







Efficient Estimation of Word Representations in Vector Space 论文精读
Information
时间:2013
会议:ICLR
作者:Tomas Mikolov Kai Chen Greg Corrado Jeffrey Dean
Title
向量空间中词表示的有效估计
Abstract
- 提出了两种新颖的模型体系结构,用于计算来自非常大的数据集的单词的连续矢量表示
- 精度大幅提高,计算成本大幅降低,语法和语义相似度测试集上表现较好
- eg: 从16亿个单词数据集中学习高质量的单词向量只需不到一天的时间
1 Introduction
简单模型(单词视为原子,没有相似性的概念)
- eg:n-gram 几乎可用于所有可用数据
优点:
- 简单性
- 健壮性
- 在大量数据上训练的简单模型胜过在较少数据上训练的复杂系统模型
缺点:
- 训练数据有限
- 无法解决词与词之间的相似度的计算
- 数据集质量较差
复杂模型
- 在更大的数据集上训练更复杂的模型
- 克服简单模型的缺点,性能优于简单模型
- 相似的单词会趋于彼此接近,而且单词可以具有多个相似度
- eg: 使用单词的分布式表示、基于神经网络的语言模型
1.1 Goals of the Paper
- 介绍一些用于从具有数十亿个单词和数百万个单词的庞大数据集中学习高质量的单词向量的技术
- 期望: 相似的词趋向于彼此接近,词可以有多个相似度
- 该现象上下文中可以观察到
- 句法规则:名词可以有多个词尾
- 代数运算的单词偏移技术向量
-
- “国王”)- 向量(“男人”)+ 向量(“女人”)产生 最接近单词 (“皇后”) 的向量
- 保留单词间的线性规律性,试图开发新的模型体系结构来提高向量运算的准确性
- 设计一个新的综合测试集来度量句法和语义的规律性,并证明了许多这样的规律性可以被高精度地学习
- 讨论训练时间和精度如何依赖于词向量的维数和训练数据量
1.2 Previous Work
- 词汇表示为连续向量,利用模型参数化的方式构造语言模型,直接从语言模型出发,将模型最优化的问题转换为词向量求解的过程
