







Scrapy-Splash 是一个用于 Scrapy 的扩展,其主要功能是处理动态网页。Scrapy 本身在抓取静态网页时表现出色,但对于由 JavaScript 渲染的动态网页,它的处理能力有限。而 Scrapy-Splash 借助 Splash 服务,能够让 Scrapy 抓取动态生成的内容。
目标:
Scrapy-Splash抓取动态网页的内容
一.安装Splash
可以通过 Docker 来安装和运行 Splash:
docker run -p 8050:8050 scrapinghub/splash
上述命令会启动一个 Splash 服务,它会监听 http://localhost:8050 端口。
然后浏览器打开http://localhost:8050
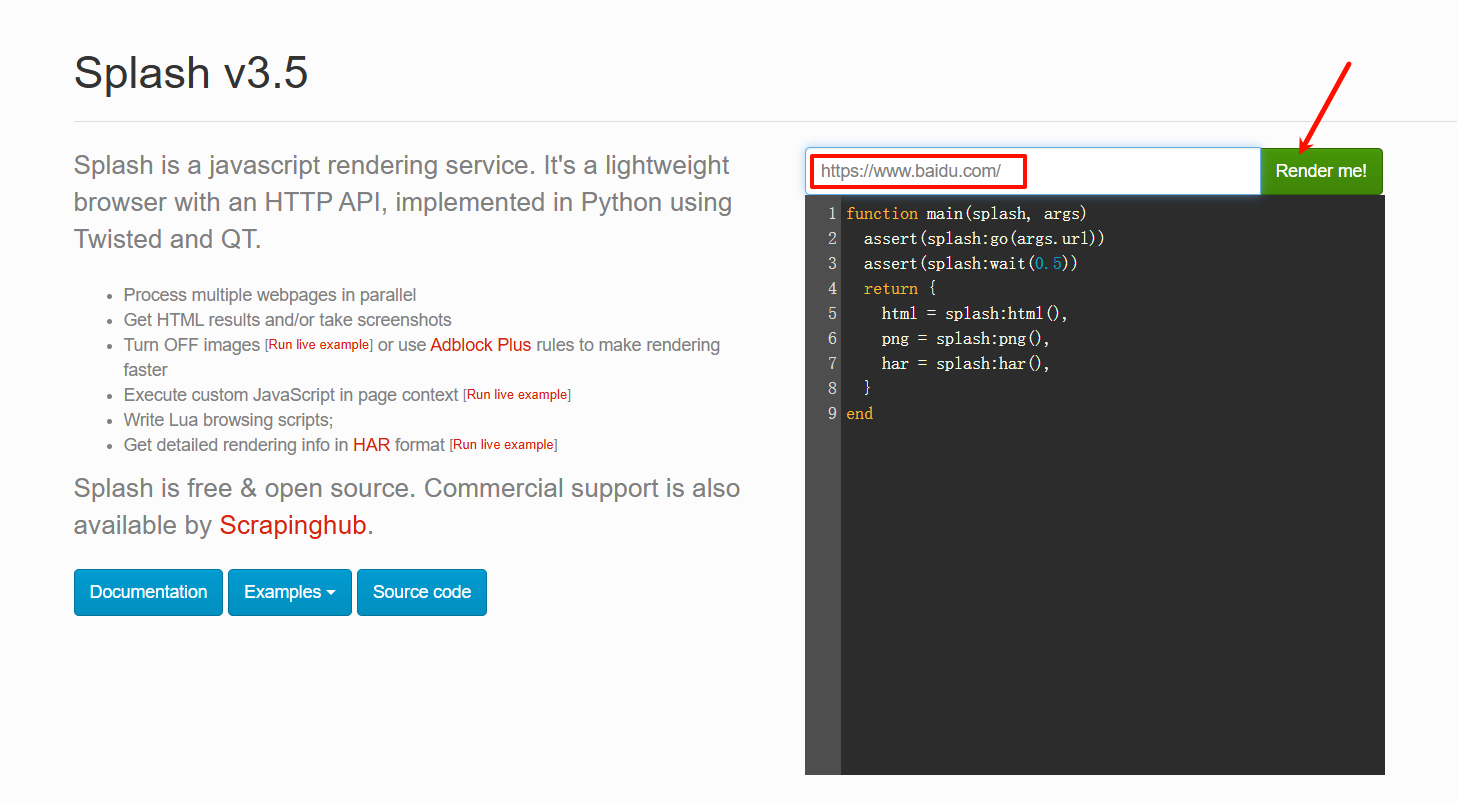
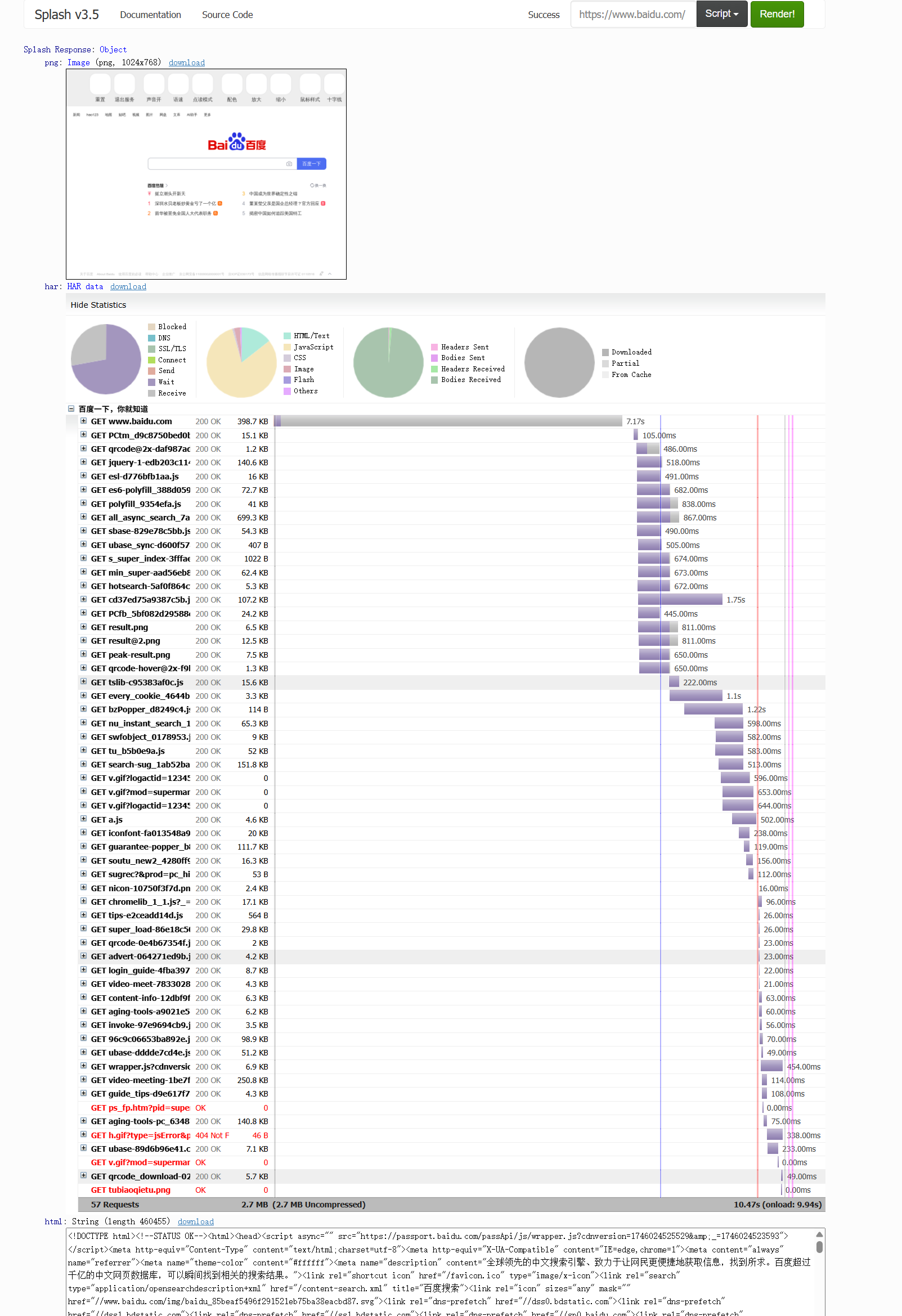
访问百度,可以看到请求和渲染的HTML页面
1. 安装 Splash
2. 安装 Scrapy-Splash
安装 Scrapy-Splash
pip install scrapy-splash
3. 配置 Scrapy 项目
在 Scrapy 项目的 settings.py 文件里添加如下配置:
# 启用 Splash 服务的 URL
SPLASH_URL = 'http://localhost:8050'
# 启用 Splash 中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 启用 Splash 的 DupeFilter
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# 启用 Splash 的 Cache
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
4. 创建 Spider
用于抓取动态网页
import scrapy
from scrapy_splash import SplashRequest
class DynamicSpider(scrapy.Spider):
name = "dynamic_spider"
start_urls = ['http://example.com'] # 替换为你要抓取的动态网页 URL
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url, self.parse, args={'wait': 5}, endpoint='render.html')
def parse(self, response):
# 处理响应内容
title = response.css('title::text').get()
self.log(f"Page title: {title}")
5. 运行 Spider
scrapy crawl dynamic_spider
- SplashRequest:这是
Scrapy-Splash提供的一个特殊请求类,它可以向 Splash 服务发送请求。args={'wait': 5}表示在页面加载完成后等待 5 秒,确保 JavaScript 代码执行完毕。 - 中间件配置:在
settings.py中配置的中间件会对请求和响应进行处理,确保 Scrapy 与 Splash 服务正常交互。 - DupeFilter 和 Cache:这些配置可以避免重复请求,提高抓取效率。
endpoint='render.html'能让 Splash 服务渲染页面,执行页面中的 JavaScript 代码,最终返回完整渲染后的 HTML 内容
值得注意的是 Scrapy、scrapy-splash、Twisted(Scrapy 依赖的网络库)版本兼容的问题,不兼容运行爬虫就会报错

















 2145
2145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









