







在这篇博客的基础上进行改进:
Elastic stack 技术栈学习(十一)—— 京东项目实战_bulkresponse.hasfailures()-CSDN博客
升级(一)
只能爬取京东一页的数据,升级爬多页,具体措施:
java pa——jsoup使用教程_java jsoup-CSDN博客
改进后的代码:
@Controller
public class HtmlParseUtil {
// public static void main(String[] args) throws IOException {
// new HtmlParseUtil().parseJD("方便面").forEach(System.out::println);
// }
public List<Good> parseJD(String keywords) throws IOException {
ArrayList<Good> goodsList = new ArrayList<>();
String url = "https://search.jd.com/Search?keyword="+keywords;
//爬取京东100页,差不多30*100 = 3000条数据
for(int page=1;page<=100;page++) {
String temp = 2 * page - 1 + ""; //int 转 string
url = url + "&page=" + temp;
// jsoup解析网页,返回浏览器document对象
Document document = Jsoup.parse(new URL(url), 30000); //url 最长解析时间
Element element = document.getElementById("J_goodsList");
Elements elements = element.getElementsByTag("li");
for (Element el : elements) {
// 找到<img>标签; 找到<li>标签下的第1个<img>标签; 获取其src属性
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
// 找到"p-price"类;找到<li>标签下的第1个"p-price"; 将其内容转为文字
String price = el.getElementsByClass("p-price").eq(0).text();
// 同上
String name = el.getElementsByClass("p-name").eq(0).text();
Good good = new Good();
good.setImg(img);
good.setName(name);
good.setPrice(price);
goodsList.add(good);
// System.out.println(img);
// System.out.println(price);
// System.out.println(name);
}
}
System.out.println("一共获取了"+goodsList.size()+"条数据");
return goodsList;
}
}但是,可以存储多页数据,但是无法展示多页数据。因为展示多页数据的话要靠前端代码实现分页,我不会,狂神给的代码也没有实现分页。不过不用管,咱是做java后端的,后端能获取到成千上万甚至百万、亿级条数据就够了,前端谁爱弄谁弄。
升级(二)
在原版代码中,需要在浏览器地址栏输入以下url先手动把数据爬取出来导入elasticsearch,
http://localhost:8080/parse/java然后再访问
http://loalhost:8080在搜索栏中输入【java】,然后一键点击【搜索】按钮,获取数据
改进: 点击搜索按钮一键实现上述所有操作!这样我们就完全模拟了一个京东商城,登录
