










嵌套使用group,子查询得到的结果集被执行计划取消
业务场景
先说下我遇到的业务场景(觉得枯燥可以跳过直接看后面的SQL)
我现在有两个表:
一个树结构的单表-机构表 dept_table【数据量约100条】。
一个保存故障设备解决历时的单表-设备故障解决历时表(实际上是多表联查得到的数据,但这里当作单表来说明,下面简称历时表)time_table【数据量约20000条】。
它们的关系是一对多,一个机构下存在多个设备。
现在我的任务是:统计每个机构故障设备的已解决历时和未解决历时平均值(需要包含下属机构的数据)。
我的做法是:将机构表 dept_table 和历时表 time_table 进行左连接,然后根据机构id 进行 group 分组,得出每个机构的平均历时数据(但此时不包含下属机构的数据)作为结果集 dept_temp_table,之后再对机构表 dept2_table 进行一次自连接后 group 分组,即可得出包含下属机构的平均历时数据。
这时,坑爹的事情来了,通过查看执行计划我发现,在自连接的时候居然忽略了我的临时表 dept_temp_table,而采用了未分组的原表 dept_table 进行表连接(要知道在进行左连接之后 dept_table 已经从一百条数据增大到了上万条,如果不进行分组处理而是直接自连接,成本是乘以百倍的),最后的结果就是原本一秒不用的SQL,居然耗费了十多秒。(我在使用MySQL的时候并没有这个问题)
模拟场景的SQL
由于项目用到的SQL比较冗长繁杂,也属于私密信息不方便公开,所以下面我用了一个比较简单的例子来证明这个结果集被取消的现象
EXPLAIN ( ANALYSE, VERBOSE, TIMING, costs, buffers, timing )
SELECT
sd4.dept_id, AVG(test_avg) AS test_avg
FROM
(
SELECT
dept_id
FROM
sys_dept sdd
WHERE
CAST ( 1 AS TEXT ) = ANY ( string_to_array( ancestors, ',' ) ) -- 权限控制,只能查询自己所属部门以及下属部门的数据
) sd4
LEFT JOIN (
-- 下面的SQL将得到所有机构的设备故障历时平均值,构成结果集sd5(不包含下属部门)
SELECT
sd.dept_id,sd.ancestors
, AVG(vai.belong_dept_id) AS test_avg -- 求出平均值
FROM
sys_dept sd INNER JOIN -- 这里的表连接用于获取每个机构的数据集
(
SELECT
vai2.belong_dept_id, vai2.inst_id
FROM
sys_dept sd2
LEFT JOIN
v_am_inst vai2
ON sd2.dept_id = vai2.belong_dept_id
) vai -- 拿到数据结果集,这里只是做一个模拟,随便拿个数值而已
ON vai.belong_dept_id = sd.dept_id
GROUP BY
sd.dept_id,
sd.ancestors
) sd5 ON CAST ( sd4.dept_id AS TEXT ) = ANY ( string_to_array( sd5.ancestors, ',' ) ) -- 通过祖级列表进行左连接,获得下属部门的数据
GROUP BY
sd4.dept_id
运行得到执行计划如下:
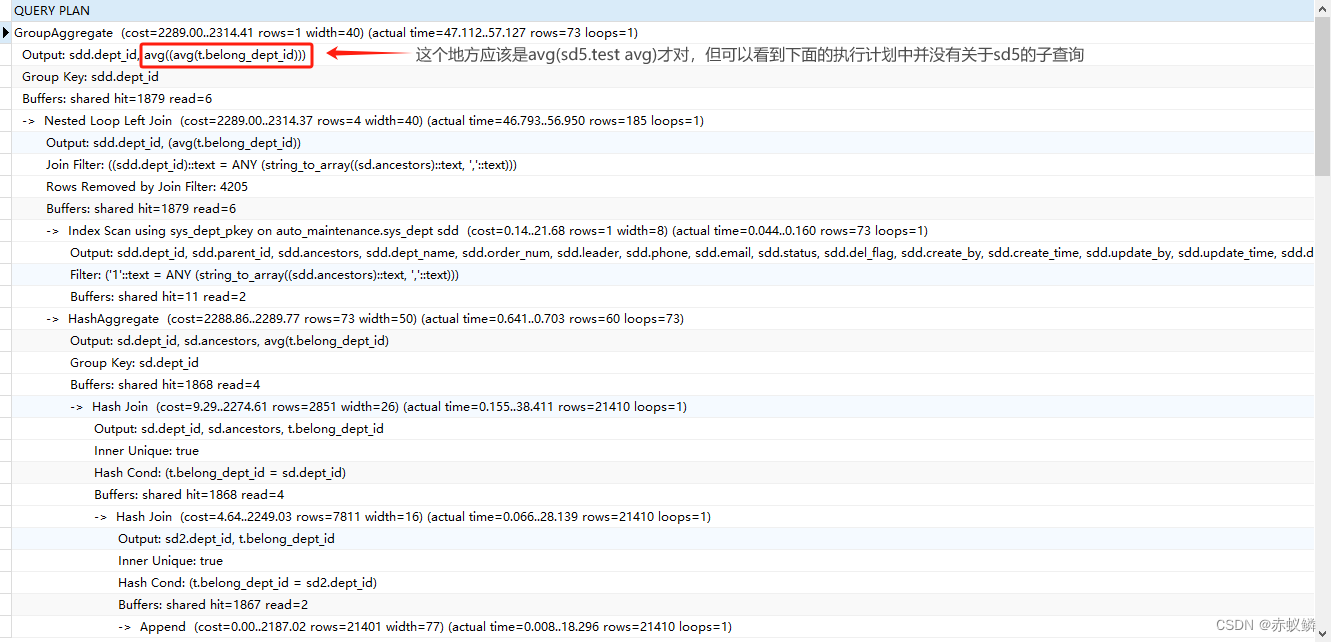
