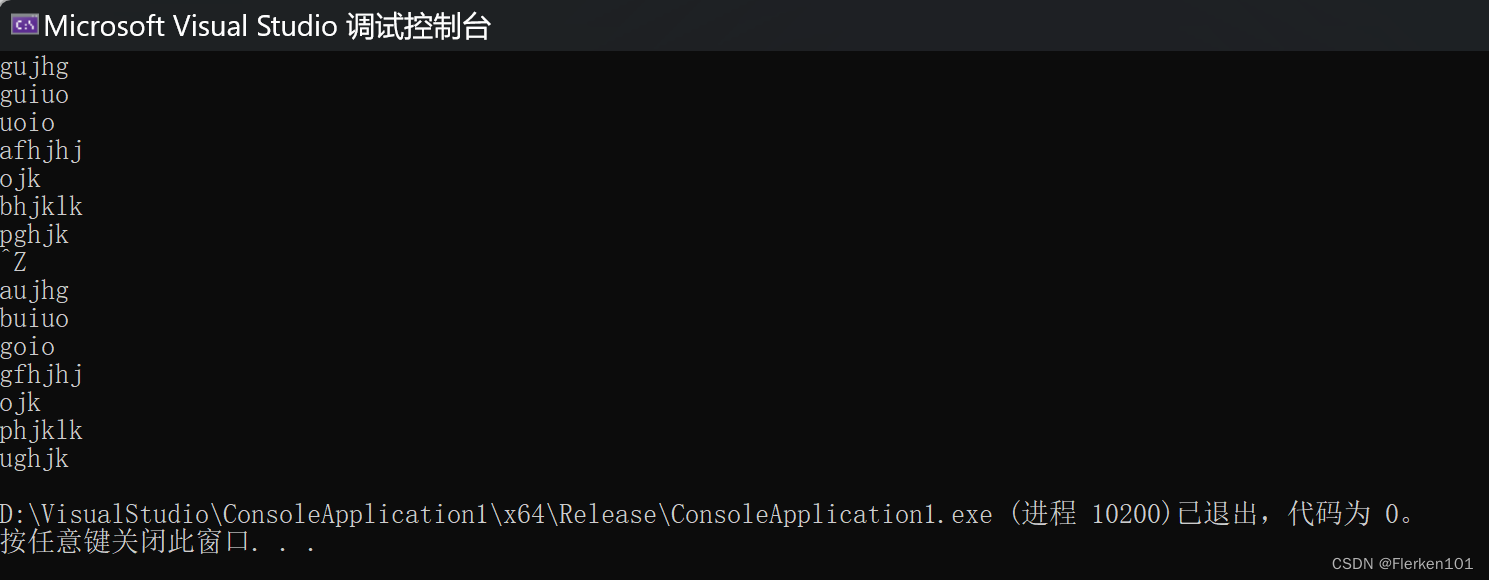
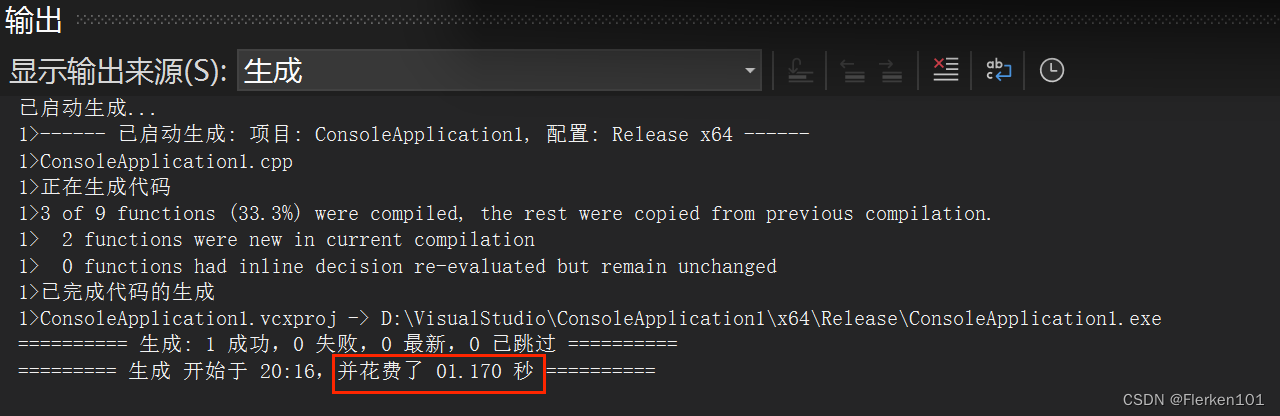
当把writelines函数中的输出命令写成 printf(“%s\n”, lineptr[i]); 时的输出结果:
void writelines(char* lineptr[], int nlines) /*输出函数,按照指针数组中的次序依次打印这些文本行,并在每行末尾加上换行符即可*/
{
int i;
for (i = 0; i < nlines; i++)
printf("%d\n", lineptr[i]);
}
练习5-7
重写readlines,将输入的文本行存储到由main函数提供的一个数组中,而不是存储到调用alloc分配的存储空间中。该函数的运行速度比改写前快多少?
K&R2 solutions:Chapter 5:Exercise 7 [primary] —— Solution by Alex Hoang (Category 0)
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 /*进行排序的最大文本行数。超过限定的最大行数时,返回-1*/
#define MAXSTORE 10000 /* max space allocated for all lines. Same as ALLOCSIZE on p.91. */
char* lineptr[MAXLINES];
int readlines(char* lineptr[], int maxlines, char* ls); /*输入函数,收集和保存每个文本行中的字符,统计输入的行数*/
void qsort(char* a[], int low, int high);
void writelines(char* lineptr[], int nlines); /*输出函数,按照指针数组中的次序依次打印这些文本行即可*/
int main()
{
int nlines;
char linestore[MAXSTORE]; /* 普通字符数组linestore用于存储所有的行array for storing all lines */
/* my readlines will pass an extra parameter linestore for storing all the input lines */
if ((nlines = readlines(lineptr, MAXLINES,linestore)) >= 0) //函数readlines的第三个形参是指针char* ls,普通数组名linestore也是可以作为实参的。
{
qsort(lineptr, 0, nlines - 1);
writelines(lineptr, nlines);
return 0;
}
else //函数readlines的返回值是-1,小于0
{
printf("error: input too big to sort\n");
return 1;
}
}
//(1)读取所有输入行
#define MAXLEN 1000 /*每行的最大字符数*/
int getline(char, int); //使用int getline(char*, int);下面不变,也不会报错,但是没必要,用了反而会引起概念混乱
int getline(char x[], int limit) /* 收集和保存每个文本行中的字符,统计输入的行数*/
{
int c, i;
c = 0;
i = 0;
for (i = 0; i < limit - 1 && (c = getchar()) != EOF && c != '\n'; ++i)
{
x[i] = c;
}
if (c == '\n')
{
x[i] = c; //x[i++] = c;
i++;
}
x[i] = '\0';
return i;
}
int readlines(char* lineptr[], int maxlines, char* ls)
{
int len, nlines;
char* p, line[MAXLEN];
nlines = 0;
p = ls + strlen(ls); /* initiate to first empty position */
/* strlen函数接收的是指针。求字符串常量及字符数组的长度时,strlen函数接受的也是指针,因此strlen(指针)是可以的。
但其实在本函数中会自动判定出按照字符数组类型的方式处理ls,而非指针,因此这里其实是strlen(数组).