http://loalhost:8080 (京东商城发布的地址)后,搜什么出来什么,就和真实的京东一样了(注意,还无法实现中文商品的搜索)。
实现效果:
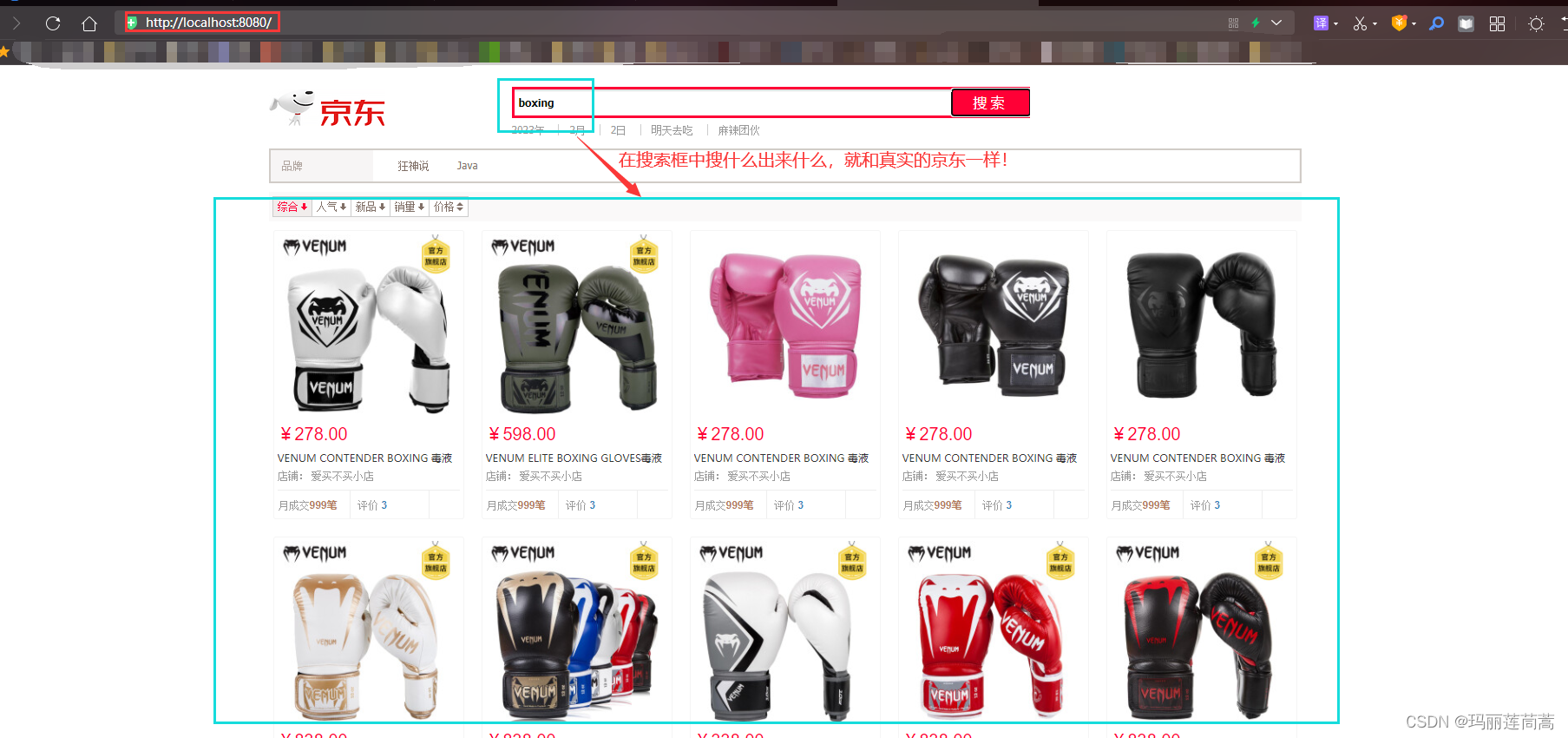
PS:注意,只能输入英文哦~
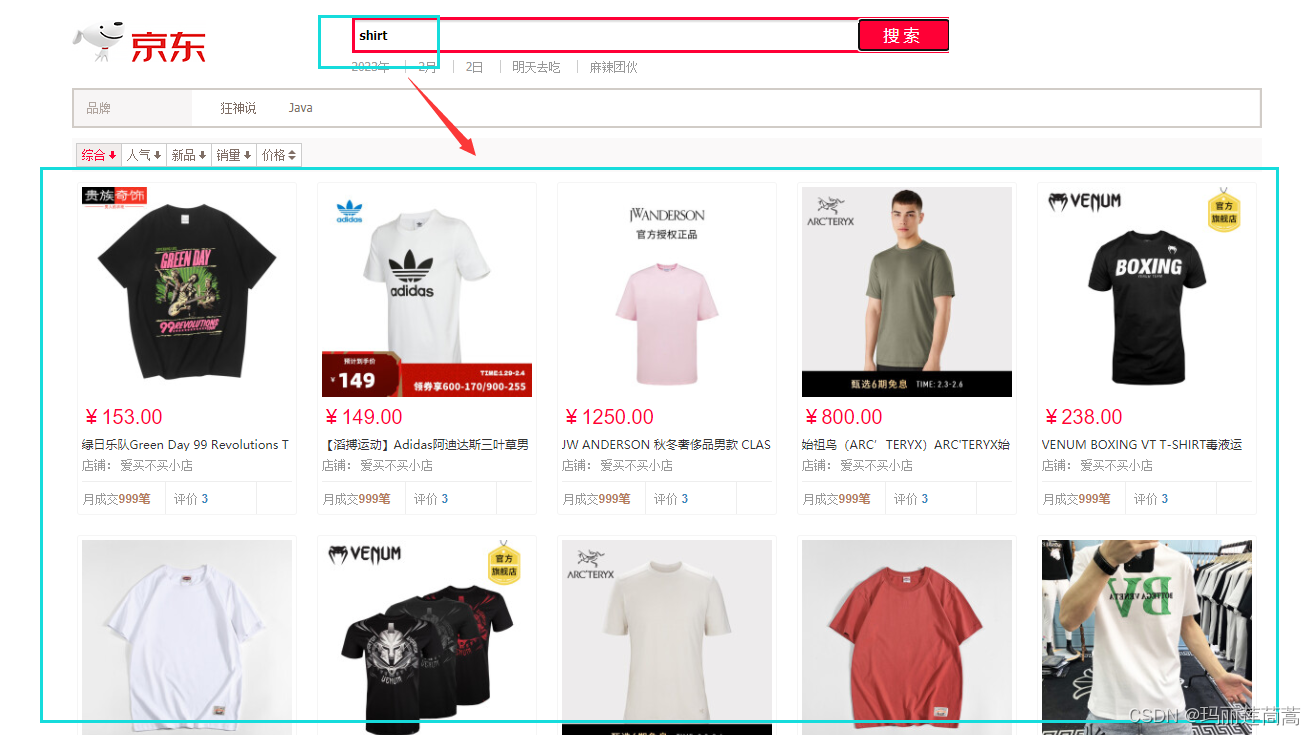
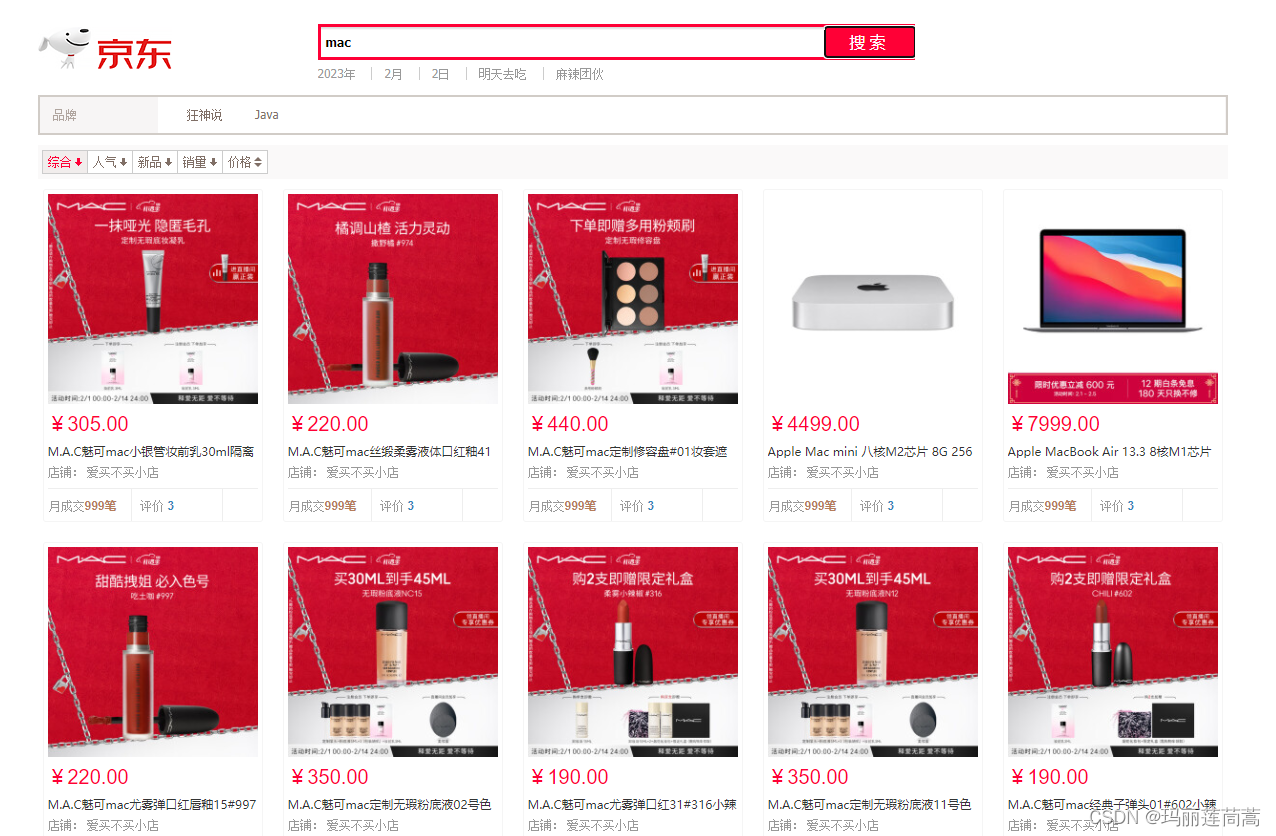
如何改进的:以前在index.html文件里,只调用了‘/search/’这个接口,我们在此之前加上'/parse/'接口的调用即可
/**
* 只要在前端输入一个关键字,就能实现先存再取
* 1)axios.get('/parse/'+keywords) 从京东爬取真实数据,存到elasticsearch里
* 2)axios.get('/search/' + keywords +"/1/20") 从elasticsearch搜索数据,显示到当前前端页面
*/
searchKeywords(){
//var keywords = this.keywords
let keywords = this.keywords; // es6.0之后用let
console.log(keywords); //传递给浏览器的控制台
//-----------------------------新加的部分
axios.get('/parse/'+keywords)//还是借助controller层
.then(response=>{
console.log(response)
})
//-----------------------------over-----------
axios.get('/search/' + keywords +"/1/20") //还是借助controller层
.then(response=>{
console.log(response)
this.results = response.data
})
}但是性能不太好,搜了几次
升级(三)暂时没解决