我的解决方法是给子查询的结果集 sd5 再套一层毫无意义的子查询并group by。如下:
EXPLAIN ( ANALYSE, VERBOSE, TIMING, costs, buffers, timing )
SELECT
sd4.dept_id, AVG(test_avg) AS test_avg
FROM
(
SELECT
dept_id
FROM
sys_dept sdd
WHERE
CAST ( 1 AS TEXT ) = ANY ( string_to_array( ancestors, ',' ) ) -- 权限控制,只能查询自己所属部门以及下属部门的数据
) sd4
LEFT JOIN (
SELECT -- 毫无意义的查询,但这种行为可以让执行计划引用我们内部的子查询。。
dept_id, ancestors, test_avg
FROM
(
-- 下面的SQL将得到所有机构的设备故障历时平均值,构成结果集sd5(不包含下属部门)
SELECT
sd.dept_id,sd.ancestors
, AVG(vai.belong_dept_id) AS test_avg -- 求出平均值
FROM
sys_dept sd INNER JOIN -- 这里的表连接用于获取每个机构的数据集
(
SELECT
vai2.belong_dept_id, sd2.dept_id
FROM
sys_dept sd2
LEFT JOIN
v_am_inst vai2
ON sd2.dept_id = vai2.belong_dept_id
) vai -- 拿到数据结果集,这里只是做一个模拟,随便拿个数值而已
ON vai.belong_dept_id = sd.dept_id
GROUP BY
sd.dept_id,
vai.dept_id, -- 这一步至关重要,在group by后面必须同时引用到两个临时表的字段,否则无效
sd.ancestors
) sd5
GROUP BY dept_id, ancestors, test_avg -- 毫无意义的分组,但这种行为可以让执行计划引用我们内部的子查询。。
) sd6 ON CAST ( sd4.dept_id AS TEXT ) = ANY ( string_to_array( sd6.ancestors, ',' ) ) -- 通过祖级列表进行左连接,获得下属部门的数据
GROUP BY
sd4.dept_id
运行得到执行计划如下: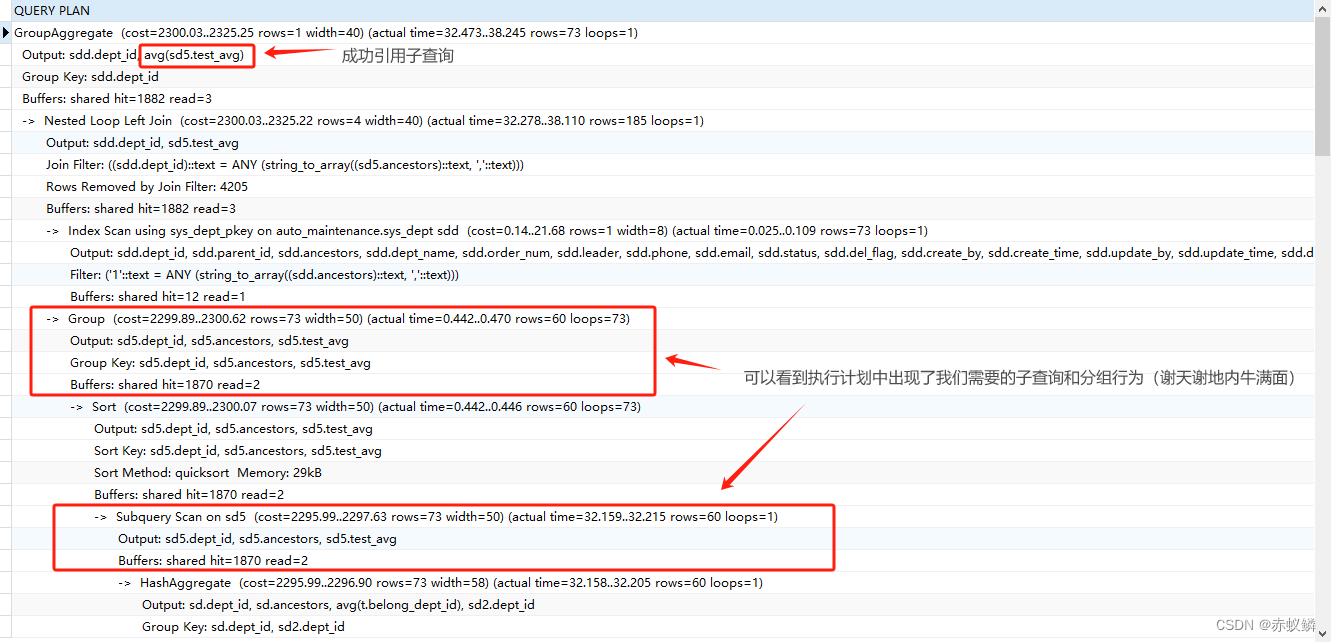
实际上在得出这个结论之前,我进行过多次测试,发现还有一些行为同样可以正常引用到子查询,比方说第 11 行的权限控制过滤SQL,如果去掉这个过滤条件,则子查询还是可以被引用到的。还有数据量的关系,如果得到的数据集行数少于6700(这个数量我不是很肯定,是用 20 条数据的表和 335 条数据的表进行连接测出来的)则子查询同样可以被引用到。
归根结底还是对PostgreSQL数据库的执行计划完全不懂,如果有前辈知道其中原理,劳烦在评论区里点拨一二,十分感谢!!
行为记录
解决耗时:三天
实际耗时:约18小时
价值:中等
具有参考价值的外链:(以下外链未必与本次问题的解决直接相关,但都是我在解决途中记录下来的)
PostgreSQL执行计划的解释_pgsql seq scan on t-CSDN博客















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









