







第21天—Python爬虫—requests库
requests库是一个Python第三方库,处理URL资源特别方便。
进入终端输入下面的命令,安装requests三方库
pip install requests
Google Chrome浏览器
Google Chrome浏览器能够帮助我们快速获取想要数据的位置
进入Google Chrome浏览器鼠标点击右键我们可以选择查看网页源码选项和检查选项

检查选项也可以使用键盘上的f12快速进入
当我们使用检查选项时
点击下图所示红色方块那,把鼠标移动到我们想获取的地方,会自动告诉我们在网页源码中的位置

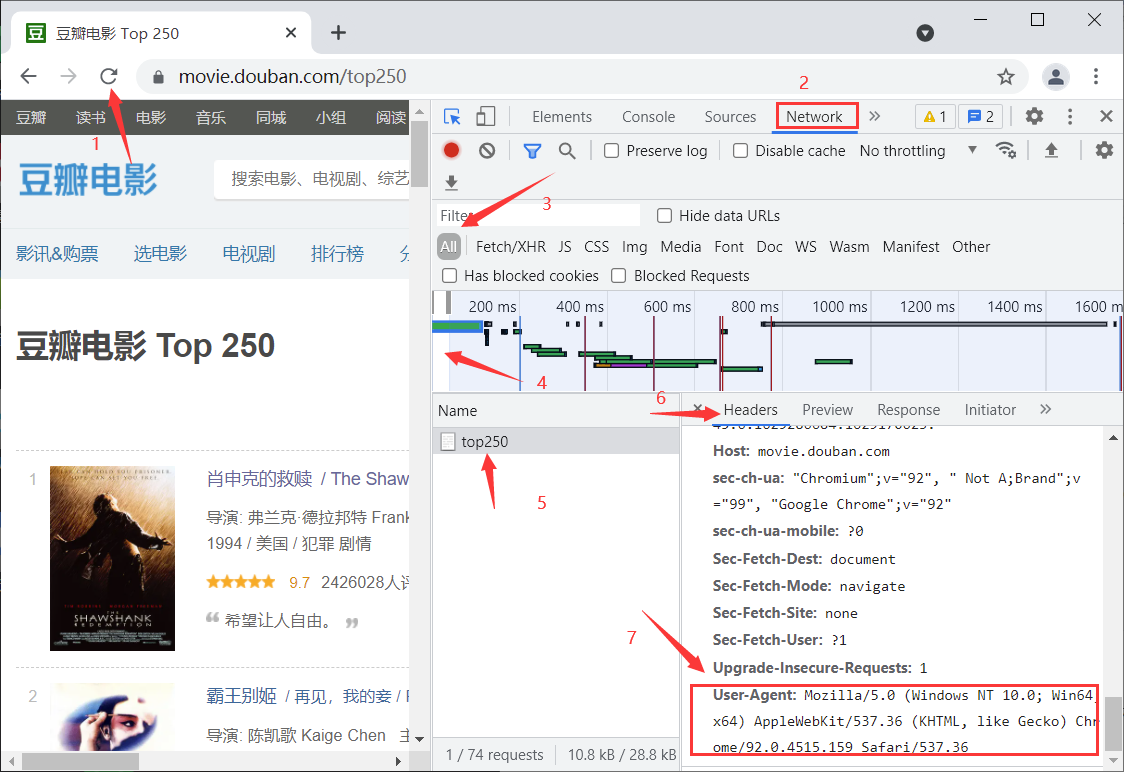
获取headers信息
headers信息,其中包含了User-Agent字段信息,也就是浏览器标识信息。如果不加这个,一些网址会禁止抓取数据。
进入网站 —> f12进入检查 —> 点击刷新 —> 点击Network —> 选择all —> 点一下前面一段 —> 选择其中一个文件 —>点击Headers —> 滚动到最下方就会找到User-Agent字段信息
使用requests
这里我们使用豆瓣电影网址
import requests
# 网址
URL = 'https://movie.douban.com/top250'
# headers信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
# 访问网页
resp = requests.get(url=URL, headers=headers)
# 打印网页源码
print(resp.text)
通过使用requests库,我们使用正则表达式对我们想要的数据进行抓取
通过Chrome浏览器的检查,找到我们需要数据的位置
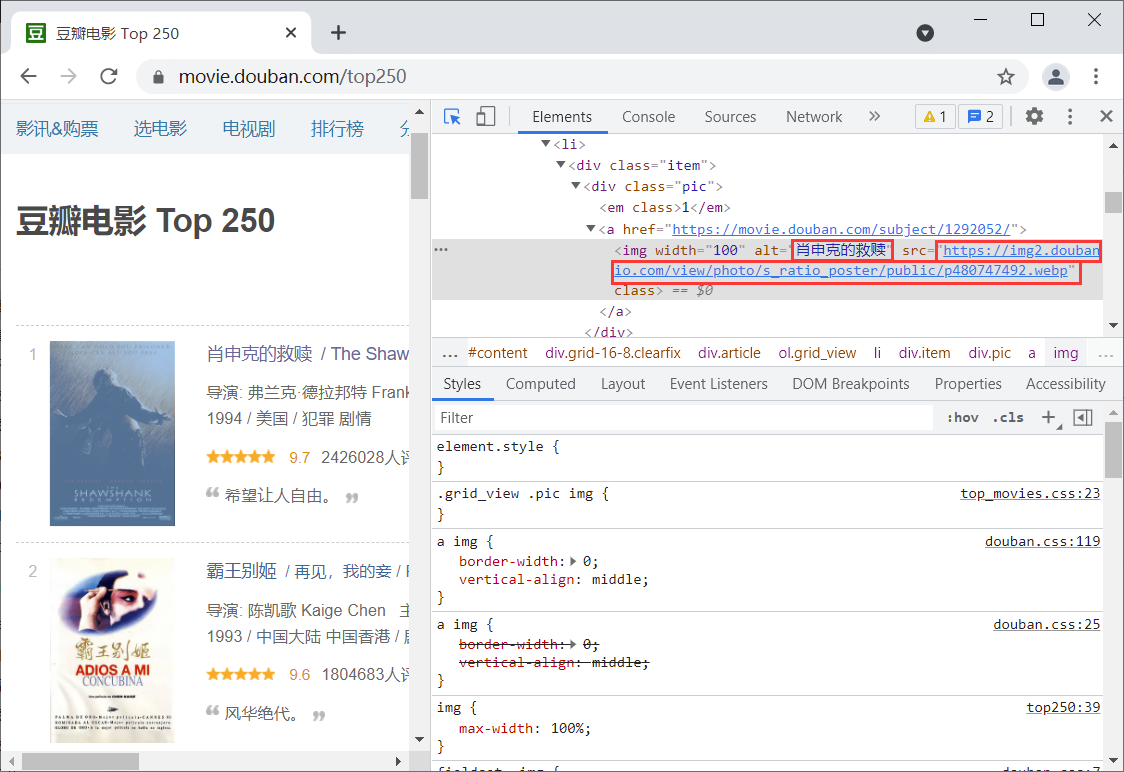
# 使用正则表达式得导入re
import re
# 正则表达式:将需要的数据使用()进行封装
re_str = '<img width="100" alt="(.+?)" src="([a-z]{5}.{3}[a-z\d]{4}\.[a-z]{8}\.[a-z]{3}/view/photo/s_ratio_poster/public/p\d{9}.jpg)" class="">'
# 匹配网页和标题
result = re.search(re_str, content)
print(result)
# span():输出匹配到的字符串的起始位置和结束位置
print(result.span())
# group():将分组中的内容返回出来
# 如果参数是0(group(0)),将匹配到的全部内容输出
print(result.group(1))
print(result.group(2))
# groups()将正则表达式中分组的内容合成一个元组
print(result.groups())
结果如下:
<re.Match object; span=(9883, 10002), match='<img width="100" alt="肖申克的救赎"src="https://img2.d>
(9883, 10002)
肖申克的救赎
https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg
('肖申克的救赎','https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg')
Process finished with exit code 0

