






 本文介绍了一种通用的可变速率图像压缩框架,利用卷积和反卷积LSTM结构,无需为不同速率单独训练。编码器-二值化-解码器架构能渐进重建图像,同时通过二值表示实现高效压缩。研究还展示了LSTM在编码和解码过程中的应用,以及如何通过动态比特分配优化压缩率。
本文介绍了一种通用的可变速率图像压缩框架,利用卷积和反卷积LSTM结构,无需为不同速率单独训练。编码器-二值化-解码器架构能渐进重建图像,同时通过二值表示实现高效压缩。研究还展示了LSTM在编码和解码过程中的应用,以及如何通过动态比特分配优化压缩率。
概要
该文提出了一个可变速率图像压缩的通用框架和一种基于卷积和反卷积LSTM递归网络的新架构。(不需要针对每个速率单独进行训练)
1. Variable Rate Compression Architecture
- Encoder: function E. 以一个图像补丁作为输入,并生成一个编码后的vector(encoded representation)
- Binaryization: function B. 由一个二值化函数B来处理编码后的vector
- Decoder: fuction D. 它接受由B产生的二进制表示,并生成一个重构的图像
数学表达:
x′=D(B(E(x)))(1)
x^{'}=D(B(E(x))) \tag{1}
x′=D(B(E(x)))(1)
2.1 IMAGE COMPRESSION FRAMEWORK
该论文框架是为图像压缩进行调整的,并支持可变的压缩率,而不需要再训练或存储同一图像的多个编码。
为了使连续传输增量信息成为可能,设计应该考虑到图像解码是渐进式的(对质量要求高时,多传几次信息)。考虑到这个设计目标,我们可以考虑建立在残差之上的架构,目的是在解码器获得额外信息时最小化重建中的残差。
Ft(rt−1)=Dt(B(Et(rt−1)))(2)
F_t(r_{t-1})=D_t(B(E_t(r_{t-1}))) \tag{2}
Ft(rt−1)=Dt(B(Et(rt−1)))(2)
rtr_trt的确定方法:
将r0r_0r0设置为等于原始输入补丁,然后rtr_trt对于t>0t>0t>0表示t阶段后的残差。对于rt(t>0)r_t(t>0)rt(t>0)的确定,取决于架构的设计:
-
non-LSTM architectures:
FtF_tFt没有记忆,所以我们只期望它能预残差部分。在这种情况下,通过对所有残差求和来恢复完全重建,每个阶段由于预测与之前残差的差异而受到惩罚.
rt=Ft(rt−1)−rt−1(3) r_t=F_t(r_{t-1})-r_{t-1}\tag{3} rt=Ft(rt−1)−rt−1(3) -
LSTM-based architectures:
对于RNN结构来说,结构是有记忆的。所以我们期望他们在每个阶段预测原始图像。据此,我们计算了相对于原始图像的残差。
rt=Ft(rt−1)−r0(4) r_t=F_t(r_{t-1})-r_{0}\tag{4} rt=Ft(rt−1)−r0(4)
该方法是不需要对所有残差求和的。
2.2 BINARY REPRESENTATION
该文的二值化结构有三个好处:
- bit vectors对于图像传输来说是可序列化/反序列化的
- 网络压缩率的控制仅仅是通过对bit vectors的约束来实现的
- 相对与传统方案来说,此二值化可以提取到更有效的信息
binarization包括两部分:
-
第一部分包括在生成所需要的bit数目,值域在[−1,1]
实现方式:采用fully-connected layer 和 tanh 激活函数
-
第二部分涉及到将这个连续值作为输入,并在集合{−1,1}中产生每个输入对应的离散输出。
b(x)=x+ϵ∈{−1,1}(5) b(x)=x+\epsilon \in\{-1,1\} \tag{5} \\ b(x)=x+ϵ∈{−1,1}(5)ϵ={1−xwith probability1+x2−x−1with probability1−x2 \epsilon = \begin{cases} 1-x& \text{with probability}\frac{1+x}{2}\\ -x-1& \text{with probability} \frac{1-x}{2} \end{cases} ϵ={1−x−x−1with probability21+xwith probability21−x
