







相信大家在听sylar讲协程调度模块时,听完肯定蒙蒙的状态,本人也是。比如有下列疑问:
协程调度是干什么的?能起到什么作用?
use_caller到底指什么意思?为什么感觉那么复杂?
使用caller线程进行调度时,和其他线程调度有什么不同,为什么要区分对待?
每个线程里面有很多协程,怎么样能让协程在线程之间切换?
m_autoStop和m_stopping是什么意思?
添加的调度任务,是指定给那个协程的?
本文记录本文学习过程中的一些理解,当然也参考了很多博客,如:协程调度模块 - 类库与框架 - 程序员的自我修养 (midlane.top),大佬写的非常好,自己结合理解画了一些流程图,也记录了自己的一些理解,希望对大家有帮助,不对的地方请多指正!
个人感觉先把协程调度的大体流程讲清楚,然后在具体讲其中的细节。
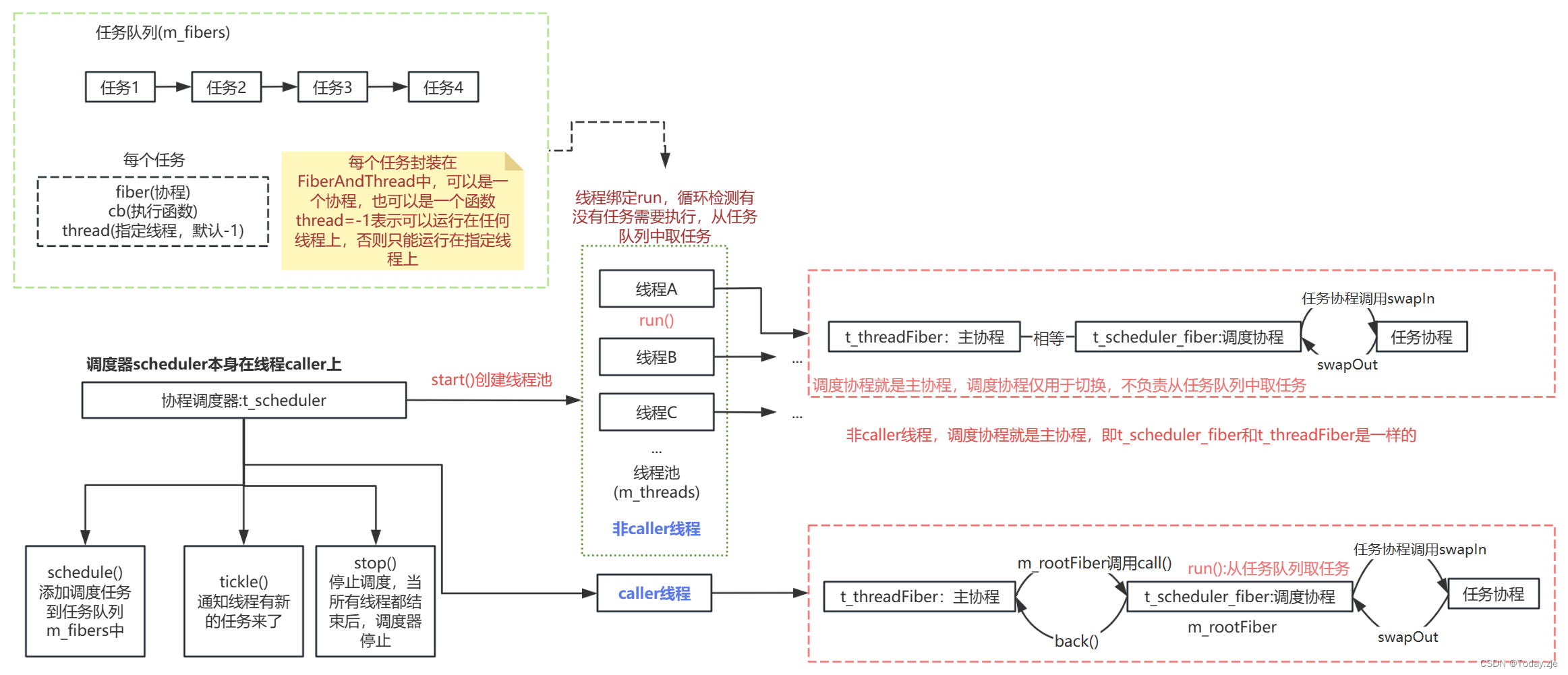
协程调度想实现什么功能
之前《操作系统》学过进程调度,指的是给进程分配处理机,进程调度的策略有先来先服务、短作业优先、时间片轮转等。协程调度也类似,就是给协程分配处理机,不过目前协程调度模块分配处理机的策略是先来先服务。任务队列中有很多任务(协程),调度器将任务队列中的各个任务协程,分配给各个线程中进行执行,这就是协程调度。
大体是下面这个流程(单线程情况下):

详细说明
任务
在sylar实现的协程调度模块中,任务可以是一个协程也可以是一个函数,具体实现中是将两者其封装到FiberAndThread中。
struct FiberAndThread
{
Fiber::ptr fiber; // 协程
std::function<void()> cb; // 任务要执行函数(具体使用是也是将函数封装到协程里)
int thread; // 线程id,可以指定将该任务运行到那个线程上,若不指定则所有线程均可以执行该任务
};
任务队列
存放多个任务,具体实现中存到链表std::list<FiberAndThread> m_fibers中,每次取任务时从链表头部开始遍历寻找可以运行的任务。每次添加任务的时候(schedule方法),将任务添加到链表尾部。(所以调度策略是先来先服务)
调度器
调度器的作用就是从任务队列中取出一个任务,然后交给线程中的任务协程处理。
线程池
因为一个线程同时只能运行一个协程,所以想要提高效率,就必须要用到多线程,sylar实现中维护了一个线程池std::vector<Thread::ptr> m_threads,多个协程在不同的线程上同时运行,线程的数量可在实例化调度器时执行。
锁
因为用到多线程,所以必须要用到锁m_mutex。
run方法
该方法的作用是循环遍历任务队列m_fibers,然后从中找到可以指定的任务,然后交给某一个线程中的协程处理。(此处省略的具体的细节,大体知道run方法的作用即可,后续会详细讨论)
关于是否使用caller线程
caller线程为调度器所在的线程,如果use_caller=true,则表示将调度器所在的线程也用于任务调度,这样在实现相同调度能力的情况下(指能够同时调度的协程数量),线程数越少,线程切换的开销也就越小,效率更高一些。(使用caller线程进行调度就会少开一个线程),是否使用caller线程,对应的处理方式也不同,这里也是比较难理解的地方。
