






1. 倒排索引
词项字典 帮助我们快速检索数据 (文件落地 数据结构)

-
倒排索引法数据结构?
-
trem index + term dictionary + 倒排表
-
倒排索引法为什么不使用B+tree?
倒排索引支持数据量较小,树深度较深
树不适合文本索引,加%索引失效
B+tree 支持千万级别, 搜索引擎 10亿级别 -
es 评分算法?
BM25(7.0后默认) TF-IDF -
trem index + term dictionary 使用到的数据结构?
FST -
倒排表 使用压缩算法
FOR(稠密数组) RBM (稀疏数组)
 6. 倒排索引解决什么问题?
6. 倒排索引解决什么问题?
通用最小化算法 解决大数据搜索
字典树(前缀树)
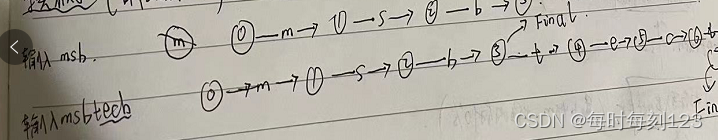
8. FSM(有限状态机) ○ 表示状态 ----> 状态转换
FSA 有限状态接收机
FST 有限状态转换机 后面数字表示匹配度


2.es写入原理

3、读写性能调优
写入性能调优:
-
增加flush时间间隔,目的是减小数据写入磁盘的频率,减小磁盘IO
-
增加refresh_interval的参数值,目的是减少segment文件的创建,减少segment的merge次数,merge是发生在jvm中的,有可能导致full GC,增加refresh会降低搜索的实时性。
-
增加Buffer大小,本质也是减小refresh的时间间隔,因为导致segment文件创建的原因不仅有时间阈值,还有buffer空间大小,写满了也会创建。 默认最小值 48MB< 默认值 堆空间的10% < 默认最大无限制
-
大批量的数据写入尽量控制在低检索请求的时间段,大批量的写入请求越集中越好。
- 第一是减小读写之间的资源抢占,读写分离
- 第二,当检索请求数量很少的时候,可以减少甚至完全删除副本分片,关闭segment的自动创建以达到高效利用内存的目的,因为副本的存在会导致主从之间频繁的进行数据同步,大大增加服务器的资源占用。
-
Lucene的数据的fsync是发生在OS cache的,要给OS cache预留足够的内从大小,详见JVM调优。
-
通用最小化算法,能用更小的字段类型就用更小的,keyword类型比int更快,
-
ignore_above:字段保留的长度,越小越好
-
调整_source字段,通过include和exclude过滤
-
store:开辟另一块存储空间,可以节省带宽
*注意:_**sourse**:**设置为false**,**则不存储元数据**,**可以节省磁盘**,**并且不影响搜索**。但是禁用_**source必须三思而后行**:*
\1. update,update_by_query和reindex不可用。
\2. 高亮失效
\3. reindex失效,原本可以修改的mapping部分参数将无法修改,并且无法升级索引
\4. 无法查看元数据和聚合搜索
影响索引的容灾能力
-
禁用_all字段:_all字段的包含所有字段分词后的Term,作用是可以在搜索时不指定特定字段,从所有字段中检索,ES 6.0之前需要手动关闭
-
关闭Norms字段:计算评分用的,如果你确定当前字段将来不需要计算评分,设置false可以节省大量的磁盘空间,有助于提升性能。常见的比如filter和agg字段,都可以设为关闭。
-
关闭index_options(谨慎使用,高端操作):词设置用于在index time过程中哪些内容会被添加到倒排索引的文件中,例如TF,docCount、postion、offsets等,减少option的选项可以减少在创建索引时的CPU占用率,不过在实际场景中很难确定业务是否会用到这些信息,除非是在一开始就非常确定用不到,否则不建议删除
搜索速度调优
-
禁用swap
-
使用filter代替query
-
避免深度分页,避免单页数据过大,可以参考百度或者淘宝的做法。es提供两种解决方案scroll search和search after
-
注意关于index type的使用
-
避免使用稀疏数据
-
避免单索引业务重耦合
-
命名规范
-
冷热分离的架构设计
-
fielddata:搜索时正排索引,doc_value为index time正排索引。
-
enabled:是否创建倒排索引
-
doc_values:正排索引,对于不需要聚合的字段,关闭正排索引可节省资源,提高查询速度
-
开启自适应副本选择(ARS),6.1版本支持,7.0默认开启,
4、ES的节点类型
可以在配置文件elasticsearch.yml中配置是否为**节点
- master: 主节点 每个集群只有一个,只承担较为轻量级的任务,比如:创建删除索引,分片均衡等。
-
尽量设置主节点不为数据节点,提高效率 - Master-eligible 候选节点
- data: 数据节点 存储数据和查询服务
- data_content:数据内容节点
- data_hot:热节点
- data_warm:索引不再定期更新,但仍可查询
- data_code:冷节点,只读索引
- Ingest:预处理节点,作用类似于Logstash中的Filter
- ml:机器学习节点
- remote_cluster_client:候选客户端节点
- transform:转换节点
- voting_only:仅投票节点
5、Mater选举过程