ϵ\epsilonϵ代表量化噪声。
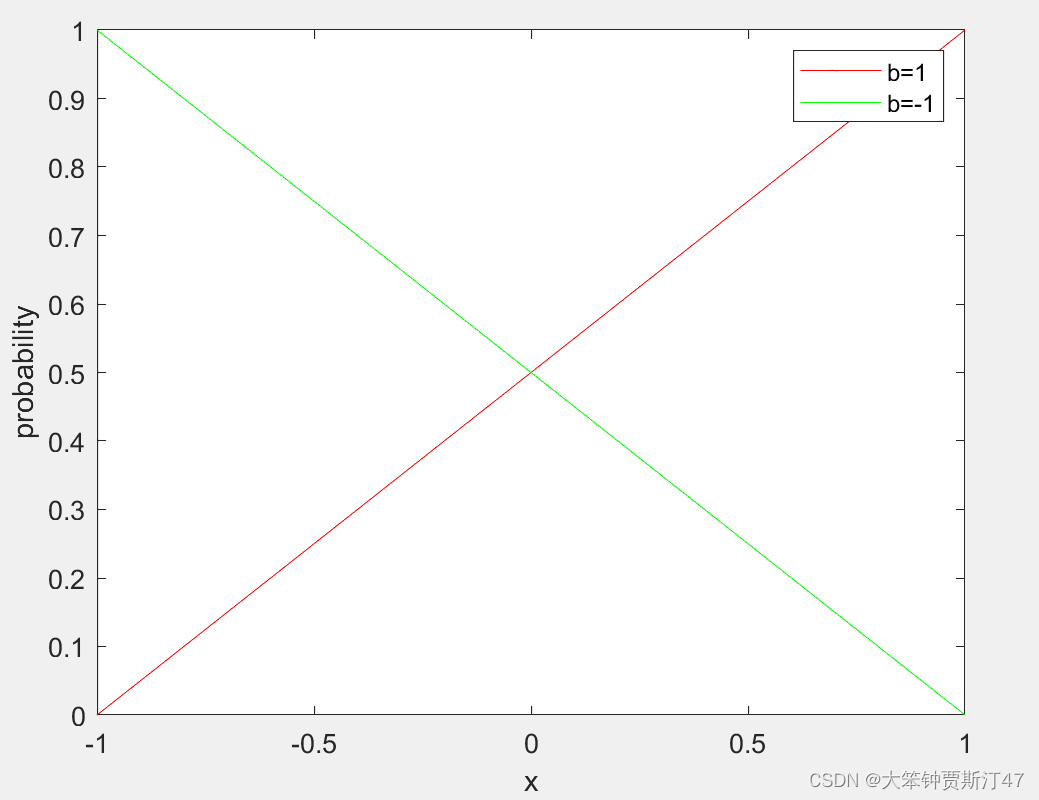
总的来说,Binarization function:
B(x)=b(tanh(Wbinx+bbin))(6)
B(x)=b(tanh(W^{bin}x+b^{bin}))\tag{6}
B(x)=b(tanh(Wbinx+bbin))(6)
为了对一个特定的输入有一个固定的表示,一旦网络被训练,只考虑b(x)最可能的结果,b可以被binfb^{inf}binf代替,定义为:
binf(x)={−1if x<0+1otherwise(7)
b^{inf}(x)=
\begin{cases}
-1& \text{if\ x<0}\\
+1& \text{otherwise} \tag{7}
\end{cases}
binf(x)={−1+1if x<0otherwise(7)
压缩码率是由bit数量决定的。根据上面描述,压缩产生后的码率与WbinW^{bin}Wbin和stage(residual autoencoder数量)的数量有关。
3. architecture
3.1 fully-connected residual autoencoder
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z24Lu0TZ-1646970890503)(C:\Users\Liujiawang\AppData\Roaming\Typora\typora-user-images\image-20220310143845645.png)]](https://i-blog.csdnimg.cn/blog_migrate/13d5fd1c97672f477dfe1e7a0393176e.png)
全连接的残差自动编码器。我们描述了一个双迭代架构,第一次迭代的目标是对原始输入补丁进行编码,第二次迭代的目标是对第一级重构中的残差进行编码。重建图像为各个residual相加。
3.2 fully-connected LSTM residual encoder
在这个体系结构中,我们探索了对编码器和解码器都使用LSTM模型。特别是,E和D都是由堆叠的LSTM层组成的。
我们使用上标来表示layer索引,并使用下标来表示时间步长。比如htl∈Rnh^l_t\in R^nhtl∈Rn代表时间t 的auto-encoder上的第lll层hidden LSTM Layer。我们定义Tnl:Rm——>RnT^l_n: R^m——>R^nTnl:Rm——>Rn是一个映射变换:Tnl(x)=Wlx+blT^l_n(x)=W^lx+b^lTnl(x)=Wlx+bl。⨀\bigodot⨀代表element-wise,ht0h^0_tht0代表在时间ttt上第一个LSTM Layer。
LSTM结构公式表示:
(ifog)=(sigmsigmsigmtanh)T4nl(htl−1ht−1l)(8)
\left(
\begin{matrix}
i \\
f \\
o\\
g
\end{matrix}
\right)=
\left(
\begin{matrix}
sigm \\
sigm \\
sigm\\
tanh\\
\end{matrix}
\right)T^l_{4n}
\left(
\begin{matrix}
h^{l-1}_t \\
h^l_{t-1}\\
\end{matrix}
\right) \tag{8}
⎝⎜⎜⎛ifog⎠⎟⎟⎞=⎝⎜⎜⎛sigmsigmsigmtanh⎠⎟⎟⎞T4nl(htl−1ht−1l)(8)
ctl=f⨀ct−1l+i⨀g(9) c^l_t=f\bigodot c^l_{t-1}+i\bigodot g \tag{9}\\ ctl=f⨀ct−1l+i⨀g(9)
