






InnoDB架构
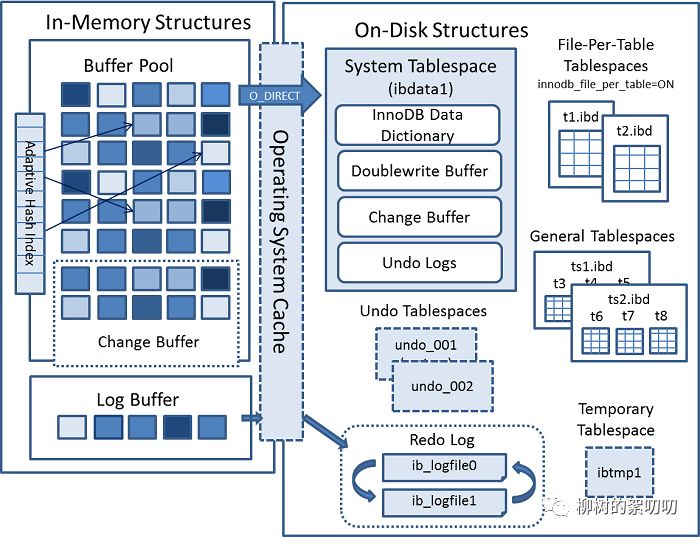
InnoDB主要分为两大块:
- In-Memory Structures
- On-Disk Structures
In-Memory Structures
1、Buffer Pool:是一个以页为元素的链表,避免每次访问磁盘,以加速数据的访问;采用基于LRU改进算法管理内存
- merge: Change Buffer -> Buffer Pool
- purge: Buffer Pool -> Disk
LRU改进:靠近链表头部分为young区、靠近尾部分为old区;新插入的数据首先进入old区,每次访问时会做个判断:若存在时间 <1 秒则保持不变,否则移动到链表头部;这种策略可以优化全表扫描时依然对Buffer Pool可控
2、Change Buffer:当要对页修改时候发现Buffer Pool中没有对应页的数据,会先记录到Change Buffer中,同时记录redo log,再慢慢把数据load到内存
3、Adaptive Hash Index:自适应哈希索引,将频繁被访问的数据记录下来加快访问速度;
4、Log Buffer:缓存red log,慢慢刷到磁盘
5、Operating System Cache:操作系统概念中的高速缓存
On-Disk Structures
1、Tablespaces:表空间,包括系统表空间、用户表空间和Undo表空间
- 系统表空间: 主要存储MySQL内部的数据字典数据
- 用户表空间: 当开启innodb_file_per_table=1时,数据表从系统表空间独立出来存储在以table_name.ibd命令的数据文件中,结构信息存储在table_name.frm文件中
- Undo表空间:存储Undo信息,如快照一致读和flashback都是利用undo信息。
2、Doublewrite Buffer:保证数据页可靠性,在MySQL刷到磁盘之前做一个备份,以便发生crash修复磁盘中的数据
InnoDB碎片
删除数据会在页面上留下一些”空洞”,或者随机写入(聚集索引非线性增加)会导致页分裂,页分裂导致页面的利用空间少于50%,另外对表进行增删改会引起对应的二级索引值的随机的增删改,也会导致索引结构中的数据页面上留下一些"空洞",虽然这些空洞有可能会被重复利用,但终究会导致部分物理空间未被使用,也就是碎片。
回收碎片,释放空间,是个随机读IO操作,会比较耗时,也会阻塞表上正常的DML运行,同时需要占用额外更多的磁盘空间
delete 语句
MySQL内部不会真正删除空间,而且做标记删除;如果下一次insert更大的记录,delete之后的空间不会被重用,如果插入的记录小于等于delete的记录空会被重用
解决方式:1、添加删除标记字段,将delete改造为update字段
2、对有生命周期的数据表可以使用Clickhouse
MVCC
MVCC保证数据库读不会加锁,提高了并发处理能力但每行记录都要额外存储空间以及做更多的行检查;MVCC只在REPEATABLE READ和READ COMMITIED两个隔离级别下工作
实现逻辑
InnoDB的MVCC是通过在每行记录后保存两个隐藏的列来实现;一个保存了行的事务ID(DB_TRX_ID),一个保存了行的回滚指针(DB_ROLL_PT)。每开始一个新事务都会自动递增产生一个新的事务id,查询时用当前事务id和每行记录的事务id进行比较
在RR隔离级别下:
select:行的事务id <= 当前事务id,且删除的行的事务id > 当前事务id
insert:为新插入的每一行保存当前事务id作为行版本号
delete:为删除每一行保存当前事务id作为行删除标识
update:为插入一行新记录保存当前事务id作为行版本号,同时保存当前事务编号作为行删除标识
实现原理
依赖undo log版本链和read view机制
undo log
undo log保证原子性,记录事务逻辑变化
undo log 分为两种:insert undo log和update undo log
insert undo log:insert操作中产生的undo log,因为insert操作记录对于其他事务此记录不可见,所以insert undo log在事务提交后直接删除而无需purge(将数据库中mark del的数据删除,批量回收undo pages)
update undo log:update或delete操作中产生的undo log,因为会对已经存在的记录产生影响,因此update undo log在事务提交时放到history list,等待purge
read view
用于判断所有版本中哪个版本是当前事务可见的处理;ReadView主要包含当前系统中还有哪些活跃的读写事务,将他们的事务id放到一个列表中即m_ids
在RC隔离级别下,是每个快照读都会生成并获取最新的Read View;
在RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View, 之后的快照读获取的都是同一个Read View
若被访问版本的trx_id < m_ids中最小id,则该版本可以被当前事务访问
若被访问版本的trx_id > m_ids中最大id,则该版本不可以被当前事务访问
若被访问版本的trx_id在m_ids列表最大最小之间,则需要判断一下是否在m_ids中,若在说明事务还未提交不可以被访问,若不在说明已经提交可以访问
总结
MVCC就是在RC和RR这两种隔离级别的事务在执行普通select操作时访问记录的版本链的过程,使不同事务的读写、写读操作并发执行
RC中每次查询会生成一个实时的ReadView,而RR中在当前事务第一次查询时生成ReadView直到当前事务提交















 4678
4678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