线程创建、线程内创建协程的理解
我们知道协程是轻量化的线程,一个线程可以包含多个协程,但同时只能运行一个协程,既然线程包含协程,那么肯定是先创建线程然后在线程内创建协程,个人理解有两种方式。
例子一:先创建线程,在线程绑定的执行函数内部再创建协程。
// 新建一个线程,名称为test,执行函数为test_fiber
sylar::Thread::ptr(new sylar::Thread(&test_fiber, "test");
// 函数test_fiber具体如下;在test_fiber内部创建协程
void test_fiber()
{
// 一个线程创建后,其执行函数内首先调用GetThis方法,创建一个主协程,用于协程切换
sylar::Fiber::GetThis();
// 创建一个子协程,执行函数为run_in_fiber
sylar::Fiber::ptr fiber(new sylar::Fiber(run_in_fiber));
fiber->swapIn();
// ...
}
void run_in_fiber()
{
// ...
}
例子二:运行main函数创建线程。假如我们有一个test.cc文件,里面有main函数,现在我们运行main函数,相当于开启的一个线程(记为main线程),则如果想在main线程里创建协程,则直接创建就好了。(main函数本身相当于是main线程的执行函数)。
// test.cc
int main(int argc, char **argv)
{
// 调用GetThis方法,创建一个主协程,用于协程切换
sylar::Fiber::GetThis();
// ...
return 0;
}
我介绍该部分,主要是想说明caller线程就相当于上述例子中运行test.cc中main函数得到的线程,非caller线程是通过new Thread的方式创建线程的。
在sylar的实现中,对于caller线程,创建协程时直接调用GetThis()方法即可,而对于非caller线程,也就是线程池里的线程,需要先创建线程(绑定run方法),然后在run方法中创建协程。在代码里你可以详细看到,明白这一点,有助于后面的理解。
任务协程、调度协程、主协程的概念
任务协程:就是我们要运行的任务,可以理解为任务队列中的单个任务。
调度协程(t_scheduler_fiber):在每一个线程中,都会有一个调度协程,调度协程负责从任务队列中取任务,然后调度协程让出执行权,运行任务协程,运行结束后再回到调度协程,如下图所示:

主协程(t_threadFiber):在之前的协程模块中,我们已经知道,对于每一个线程都有一个主协程,主协程用于和任务协程(子协程)进行切换,因为实现的是非对称协程,只能通过主协程和任务协程(子协程)进行切换(是否使用caller协程对应主协程任务也不同,后面会讨论)。
有同学可能就有疑问了
疑问一:调度协程和主协程不是一个东西吗?为什么非要再声明一个调度协程?直接用主协程不就行了吗?
