







刘二大人 PyTorch深度学习实践 笔记 P8 加载数据集
P8 加载数据集
1、mini-batch产生的原因
随机梯度下降: 只用一个样本,具有较好的随机性,可以克服鞍点的问题,但训练时间比较长
batch: 最大化利用向量计算的优势,提升计算的速度,但性能上会遇到一些问题
解决办法: 使用mini-batch来均衡速度和性能上的需求
2、DataLoader工作过程
先通过shuffle打乱数据,再将数据分成mini-batch大小
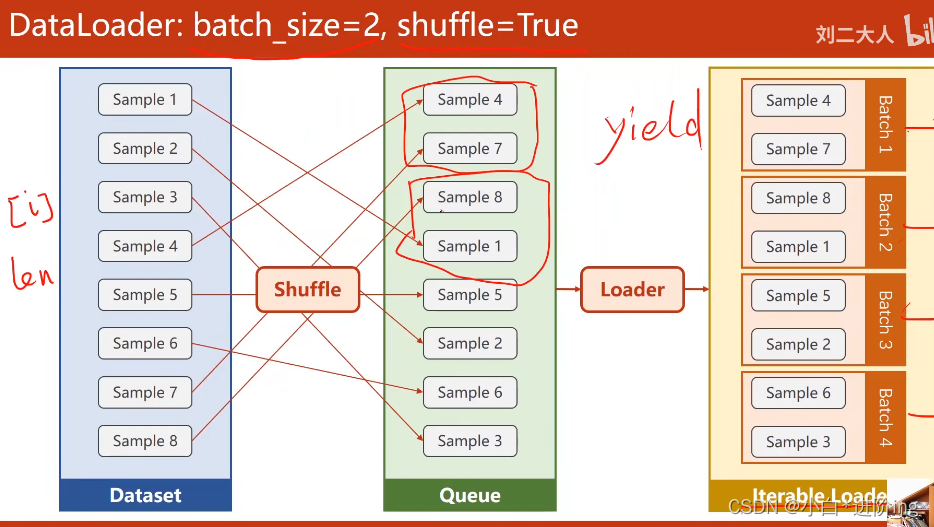
3、代码实现
import torch
import numpy as np
# 两个帮助加载数据的工具类
from torch.utils.data import Dataset # 构造数据集,支持索引
from torch.utils.data import DataLoader # 拿出一个mini-batch的一组数据以供训练
import matplotlib.pyplot as plt
# Dataset是一个抽象类,不能被实例化,只能被子类去继承
# 自己定义一个类,继承自Dataset
class DiabetesDataset(Dataset):
# init()魔法方法:文件小,读取所有的数据,直接加载到内存里
# 如果文件很大,初始化之后,定义文件列表,再用getitem()读出来
def __init__(self, filepath):
# filepath:文件路径
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # xy.shape = (n, 9) 0表示知道多少行,即数据集长度
self.x_data = torch.from_numpy(xy[:, :-1]) # 所有行,前八列
self.y_data = torch.from_numpy(xy[:, [-1]]) # 所有行,最后一列
# getitem()魔法方法:实例化类之后,该对象把对应下标的数据拿出来
def __getitem__(self, index):
return self.x_data[index], self.y_data[index] # 返回的是元组
# len()魔法方法:使用对象时,可以对数据条数进行返回
def __len__(self):
return self.len # 759
dataset = DiabetesDataset('dataset/diabetes.csv.gz')
# DataLoader是一个加载器,用来帮助我们加载数据的,可以进行对象实例化
# 知道索引,数据长度,就可以自动进行小批量的训练
# dataset:数据集对象 batch_size:小批量的容量 shuffle:数据集是否要打乱
# num_workers:读数据是否用多线程并行读取数据,一般设置4或8,不是越高越好
# 此处因为本人电脑CPU限制,线程设置为0,否则会报错
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True,