- 前馈神经网络语言模型 NNLM: 具有线性投影层 + 非线性隐层的 前馈神经网络 来联合学习词向量表示和统计语言模型
- 另一个有趣的NNLM体系结构: 第一次使用具有单个隐藏层的神经网络来学习词向量
- 不构造完整的NNLM也可以学习单词向量
2 Model Architectures
常见的用于估计单词的连续向量表示的模型
1、潜在语义/索引分析(LSA): 最初是用在语义检索上,为了解决一词多义和一义多词的问题
- 如果两个词多次出现在同一文档中,则这两个词在语义上具有相似性
- 将文本集合表示为单词-文本矩阵
- 对单词-文本矩阵进行奇异值分解,从而得到话题向量空间,以及文本在话题向量空间的表示
-
- 现在假设存在矩阵X的一个分解,即矩阵X可分解成正交矩阵U和V,和对角矩阵∑的乘积
-
- 根据 确定的话题个数k 对单词-文本矩阵XXT进行截断奇异值分解
-
- 降维后,原有词向量对应的二义部分会加到和其语义相似的词上,而剩余部分则减少对应的二义分量

- 降维后,原有词向量对应的二义部分会加到和其语义相似的词上,而剩余部分则减少对应的二义分量
-
- 计算行向量的cos值(或者归一化之后使用向量点乘),值越接近于1则说明两个词语越相似,越接近于0则说明越不相似
应用:
- 低维语义空间可对文档进行比较,可用于文档聚类和文档分类
- 在翻译好的文档上进行训练,可以发现不同语言的相似文档,可用于跨语言检索
- 发现词与词之间的关系,可用于同义词、歧义词检测
- 通过查询映射到语义空间,可进行信息检索
- 从语义的角度发现词语的相关性,可用于“选择题回答模型”
2、潜在Dirichlet分配(LDA): 作为基于 贝叶斯学习的话题模型,是潜在语义分析、概率潜在语义分析的扩展
随机生成一个文本的话题分布,依据该文本的话题分布随机生成一个话题,然后在该位置依据该话题的单词分布随机生成一个单词,直至文本的最后一个位置,生成整个文本,重复以上过程生成所有文本

LDA在文本数据挖掘、图像处理、生物信息处理等领域被广泛使用
3、重点: 研究神经网络学习的词的分布式表示
- 保持词之间的线性规律性方面明显优于LSA
- 在大数据集上,LDA在计算上变得非常昂贵