疑问二:调度协程要和任务协程(子协程)切换,另外只能通过主协程和任务协程(子协程)进行切换,所以调度协程就是主协程?
其实是这样的,刚刚说了调度协程负责从任务队列中取任务,这就意味着我必然要给调度协程设置一个执行函数啊。
但是!但是!
在协程类设计时,主协程创建时,并没有给主协程分配栈,也没有给主协程设置执行函数(具体可见Fiber()构造函数),只用于协程之间的切换,所以就导致主协程不能当作调度协程,因为调度协程需要绑定执行run方法,不断从任务队列中取任务,而主协程又不能设置执行函数。所以调度协程和主协程不是一个东西。
接着听我往下讲。记住重点:调度协程需要绑定执行run方法
caller线程和非caller线程的实现区别理解
caller线程:创建调度器的线程,我们在main函数创建了调度器,该caller线程的执行函数就是main函数(对应上边的例子二),如果想使用caller线程进行协程调度,那就需要创建一个调度协程且绑定执行run方法,才能参与协程调度。代码如下:
if (use_caller)
{
// 如果主协程不存在,内部会创建主协程
sylar::Fiber::GetThis();
// 线程池可用数量-1
--threads;
SYLAR_ASSERT(GetThis() == nullptr);
t_scheduler = this;
// m_rootFiber为caller线程中的调度协程,协程绑定run方法
m_rootFiber.reset(new Fiber(std::bind(&Scheduler::run, this), 0, true));
// ...
}
非caller线程:在创建完调度器,调用start方法时会创建线程池,线程池里的线程就是非caller线程,每个非caller线程指定执行函数为run。(对应上边例子一),注意这里run方法绑定到了线程上了,不是协程,在线程上执行run方法不断从任务队列取任务,所以就不用再创建一个调度协程绑定执行run方法了
for (size_t i = 0; i < m_threadCount; ++i)
{
// 线程的执行函数该Scheduler的run方法
// new Thread()方法内部会创建一个线程执行
m_threads[i].reset(new Thread(std::bind(&Scheduler::run, this), m_name + "_" + std::to_string(i)));
m_threadIds.push_back(m_threads[i]->getId());
}
总结就是:
对于caller线程,run方法绑定到了一个子协程上(就是调度协程t_scheduler_fiber)
对于非caller线程,run方法绑定到了线程上,不断从任务队列寻找任务的事情交给了线程,所以就不需要调度协程了,具体实现中,为了复用代码,调度协程就是的主协程。t_scheduler_fiber等于t_threadFiber,仅用于协程之间切换。代码如下:
void Scheduler::run()
{
// ...
// m_rootThread为caller线程的id
if (sylar::GetThreadId() != m_rootThread)
{
// 当前线程如果不是caller线程,需要获取当前线程的调度线程
SYLAR_LOG_DEBUG(g_logger) << "run(): sylar::GetThreadId() != m_rootThread";
// 内部如果没有主协程,则会创建一个主协程,所以调度协程就是主协程
t_scheduler_fiber = Fiber::GetThis().get();
}
// ...
}
idle协程
假设当线程A没有任务可以做,且整个协程调度还没结束(就是说虽然线程A没任务了,但是其他的线程还有任务正在执行,调度还没结束),此时会让线程A执行idle协程(也是一个子协程),idle协程内部循环判断协程调度是否停止。
如果未停止,则将idle协程置为HOLD状态,让出执行权,继续运行run方法内的while循环,从任务队列取任务。(属于忙等状态,CPU占用率爆炸)
如果已经停止,则idle协程执行完毕,将idle协程状态置为TERM,协程调度结束。
伪代码如下:
void Scheduler::idle()
{
while (!stopping())
{
// 当stopping()为false,也就是调度还没停止,还有活跃的线程,将idle进程挂起,状态转为Hold
sylar::Fiber::YieldToHold();
}
// 当stopping()为true,没有任务要执行了,执行完idle,状态置为TERM
}
void Scheduler::run()
{
// 前置操作..