虽然形式上形式参数ls被定义为指针,但实际上在下面的函数命令行中都仅把ls当作字符数组ls[]来看,而不是指针ls。
因为:虽然类型不同,但char *ls(类型为指向字符的指针)与char ls[](类型为字符数组)这两种声明是等价的,C语言中即使使用的确实是字符数组ls[],也更习惯于采用char *ls的声明方式。
此时如果将数组名(main函数中的linestore)传递给函数readlines,函数readlines会在系统中自动实现根据情况判定是按照数组处理还是指针处理,随后根据相应的方式操作该函数。
(此处判定过后将数组名linestore按照数组的方式处理。)*/
while ((len = getline(line, MAXLEN)) > 0) //可同时输入多行,处理多行。同getchar()函数一样。
/* The line below will check to make sure adding the nextline will not exceed MAXSTORE */
{
if (nlines >= maxlines || (strlen(ls) + len) > MAXSTORE) //总的行数及每行总的字符数超过限定值,均返回-1
return -1;
else
{
line[len - 1] = '\0';
strcpy_s(p, strlen(line) + 1, line);
/* 利用line字符串产生的指向字符串的常量指针,及指针p,将line指向的字符串复制到指针p指向的位置。
*p = *(line)
而指针p指向字符数组ls中元素,即将line中的字符串常量通过指针复制到字符数组ls中。*/
lineptr[nlines++] = p;
/*与上面复制操作的区别是,没有进行取值运算*.因此此处是:令指针lineptr[nlines]指向指针p指向的位置。*/
p += len; /* point p to next empty position */
/* 指针的算数运算,表示令指针p指向p后面len个长度的位置(即数组ls中下一个空位的位置处)。*/
}
}
return nlines;
}
//(2)对文本进行排序
void qsort(char* a[], int low, int high) //快速排序法
{
int i = low; //第一位
int j = high; //最后一位
char key = *(a[i]); //将第一个数作为基准值-- 先找到一个基准值
//进行排序---> 最终结果就是 左面的 都比基准值小 ,右面的都比 基准值大,所以这是所有循环的结束条件
while (i < j)
{
while (i < j && *(a[j]) >= key)
{
j--;//继续走
}
*(a[i]) = *(a[j]);
while (i < j && *(a[i]) <= key) //i仍为初始值low,但a[i]的值已经发生改变了
{
i++;
}
*(a[j]) = *(a[i]);
}
//i和j在中间相遇了就跳出循环,将基准值放入数据a[i]中
*(a[i]) = key;
//对基准值左边 的所有数据 再次进行快速查找(递归)
if (i - 1 > low)
{
qsort(a, low, i - 1);
}
//对基准值右边的所有数据再次进行快速查找(递归)
if (i + 1 < high)
{
qsort(a, i + 1, high);
}
}
//(3)按次序打印文本行
void writelines(char* lineptr[], int nlines) /*输出函数,按照指针数组中的次序依次打印这些文本行,并在每行末尾加上换行符即可*/
{
int i;
for (i = 0; i < nlines; i++)
printf("%s\n", lineptr[i]);
}
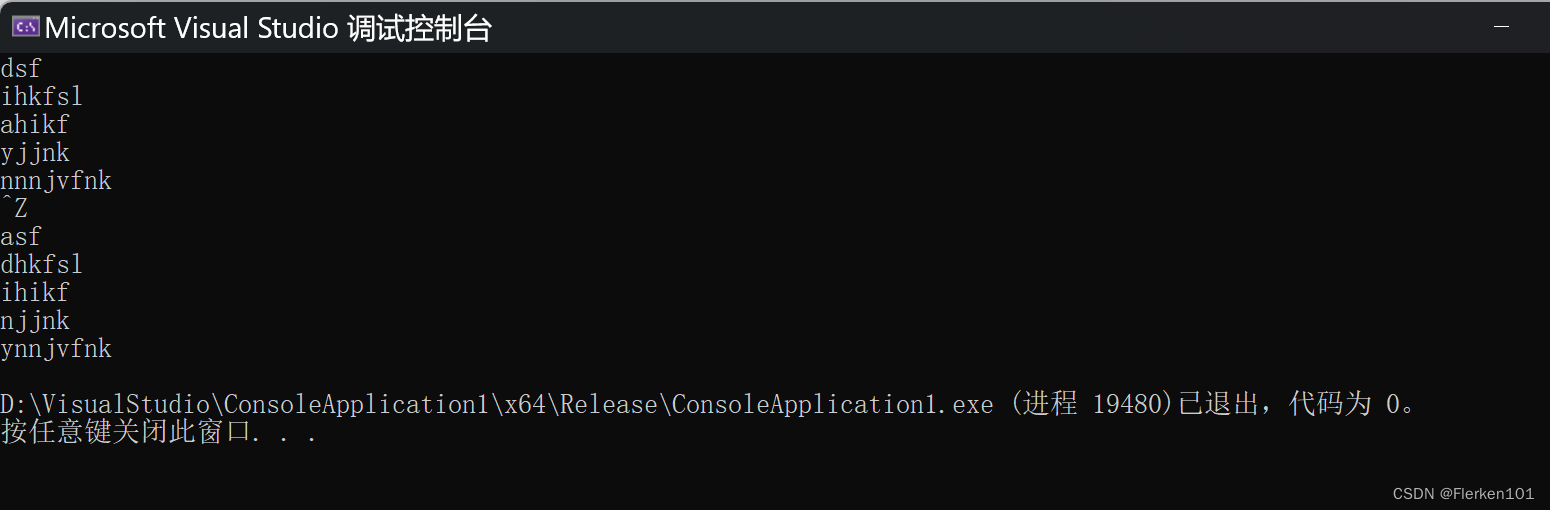
比上面的1.170秒快了半秒(0.409s)
5.7 多维数组
#include <stdio.h>
int day_of_year(int year, int month, int day);
void month_day(int year, int yearday, int* pmonth, int* pday);
int main()
{
int day;
int month = 0;
int day2 = 0;
day = day_of_year(2023, 11, 23);
printf("%d\n", day);
month_day(2023,300,&month,&day2);
printf("%d月%d日", month, day2);
return 0;
}
static char daytab[2][13] = {
{0,31,28,31,30,31,30,31,31,30,31,30,31},
{0,31,29,31,30,31,30,31,31,30,31,30,31},
};
/* day_of_year函数:将某月某日的日期表示形式转化为某年中第几天的表示形式 */
int day_of_year(int year, int month, int day)
{
int i, leap;
leap = year % 4 == 0 && year % 100 != 0 || year % 400 == 0;
for (i = 1; i <= month; i++) //这里一定要有等于号,否则会不算最后一个月的天数
day += daytab[leap][i]; //将day与month前面几个月每月的天数依次累加起来
return day;
}
/* month_day函数:将某年中第几天的日期表示形式转换为某月某日的表示形式 */
void month_day(int year, int yearday, int* pmonth, int* pday)
{
int i, leap;
leap = (year % 4 == 0 && year % 100 != 0 || year % 400 == 0);
for (i = 1; yearday > daytab[leap][i]; i++) //此处不能加等于号(主要区别在与当该天数正好是某天个月的最后一天时,加上等于会额外多进行一次下面的循环,将yearday变为0,月份i也会额外多加一次,如将2023年第212天由7月31日变为8月0日。)
yearday -= daytab[leap][i];
*pmonth = i;
*pday = yearday;
}

运算符的优先级顺序为:(计算每个符号最近的两个表达式的结果值)
逻辑非! > 算术 > 判断等于== > 判断不等于!= > 逻辑与&& > 逻辑或|| > 赋值=
该程序中的leap判断year是否是闰年,是闰年则返回1,不是闰年则返回0.
year%4 == 0 设为A;
year%100 != 0 设为B;
year%400 == 0 设为C.