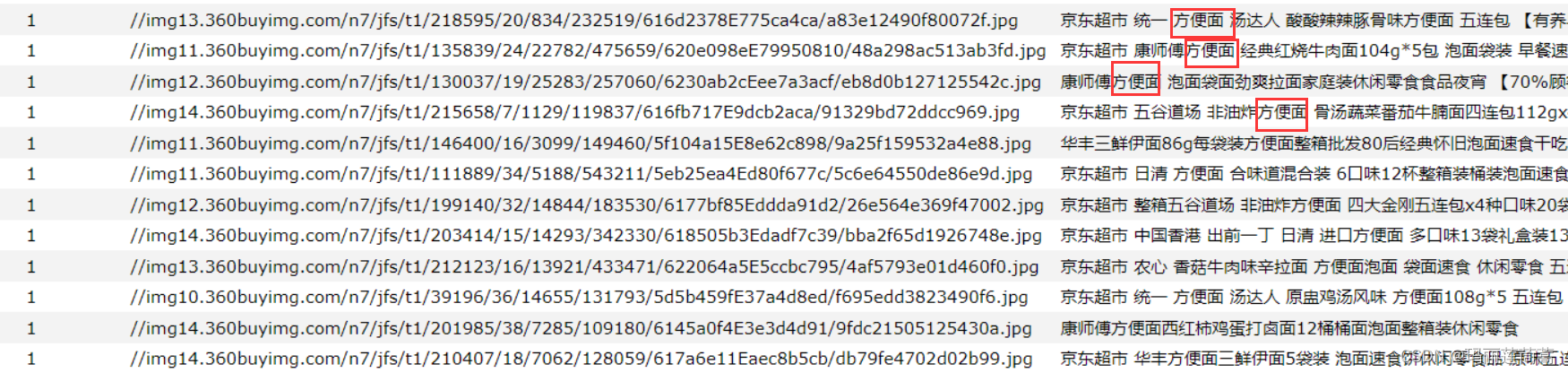
问题:在原版代码中,对于【中文】只能爬取,无法查询。比如我们在浏览器地址栏输入
http://localhost:8080/parse/方便面也就是执行server层的parseContent(“方便面”)方法,
public Boolean parseContent(String keywords)是可以识别中文的,并且结果都存储在了elasticsearch里(如下图)
但是!当我们在浏览器中输入
http://localhost:8080/search/方便面/1/20也就是执行server层的searchContent(“方便面”)方法,
public ArrayList<Map<String,Object>> searchContent(String keywords, int pageOn, int pageSize)什么也搜不出来,说明无法识别中文。
解决:
究其原因,之所以server层-parseContent(“方便面”)方法能够识别中文是因为底层调用了Jsoup的API
String url = "https://search.jd.com/Search?keyword="+keywords;
Document document = Jsoup.parse(new URL(url), 30000); 肯定是人家Jsoup.parse()方法或者new URL(url)本身能够识别中文。
而server层-searchContent(“方便面”)方法无法识别中文,问题就出现在这几行
//精确匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", keywords);
searchSourceBuilder.query(termQueryBuilder);
//client发起请求
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