// 没有任务时执行的协程,默认状态为INIT
Fiber::ptr idle_fiber(new Fiber(std::bind(&Scheduler::idle, this)));
// ... 定义必要的变量
while (true)
{
// 从任务队列里寻找任务
if (找到任务)
{
// 执行任务
}
else
{
// 未找到任务
// idle的状态为结束TERM(当所有协程调度任务完成)
if (idle_fiber->getState() == Fiber::TERM)
{
// 执行结束,while循环的唯一退出条件
SYLAR_LOG_INFO(g_logger) << "idle fiber term";
break;
}
// 没有任务可以执行,则执行idle协程
idle_fiber->swapIn();
}
}
}
整体流程图:
协程之间的切换问题
参考:协程调度模块 - 类库与框架 - 程序员的自我修养 (midlane.top)
考虑两种情况:
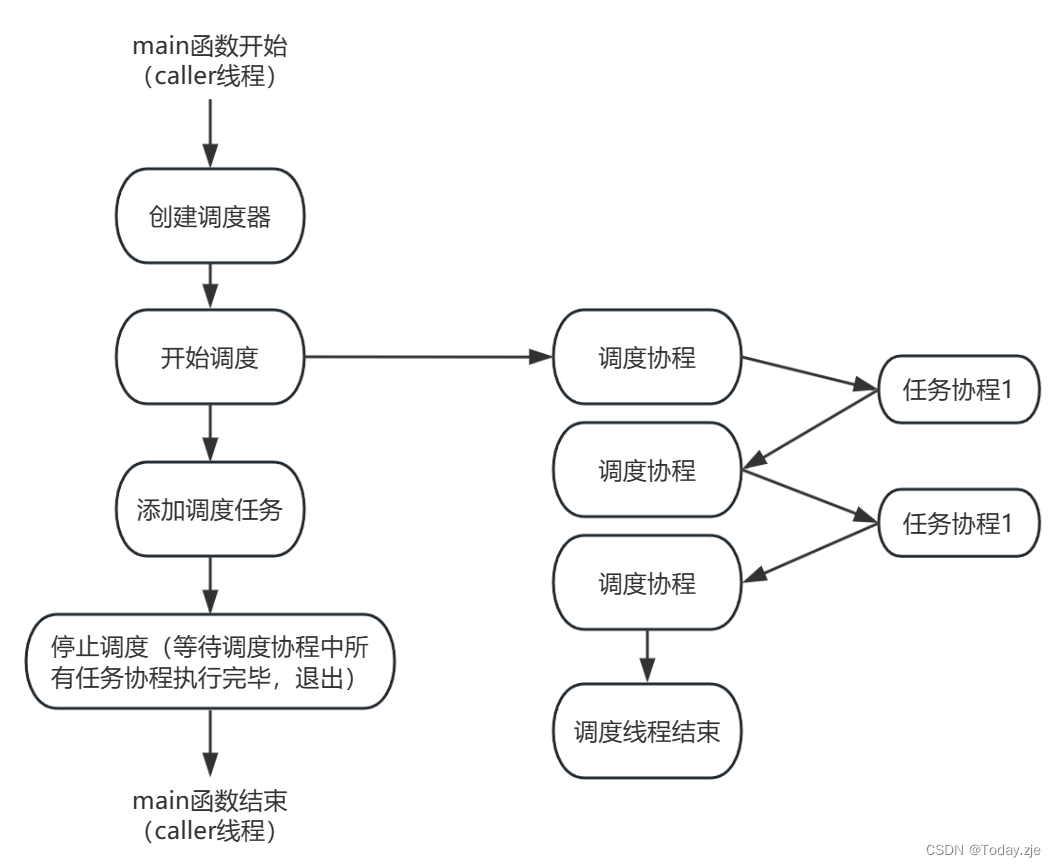
情况一:use_caller=false(调度器所在线程不参与调度),仅有一个线程。会创建一个调度协程来进行协程调度,主协程就是调度协程。
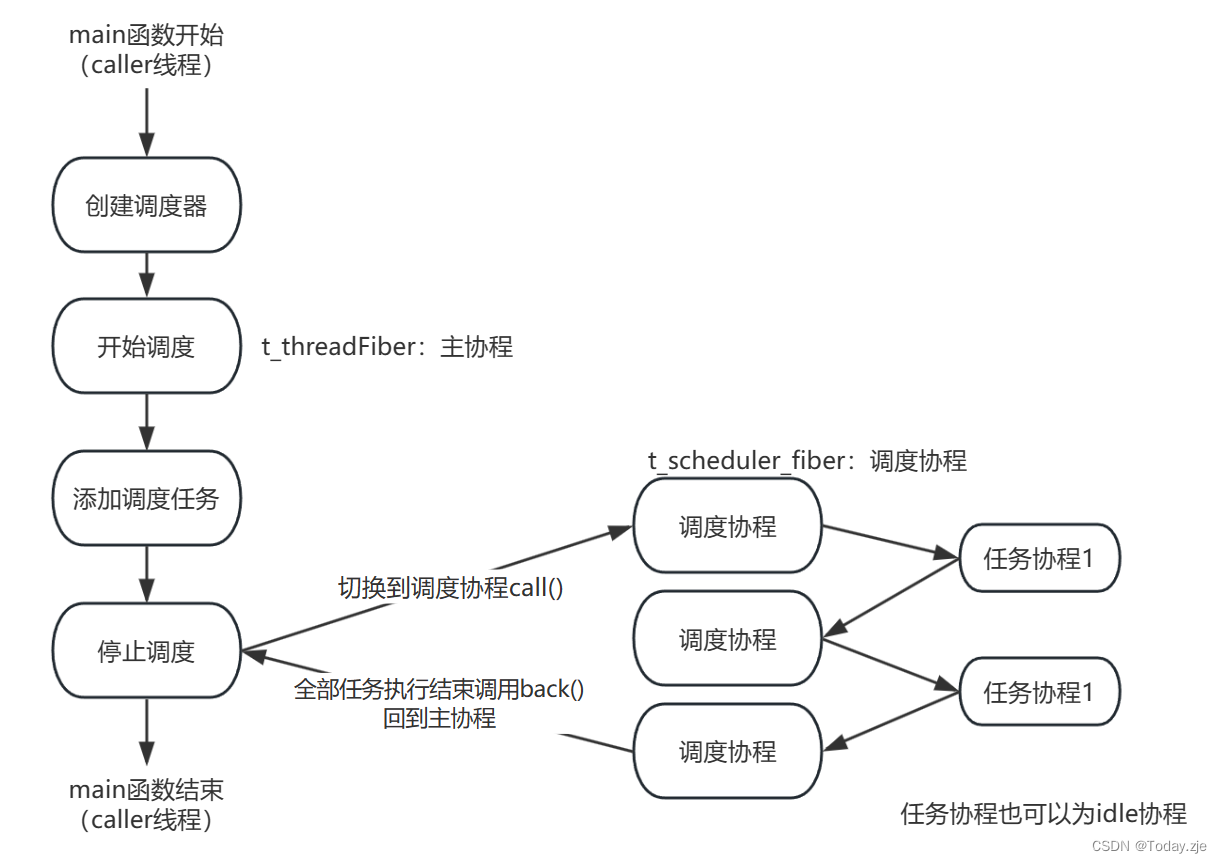
情况二:use_caller=true(调度器所在线程参与调度),仅有一个线程,则不会创建其他线程,仅有caller线程进行调度。
对于情况一,不使用caller线程,新建一个线程,将新线程执行函数绑定为run(),线程负责从任务队列中取任务,进行协程调度。caller线程只需要向任务队列中添加任务即可。当调度器停止时,caller线程等待调度线程中所有协程执行完毕在退出,过程如下图所示。
对于情况二,流程大致如下
创建调度器,初始化调度器时创建主协程
t_threadFiber。创建调度协程
t_scheduler_fiber(m_rootFiber),绑定run方法。
start()方法开启协程调度(因为只有caller线程,内部实际什么都没做)。
schedule()方法向任务队列中添加任务。
stop()方法停止调度,内部会检测到调度协程t_scheduler_fiber(m_rootFiber)不为空,执行m_rootFiber->call();,主协程让出执行权,切换到调度协程执行,从任务队列取任务执行。每次执行任务,调度协程都要让出执行权,去执行任务协程,任务执行结束后,切换到调度协程,继续下一个任务调度。
让所有任务执行完成,调度协程要让出执行权回到主协程,以保证程序正常结束。
过程如下:
实现细节
大体流程
调度器创建:内部首先创建一个调度线程池,调度开始后,所有调度线程按顺序从任务队列里取任务执行,调度线程数越多,能够同时调度的任务也就越多,当所有任务都调度完后,调度线程就停下来等新的任务进来。