比较不同的模型体系结构:首先定义模型的参数,最大限度地提高精确度,同时最小化计算复杂度,训练复杂度都是成比例的,O = E × T × Q,E 是训练迭代次数(3-50) ,T 是训练集中的单词个数(高达10亿) ,Q 是每个模型体系结构的进一步定义T
所有模型都是用随机梯度下降和反向传播训练的
2.1 Feedforward Neural Net Language Model (NNLM)
前馈神经网络
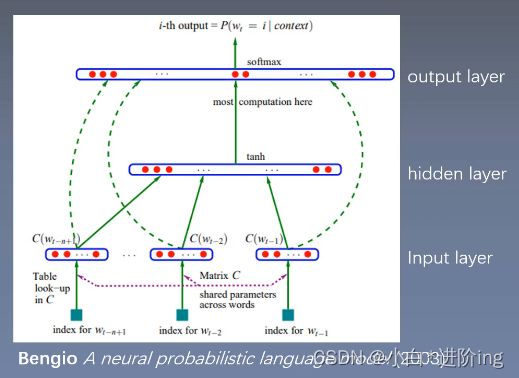
- 输入层:使用1 of V编码对N个前面的单词进行编码,其中V是词汇量的大小
- 投影层:然后使用共享投影矩阵将输入层投影到维数为n×d的投影层P
- 隐藏层:以tanh为激活函数的全连接层 a = tanh(d + Ux),用于计算词汇表中所有词的概率分布,得到维数为V的输出层
- **输出层:**全连接层,接一个softmax函数来生成概率分布,y = b + Wa
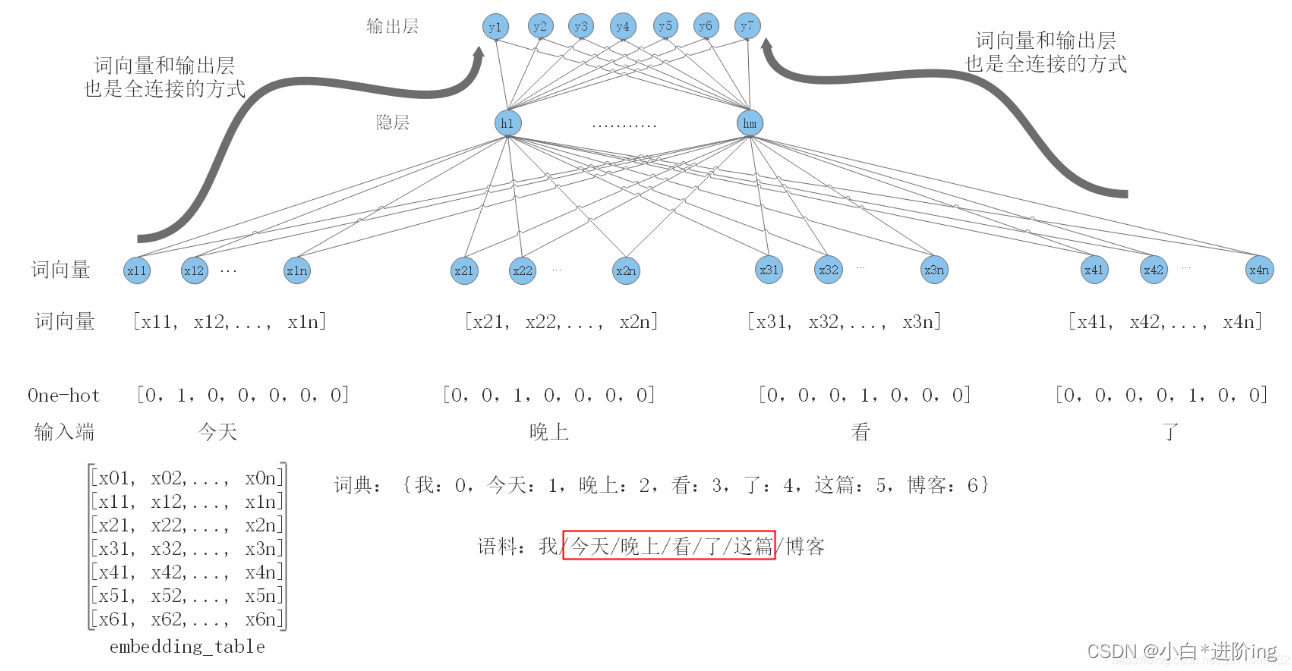
- 具体细图: one-hot: 1V ==》(1V) * W1(VN) = 1N 相加取平均 ==》(1N) * W2(NV) = 1*V
计算复杂度为Q = N×D + N×D×H + H×V,(2)其中控制项为h×v
在我们的模型中,使用分层Softmax,其中词汇表表示为哈夫曼二叉树,哈夫曼树将短二进制代码分配给频繁字,减少了需要计算的输出单元的数量,基于Huffman树的分层Softmax 只需要大约log2(Unigram pleplexity(V))
2.2 Recurrent Neural Net Language Model (RNNLM)
循环神经网络: CONTEXT(t-1)就是上一个RNN的隐状态传过来的向量,INPUT(t)指的是这个时刻传进去的词,OUTPUT(t)就是一个词典大小的向量
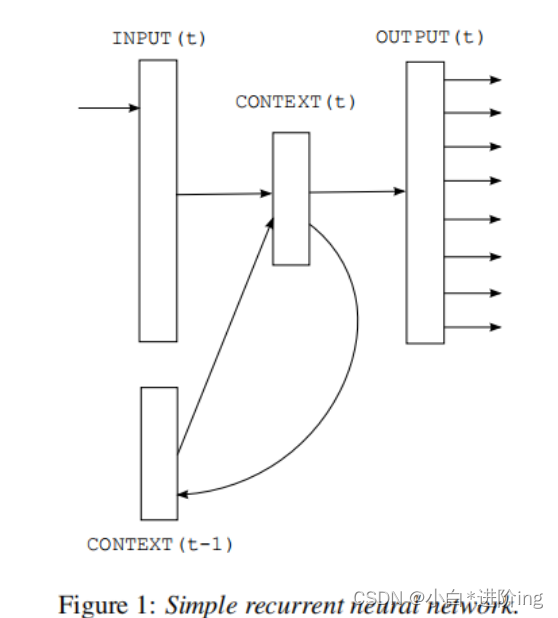
RNN模型没有投影层, 只有输入,隐藏和输出层,特殊之处在于利用时延连接将隐层连接到自身的递归矩阵,这允许递归模型形成某种短期记忆,因为来自过去的信息可以用基于当前输入和前一时间步中隐藏层的状态更新的隐藏层状态来表示