num_workers=0)
# 定义模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 需要放在if/封装一下,否则在windows系统中会报错
if __name__ == '__main__':
loss_list = []
# epoch:训练周期,所有样本都参与训练叫做一个epoch
for epoch in range(100):
# lteration:迭代次数 = 样本总数 / mini-batch
# eg: 10000个样本, batch-size = 1000个, Iteration = 10次
# 内层每一次跑一个mini-batch
for i, (inputs, labels) in enumerate(train_loader, 0):
# enumerate() 用于可迭代/可遍历的数据对象组合为一个索引序列
# 同时列出数据和数据下标,0表示从索引从0开始
# inputs,label会自动转换成tensor类型的数据
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss.item())
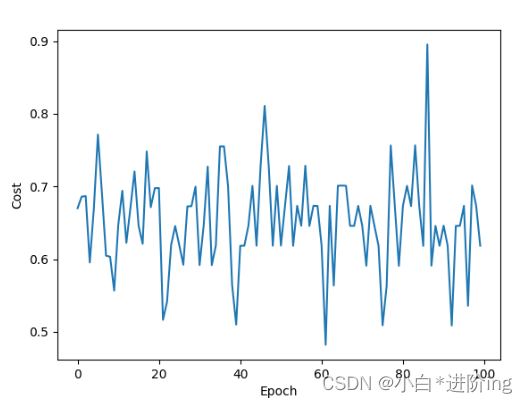
plt.plot(range(100), loss_list)
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.show()
输出:
...
98 0 0.564204752445221
98 1 0.6629743576049805
98 2 0.5637972354888916
98 3 0.6631717681884766
98 4 0.7029669284820557
98 5 0.6035494804382324
98 6 0.6234502792358398
98 7 0.5834643840789795
98 8 0.7233830690383911
98 9 0.663110613822937
98 10 0.7231361269950867
98 11 0.5837068557739258
98 12 0.6431715488433838
98 13 0.6827366352081299
98 14 0.60354083776474
98 15 0.7226895093917847
98 16 0.5838867425918579
98 17 0.6235294342041016
98 18 0.6431921720504761
98 19 0.6435189843177795
98 20 0.7230058908462524
98 21 0.6828587651252747