练习:
使用正则表达式匹配链家二手房信息:标题,位置,总价,单价
import requests
import re
for j in range(1, 101):
# 使用for循环把1-100页的网页遍历
URL = f'https://cd.lianjia.com/ershoufang/pg{j}/'
# headers信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
# 请求链接
resp = requests.get(url=URL, headers=headers)
# 获取所有信息
li_str = re.compile('<li class="clear(.+?)</li>')
# 类型为列表
content = li_str.findall(resp.text)
# 循环遍历
for i in content:
# 房屋标题
title = re.compile(
'data-log_index="\d{1,2}" data-el="ershoufang" data-housecode="\d{12}" data-is_focus="" data-sl="">(.+?)</a>')
title_content = title.search(i)
title_1 = title_content.group(1)
print(title_1)
# 位置
area = re.compile(
'data-el="region">([\u4e00-\u9fa5]+([\u4e00-\u9fa5]+|\d+|[A-Z]+)[\u4e00-\u9fa5]+)[^\u4e00-\u9fa5]+([\u4e00-\u9fa5]+)</a>')
area_content = area.search(i)
x, y, z = area_content.groups()
print(f'{x}-{z}')
# 单价
unit_price = re.compile('<span>(单价\d+元/平米)</span>')
unit_price_1 = unit_price.search(i)
print(unit_price_1.group(1))
# 总价
total_price = re.compile('<span>(\d+\.?\d+)</span>万')
total_price_1 = total_price.search(i)
print(total_price_1.group(1) + '万')
print('*' * 10)

requests相关操作
import requests
URL = 'https://www.baidu.com/'
# User-Agent:将爬虫模拟成浏览器
# Cooike:存放的用户的账户密码信息
headers = {
'User-Agent': ''
}
resp = requests.get(url=URL, headers=headers)
# 状态码
# 200,爬虫可用
# 403,访问的网络将爬虫封了
# 404,页面丢失
# 500,服务器出问题
print(resp.status_code)
# 打印访问的网址
print(resp.url)
# 打印响应头:只需要记住:'Content-Type'
print(resp.headers)
# 打印响应头中提供的编码方式
# 如果没有,默认ISO-8859-1:不能解析中文
print(resp.encoding)
# 打印网页源代码提供的编码方式
print(resp.apparent_encoding)
# resp.encoding = resp.apparent_encoding
# 文本流方式打印网页源码
print(resp.text)
# 以字节流(二进制)输出源码
print(resp.content)














 5240
5240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