先计算B、再按顺序计算A、C;
leap
= ( year%4 == 0 && year%100 != 0 || year%400 == 0)
= ( A && B || C ) //B、A、C三个均在&&与||之前计算
= ( (A && B) || C ) //&& > ||,先计算A && B,假设结果为D
= ( D || C ) //再计算||,即 D || C
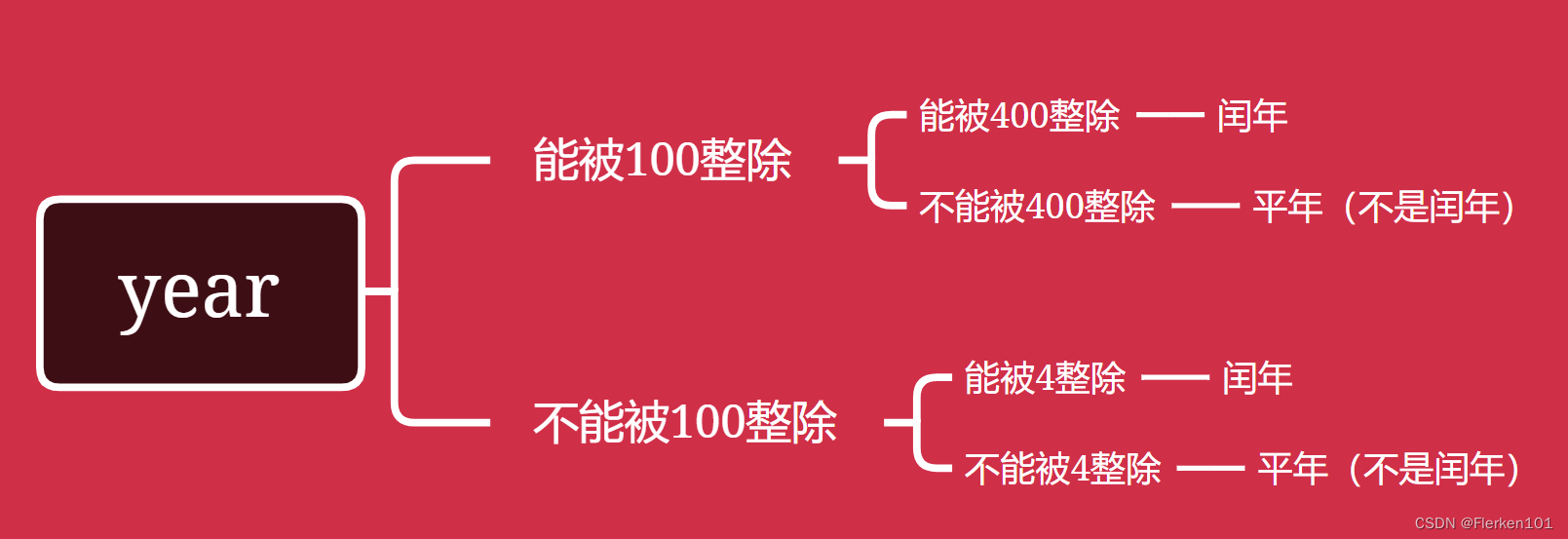
判断year是否"是闰年"的方法:
①先判断year能否被100整除,能被100整除时,再判断能否被400整除,若能被400整除,则是闰年。
例如2000是闰年,但1900就不是闰年,因1900能被100整除但不能被400整除;
②先判断year能否被100整除,不能被100整除时,再判断能否被4整除,若能被4整除,则是闰年。
判断year是否"不是闰年"的方法:
①先判断year能否被100整除,能被100整除时,再判断能否被400整除,若不能被400整除,则是平年(不是闰年);
②先判断year能否被100整除,不能被100整除时,再判断能否被4整除,若不能被4整除,则是平年(不是闰年)。
根据判断year是否"是闰年"的方法,该程序中的leap应该写成:
leap1 = ( year%100 != 0 && year%4 == 0 || year%100 == 0 && year%400 == 0 )
而在上面的式子leap2中,省略了 year%100 == 0.
leap2 = ( year%4 == 0 && year%100 != 0 || year%400 == 0)
这两种写法均可。
leap1、leap2判断year是否是闰年,是闰年则返回1,不是闰年则返回0.
根据判断year是否"不是闰年"的方法:
leap3应该写成:
leap3 = (year%100 == 0 && year%400 != 0) || (year%100 != 0 && year%4 != 0)
另一种写法:省略了year%100 != 0
leap4 = (year%4 != 0) || (year%100 == 0 && year%400 != 0)
leap3、leap4不是闰年则返回1,是闰年则返回0.(后面的程序也要改变。)
证明: leap1与leap2均可判断是否“是闰年”;
leap3与leap4均可判断是否“不是闰年”。
leap1 = ( year%100 != 0 && year%4 == 0 || year%100 == 0 && year%400 == 0 )
leap2 = ( year%4 == 0 && year%100 != 0 || year%400 == 0 )
leap3 = (year%100 == 0 && year%400 != 0) || (year%100 != 0 && year%4 != 0)
leap4 = (year%4 != 0) || (year%100 == 0 && year%400 != 0)两两比较四种写法:
1、(1)假如year为普通年份(不能被100整除)的闰年:
则 year%100 != 0 为真,year%4 == 0 也为真,
year%100 != 0 && year%4 == 0 的结果也为真。
得出year%100 == 0 为假;year%4 != 0为假。
year%400 == 0在此处无法判断。 (不能被100整除且能被4整除的数,无法判断其能否被400整除。)
此处假设year%400 == 0 为真, 则year%400 != 0为假。
(实际上year%400 == 0 的结果不会影响leap的计算结果。)leap1 = ( year%100 != 0 && year%4 == 0 || year%100 == 0 && year%400 == 0 ) = (1 && 1 || 0 && 1) = 1 //leap1结果为真,year是闰年,与假设相符。 leap2 = ( year%4 == 0 && year%100 != 0 || year%400 == 0) = ( 1 && 1 || 1) = 1 //leap2结果为真,year是闰年,与假设相符。 leap3 = (year%100 == 0 && year%400 != 0) || (year%100 != 0 && year%4 != 0) = (0 && 0) || (1 && 0) = (0 || 0) = 0 //leap3结果为假,year是闰年,与假设相符。 leap4 = (year%4 != 0) || (year%100 == 0 && year%400 != 0) = 0 || (0 && 0) = 0 //leap4结果为假,year是闰年,与假设相符。
(2)假如year为能被100整除年份的闰年:
则year%100 == 0 为真,year%400 == 0也为真,
year%100 0 && year%400 0 的结果也为真。
得出year%100 != 0 为假;year%4 == 0 为真(能被100整除又能被400整除的数,一定能被4整除。)leap1 = ( year%100 != 0 && year%4 == 0 || year%100 == 0 && year%400 == 0 ) = (0 && 1 || 1 && 1) = ((0 && 1) || (1 && 1)) // && > ||,从左到右依次均先计算&& = (0 || 1) = 1 //leap1结果为真,year是闰年,与假设相符。 ``` leap2 = ( year%4 == 0 && year%100 != 0 || year%400 == 0) = ( 1 && 0 || 1) = ( (1 && 0) || 1) // && > ||,从左到右依次均先计算&& = ( 0 || 1) = 1 //leap2结果为真,year是闰年,与假设相符。 ``` leap3 = (year%100 == 0 && year%400 != 0) || (year%100 != 0 && year%4 != 0) = ( 1 && 0) || ( 0 && 0) = (0 || 0) = 0 //leap3结果为假,year是闰年,与假设相符。 leap4 = (year%4 != 0) || (year%100 == 0 && year%400 != 0) = 0 || (1 && 0) = 0 //leap4结果为假,year是闰年,与假设相符。
2、假如year不是闰年:
(1)先判断year能否被100整除,能被100整除时,再判断能否被400整除,若不能被400整除,则是平年(不是闰年)。
year%100 == 0 为真,year%400 != 0 为真。
year%4 == 0在此处无法判断。 (能被100整除且不能被400整除的数,无法判断其能否被4整除。)
此处假设year%4 == 0 为真, 则year%4 != 0为假。
