







文章目录
Docker搭建ES集群
关闭防火墙
后面我们要使用多个端口,为了避免繁琐的开放端口操作,我们关掉防火墙
# 关闭防火墙
systemctl stop firewalld.service
# 禁用防火墙
systemctl disable firewalld.service
安装Docker
我们使用 Docker 来运行 Elasticsearch,首先安装 Docker,参考下面笔记:
https://blog.csdn.net/weixin_38305440/article/details/102810532
下载 Elastic Search 镜像
docker pull elasticsearch:7.9.3
集群部署结构
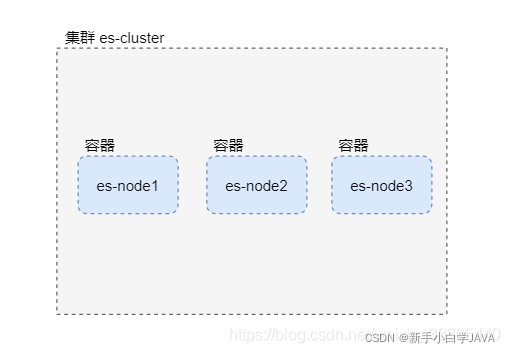
在一台服务器上,使用Docker部署三个ES容器组成的集群
准备虚拟网络和挂载目录
# 创建虚拟网络
docker network create es-net
# node1 的挂载目录
mkdir -p -m 777 /var/lib/es/node1/plugins
mkdir -p -m 777 /var/lib/es/node1/data
# node2 的挂载目录
mkdir -p -m 777 /var/lib/es/node2/plugins
mkdir -p -m 777 /var/lib/es/node2/data
# node3 的挂载目录
mkdir -p -m 777 /var/lib/es/node3/plugins
mkdir -p -m 777 /var/lib/es/node3/data
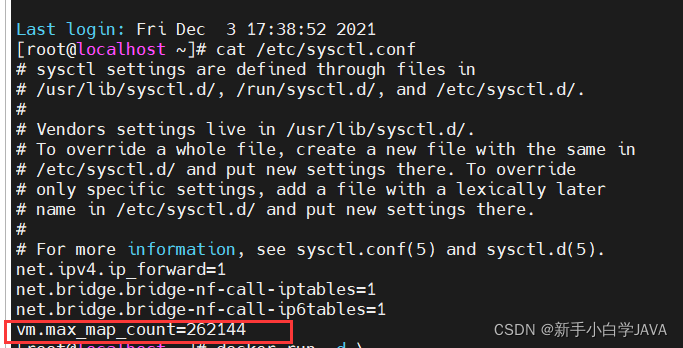
设置 max_map_count
必须修改系统参数 max_map_count,否则 Elasticsearch 无法启动:
在 /etc/sysctl.conf 文件中添加 vm.max_map_count=262144
echo 'vm.max_map_count=262144' >>/etc/sysctl.conf
需要重启服务器!(即重启虚拟机)
确认参数配置:
cat /etc/sysctl.conf
启动 Elasticsearch 集群
node1:
docker run -d \
--name=node1 \
--restart=always \
--net es-net \
-p 9200:9200 \
-p 9300:9300 \
-v /var/lib/es/node1/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node1/data:/usr/share/elasticsearch/data \
