







今天是哈夫曼树
此处知识来自b站讲解
哈夫曼树(最优二叉树)的主要思想是,叶子带有权值,而访问叶子,则需要从根节点开始遍历,若想要树的带权路径长度(WPL)最小,则需要权大的,路径小。
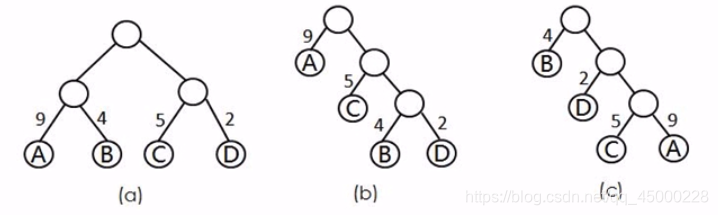
同样的数据,WPL却不同。
那么让我们开拓一下思想,前面将权值越大的越靠前,那我们是不是可以将这个权值表达别的意思,也就是不仅仅是在于数字上的意义,那么哈夫曼编码就是很聪明的了
在正常的数据的传输中,若想传输一串字符串,则每个字符,都需要有对应的一串二进制数字来表示,每个byte由8个bit组成,每个字符(一个字母之类的)由一个byte组成(应该没错🙃),那么就会出现这样一个情况,8位长的byte,对于一些不经常使用的字符,也需要存储同样大的空间。
那么哈夫曼编码如何解决呢?
先筛选出在这串字符中最经常使用的字符,并形成一个使用频率降序的数组,当叶子在二叉树的左边时,编码为0,右边为1,又因为哈夫曼树是二叉树,两个子叶满后,会在一个子叶上开辟新的子树,有了深度,同时也保证了编码的唯一
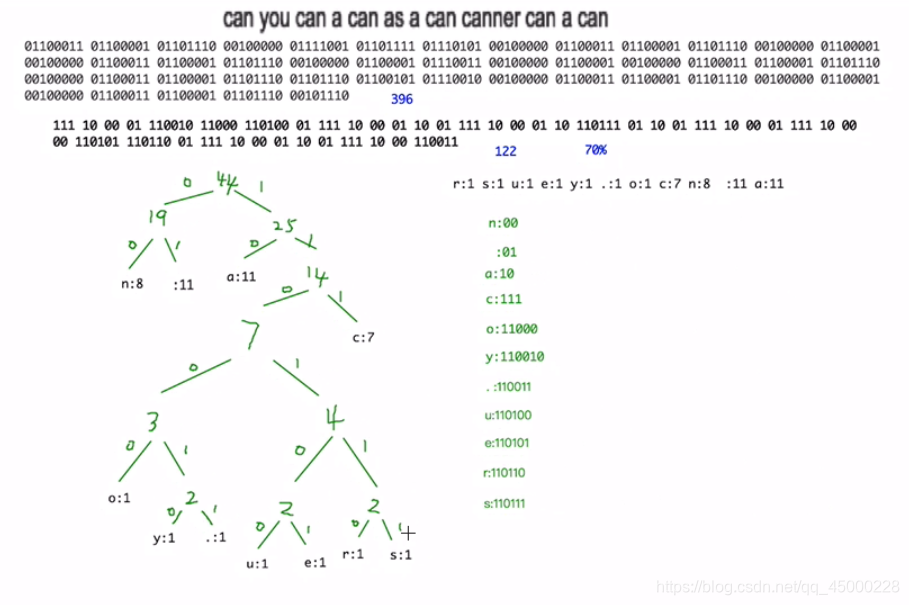
先上每个节点的代码
//实现了Comparable的接口,便于排序
public class Node implements Comparable<Node> {
// 存放字符
Byte data;
// 存放权重
int weight;
// 左节点
Node left;
// 右节点
Node right;
public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
// 降序方法
@Override
public int compareTo(Node o) {
return o.weight - this.weight;
}
// 重写的toString
@Override
public String toString() {
return "Node [data=" + data + ", weight=" + weight + "]";
}
}
然后是哈夫曼编码的代码
import java.util.*;
import java.util.Map.Entry;
public class TestHuffmanCode {
public static void main(String[] args) {
// 需要压缩的字符串
String msg = "can you can a can as a can canner can a can.";
// 将字符串用再带的api转成byte数组
byte[] bytes = msg.getBytes();
// 进行哈夫曼编码
byte[] b = huffmanZip(bytes);
System.out.println(bytes.length);
System.out.println(b.length);
}
/**
* 哈夫曼压缩(主)
*
* @param bytes
* @return byte[]
*/
private static byte[] huffmanZip(byte[] bytes) {
// 先统计每一个byte出现的次数,并放入一个链表的集合中
List<Node> nodes = getNodes(bytes);
// 创建一棵合并过的哈夫曼树
Node tree = createHuffmanTree(nodes);
// 创建一个哈夫曼编码表
Map<Byte, String> huffCodes = getCodes(tree);
// System.out.println(huffCodes);
// 编码
byte[] b = zip(bytes, huffCodes);
return b;
}
/**
* 进行哈夫曼编码
*
* @param bytes
* @param huffCodes2
* @return
*/
private static byte[] zip(byte[] bytes, Map<Byte, String> huffCodes) {
StringBuilder sb = new StringBuilder();
// 把需要压缩的byte数组处理成一个二进制的字符串
for (byte b : bytes) {
sb.append(huffCodes.get(b));
}
// 定义长度给下面byte数组定义长度,每8位是一组,不足8位,仍占一组
// byte是八位的二进制
int len;
if (sb.length() % 8 == 0) {
len = sb.length() / 8;
} else {
len = sb.length() / 8 + 1;
}
// System.out.println(sb.toString());
// 用于存储压缩后的byte
byte[] by = new byte[len];
// 记录新byte的位置,用以截取字符串
int index = 0;
// 遍历sb这个String,i以8进
for (int i = 0; i < sb.length(); i += 8) {
String strByte;
// 当下一组不够8位的时候
if (i + 8 > sb.length()) {
// 获取剩下所有的字符
strByte = sb.substring(i);
} else {
// 正常情况,获取当下第i个到第i+8个的字符
strByte = sb.substring(i, i + 8);
}
// 先将获取的字符串编成二进制,在将其强转位byte类型
byte byt = (byte) Integer.parseInt(strByte, 2);
