







原题如下
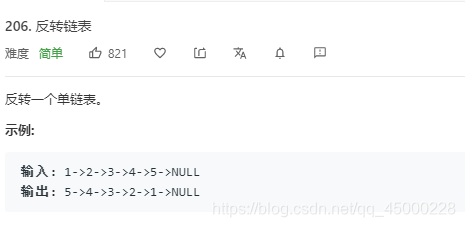
206.反转链表
我先试试手撸一遍代码试试,没有任何提示的那种 😀
//这是给出的节点信息
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
* */
class Solution {
public ListNode reverseList(ListNode head) {
//遍历前 创建一个前驱节点pre为null,一个当前节点curr为传入的头节点head
ListNode pre=null;
ListNode curr=head;
//在循环中当前节点curr在不断向后走,当当前节点curr指向了之前链表的末尾null时,反转完毕
while(curr!=null){
//创建一个临时节点next,用来保存当前节点的后继节点
ListNode next=curr.next;
//将当前节点的后继节点变为前驱节点pre,因为怕丢了之前的后继,所以前面才把它提出了
curr.next=pre;
//本次循环的目的已经达到了,下面进行下一次循环的准备
//前驱节点pre指向了当前节点curr
pre=curr;
//当前节点指向了前面保存的当前节点curr的后继节点next
curr=next;
}
//遍历完成后,现在的pre即时翻转完成后链表的头节点
return pre;
}
}
我当时怎么都不能理解循环里面的四句话,现在才看懂了,可以理解为链表的遍历中进行了翻转
其实数据结构的本质不仅仅是为了更好的存储数据,而且也是为了更便捷的查找到需要的数据,对数据结构的操作,无非是增删改查,而这些操作全部基于查找,换句话说,如果这个数据结构的查找比较好,其他的操作也会更加容易一些,但为什么会有这么多数据结构呢,这是为了适应各种不同的问题
马上下个题见😀
幸福的家庭都是相似的,不幸的家庭各有各的不幸。
——安娜·卡列妮娜














 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