(实际上year%4 == 0 的结果不会影响leap的计算结果。)leap1 = ( year%100 != 0 && year%4 == 0 || year%100 == 0 && year%400 == 0 ) = ( (0 && 1) || (1 && 0) ) = (0 || 0) = 0 //leap1结果为假,year不是闰年,与假设相符。 leap2 = ( year%4 == 0 && year%100 != 0 || year%400 == 0) = ( (1 && 0) || 0) = (0 || 0) = 0 //leap2结果为真,year不是闰年,与假设相符。 leap3 = (year%100 == 0 && year%400 != 0) || (year%100 != 0 && year%4 != 0) = ( 1 && 1) || ( 0 && 1) = (1 || 0) = 1 //leap3结果为真,year不是闰年,与假设相符。 leap4 = (year%4 != 0) || (year%100 == 0 && year%400 != 0) = (1 || (1 && 1)) = (1 || 1) = 1 //leap4结果为真,year不是闰年,与假设相符。 (2)先判断year能否被100整除,不能被100整除时,再判断能否被4整除,若不能被4整除,则是平年(不是闰年)。 year%100 != 0 为真; year%4 != 0 为真。 得出year%400 == 0为假(不能被100整除又不能被4整除的数,一定不能被400整除。) leap1 = ( year%100 != 0 && year%4 == 0 || year%100 == 0 && year%400 == 0 ) = (1 && 0) || (0 || 0) = ( 1 || 0 ) = 0 //leap1结果为假,year不是闰年,与假设相符。 leap2 = ( year%4 == 0 && year%100 != 0 || year%400 == 0) = ( (0 && 1) || 0) = ( 0 || 0) = 0 //leap2结果为假,year不是闰年,与假设相符。 leap3 = (year%100 == 0 && year%400 != 0) || (year%100 != 0 && year%4 != 0) = ( 0 && 1) || ( 1 && 1) = (0 || 1) = 1 //leap3结果为真,year不是闰年,与假设相符。 leap4 = (year%4 != 0) || (year%100 == 0 && year%400 != 0) = ( 1 || (0 && 1)) = ( 1 || 0) = 1 //leap4结果为真,year不是闰年,与假设相符。 结论: 判断year是否"是闰年",leap1与leap2的写法均正确。 判断year是否"不是闰年",leap3与leap4的写法均正确。
因此最终判断是否是闰年的方式为:
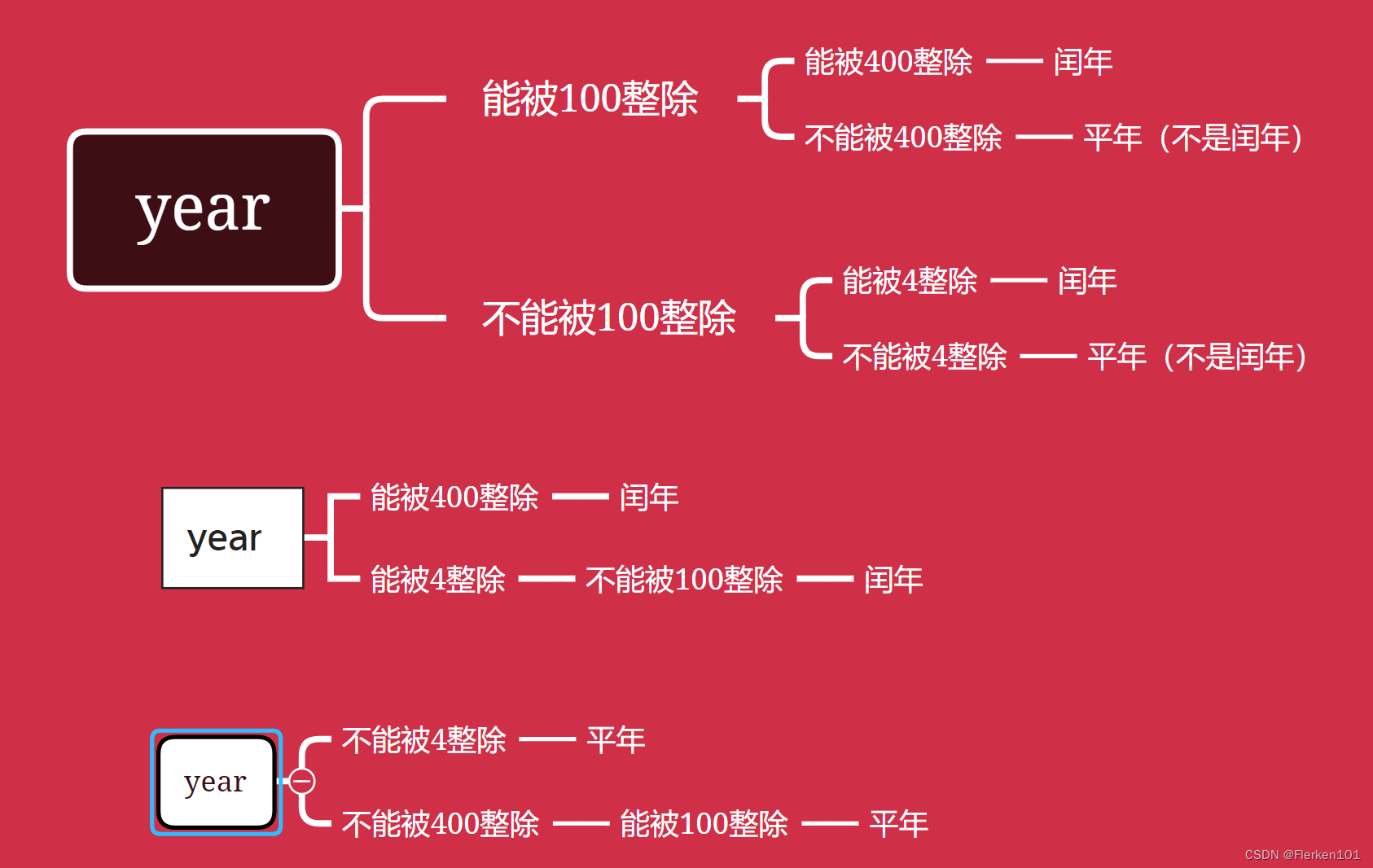
(不能被100整除且能被4整除的数,无法判断其能否被400整除。)
(能被100整除又能被400整除的数,一定能被4整除。)
(能被100整除且不能被400整除的数,无法判断其能否被4整除。)
(不能被100整除又不能被4整除的数,一定不能被400整除。)
练习5-8
函数day_of_year 和 month_day中没有进行错误检查,请解决该问题。
#include <stdio.h>
#include <stdlib.h>
static char daytab[2][13] =
{
{0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31},
{0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}
};
int day_of_year(int year, int month, int day)
{
if (year < 1752)
return -1; //错误判断1
int i, leap;
leap = (year % 400 == 0) || (year % 4 == 0 && year % 100 != 0);
if (!((month >= 1 && month <= 12) && (day >= 1 && day <= daytab[leap][month])))
return -1; //错误判断2
for (i = 1; i < month; i++)
{
day += daytab[leap][i];
}
return day;
}
void month_day(int year, int yearday, int* pmonth, int* pday)
{
if (year < 1752)
{
*pmonth = *pday = -1;
return;
} //错误判断1
int i, leap;
leap = (year % 400 == 0) || (year % 4 == 0 && year % 100 != 0);
if (!(yearday >= 1 && yearday <= (leap ? 366 : 365)))
{
*pmonth = *pday = -1;
return;
} //错误判断2
for (i = 1; yearday > daytab[leap][i]; i++)
yearday -= daytab[leap][i];
*pmonth = i;
*pday = yearday;
}
int main()
{
int month, day, year, yearday, retval;
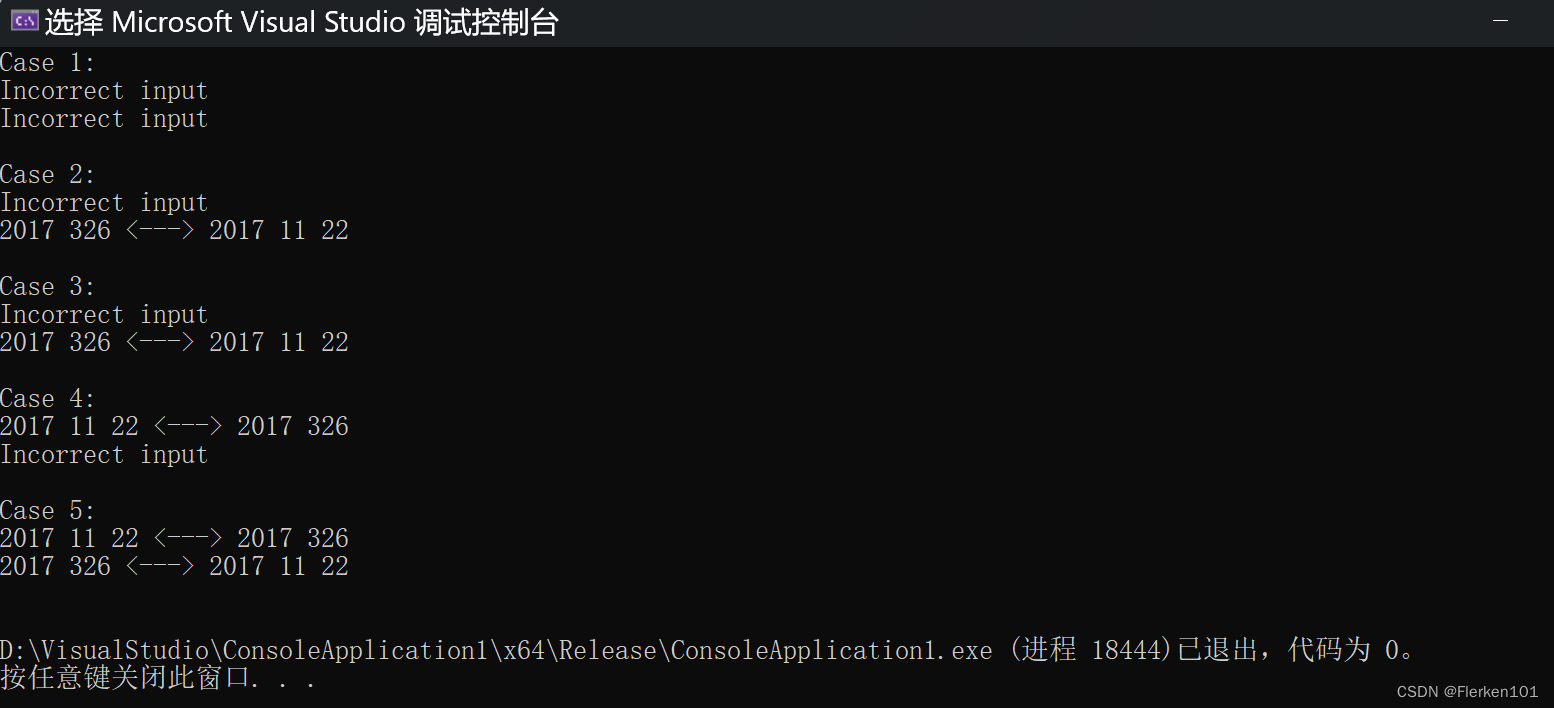
/******************************* Case 1 *****************************/
printf("Case 1:\n");
year = -2017;
month = 11;
day = 22;
yearday = 326;
retval = day_of_year(year, month, day);
if (retval == -1)
printf("Incorrect input\n");
else
printf("%d %d %d <---> %d %d\n", year, month, day, year, retval);
month_day(year, yearday, &month, &day);
if (month == -1 && day == -1)
printf("Incorrect input\n");
else
printf("%d %d <---> %d %d %d\n", year, yearday, year, month, day);
printf("\n");
/*********************************************************************/
/******************************* Case 2 *****************************/
printf("Case 2:\n");
year = 2017;