by[index] = byt;
index++;
}
return by;
}
// 用于临时存储路径
static StringBuilder sb = new StringBuilder();
// 用于存储哈夫曼编码
static Map<Byte, String> huffCodes = new HashMap<>();
/**
* 根据哈夫曼树获取和父母编码
*
* @param tree
* @return
*/
private static Map<Byte, String> getCodes(Node tree) {
// 排除树空的情况,并作为递归结束的条件
if (tree == null) {
return null;
}
// 用递归的想法,处理整棵树
// 左子树编码为0
getCodes(tree.left, "0", sb);
// 右子树编码为1
getCodes(tree.right, "1", sb);
return huffCodes;
}
/**
* 获取哈夫曼编码
*
* @param node
* @param code
* @param sb
*/
private static void getCodes(Node node, String code, StringBuilder sb) {
// 初始化一个Stirng
StringBuilder sb2 = new StringBuilder(sb);
// 将这个string添加上code(用以分别左右子树,0和1)
sb2.append(code);
// 仍是递归,结束添加是节点的数据为空,也就是父节点
if (node.data == null) {
getCodes(node.left, "0", sb2);
getCodes(node.right, "1", sb2);
} else {
// 将之前创建的全局变量存储节点信息
huffCodes.put(node.data, sb2.toString());
}
}
/**
* 创建哈夫曼树
*
* @param nodes
* @return
*/
private static Node createHuffmanTree(List<Node> nodes) {
// 每次循环将链表中最小的两个树合并,以得到最后只有一棵树的哈夫曼树
// 经过哈夫曼编码的树,最后仅剩余一棵没有数据,只有所有树的权的和的权
while (nodes.size() > 1) {
// 排序(使用Collections的排序,需要将Node节点实现Comparable并泛型为Node,重写compareTo)
Collections.sort(nodes);
// 取出两个权值最低的二叉树
Node left = nodes.get(nodes.size() - 1);
// 因为已经经过了降序排序,所以最小的两个叶子为链表的最后两个
Node right = nodes.get(nodes.size() - 2);
// 创建一棵新的二叉树,作为两颗删除的叶子的父节点,像这样的父节点,没有数据只有删去节点的两个权值和
Node parent = new Node(null, left.weight + right.weight);
// 把之前取出来的两颗二叉树设置为新创建的二叉树的字数
parent.left = left;
parent.right = right;
// 把之前取出来的而二叉树删除
nodes.remove(left);
nodes.remove(right);
// 把新创建的二叉树放入集合中
nodes.add(parent);
}
return nodes.get(0);
}
/**
* 把byte数组转为node集合
*
* @param bytes
* @return
*/
private static List<Node> getNodes(byte[] bytes) {
// 初始化一个链表,泛型限制为Node
List<Node> nodes = new ArrayList<>();
// 用HashMap存储每一个byte出现了多少次
Map<Byte, Integer> counts = new HashMap<>();
// 遍历传进来的byte数组,以统计每一个byte出现的次数
for (byte b : bytes) {
// 用Integer对象进行计数
Integer count = counts.get(b);
// 便于判断map中是否存在当前正在遍历的byte
if (count == null) {
// 不存在,添加新的,赋值value是1
counts.put(b, 1);
} else {
// 存在则覆盖以当前byte为key的节点的value(即加一)
counts.put(b, count + 1);
}
}
// 把每一个键值对转为一个node对象
// 这里值得注意的是,因为是要使用HashMap中的entrySet,并且HashMap的Entry是基础Map的,所以使用
// foreach的时候,单个的对象需要为Map.Entry
for (Entry<Byte, Integer> entry : counts.entrySet()) {
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
}
这里我输出了编码前与编码后,传输的代码的长度
44
16
原本的字符串长度为44,但是在编码以后,长度变为了16
后面再更新解码的代码
我想成为一个温柔的人,因为曾被温柔的人那样对待,深深了解那种被温柔相待的感觉。
——夏目友人帐


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









