







Redis
简介
Redis是一个开源的、高效的、分布式Key-Value数据库。Redis目前支持存储5种数据类型,字符串(String)、有序列表(List)、无序列表(Set)、字典/哈希表(Hash)、有序Set(zSet)。并且拥有内存回收策略和数据持久策略来保证Redis的高效和安全,我们在项目中主要使用Redis作为缓存,存储一些频繁访问但是又不经常改变的数据比如说字典数据、权限数据、城市数据等。
常用数据类型
字符串(String):简单的key-value存储,string类型是二进制安全的。意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储521MB.
有序列表(list):有序可重复、有序的数据(按照插入顺序排序),基于双向链表的数据类型,可以分别在list两端进行操作最大存储2^32-1个元素。
无序列表(set):不允许重复,不能通过下边获取元素。基于hash表实现,可以获取集合中的交集,并集,差集,最大存储2^32-1个元素。
字典/哈希表(hash):氏一族key-value结构,特别适合存储对象。当hash表中k-v较少时采用紧凑型(zipmap)数据结构,当k-v较多时变为真正的hashmap(ht).一个hash中可以存储2^32-1键值对。
有序set(zSet):相当于set的升级,表六了set的无序特性,按照指定字段值进行排序,最大存储2^32-1个元素。
注:注:默认16个库
各类数据类型使用场景
常见数据类型操作命令
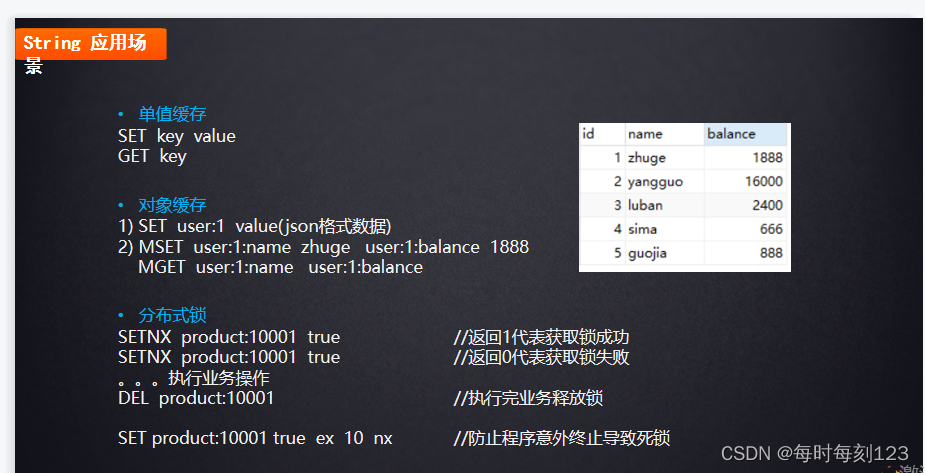
string : set key value
setnx key value 设置一个不存在的key
get key
del key
原子加减:
incr key
decr key
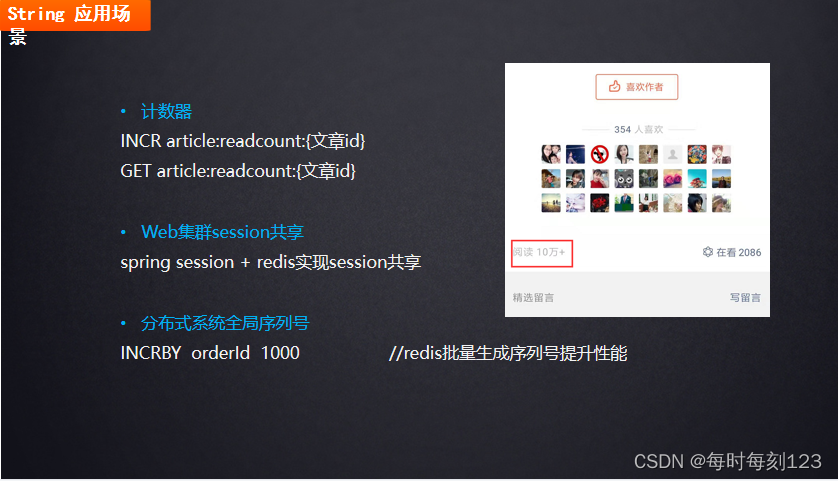
Hash
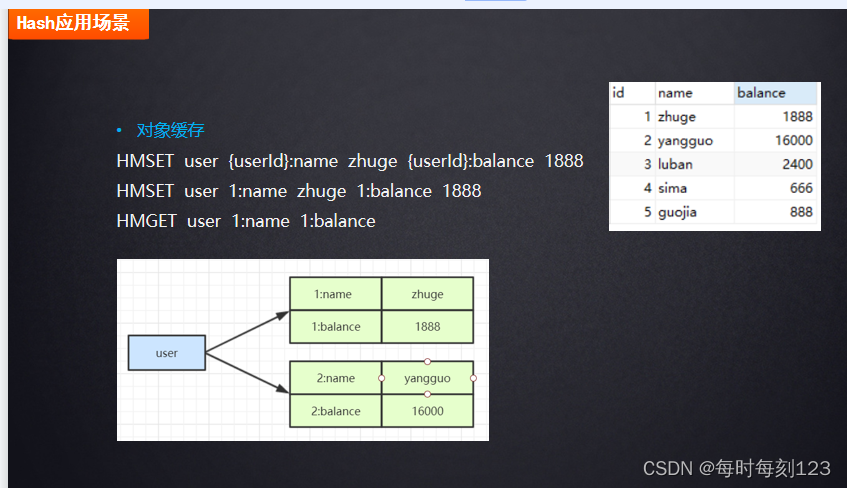
hset key filed value
hsetnx key filed value
hget key filed
hdel key filed [filed…]
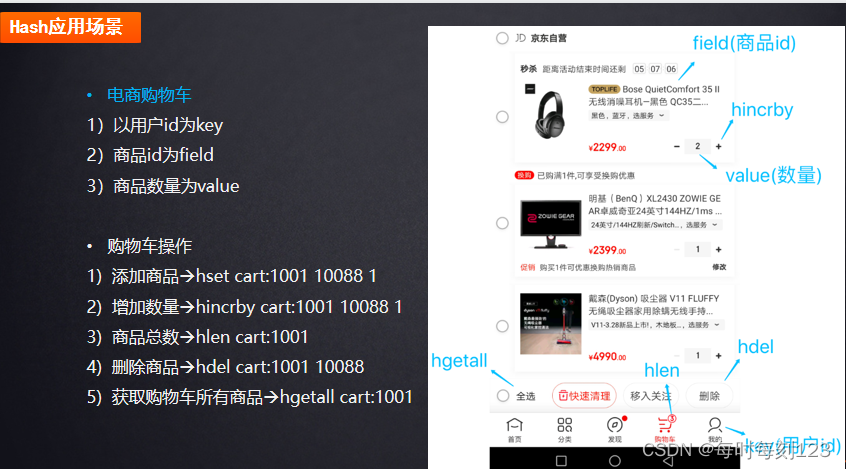
String优缺点:
同类数据规整整合存储,方便数据管理
相比String操作消耗内存和cpu更小,更节省空间
设置过期key只能作用于key上,不用作用于filed
集群不适合大规模使用
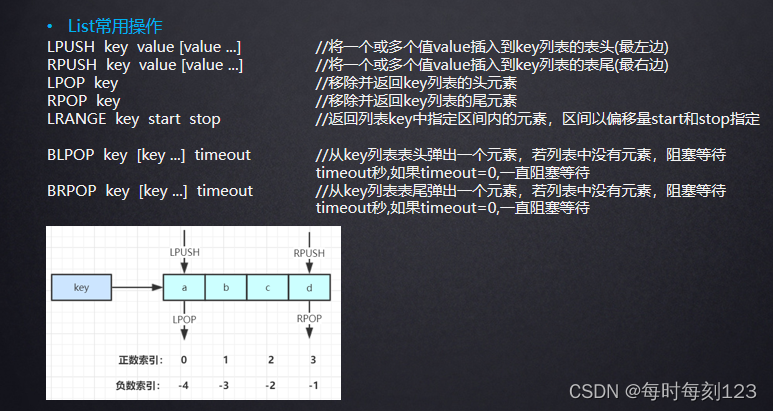
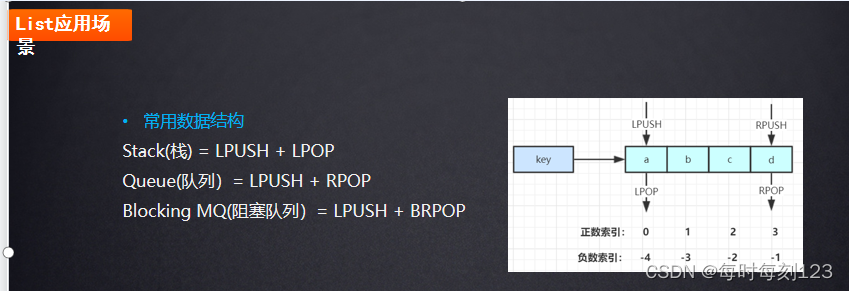
List常用操作



Redis是单线程还是多线程?