-
设计思路:所有分布式系统都需要解决数据的一致性问题,处理这类问题一般采取两种策略:
-
主从模式和无主模式
-
ES的选举算法
- Bully和Paxos -
脑裂是什么以及如何避免
-
**msater重新选举过程中就有可能发送脑裂问题**, 原master节点并没有挂掉,只是有些节点无法与之取得联系了,此时集群可能存在多个master节点。 脑裂对我们的影响主要是导致没有有效的团体存在,所有的团体都不包含多数的表决。产生原因:1.网络波动 2.主节点即是候补节点也是数据节点
避免:1. 候补节点不设置为数据节点 2. 将节点判断状态时间加长 3.增加选举的节点数,过半
如果已经发生: 可以重启
6、Elasticsearch调优
-
通用法则
- 通用最小化算法:对于搜索引擎级的大数据检索,每个bit尤为珍贵。
- 业务分离:聚合和搜索分离
-
数据结构 学员案例
-
硬件优化
es的默认配置是一个非常合理的默认配置,绝大多数情况下是不需要修改的,如果不理解某项配置的含义,没有经过验证就贸然修改默认配置,可能造成严重的后果。比如max_result_window这个设置,默认值是1W,这个设置是分页数据每页最大返回的数据量,冒然修改为较大值会导致OOM。ES没有银弹,不可能通过修改某个配置从而大幅提升ES的性能,通常出厂配置里大部分设置已经是最优配置,只有少数和具体的业务相关的设置,事先无法给出最好的默认配置,这些可能是需要我们手动去设置的。关于配置文件,如果你做不到彻底明白配置的含义,不要随意修改。
jvm heap分配:7.6版本默认1GB,这个值太小,很容易导致OOM。Jvm heap大小不要超过物理内存的50%,最大也不要超过32GB(compressed oop),它可用于其内部缓存的内存就越多,但可供操作系统用于文件系统缓存的内存就越少,heap过大会导致GC时间过长
-
节点:
根据业务量不同,内存的需求也不同,一般生产建议不要少于16G。ES是比较依赖内存的,并且对内存的消耗也很大,内存对ES的重要性甚至是高于CPU的,所以即使是数据量不大的业务,为了保证服务的稳定性,在满足业务需求的前提下,我们仍需考虑留有不少于20%的冗余性能。一般来说,按照百万级、千万级、亿级数据的索引,我们为每个节点分配的内存为16G/32G/64G就足够了,太大的内存,性价比就不是那么高了。
-
内存:
根据业务量不同,内存的需求也不同,一般生产建议不要少于16G。ES是比较依赖内存的,并且对内存的消耗也很大,内存对ES的重要性甚至是高于CPU的,所以即使是数据量不大的业务,为了保证服务的稳定性,在满足业务需求的前提下,我们仍需考虑留有不少于20%的冗余性能。一般来说,按照百万级、千万级、亿级数据的索引,我们为每个节点分配的内存为16G/32G/64G就足够了,太大的内存,性价比就不是那么高了。
- 磁盘:
对于ES来说,磁盘可能是最重要的了,因为数据都是存储在磁盘上的,当然这里说的磁盘指的是磁盘的性能。磁盘性能往往是硬件性能的瓶颈,木桶效应中的最短板。ES应用可能要面临不间断的大量的数据读取和写入。生产环境可以考虑把节点冷热分离,“热节点”使用SSD做存储,可以大幅提高系统性能;冷数据存储在机械硬盘中,降低成本。另外,关于磁盘阵列,可以使用raid 0。
-
CPU:
CPU对计算机而言可谓是最重要的硬件,但对于ES来说,可能不是他最依赖的配置,因为提升CPU配置可能不会像提升磁盘或者内存配置带来的性能收益更直接、显著。当然也不是说CPU的性能就不重要,只不过是说,在硬件成本预算一定的前提下,应该把更多的预算花在磁盘以及内存上面。通常来说单节点cpu 4核起步,不同角色的节点对CPU的要求也不同。服务器的CPU不需要太高的单核性能,更多的核心数和线程数意味着更高的并发处理能力。现在PC的配置8核都已经普及了,更不用说服务器了。
-
网络:
ES是天生自带分布式属性的,并且ES的分布式系统是基于对等网络的,节点与节点之间的通信十分的频繁,延迟对于ES的用户体验是致命的,所以对于ES来说,低延迟的网络是非常有必要的。因此,使用扩地域的多个数据中心的方案是非常不可取的,ES可以容忍集群夸多个机房,可以有多个内网环境,支持跨AZ部署,但是不能接受多个机房跨地域构建集群,一旦发生了网络故障,集群可能直接GG,即使能够保证服务正常运行,维护这样(跨地域单个集群)的集群带来的额外成本可能远小于它带来的额外收益。
-
集群规划:没有最好的配置,只有最合适的配置。
-
在集群搭建之前,首先你要搞清楚,你ES cluster的使用目的是什么?主要应用于哪些场景,比如是用来存储事务日志,或者是站内搜索,或者是用于数据的聚合分析。针对不同的应用场景,应该指定不同的优化方案。