-e node.name=node1 \
-e node.master=true \
-e network.host=node1 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
node2:
docker run -d \
--name=node2 \
--restart=always \
--net es-net \
-p 9201:9200 \
-p 9301:9300 \
-v /var/lib/es/node2/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node2/data:/usr/share/elasticsearch/data \
-e node.name=node2 \
-e node.master=true \
-e network.host=node2 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
node3:
docker run -d \
--name=node3 \
--restart=always \
--net es-net \
-p 9202:9200 \
-p 9302:9300 \
-v /var/lib/es/node3/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node3/data:/usr/share/elasticsearch/data \
-e node.name=node3 \
-e node.master=true \
-e network.host=node3 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
环境变量说明:
| 环境变量 | 说明 |
|---|---|
| node.name | 节点在集群中的唯一名称 |
| node.master | 可已被选举为主节点 |
| network.host | 当前节点的地址 |
| discovery.seed_hosts | 集群中其他节点的地址列表 |
| cluster.initial_master_nodes | 候选的主节点地址列表 |
| cluster.name | 集群名 |
| ES_JAVA_OPTS | java虚拟机参数 |
参考 https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html
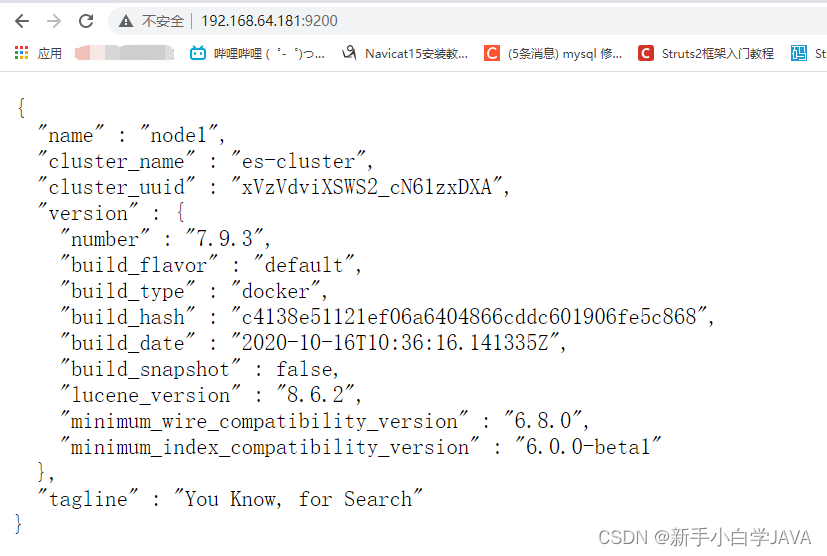