98 22 0.6037335991859436
98 23 0.673571765422821
99 0 0.6236145496368408
99 1 0.6234683394432068
99 2 0.6431238651275635
99 3 0.6827008128166199
99 4 0.7026492357254028
99 5 0.6828118562698364
99 6 0.7220567464828491
99 7 0.6038920879364014
99 8 0.5842884182929993
99 9 0.6236342787742615
99 10 0.6630747318267822
99 11 0.6037428975105286
99 12 0.6429885029792786
99 13 0.6627420783042908
99 14 0.7423494458198547
99 15 0.6827110648155212
99 16 0.6235508918762207
99 17 0.7024604678153992
99 18 0.7023466229438782
99 19 0.5258728265762329
99 20 0.6827645897865295
99 21 0.5847006440162659
99 22 0.5449429750442505
99 23 0.6185333728790283
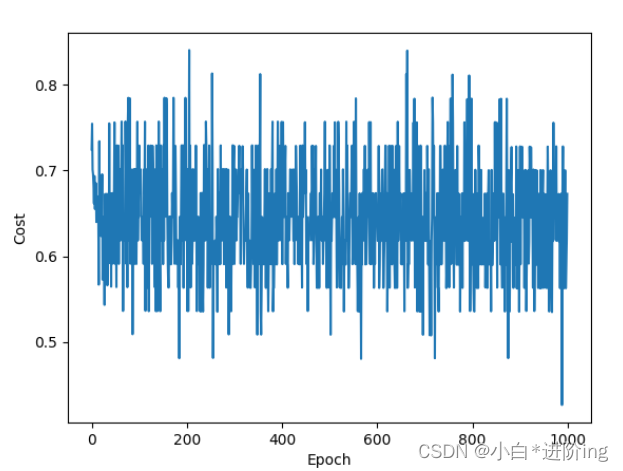
增加训练次数到1000
4、练习
使用MNIST Dataset
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
train_dataset = datasets.MNIST(root='dataset/minist', train=True,
transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='dataset/mnist', train=False,
transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=True)
5、作业
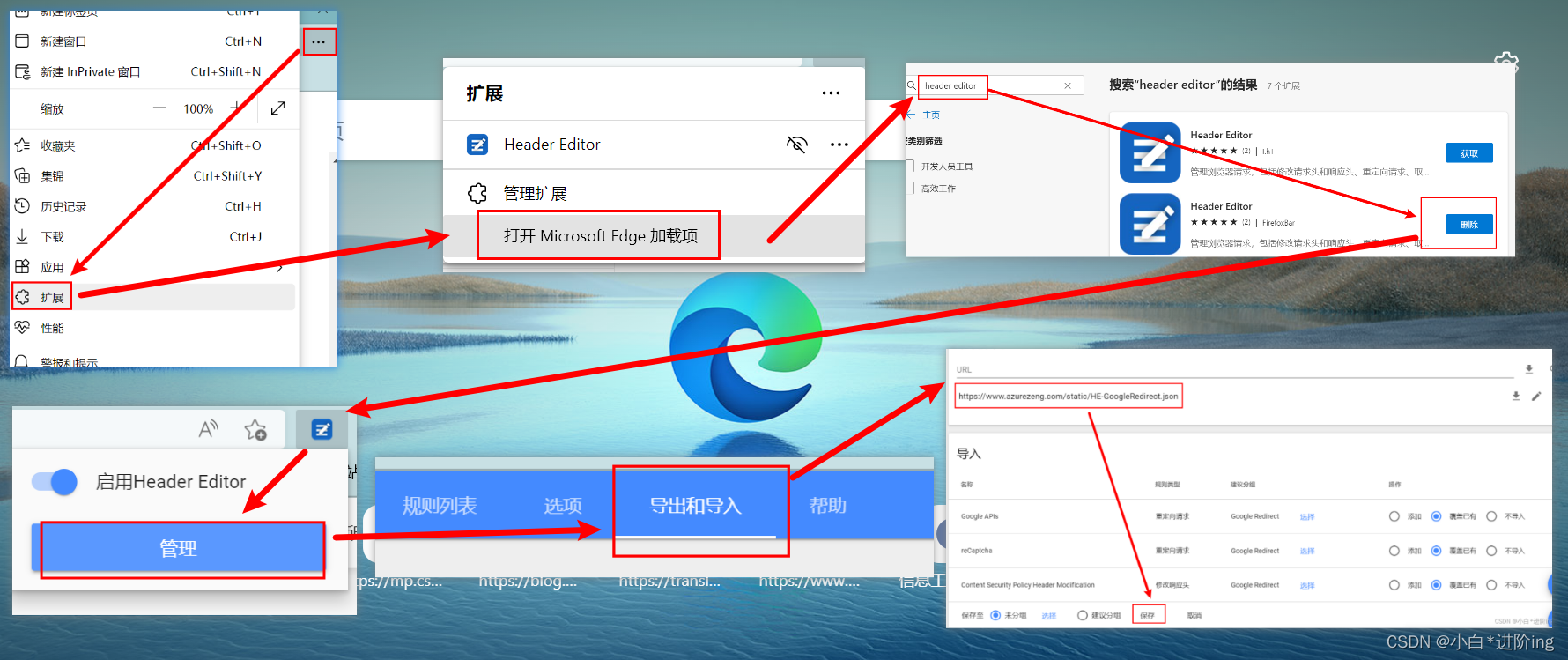
I 解决注册Kaggle无人机验证问题
- 打开Microsoft Edge浏览器
- 右上角三个点选择扩展
- 选择打开Microsoft Edge加载项
- 搜索Header Editor,选择第二个点击获取
- 再点击扩展图标选择Header Editor管理
- 选择导出和导入
- 在URL输入网址https://www.azurezeng.com/static/HE-GoogleRedirect.json
- 点击下载、保存
- 再在浏览器地址栏输入kaggle进入注册页面就会出现人机验证选项,完美解决!