htl=o⨀tanh(ctl)(10) h^l_t=o\bigodot tanh(c^l_t) \tag{10} htl=o⨀tanh(ctl)(10)
sigm代表sigmoid function。
对于编码器,我们使用一个全连接的层,然后是两个堆叠的LSTM层。解码器具有相反的结构:两个堆叠的LSTM层,然后是一个完全连接的层,具有tanh非线性,可以预测RGB值。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qw33LyxH-1646970890504)(C:\Users\Liujiawang\AppData\Roaming\Typora\typora-user-images\image-20220310150946137.png)]](https://i-blog.csdnimg.cn/blog_migrate/7618935d5b245e361035be47180eb450.png)
3.3 forward convolution/deconvolution residual encoder
第3.1节提出了一种全连接的残余自动编码器。我们分别用卷积和反卷积替换encoder和decoder的全连接层来扩展这种结构。解码器的最后一层由1×1卷积组成,三个滤波器将解码后的表示转换为RGB值.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-unJhQQUr-1646970890504)(C:\Users\Liujiawang\AppData\Roaming\Typora\typora-user-images\image-20220310152838611.png)]](https://i-blog.csdnimg.cn/blog_migrate/a60398795106541a79ffdc6a43f1d299.png)
3.4 Convolutional/Deconvolutional LSTM Compression
该体系结构将卷积和反卷积运算符与LSTM相结合。我们用卷积加偏置代替方程(8)中的变换T4nlT^l_{4n}T4nl来定义卷积LSTM结构。具体公式表达为:
T4nl(htl−1,ht−1l)=W1l⨂htl−1+W2l⨂ht−1l+bl(11)
T^l_{4n}(h^{l-1}_t,h^l_{t-1})=W^l_1\bigotimes h^{l-1}_t+W^l_2\bigotimes h^l_{t-1}+b^l \tag{11}
T4nl(htl−1,ht−1l)=W1l⨂htl−1+W2l⨂ht−1l+bl(11)
3.5 dynamic bit assignment
对于这里提出的非卷积方法,通过允许编码器的不同数量的迭代,这样就可以为每个补丁分配不同的比特数。
4. 结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L7I3D9CN-1646970890505)(C:\Users\Liujiawang\AppData\Roaming\Typora\typora-user-images\image-20220310173905151.png)]](https://i-blog.csdnimg.cn/blog_migrate/2686cf27a08d486aa91d982c139aa639.png)
总结
- 该文的网络只需要训练一次(而不是每张图像),而不管输入图像的尺寸和期望的压缩率
- 该文的网络是渐进的,这意味着发送的比特越多,图像重建就越准确
- 对于给定的比特数,所提出的架构至少与一个标准的专门训练的自动编码器一样有效(在32×32的大规模基准测试中,我们基于LSTM的方法提供了比JPEG、JPEG2000和WebP更好的视觉质量,存储大小减少了10%或更多)
Reference:Variable rate image compression with recurrent neural networks

















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