-
集群需要多少种配置(内存型/IO型/运算型),每种配置需要多少数量,通常需要和产品运营和运维测试商定,是业务量和服务器的承载能力而定,并留有一定的余量。
-
一个合理的ES集群配置应不少于5台服务器,避免脑裂时无法选举出新的Master节点的情况,另外可能还需要一些其他的单独的节点,比如ELK系统中的Kibana、Logstash等。
-
-
架构优化:
-
Mpping优化:
-
Developer调优:修炼内功,提升修养
7、索引备份还原
snapshot(快照技术)
8、数据同步方案
9、搜索引擎和ES(搜索引擎的原理、ES的认识或理解)
-
概念:大数据检索(区分搜索)、大数据分析、大数据存储
-
性能:PB级数据秒查(NRT Near Real Time)
- 高效的压缩算法
- 快速的编码和解码算法
- 合理的数据结构
- 通用最小化算法
-
场景:搜索引擎、垂直搜索、BI、GIthub、ELKB
-
大厂:JD、百度、阿里、腾讯、滴滴、字节、美团、Github、马士兵教育(如果记不住,就把你能想到的大厂有几个说几个)。
10、ES容灾问题
ES集群因为分片和副本的存在使ES集群的可用性非常高。
ES集群不可用的原因主要是因为主节点的宕机,
所以ES的容灾机制依靠的就是master选举、分片以及副本。
11、分片是啥
elasticsearch集群是由一个或者多个节点组成的集合
节点是可以存储数据,参与集群索引数据
索引(相当于数据库)可以定义一个或多个类型(表)
每个索引都有多个分片,每个分片是一个Lucene索引
关系:集群有节点组成,节点有分片、副本组成,一个索引分为多个分片,一个分片由索引,类型组成,类型由文档组成。这是他们之间的关系
10、深度分页问题
假如要查询990-1000数据,查询语句应该这么写
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, # 分页开始的位置,默认为0
"size": 10, # 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
elasticsearch内部分页时,必须先查询 0~1000条,然后截取其中的990 ~ 1000的这10条:
如果是集群环境,必须查出每台机器0-1000数据,然后汇总进行排序。
如果查询9900-100000?数据量过于大
内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求
解决方案:
- 限制请求,而淘宝则对深度分页处理则很直接,限制分页页数.超过100页后面的数据,基本认为是无效数据.则会丢弃这些数据.
- search after:
原理 :分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式
注意
要保证排序值是唯一不重复的,否则分页时可能会漏掉数据。
例子:
期望结果:
第一次查询:最后一条数据的排序值是 score=47,price=245。 score=47,price=245的数据只有一条
下一次查询:查询 score=47,price=245之后的数据,没有任何问题
但是如果:
score=45,price=245的数据有多条,假定为doc1、doc2
第一次查询第一页时,顺序是doc1、doc2,这一页刚好查询到了doc1
查询下一页时,顺序是doc2、doc1,从第2条开始,查询到了doc1
最终就漏掉了doc2
解决方案:
建议保证排序条件值不重复,就不会出现上面的问题了
例如:以score降序、price升序、_id降序。 _id是文档的唯一标识,是不重复的
11、深度优先和广度优先算法
都属于 图搜索算法
深度优先算法:
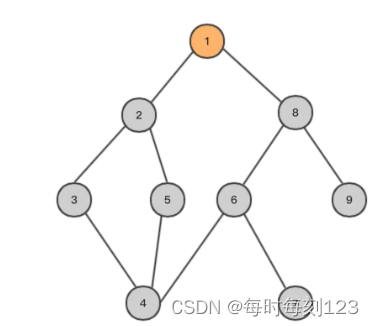
优先取左节点 其搜索节点顺序是 1,2,3,4,5,6,7,8
广度优先搜索
广度优先搜索(也称宽度优先搜索,缩写BFS,以下采用广度来描述)是连通图的一种遍历算法这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。
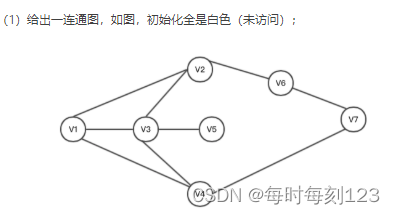
以 V1为起点。依次遍历,遍历后节点置为黑色,直到遍历完V7
最短路径:v1 ---->v4------>v7
12、向量空间模型
数学中向量
X = {X1, X2,X3…}
















 1691
1691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