month = -11;
day = 22;
yearday = 326;
retval = day_of_year(year, month, day);
if (retval == -1)
printf("Incorrect input\n");
else
printf("%d %d %d <---> %d %d\n", year, month, day, year, retval);
month_day(year, yearday, &month, &day);
if (month == -1 && day == -1)
printf("Incorrect input\n");
else
printf("%d %d <---> %d %d %d\n", year, yearday, year, month, day);
printf("\n");
/*********************************************************************/
/******************************* Case 3 *****************************/
printf("Case 3:\n");
year = 2017;
month = 11;
day = -22;
yearday = 326;
retval = day_of_year(year, month, day);
if (retval == -1)
printf("Incorrect input\n");
else
printf("%d %d %d <---> %d %d\n", year, month, day, year, retval);
month_day(year, yearday, &month, &day);
if (month == -1 && day == -1)
printf("Incorrect input\n");
else
printf("%d %d <---> %d %d %d\n", year, yearday, year, month, day);
printf("\n");
/*********************************************************************/
/******************************* Case 4 *****************************/
printf("Case 4:\n");
year = 2017;
month = 11;
day = 22;
yearday = -326;
retval = day_of_year(year, month, day);
if (retval == -1)
printf("Incorrect input\n");
else
printf("%d %d %d <---> %d %d\n", year, month, day, year, retval);
month_day(year, yearday, &month, &day);
if (month == -1 && day == -1)
printf("Incorrect input\n");
else
printf("%d %d <---> %d %d %d\n", year, yearday, year, month, day);
printf("\n");
/*********************************************************************/
/******************************* Case 5 *****************************/
printf("Case 5:\n");
year = 2017;
month = 11;
day = 22;
yearday = 326;
retval = day_of_year(year, month, day);
if (retval == -1)
printf("Incorrect input\n");
else
printf("%d %d %d <---> %d %d\n", year, month, day, year, retval);
month_day(year, yearday, &month, &day);
if (month == -1 && day == -1)
printf("Incorrect input\n");
else
printf("%d %d <---> %d %d %d\n", year, yearday, year, month, day);
printf("\n");
/*********************************************************************/
return 0;
}
5.8 指针数组的初始化
/* month_name函数:返回第n个月份的名字 */
char* month_name(int n)
{
static char* name[] = {
"illegal month",
"January","February","March",
"April","May","June",
"July","August","September",
"October","November","December"
};
return (n < 1 || n > 12) ? name[0] : name[n];
}
5.9 指针与多维数组
练习5-9
用指针方式代替数组下标方式改写函数day_of_year 和 month_day
#include <stdio.h>
static char daytab[2][13] = {
{0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31},
{0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31},
};
/*函数的定义程序放在main函数前面,则不用再写函数的声明。*/
/* pointer versions */
int day_of_year_pointer(int year, int month, int day)
{
int i, leap;
char* p; //引入指针p
leap = (year % 4 == 0 && year % 100 != 0) || year % 400 == 0;
/* Set `p' to point at first month in the correct row. */
p = &daytab[leap][1]; //令指针p指向daytab数组中的闰年(leap = 1,第二行)/平年(leap = 0,第一行)的第一个月份
/* Move `p' along the row, to each successive month. */
for (i = 1; i < month; i++) {
day += *p; //每次移动p后,将指针p指向的值累加后赋给day
++p; //指针p不断在数组中向前移动
