






 博主通过Python将大量CSV数据切分为15个小文件并导入数据库,以解决数据处理问题。首先尝试使用SQL计算服务器价格方差,但由于数据量大导致耗时过长而放弃。接着,博主改为计算服务器在一个月内的价格变化次数作为波动指标,此方法执行快速,最终得到包含服务器地区、实例类型等信息的结果表,并按变化次数排序,能快速查询到价格波动最剧烈的服务器。
博主通过Python将大量CSV数据切分为15个小文件并导入数据库,以解决数据处理问题。首先尝试使用SQL计算服务器价格方差,但由于数据量大导致耗时过长而放弃。接着,博主改为计算服务器在一个月内的价格变化次数作为波动指标,此方法执行快速,最终得到包含服务器地区、实例类型等信息的结果表,并按变化次数排序,能快速查询到价格波动最剧烈的服务器。
上面提到我已经获取了1个G的数据文件,下面的工作就是如何应对这个庞然大物,从其中分析出价格变化最大的服务器。我的想法是把所有数据导入数据库,用强大的检索查找能力来完成这项工作。
我将csv文件按照每1000000条数据为单位划分成若干个csv文件,共计15个(采用python完成),速度非常可观。接着我对每个csv文件进行去重操作,总计还剩700多万条数据。
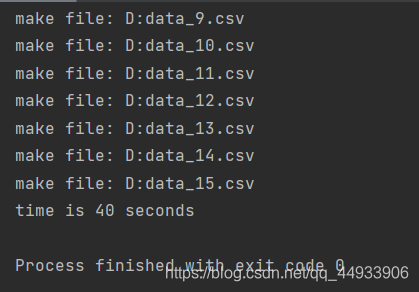
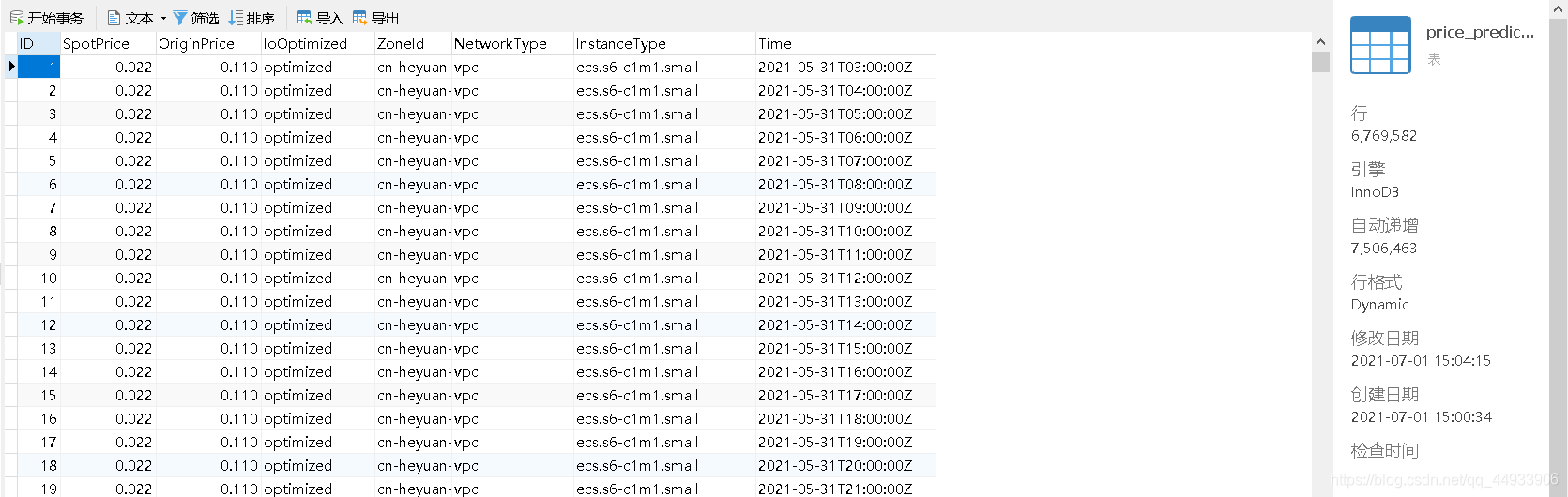
用Navicat将所有csv文件导入数据库
起初我想计算每个服务器所有时刻的价格均值,然后计算出服务器的价格方差,利用方差来衡量服务器价格波动的剧烈程度。然而由于数据量的庞大,sql语句计算方差耗时巨大,我被迫放弃了这种方案。
随后我想到了另一种方案,计算出每个服务器在一个月内价格变化的次数,利用变化次数的多少来衡量价格波动情况。这种方案的sql语句运行较快,只用了100多秒就成功得到结果。
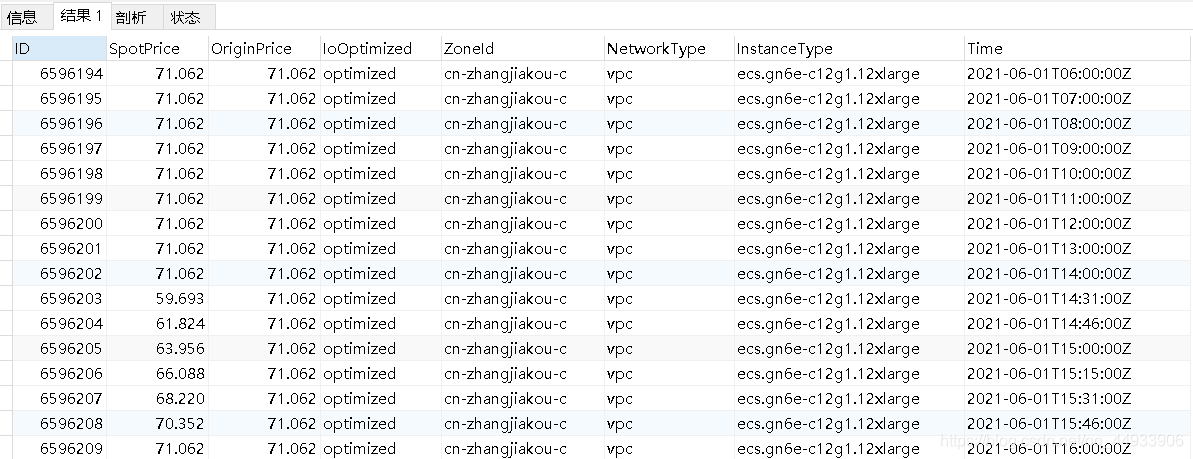
我将结果保存为res表,其中存放了10000多个服务器的地区,实例类型,IO优化情况,网络类型,一个月内采样均价,一个月内价格变化次数。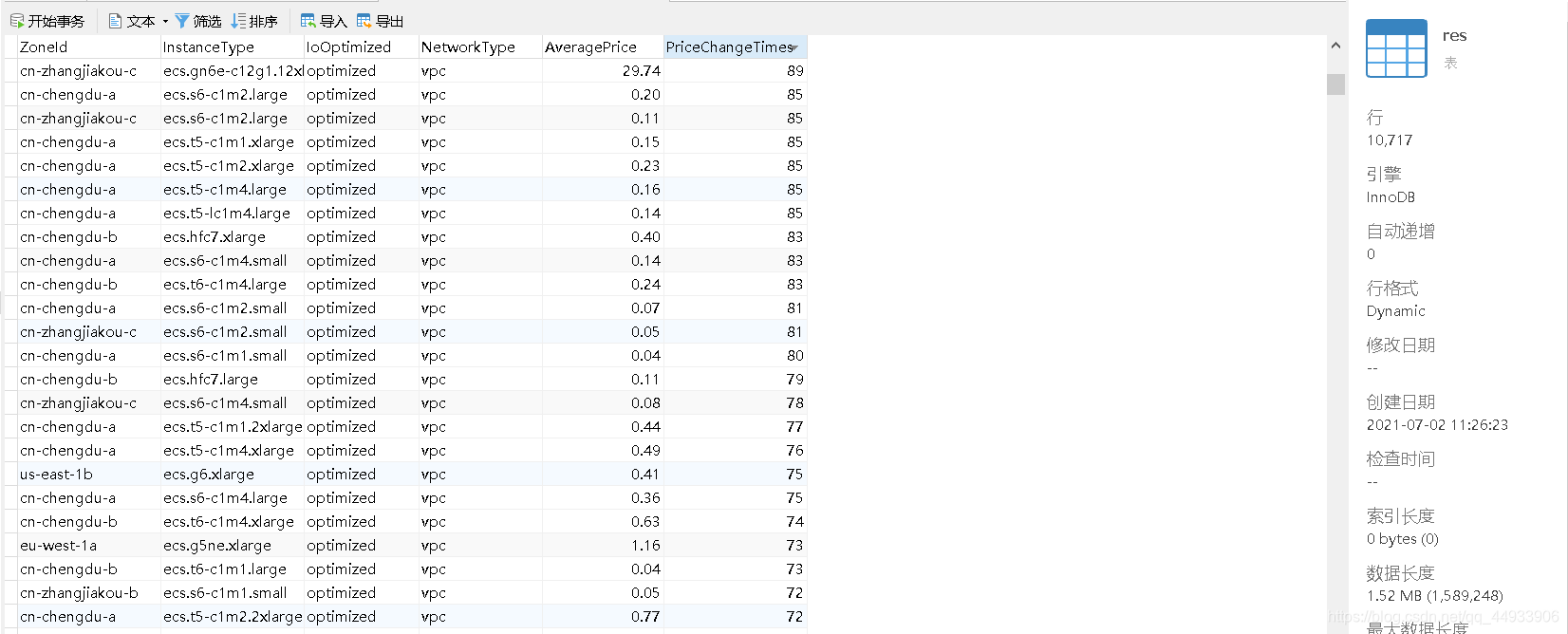
将数据按照价格变化次数排序,取出排名靠前数据的详细信息,再到包含所有数据的表中查询,仅用时五秒即可获得该服务器每次采样的具体价格(SpotPrice)。
![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