1,无论什么版本,工作线程就是一个
2,6.x高版本出现了IO多线程
3,使用上来说,没有变化
------
3,[去学一下系统IO课],你要真正的理解面向IO模型编程的时候,有内核的事,从内核把数据搬运到程序里这是第一步,
然后,搬运回来的数据做的计算式第二步,netty
4,单线程,满足redis的串行原子,只不过IO多线程后,把输入/输出放到更多的线程里去并行,好处如下:1,执行时间缩短,更快;2,更好的压榨系统及硬件的资源(网卡能够高效的使用);
*,客户端被读取的顺序不能被保障
那个顺序时可以被保障的:在一个连接里,socket里
Redis持久化策略
AOF和RDB
RDB快照 是将内存数据库快照保存为 dump.rdb文件中
你可以对其进行设置,使N秒内有N个key改动,触发一次快照
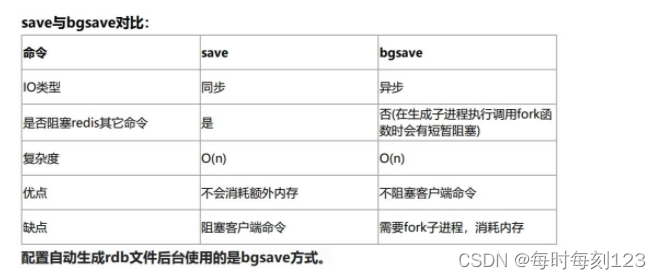
也可以手动执行生成RDB文件,通过save和besave命令
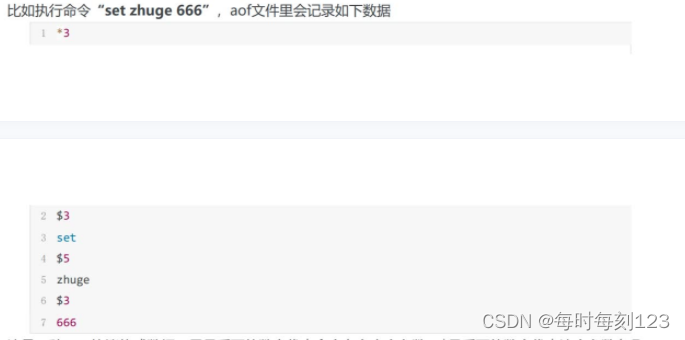
AOF以日志追加形式进行持久化,如果机器发生故障,将会丢失最近的写入,从1.1版本开始,Redis增加了一种完全持久化的策略方式,没修过一条记录aof中,隔一段时间刷新到磁盘。可以设置每秒刷新一次,可以兼顾速度和安全性
Redis4.0之后可以采用混合持久化,先用RDB进行持久化,之后再根据AOF差集进行数据追加
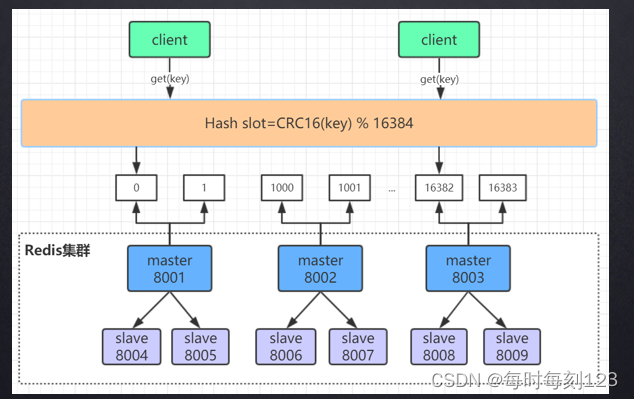
Redis集群
如果达不到单实例的瓶颈,可以采用单机的主从和哨兵(1主2从 + 3个哨兵)
集群采用Redis cluter
比如:3个master 每个master有2个node 。 推荐单数个主节点(从性能和实用方面)
主从一般会分配在不同的机器上,防止宕机,丢失数据
如果一半以上机器挂掉,机器就不能够使用。
存储数据使用槽位(16384个),可以分布在多台master中。 一个数据只会保存在一台master上。
为了防止数据丢失:可以通过配置 min-repliaces-to-write 1,node节点写成功后,才返回success.
然而性能会降低,node宕机,就不能用了,zk可以保证一致性,然而redis集群强调效率。
master宕机后,node成为主节点,之前master恢复后,会从node(主节点)恢复数据,master与node差集数据就会丢失
丢失部分数据是可以接受的,可以从数据库获 取。
分片
简单说就是将数据根据一定算法(有唯一且规则的算法[hash])存储到不同位置。
集群策略
据我所知目前Redis的集群策略比较流行的是主从复制+sentinel哨兵、redis cluster(redis官方提供的基于ruby的集群方案)、代理分片、codeis(豌豆荚的集群解决方案)
你们用的那种?
目前我做到xxx项目只使用到了主从复制(一主两从+3哨兵),主只做写的操作,从做读的操作,因为该项目还属于业务的前期用户量和数据类还达不到Redis单实例的瓶颈,没必要去搭集群。
为啥是3哨兵?