}
return day;
}
void month_day_pointer(int year, int yearday, int* pmonth, int* pday)
{
int i, leap;
char* p; //引入指针p
leap = (year % 4 == 0 && year % 100 != 0) || year % 400 == 0;
p = &daytab[leap][1]; //令指针p指向daytab数组中的闰年(leap = 1,第二行)/平年(leap = 0,第一行)的第一个月份
for (i = 1; yearday > *p; i++) {
yearday -= *p; //每次移动p后,将指针p指向的值累减后赋给yearday
++p; //指针p不断在数组中向前移动
}
*pmonth = i;
*pday = yearday;
}
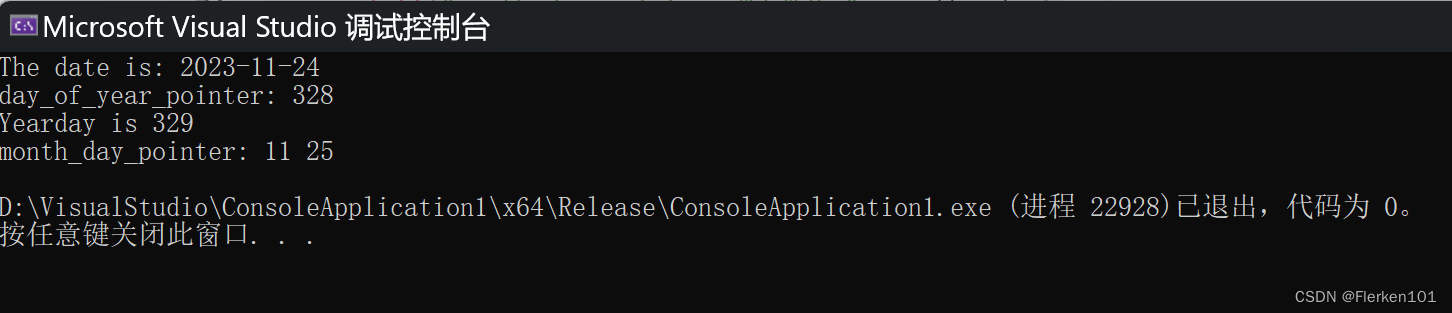
int main(void)
{
int year, month, day, yearday;
year = 2023;
month = 11;
day = 24;
printf("The date is: %d-%02d-%02d\n", year, month, day);
printf("day_of_year_pointer: %d\n",
day_of_year_pointer(year, month, day));
yearday = 329 ; /* 2000-03-01 */
printf("Yearday is %d\n", yearday);
month_day_pointer(year, yearday, &month, &day); //定义了变量month与day后,即可将他们的寻址结果作为指针形式参数的实参。不用专门定义指针再进行初始化
printf("month_day_pointer: %d %d\n", month, day);
return 0;
}
5.10 命令行参数
在windows平台下,运行命令行参数的步骤:
①将下面的程序,用VisualStudio编译生成目标文件为test的应用程序
参考链接:在VisualStudio上生成代码的exe可执行文件
#include <stdio.h>
/*回显程序命令行参数:版本1 */
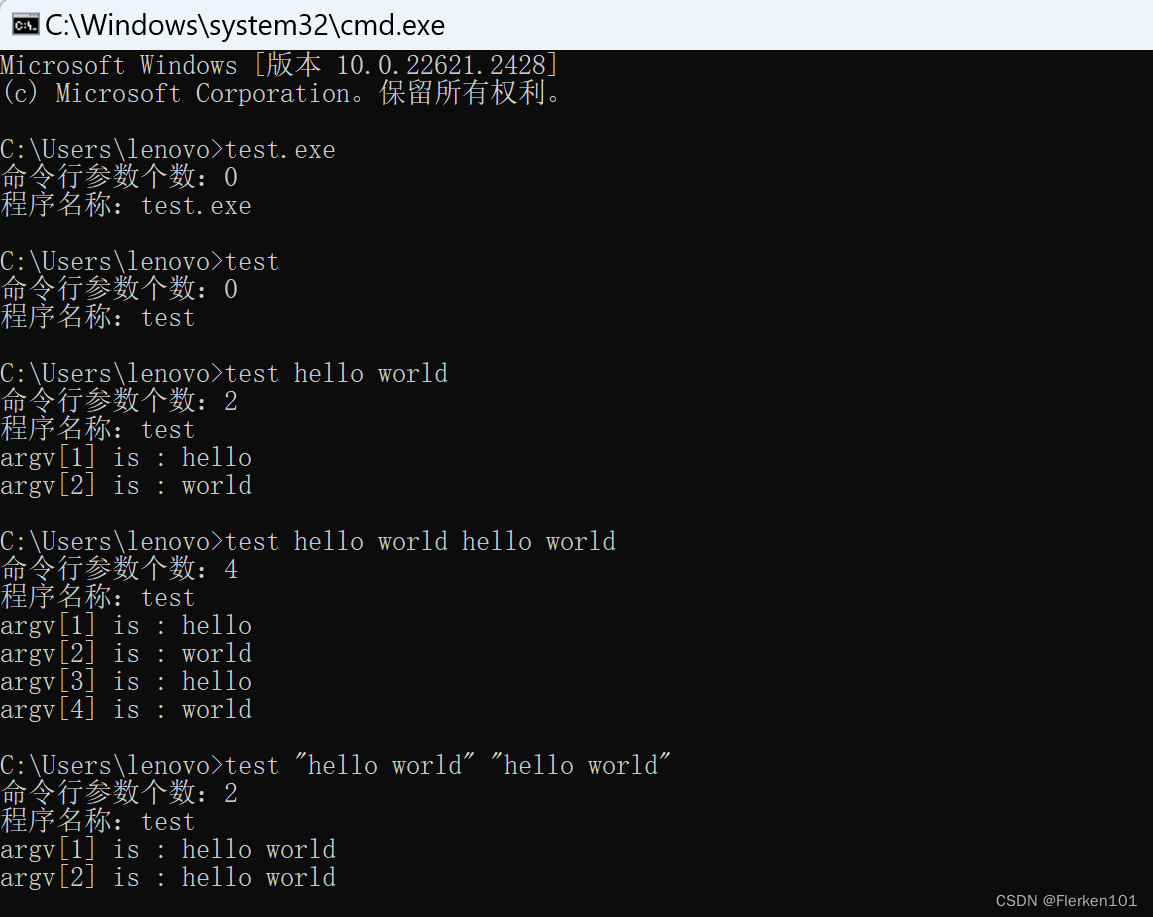
int main(int argc, char* argv[])
{
int i;
printf("命令行参数个数:%d\n", argc - 1);
printf("程序名称:%s\n", argv[0]);
for (i = 1; i < argc; i++)
printf("argv[%d] is : %s\n", i, argv[i]);
return 0;
}
②在windows+R/cmd命令对话框中,根据规则,运行test应用程序及命令行参数
windows下的C语言命令行参数
复制到相应目录lenovo下
运行结果:
如果不生成exe可执行文件,则程序的名称显示的是VisualStudio中自动生成的文件名称,且无法真正输入命令行参数。
#include <stdio.h>
/*回显程序命令行参数:版本1 */
int main(int argc, char* argv[])
{
int i;
printf("argc is %d\n", argc);
for (i = 0; i < argc; i++)
printf("argv[%d] is : %s\n", i, argv[i]);
return 0;
}

#include <stdio.h>
/*回显程序命令行参数:版本1 */
int main(int argc, char* argv[])
{
int i;
printf("argc is %d\n", argc);
for (i = 0; i < argc; i++)
printf("It is %s %s\n", argv[i], (i < argc - 1) ? "A" : "B");
//输出B,说明i >= argc - 1. 已知argc=1
return 0;
}

#include <stdio.h>
/*回显程序命令行参数:使用指针的版本2 */
int main(int argc,char *argv[])
{
int i = 0;
printf("argc is %d\n", argc);
for(i = 0; i < argc; i++)
printf("argv[%d] is : %s\n",i,*++argv);
//指针argv先自增,再赋给函数printf *argv的值。
return 0;
}

通过命令行的第一个参数指定待匹配模式的程序。
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char* line[], int limit);
int main(int argc, char* argv[])
{
char* line[MAXLINE];
int found = 0;
int i = 0;
if (argc != 1)
{
printf("Usage : find pattern\n");
}
else
{
for (i = 0; i < argc; i++)
printf("argv[%d] is : %s\n", i, *++argv);
while (getline(line, MAXLINE) > 0)
{
if (strstr(*line, argv[0]) != NULL)
{
printf("%s", *line);
found++;
}
}
}
return found;
}
int getline(char* line[], int limit)
{
int i;
char c = 'a';
for (i = 0; i < limit - 1 && (c = getchar()) != EOF && c != '\n'; i++)
{
line[i] = &c;
}
if (c == '\n')
{
line[i++] = &c;
}
*(line[i]) = '\0';
return i;
}
strstr函数中的第二个参数argv[0]是NULL,所以strstr(*line, argv[0]) 的结果是 NULL

改写后的 通过命令行的第一个参数指定待匹配模式的程序。上面的版本2
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char* line[], int max);
int main(int argc,char *argv[])
{
char* line[MAXLINE];
long lineno = 0;
int c, except = 0, number = 0, found = 0,i=0;
printf("argc is %d\n", argc);
for (i = 0; i < argc; i++)
printf("argv[%d] is : %s\n", i, *++argv);