RNN模型的每个训练例的复杂度为Q = H×H + H×V,(3)其中词表示形式D与隐层H具有相同的维数。
再次,利用分层Softmax可以有效地将H×V降为H×log2(V), 因此,大部分复杂度来自于H×H
2.3 Parallel Training of Neural Networks
为了在巨大的数据集上训练模型,本文在大规模分布式框架DistBelief上实现了几个模型,包括前馈NNLM和本文提出的新模型。这个框架允许并行运行同一个模型的多个副本,每个副本通过一个保存所有参数的集中式服务器同步其梯度更新。对于这种并行训练,使用Adagrad优化算法。
3 New Log-linear Models
- 大多数复杂性是由模型中的非线性隐层引起的
- 提出了两个新的模型架构来学习词的分布式表示,试图最小化计算复杂度
- 探索更简单的模型,可能无法像神经网络那样精确地表示数据,但可能可以在更多的数据上有效地训练
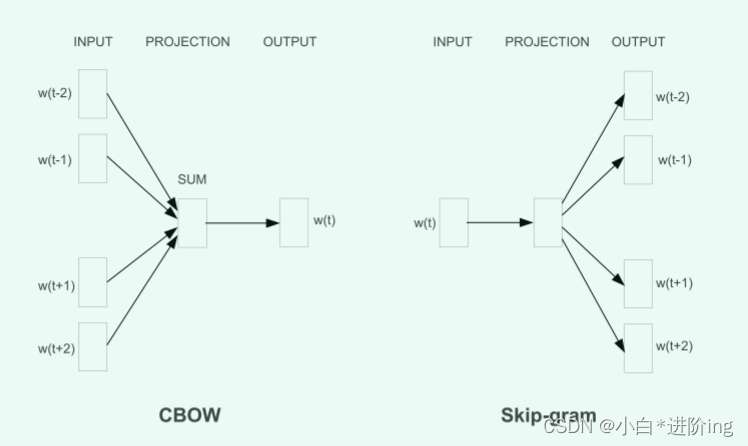
3.1 Continuous Bag-of-Words Model
1、词袋模型
结构类似于前馈NNLM,去掉了非线性隐层,投影层对所有单词(不仅仅是投影矩阵)共享; 因此,所有单词都被投射到相同的位置(它们的向量被平均)
2、CBOW
CBOW模型体系结构:根据上下文预测当前单词,只有输入、投影以及输出三层
训练复杂度为 Q = N × D + D × log2(V)
3.2 Continuous Skip-gram Model
Skip-gram模型体系结构: 根据当前单词预测周围的单词
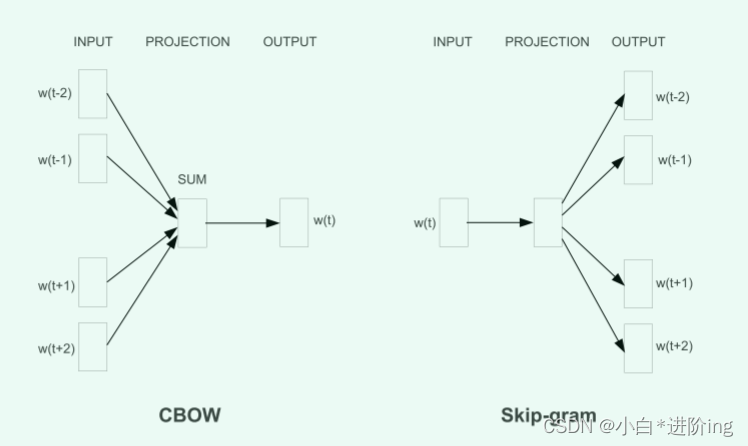
skip-gram详解

训练复杂度为Q = C×(D+D×Log2(V)),C是单词的最大距离
增加范围可以提高得到的词向量的质量,但也增加了计算复杂度
由于距离较远的单词与当前单词的关系通常比距离较近的单词更少,因此我们在训练示例中从距离较远的单词中抽取较少的样本,从而给距离较远的单词以较少的权重
4 Results
-
简单地计算X = vector(”biggest”)−vector(”big”)+ vector(”small”)