1个哨兵容易出现失误(由于网络的原因导致哨兵认为主挂掉了),
2个哨兵容易在相互投票选举时出现脑死情况导致无法切换主。
3个哨兵投票数为2的可以避免失误和哨兵在选举时的问题。
redis穿透,击穿,雪崩
Redis穿透
缓存和数据库中都没有,造成基本原因:自身业务代码问题或者数据出现问题
解决办法:
1:空key, 不同过期时间。第二次就不会再访问数据库。
2: 对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。【用的不多】
Redis击穿
大量缓存集中在某一个时间段失效,会给后端系统(比如DB)带来很大压力。
解决:
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待
设置不同过期时间
Redis雪崩
当缓存服务器重启,会给后端系统(比如DB)带来很大压力,随着存储层调用量暴增
解决办法:
1:保证缓存层服务高可用,使用redis sentinel或redis cluter
2. 采用sentinel或熔断器限流降级组件
3. 提前演练,演示缓存宕机,一些方案预定。
Redis的过期Key是如何被Redis删除掉的
我了解到的Redis删除过期Key是通过2中方式进行删除的,主动删除和惰性删除的方式,主动删除就是Redis会定时检查具有过期时间的Key是否过期,过期进行删除。惰性删除就是当进行get具有过期的Key是会检查一下该Key是否过期,过期删除并返回null,没过期就返回对应数据。
你们Redis存了什么数据(T)?
(字典数据、权限数据、城市数据、session等)
Redis内存回收机制你了解过吗?/你怎么理解的(T)。
Redis的内存回收会主动删除过期的key或不常用的key,通过设置maxmemory的大小来开启key的删除,通过指定maxmemory-policy的策略来指定Redis删除key的方式。
1、noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
2、allkeys-lru:在主键空间中,优先移除最近未使用的key。
3、volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。
4、allkeys-random:在主键空间中,随机移除某个key。
5、volatile-random:在设置了过期时间的键空间中,随机移除某个key。
6、volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
(删除的是部分满足算法选中key,而不是满足算法的全部key)
怎么选择?
根据系统的实际要求进行选择,防止过期key的脏读概率使用volatile-ttl,为了给更多频繁使用的key提高更多的空间可以使用volatile-lru
lru算法你有了解过吗?(T)
这个lru算法我只有一点简单的了解,LRU就算最近最少使用的数据,redis主要用它来进行获取要删除的key。
Redis持久策略相关
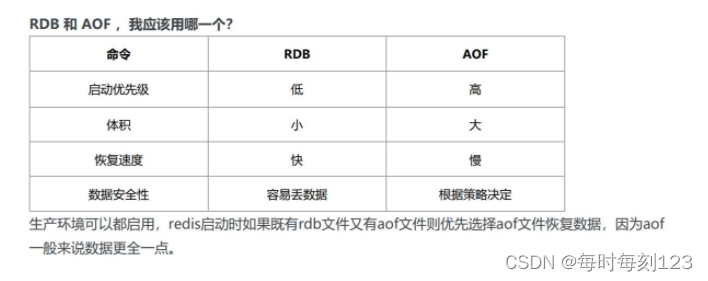
Redis的持久化策略分为两种AOF和RDB,它俩的区别是存储数据的方式不一样,RDB是定时将全部内存中的数据进行存储。AOF是以日志Append(追加)的方式进行部分数据的持久化。AOF和RDB各有利弊,AOF的主要优势在于损失部分性能来保证数据的安全以及更高的一致性,相比AOF,RDB的优势在于其的高性能。
为什么选用Redis(F)。
高效、数据类型丰富可以应对不同的业务场景,有良好的持久策略和内存回收策略。并且Redis可以集群来对redis服务质量的提高。
Redis为什么高效?(F)
因为Redis的所有操作都是基于内存的所以相比硬盘,省去了频繁的IO操作,所以高效。
你们项目中用什么连接Redis/你们是怎么使用Redis的?(F)
Redis的java连接常用的是jedis,我们在项目中使用的是Spring-data-redis,用的是Jedis的连接池。
你对Redis的看法(F)
我觉得Redis目前还不太适合直接代替关系型数据库进行数据的持久化,首先是应为它是基于内存的带给我们高效的同时必然不能相硬盘一样存储海量数据而且Redis的设计之初也不是为了代替关系型数据库。虽然说现在Redis的集群分片+主从复制可以进行类数据库的持久,但是Redis始终存在会丢失数据可能,存在一定的风险,对于公司和用户来说数据的丢失是不可取的行为。
Redis与Memcached
我们在项目中使用的是redis, Memcached没用过但简单了解过,redis和memcached都是key-value存储的,但redis还能存储list,set,zset,hash等数据结构的数据,简单的就了解这么多

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