while (--argc > 0 && (*++argv)[0] == '-')
{
while(c = *++argv[0])
switch (c)
{
case 'x':
except = 1;
break;
case '\n':
number = 1;
break;
default:
printf("find : illegal option %c\n", c);
argc = 0;
found = -1;
break;
}
}
printf("argc is %d\n", argc);
if (argc != 1)
printf("Usage : find -x -n pattern\n");
else
while (getline(line, MAXLINE) > 0)
{
lineno++;
if ((strstr(*line, *argv) != NULL) != except)
{
if (number)
printf("%1d:", lineno);
printf("%s", *line);
found++;
}
}
return found;
}
int getline(char* line[], int limit)
{
int i;
char c = 'a';
for (i = 0; i < limit - 1 && (c = getchar()) != EOF && c != '\n'; i++)
{
line[i] = &c;
}
if (c == '\n')
{
line[i++] = &c;
}
*(line[i]) = '\0';
return i;
}

5.11 指向函数的指针
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#define MAXLINES 5000
#define MAXLEN 1000 /*每行的最大字符数*/
#define MAXSTORE 10000
int getline(char, int); //使用int getline(char*, int);下面不变,也不会报错,但是没必要,用了反而会引起概念混乱
int readlines(char* lineptr[], int maxlines, char* ls);
void writelines(char* lineptr[], int nlines);
void quick_sort(void* a[], int low, int high, int (*comp)( void*, void*));
double atof(char s[]);
char* lineptr[MAXLINES];
int numcmp(char*, char*);
/*对输入的文本行进行排序 */
int main(int argc, char* argv[])
{
int nlines;
int numeric = 0;
char linestore[MAXSTORE];
if (argc > 1 && strcmp(argv[1], "-n") == 0)
{
numeric = 1;
}
if ((nlines = readlines(lineptr, MAXLINES, linestore)) >= 0)
{
quick_sort((void **)lineptr, 0, nlines - 1, (numeric ? (int (*)(void*, void*))numcmp : (int (*)(void*, void*))strcmp));
writelines(lineptr,nlines);
return 0;
}
else
{
printf("input too big to sort\n");
return 1;
}
}
int getline(char x[], int limit) /* 收集和保存每个文本行中的字符,统计输入的行数*/
{
int c, i;
c = 0;
i = 0;
for (i = 0; i < limit - 1 && (c = getchar()) != EOF && c != '\n'; ++i)
{
x[i] = c;
}
if (c == '\n')
{
x[i] = c; //x[i++] = c;
i++;
}
x[i] = '\0';
return i;
}
int readlines(char* lineptr[], int maxlines, char* ls)
{
int len, nlines;
char* p, line[MAXLEN];
nlines = 0;
p = ls + strlen(ls); /* initiate to first empty position */
while ((len = getline(line, MAXLEN)) > 0) //可同时输入多行,处理多行。同getchar()函数一样。
/* The line below will check to make sure adding the nextline will not exceed MAXSTORE */
{
if (nlines >= maxlines || (strlen(ls) + len) > MAXSTORE) //总的行数及每行总的字符数超过限定值,均返回-1
return -1;
else
{
line[len - 1] = '\0';
strcpy_s(p, strlen(line) + 1, line);
lineptr[nlines++] = p;
p += len; /* point p to next empty position */
}
}
return nlines;
}
/* qsort函数:以递增顺序对v[left]…v[right]进行排序 */
void quick_sort(void* a[], int low, int high, int (*comp)(void*, void*))
{
int i = low;
int j = high;
void* key = a[i];
while (i < j)
{
while (i < j && (*comp)(a[j], key) >= 0)
{
j--;
}
a[i] = a[j];
while (i < j && (*comp)(a[i], key) <= 0)
{
i++;
}
a[j] = a[i];
if (i - 1 > low)
{
quick_sort(a, low, i - 1, comp);
}
if (i + 1 < high)
{
quick_sort(a, i+1, high, comp);
}
}
}
double atof(char s[])
{
double val, power;
int i, sign;
for (i = 0; isspace(s[i]); i++)
{
;
}
sign = (s[i] == '-') ? -1 : 1;
if (s[i] == '+' || s[i] == '-')
{
i++;
}
for (val = 0.0; isdigit(s[i]); i++)
{
val = 10.0 * val + (s[i] - '0');
}
if (s[i] == '.')