II 使用Titanic数据集
先将训练集和测试集下载好,下载网址:https://www.kaggle.com/c/titanic/data
代码实现:
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
class TitanicDataset(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
self.len = xy.shape[0]
# 选取相关的数据特征
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
# 先进行独热表示,然后转化成array,最后再转换成tensor矩阵
self.x_data = torch.from_numpy(np.array(pd.get_dummies(xy[feature])))
self.y_data = torch.from_numpy(np.array(xy["Survived"]))
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = TitanicDataset('dataset/titanic/train.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(6, 3)
self.linear2 = torch.nn.Linear(3, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
def test(self, x):
with torch.no_grad():
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
y = []
for i in x:
if i > 0.5:
y.append(1)
else:
y.append(0)
return y
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
if __name__ == '__main__':
loss_list = []
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader, 0):
inputs = inputs.float()
labels = labels.float()
y_pred = model(inputs)
y_pred = y_pred.squeeze(-1)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss.item())
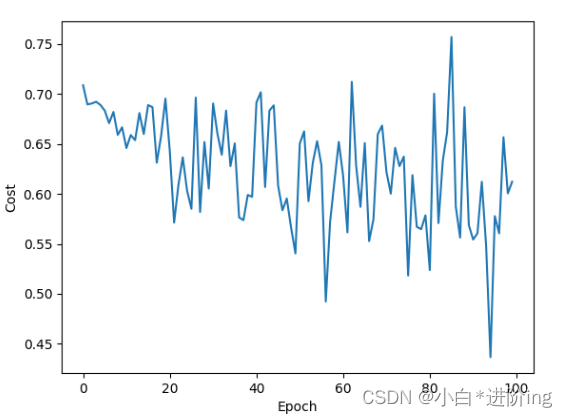
plt.plot(range(100), loss_list)
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.show()
# 测试
test_data = pd.read_csv('dataset/titanic/test.csv')
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[feature])))
y = model.test(test.float())
# 输出预测结果
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': y})
output.to_csv('my_predict.csv', index=False)
输出:
...
97 27 0.6567738056182861
98 0 0.573180615901947
98 1 0.6233570575714111
98 2 0.5645648837089539
98 3 0.5094355344772339
98 4 0.5878120064735413
98 5 0.5655866861343384
98 6 0.5232588052749634
98 7 0.5455686450004578
98 8 0.5780489444732666
98 9 0.5971747040748596
98 10 0.5638140439987183
98 11 0.6441144943237305
98 12 0.5995449423789978
98 13 0.7133046388626099
98 14 0.5324186682701111
98 15 0.540938675403595
98 16 0.6539331674575806
98 17 0.5840151906013489
98 18 0.5795853734016418
98 19 0.6333624124526978
98 20 0.6103789210319519
98 21 0.6049869060516357
98 22 0.6752082109451294
98 23 0.6137862205505371
98 24 0.5124465823173523
98 25 0.5153355598449707
98 26 0.5360470414161682
98 27 0.6005450487136841
99 0 0.5178604125976562
99 1 0.5077474117279053
99 2 0.5932661890983582
99 3 0.6284676790237427
99 4 0.671402633190155
99 5 0.6305621862411499
99 6 0.6018837094306946
99 7 0.5711438655853271
99 8 0.6675225496292114
99 9 0.5513409376144409
99 10 0.5855227112770081
99 11 0.5279020667076111
99 12 0.5582211017608643
99 13 0.6686149835586548
99 14 0.556044340133667
99 15 0.6131739616394043
99 16 0.6314656734466553
99 17 0.5938730239868164
99 18 0.6273018717765808
99 19 0.5895856022834778
99 20 0.5999583601951599
99 21 0.5213016867637634
99 22 0.5114009380340576
99 23 0.5910142660140991
99 24 0.5049216747283936
99 25 0.5323103666305542
99 26 0.5947215557098389
99 27 0.6122090816497803















 2886
2886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