查看启动结果结果
http://192.168.64.181:9200
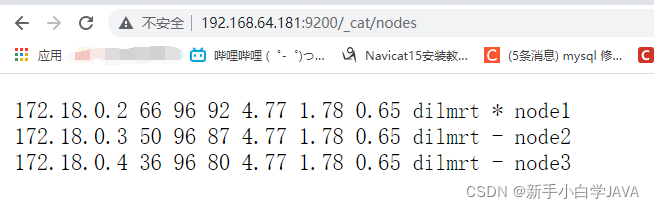
http://192.168.64.181:9200/_cat/nodes
chrome浏览器插件:elasticsearch-head
elasticsearch-head 项目提供了一个直观的界面,可以很方便地查看集群、分片、数据等等。elasticsearch-head最简单的安装方式是作为 chrome 浏览器插件进行安装。
-
在 elasticsearch-head 项目仓库中下载 chrome 浏览器插件
https://github.com/mobz/elasticsearch-head/raw/master/crx/es-head.crx -
将文件后缀改为 zip
-
解压缩
-
在 chrome 浏览器中选择“更多工具”–“扩展程序”
-
在“扩展程序”中确认开启了“开发者模式”
-
点击“加载已解压的扩展程序”
-
选择前面解压的插件目录
-
在浏览器中点击 elasticsearch-head 插件打开 head 界面,并连接 http://192.168.64.181:9200/
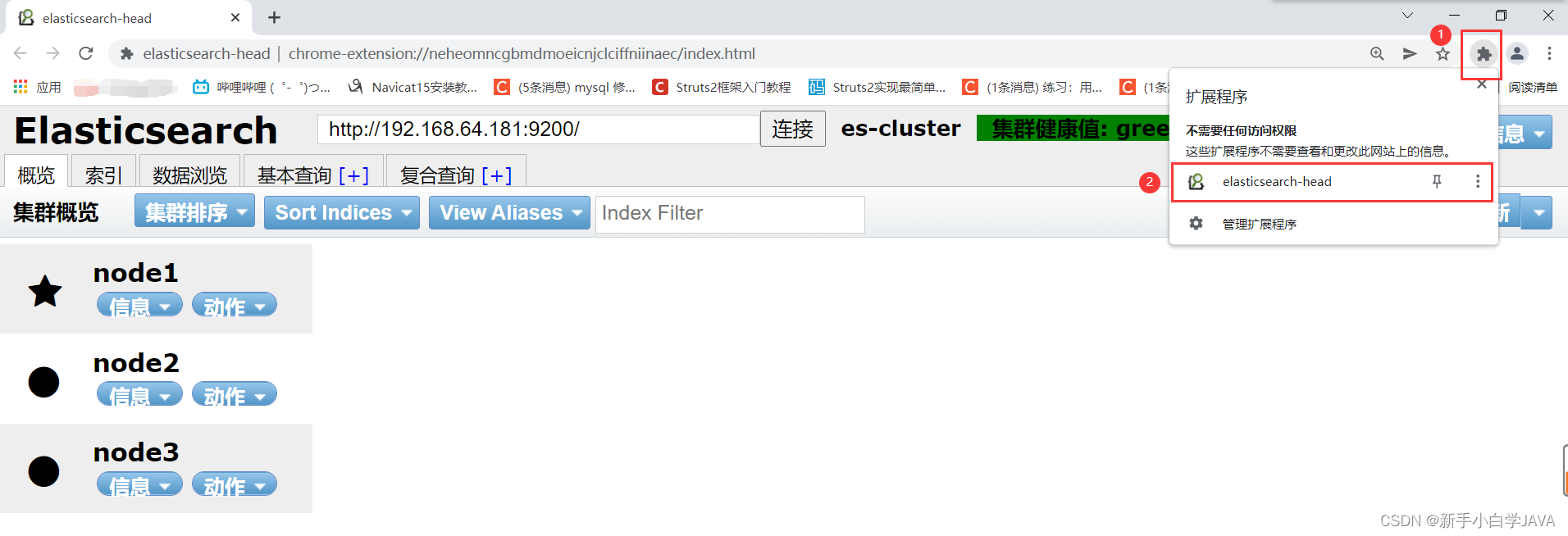
IK中文分词器
安装 ik 分词器
从 ik 分词器项目仓库中下载 ik 分词器安装包,下载的版本需要与 Elasticsearch 版本匹配:
https://github.com/medcl/elasticsearch-analysis-ik
或者可以访问 gitee 镜像仓库:
https://gitee.com/mirrors/elasticsearch-analysis-ik
下载 elasticsearch-analysis-ik-7.9.3.zip 复制到 /root/ 目录下
在三个节点上安装 ik 分词器
cd ~/
# 复制 ik 分词器到三个 es 容器
docker cp elasticsearch-analysis-ik-7.9.3.zip node1:/root/
docker cp elasticsearch-analysis-ik-7.9.3.zip node2:/root/
docker cp elasticsearch-analysis-ik-7.9.3.zip node3:/root/
# 在 node1 中安装 ik 分词器
docker exec -it node1 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip
# 在 node2 中安装 ik 分词器
docker exec -it node2 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip
# 在 node3 中安装 ik 分词器
docker exec -it node3 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip
# 重启三个 es 容器
docker restart node1 node2 node3
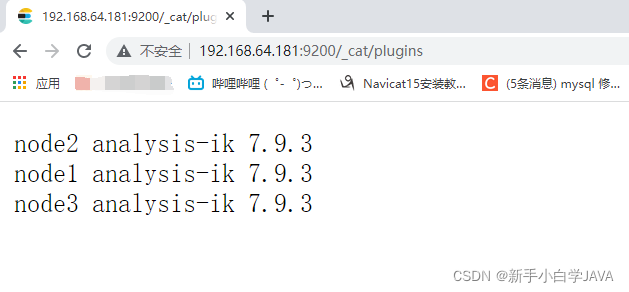
查看安装结果
在浏览器中访问 http://192.168.64.181:9200/_cat/plugins
如果插件不可用,可以卸载后重新安装:
docker exec -it node1 elasticsearch-plugin remove analysis-ik
docker exec -it node2 elasticsearch-plugin remove analysis-ik
docker exec -it node3 elasticsearch-plugin remove analysis-ik
ik分词测试
ik分词器提供两种分词器: ik_max_word 和 ik_smart
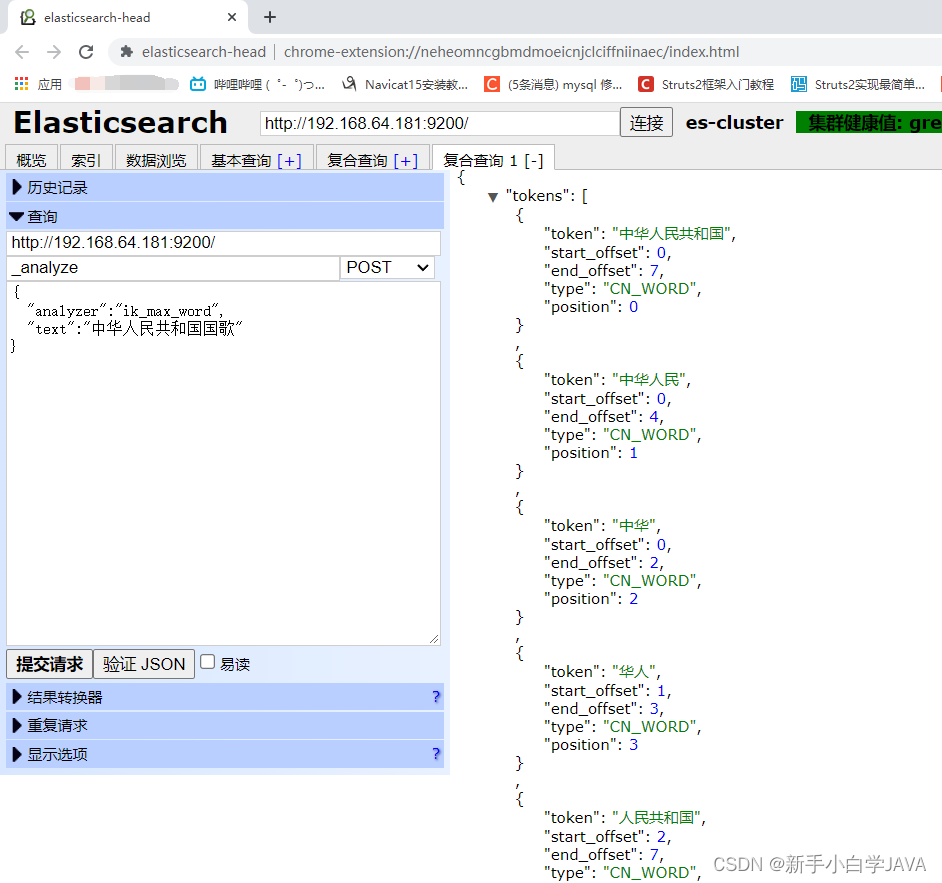
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
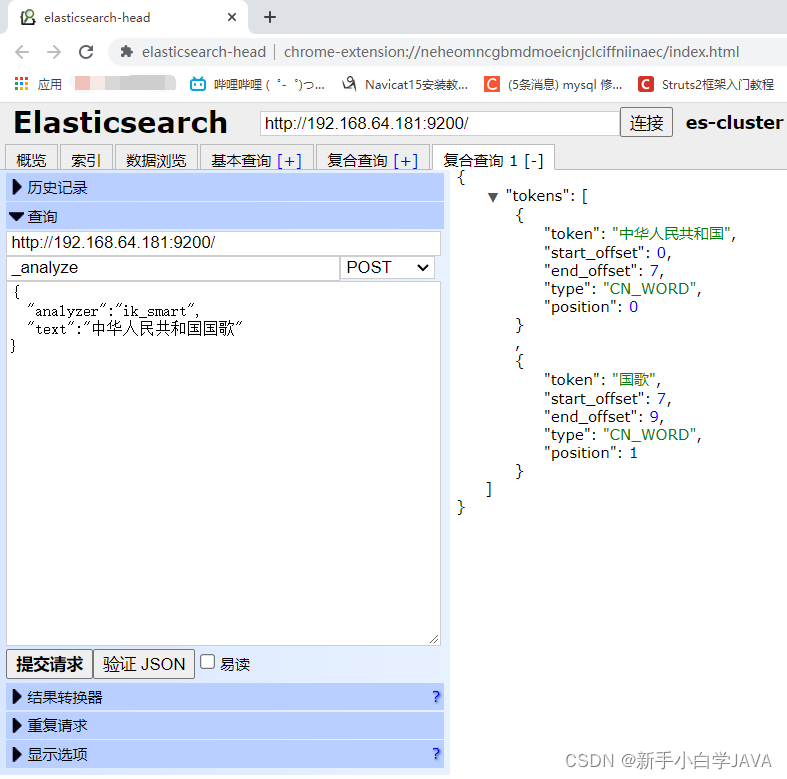
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
ik_max_word 分词测试
使用 head 执行下面测试:
向 http://192.168.64.181:9200/_analyze 路径提交 POST 请求,并在协议体中提交 Json 数据:
{
"analyzer":"ik_max_word",
"text":"中华人民共和国国歌"
}
ik_smart 分词测试
使用 head 执行下面测试:
向 http://192.168.64.181:9200/_analyze 路径提交 POST 请求,并在协议体中提交 Json 数据:
{
"analyzer":"ik_smart",
"text":"中华人民共和国国歌"
}
使用 Kibana 操作 ES
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash和Kibana这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