{
i++;
}
for (power = 1.0; isdigit(s[i]); i++)
{
val = 10.0 * val + (s[i] - '0');
power *= 10.0;
}
return sign * val / power;
}
int numcmp(char* s1, char* s2)
{
double v1, v2;
v1 = atof(s1);
v2 = atof(s2);
if (v1 < v2)
return -1;
else if (v1 > v2)
return 1;
else
return 0;
}
void writelines(char* lineptr[], int nlines)
{
int i;
for (i = 0; i < nlines; i++)
printf("%s\n", lineptr[i]);
}
5.12 复杂声明
int *p、int **p、int (*p)()、int *p()、int *p[n]、int (*p)[n]等简单总结 ——品学兼优张同学
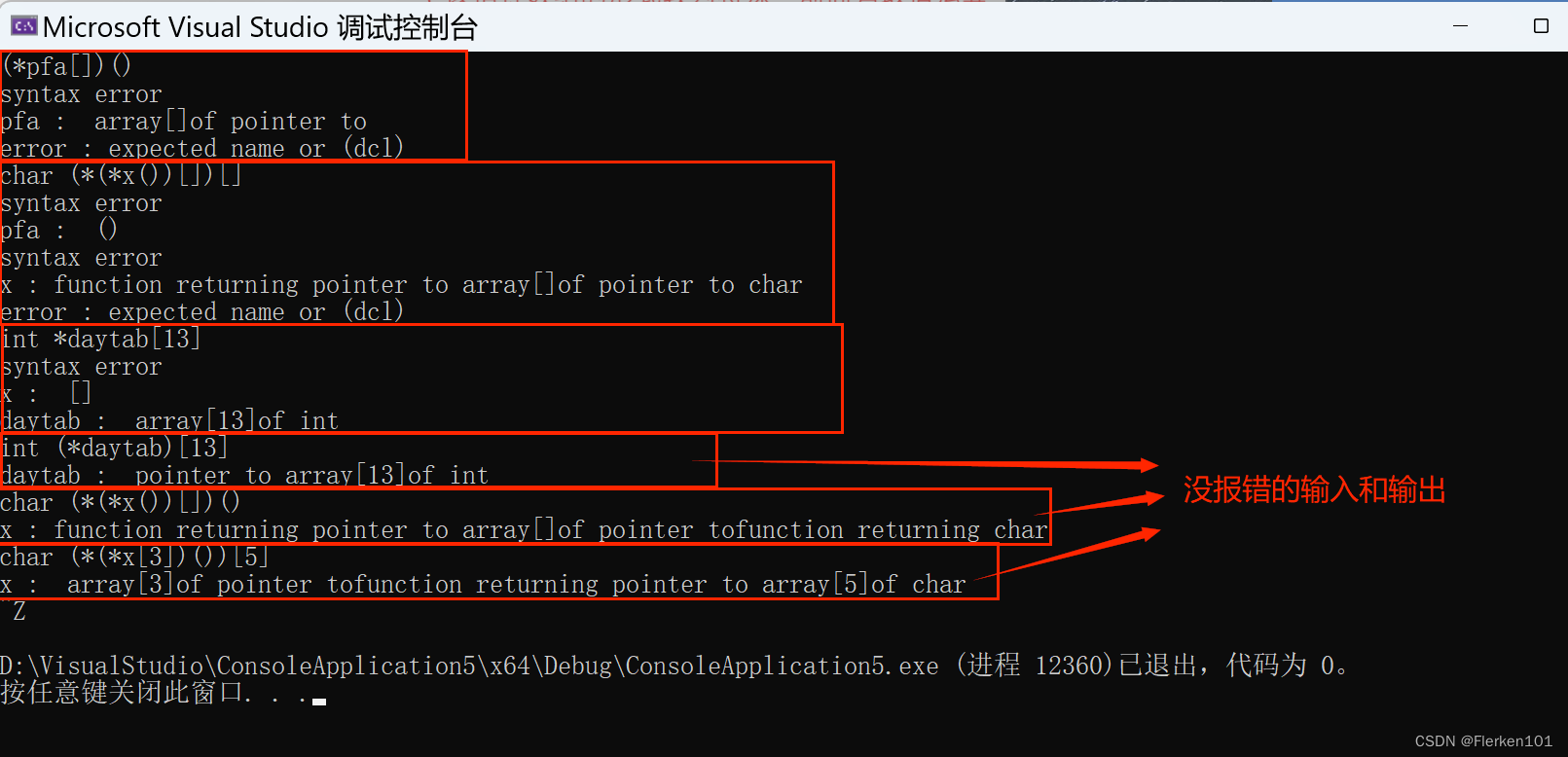
char (*(*x[3])())[5]
①从里到外分析各个部分的定义(名称及属性):
(根据运算符()>[]>*的优先级顺序,先分析运算符() ())
先分析最里面的括号部分
*x[3],x是一个有三个元素的指针数组,指针元素指向的数据类型没有说明;
令 x[3] 为 A
再分析它外层的括号(A)()部分
*A(),A是一个返回值为指针的函数,函数的形式参数没有说明;
令 *A() 为 B
最后分析最外层的括号B[5]部分
char B[5],B是一个有五个元素的字符型数组。
②再将各个分部分A、B(不是整体),从外到里分析,将各个部分联系起来:
由A,x[3]是一个返回值为指针的函数,函数的形式参数没有说明;
由x[3]本身,三个元素的指针数组
则x的三个指针元素,各指向一个返回值为指针的函数(函数的形式参数没有说明)
【所以最终将*(A)()写成了*(*x[3])()】
由B,A()是一个有五个元素的字符型数组
由A()本身,返回值为指针的函数,函数的形式参数没有说明
则函数A返回的指针指向一个有五个元素的字符型数组(函数的形式参数没有说明)。
【所以最终将char B[5]写成了char (*A())[5]】
通过A,将B与x联系起来:
则 x[3] 是一个返回值为指向一个有五个元素的字符型数组的指针 的函数(函数的形式参数没有说明)。
由x[3]本身,三个元素的指针数组
则x 中的每一个元素指针,都指向一个返回值为指向一个有五个元素的字符型数组的指针 的函数(函数的形式参数没有说明)。
即x 是一个 有三个 指向返回值为指向一个有五个元素的字符型数组的指针的函数(函数的形式参数没有说明) 指针元素的数组。
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#define MAXTOKEN 100
#define BUFSIZE 100
enum {NAME,PARENS,BRACKETS};
void dcl(void);
void dirdcl(void);
int gettoken(void);
int tokentype;
char token[MAXTOKEN];
char name[MAXTOKEN];
char datatype[MAXTOKEN];
char out[1000];
int main()
{
while (gettoken() != EOF)
{
strcpy_s(datatype, token);
out[0] = '\0';
dcl();
if (tokentype != '\n')
printf("syntax error\n");
printf("%s : %s %s\n", name, out, datatype); //名称name : 分析out 数据类型datatype
}
return 0;
}
static char buf[BUFSIZE]; //共享缓冲区,字符数组
static int bufp; //buf的下标,缓冲区buf的下一个空闲位置
int getch(void)
{
return (bufp > 0) ? buf[--bufp] : getchar(); //当缓冲区不空时。从缓存区读入,否则直接从输入中读入
}
void ungetch(int c)
{
if (bufp >= BUFSIZE)
printf("ungetch: too many characters\n");
else
buf[bufp++] = c;
}
int gettoken(void)
{
int c, getch(void);
void ungetch(int);
char* p = token;
while ((c = getch()) == ' ' || c == '\t')
;
if (c == '(')
{
if ((c = getch()) == ')')
{
strcpy_s(token, "()");
return tokentype = PARENS;
}
else
{
ungetch(c);
return tokentype = '(';
}
}
else if (c == '[')
{
for (*p++ = c; (*p++ = getch()) != ']';)
;
*p = '\0';
return tokentype = BRACKETS;
}
else if (isalpha(c))
{
for (*p++ = c; isalnum(c = getch());)
*p++ = c;
*p = '\0';
ungetch(c);
return tokentype = NAME;
}
else
return tokentype = c;
}
/* dcl函数:对一个声明符进行语法分析 */
void dcl(void)
{
int ns;
for (ns = 0; gettoken() == '*';) /* 统计数字符*的个数 */
ns++;
dirdcl();
while (ns-- > 0) /*有几个* 代表有几个指针 */
strcat_s(out, " pointer to");
}
/* dirdcl 函数:分析一个直接声明 */
void dirdcl(void)
{
int type;
if (tokentype == '(') /* 形式为(dcl) */
{
dcl();
if (tokentype != ')')
printf("error : missing )\n");
}
else if(tokentype == NAME) /* 变量名 */
{
strcpy_s(name, token);
}
else
{
printf("error : expected name or (dcl) \n");
}
while ((type = gettoken()) == PARENS || type == BRACKETS)
if (type == PARENS)
strcat_s(out, "function returning");
else
{
strcat_s(out, " array");
strcat_s(out, token);
strcat_s(out, "of");
}
}














 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









