






关于浏览器下载文件名乱码问题
在Web开发中,我们会写下面的(本文我以Chrome浏览器讲解,旨在讲解一些底层原理,为什么乱码,由于不同浏览器解码不同,所以我选择了Chrome为基础讲解)
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// req.setCharacterEncoding("utf-8");//设置获取参数的格式,但如果是Get方式不写特不会乱码,本次测试我没写
String filename = req.getParameter("filename");//获取参数filename
ServletContext servletContext = this.getServletContext();//获取域对象
String mimeType = servletContext.getMimeType(filename);//获取Mime数据格式
resp.setContentType(mimeType);//设置响应头
resp.setHeader("content-disposition","attachment;filename="+filename);//这一步我标号为①
String path = servletContext.getRealPath("image/"+filename);
System.out.println(path);
ServletOutputStream outputStream = resp.getOutputStream();
System.out.println("图片");
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream(path);
} catch (FileNotFoundException e) {
e.printStackTrace();
return;
}
byte[] bt = new byte[1024 * 1024];
fileInputStream.read(bt, 0, bt.length);
fileInputStream.close();
outputStream.write(bt, 0, bt.length);
outputStream.close();
}
在①这一步会发生这样的事情,Tomcat会默认的把(注意这里的编码格式不是content-type里设置来确定的)filename以ISO-8859-1转化为二进制流数据保存在响应头content-dispositin中然后给Chrome,Chrome会以UTF-8解码然后放在响应头中,之后在从刚刚放的响应头中再解码一次才是最终的文件名。过程如下图解如下:
代码模拟这一过程:
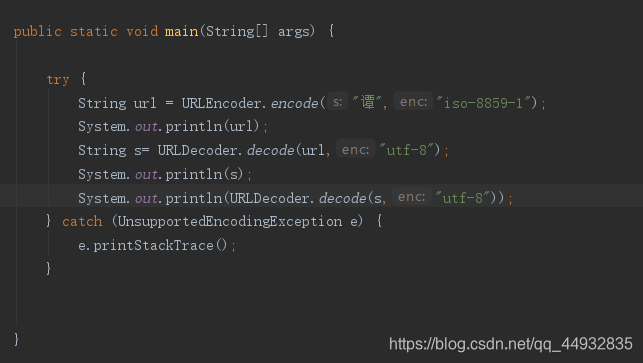
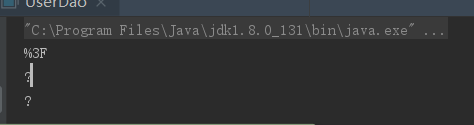
在浏览器中:
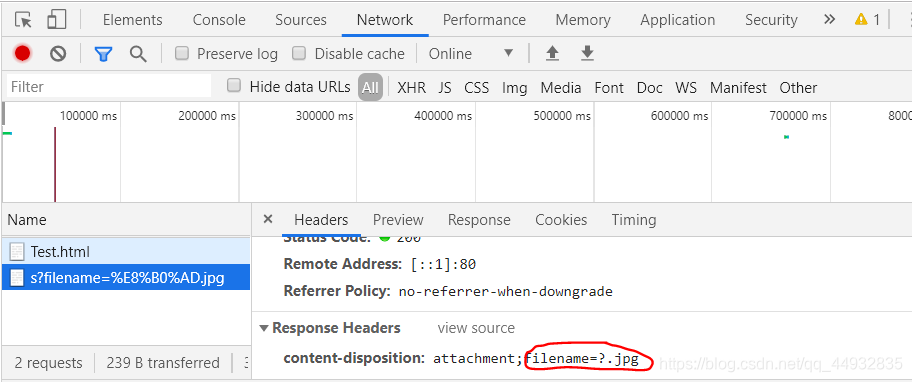
解决办法:在①前加上:
filename = URLEncoder.encode(filename, "utf-8");
代码模拟这一过程:
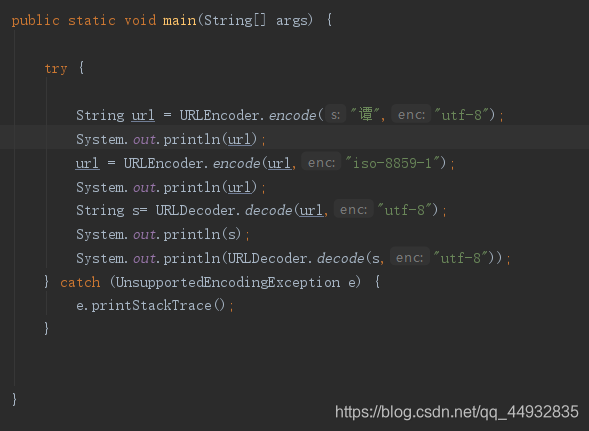
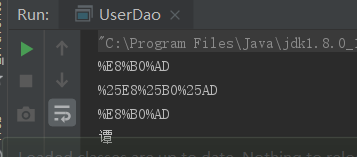
浏览器结果:
不同浏览器解码方式不同,但原理一样。















 1503
1503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









