









一、基础复习
上节课回顾:
1.文件永久存储(上) python文件永久存储(创建打开文件、文件对象的各种方法及含义)
2.文件永久存储(中)总结 路径处理 pathlib–面向对象的文件系统路径 绝对路径vs相对路径(路径查询、路径修改、查找功能)
二、文件操作
1.with语句和上下文管理器
传统的文件操作
文件操作三板斧:打开文件、操作文件、关闭文件
例1:
>>> f=open("FishC,txt","w")
>>> f.write("I love Fishc.")
13 #写入字符串的长度
>>> f.close()
使用with语句操作
例2:
代码功能和例1相同,不需要手动关闭文件
>>> with open("Fishc,txt","w") as f:
f.write("I love Fishc.")
13
>>>
不在IDLE中执行,在test.py文件中执行
例3:
f=open("FishC,txt","w")
f.write("I love Fishc.")
1/0
f.close()
运行结果报错,除法运算中,除数不能为0。但创建了一个FishC,txt的文件,文件中没有内容,因为程序出错的时候,并没有机会执行到这个文件关闭的一个操作,所以写入的内容在缓冲区中,并没有写入,程序就关闭了。

改成with的形式,
with open("FishC,txt","w") as f:
f.write("I love Fishc.")
1/0
可以看到结果依然会报错,但FishC,txt里面有内容,with上下文管理器可以帮你确保文件的正常关闭。
2.pickle模块
允许将字符串、列表、字典这些python对象保存为文件的形式。
python对象序列化,将Python对象转化为二进制字节流的过程。
2.1第一个函数dump函数
例4:
import pickle
x,y,z = 1,2,3
s="Fishc"
l=["小甲鱼",520,3.14]
d={"one":1,"two":2}
with open("data.pkl","wb") as f: #保存为pickle文件,后缀名为pkl,以二进制形式打开
pickle.dump(x,f)
pickle.dump(y,f)
pickle.dump(z,f)
pickle.dump(s,f)
pickle.dump(l,f)
pickle.dump(d,f)
出现了一个data.pkl文件
打开后为二进制形式。文本文件打开为乱码。
编写一个read.py文件,将乱码读出来
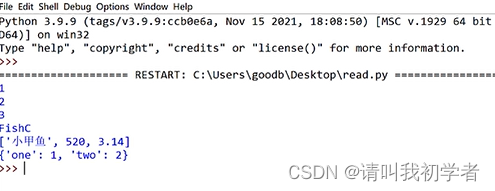
例5:
import pickle
with open("data.pkl","rb") as f: #读取wb改为rb
x=pickle.load(f)
y=pickle.load(f)
z=pickle.load(f)
s=pickle.load(f)
l=pickle.load(f)
d=pickle.load(f)
print(x,y,z,s,l,d,sep="\n")
结果:
 对内容用元祖进行打包
对内容用元祖进行打包
例6:
import pickle
x,y,z = 1,2,3
s="Fishc"
l=["小甲鱼",520,3.14]
d={"one":1,"two":2}
with open("data.pkl","wb") as f:
pickle.dump((x,y,z,s,l,d),f)
读取出来,进行解包得到的内容是一样的。
import pickle
with open("data.pkl","rb") as f:
x,y,z,s,l,d=pickle.load(f)
print(x,y,z,s,l,d,sep="\n")

课后题:
1.with 上下文管理器最核心的功能是什么?
答:确保资源的释放。
2.请问下面代码段 A 和代码段 B 的执行结果是否等价?
代码段 A:
f = open("FishC.txt", "w")
f.write("I love FishC.")
1 / 0
f.close()
代码段 B:
with open("FishC.txt", "w") as f:
f.write("I love FishC.")
1 / 0
答:不等价。
解析:with 上下文管理器可以确保文件被正确关闭(尽管中间出现了异常)
3.下面是使用 pickle 保存 Python 对象的代码,请问哪里做错了?
import pickle
x = 250
y = 3.14
z = "FishC"
with open("data.pkl", "w") as f:
pickle.dump((x, y, z), f)
答:由于 pickle 是将 Python 对象序列化保存,是二进制形式,因此需要使用 “wb” 的文件打开模式。
解析:读取也一样噢,人家是二进制文件,而非文本文件~
4. 如果想要读取一个 pickle 文件,是否需要预先知道其中的对象类型和数量?
答:不需要。
解析:load() 函数会根据 dump() 函数保存的顺序,将对象逐个读取出来。
5.请问可以使用 with 语句管理两个文件的上下文吗?
答:可以。
比如原来是这样的代码:
f1 = open("FishC.txt", "r")
f2 = open("FishD.txt", "w")
f1.seek(10)
f2.write(f1.read(5))
f1.close()
f2.close()
使用 with 语句写法如下:
with open("FishC.txt", "r") as f1, open("FishD.txt", "r") as f2:
f1.seek(10)
f2.write(f1.read(5))
题目来自小甲鱼python文件永久存储(下)















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