开启调度:调用start方法后会创建线程池,调度线程一旦创建,就会从任务队列中取任务执行。
调度协程负责从调度器的任务队列中取任务执行。取出的任务即子协程,这里调度协程和子协程的切换模型即为前一章介绍的非对称模型,每个子协程执行完后都必须返回调度协程,由调度协程重新从任务队列中取新的协程并执行。如果任务队列空了,那么调度协程会切换到一个idle协程,这个idle协程什么也不做,等有新任务进来时,idle协程才会退出并回到调度协程,重新开始下一轮调度。
添加调度任务:往调度器的任务队列添加任务,可以执行任务放到那个线程上执行,但是,只添加调度任务是不够的,还应该有一种方式用于通知调度线程有新的任务加进来了(tickle()),实际该方法啥也没做,因为调度线程并不一定知道有新任务进来了。当然调度线程也可以不停地轮询有没有新任务,但是这样CPU占用率会很高(sylar实现就是不断轮询,如何实现通知调度协程任务来了,观察者模式?)。
调度器停止:停止调度,当所有的调度线程都结束后(join阻塞等待),调度器才算真正停止。
调度器停止条件
bool Scheduler::stopping()
{
MutexType::Lock lock(m_mutex);
return m_autoStop && m_stopping && m_fibers.empty() && m_activeThreadCount == 0;
}
// m_autoStop=true 调用stop方法后将m_autoStop置为true;感觉可以理解为是否调用了stop方法,true表示调用了
// m_stopping=true 是否正在停止
// m_fibers.empty()==true 任务队列为空
// m_activeThreadCount == 0 正在执行任务的线程数为0
// 均满足,返回true
void Scheduler::stop()
{
m_autoStop = true;
if (m_rootFiber && m_threadCount == 0 && (m_rootFiber->getState() == Fiber::TERM || m_rootFiber->getState() == Fiber::INIT))
{
SYLAR_LOG_INFO(g_logger) << this << " stopped";
m_stopping = true;
if (stopping())
{
return;
}
}
if (m_rootThread != -1)
{
// 未使用caller线程
SYLAR_ASSERT(GetThis() == this);
}
else
{
// 使用caller线程
SYLAR_ASSERT(GetThis() != this);
}
m_stopping = true;
for (size_t i = 0; i < m_threadCount; ++i)