-
然后,我们在向量空间中搜索用余弦距离度量的最接近X的词,并将其作为问题的答案(我们在此搜索过程中丢弃输入的问题词)
-
当单词向量训练良好时,使用该方法可以找到正确的答案(word smallest)
-
我们发现,当我们在大量数据上训练高维单词向量时,得到的向量可以用来回答单词之间非常微妙的语义关系
-
- 例如法国之于巴黎,就像德国之于柏林一样
-
- 具有这种语义关系的词向量可以用来改进许多现有的NLP应用,如机器翻译、信息检索和问答系统,并可能使其他未来的应用尚待发明
4.1 Task Description
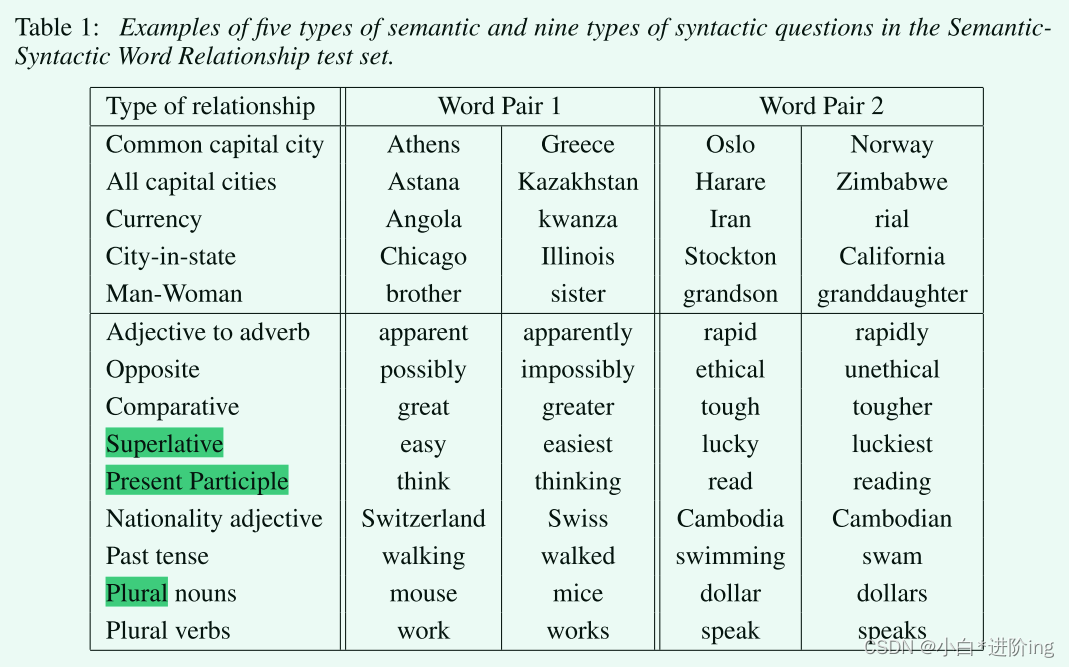
结果依据给定例子的语法与语义相似性准确性来度量,一共设置了5类语义关系和9类语法关系综合测试集
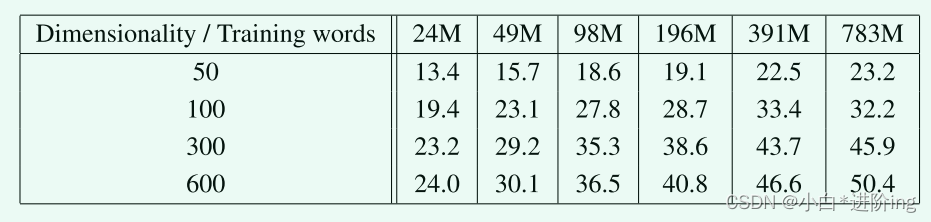
4.2 Maximization of Accuracy
在某一点之后,添加更多的维度或添加更多的训练数据提供了递减的改进,必须同时增加向量维数和训练数据量
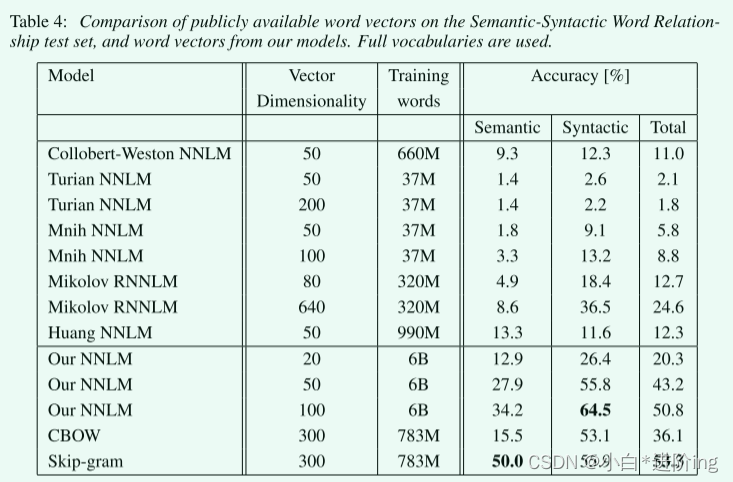
4.3 Comparison of Model Architectures
RNN的词向量在句法问题上表现得很好
NNLM向量的性能明显优于RNNLM,因为RNNLM中的单词向量直接连接到非线性隐藏层
Skip-gram体系结构在语法任务上的工作比CBOW模型稍差(但仍然比NNLM好),在测试的语义部分比所有其他模型都好得多
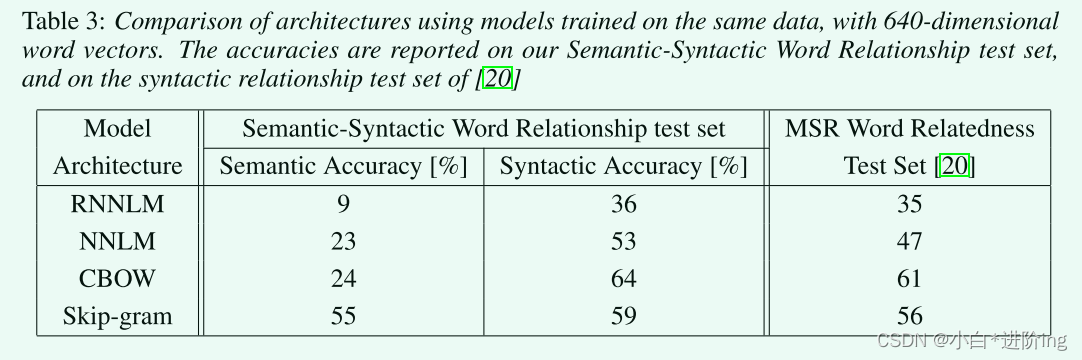
维度的增加会对NNLM的性能提升
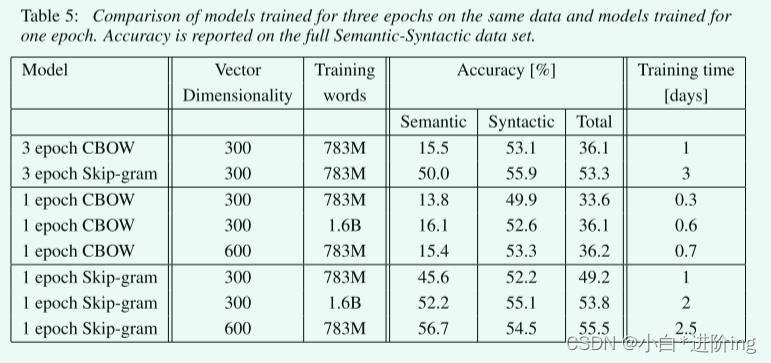
在训练轮次的增加后,效果也会提升
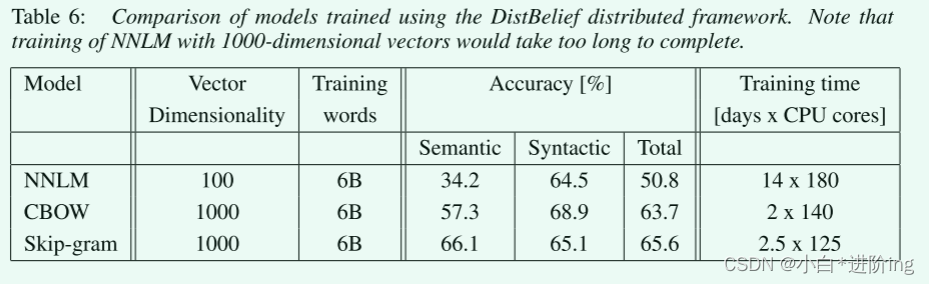
4.4 Large Scale Parallel Training of Models
模型训练所花费的时间的结果,Skip-gram最快,其次是CBOW最慢的是NNLM
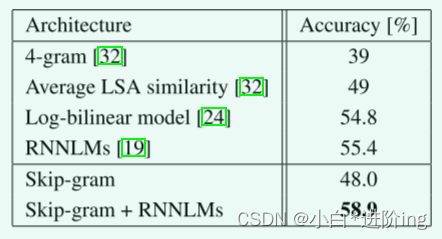