{
// 通知还有任务,其实啥也没做
tickle();
}
if (m_rootFiber)
{
tickle();
}
if (m_rootFiber)
{
// 如果调度器只使用了caller线程来调度,那caller调度器真正开始执行调度的位置就是这个stop方法
// 如果使用了caller线程,需要将caller线程再执行一下
if (!stopping())
{
m_rootFiber->call();
}
}
std::vector<Thread::ptr> thrs;
{
// 遍历线程池
MutexType::Lock lock(m_mutex);
thrs.swap(m_threads);
}
for (auto &i : thrs)
{
// 阻塞等待所有线程执行完毕,才能停止
i->join();
}
}
其他注意事项
遍历任务队列时,需要判断任务的状态和线程id(如判断该任务协程自己是否能执行,任务协程是否正在运行)。
任务协程让出执行权后,需要判断任务协程的状态,若未执行完毕,需要重新假如到任务队列中(这里可能需要改进,因为协程未执行完毕,需要调度器来将未执行完的协程重新放入任务队列中,如果说协程自己把自己放入任务队列,然后再释放执行权会比较好,好的协程要学会自己管理自己)。
让出执行权前,活跃线程数+1,回来之后,活跃线程数-1;
检测是否使用了caller线程进行调度,如果使用了caller线程进行调度,那要保证stop方法是由caller线程发起的。
如果使用caller协程,即use_caller=true,对于caller协程,内部实现中绑定的是CallerMainFunc方法,执行完函数后,内部调用back切换到主线程。非caller协程,内部实现中绑定MainFunc,执行完函数后,内部调用swapOut切换回调度协程。
疑问 and 存在问题:
任务队列空闲时,调度协程进入idle协程,忙等待的问题,实际并不实用。代码中看到有方法tickle()其作用是通知线程有任务来了,感觉当一个线程空闲时,不要让其处于忙等状态,可以阻塞再idle协程上,然后有任务来时调用tickle()通知线程,该如何实现?一个协程阻塞会不会导致整个线程阻塞?
目前我的理解来看,有若干任务放到任务队列里,然后有多个线程同时从任务队列取任务,放到各自协程中执行(目前看使用的策略是先来先服务),类似于进程调度或者线程调度,我不理解的地方是协程调度相比与使用进程、线程调度有优势在那里?或者有没有一种实际情况用协程处理比较合适(之前听过IO多路复用但是还不理解)
m_stopping表达的意思是“是否正在停止”,值为true表示正在停止,值为false表示不是正在停止。sylar中部分代码true、false好像写反了。















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