4.5 Microsoft Research Sentence Completion Challenge
这项任务由1040个句子组成,每个句子中缺少一个单词,目标是给出五个合理的选择列表,选出与句子其余部分最连贯的单词,目前保持在该基准上55.4%的精确度的最先进的性能
只是Skip-gram模型本身并不比LSA的正确率高,但是将其与RNNLM加权结合便可以达到很高的分数
5 Examples of the Learned Relationships
- 通过减去两个单词向量来定义关系,并将结果添加到另一个单词中
-
- eg: Paris - France + Italy = Rome
- 提高准确性的另一种方法是提供一个关系示例,通过使用10个例子而不是一个例子来形成关系向量(我们将单个向量平均在一起),观察到我们的最佳模型在语义-句法测试中的准确率绝对提高了10%左右

6 Conclusion
- 研究了在句法和语义语言任务集合上由各种模型导出的词的向量表示的质量
- 使用非常简单的模型架构训练高质量的词向量是可能的
- 由于计算复杂度低得多,可以从更大的数据集计算非常精确的高维字向量
- 使用DistRefield分布式框架,即使在有一万亿个单词的语料库中也应该可以训练CBOW和Skip-Gram模型
- 词向量可以成功地应用于知识库中事实的自动扩展,也可以用于已有事实的正确性验证
- 我们的综合测试集将有助于研究界改进现有的词向量估计技术
- 我们还期望高质量的词向量将成为未来NLP应用的重要组成部分
7 Follow-Up Work
- 我们发布了单机多线程C++代码来计算单词向量,使用了连续的词袋和skip-gram结构
- 训练速度明显高于本文之前的报道,训练速度在每小时数十亿字的量级
- 我们还发布了超过140万个表示命名实体的向量,对超过1000亿个单词进行了训练
- 我们的一些后续工作将发表在即将发表的NIPS 2013论文中 [21]1
注:如有侵权请联系作者删除 ↩︎















 9369
9369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











