






Redis
nosql
Nosql概述:
为什么要用Nosql
-
单机MySQL的年代!
app —> dal —>Mysql
-
Memcached(缓存)+ MySql + 垂直拆分(读写分离)
优化数据结构和索引 --> 文件缓存(IO)–> Memcached(当时最热门的技术!)
-
分库分表 + 水平拆分 + MySQL集群
本质:数据库(读、写)
早些年MyISAM:表锁,十分影响效率!高并发下就会出现严重的锁问题
转战Innodb : 行锁
慢慢就开始了分库分表来缓解压力!
什么是Nosql
NoSQL = Not Only Sql (不仅仅是sql)
泛指非关系型数据库
NoSql特点:
解耦!
-
方便扩展!(数据之间没有关系,很好扩展!)
-
大数据量高性能!(Redis 一秒写8万次,读取11万次)
-
数据类型是多样型的!(不需要实现设计数据库!随取随用!)
-
传统RDBMS 和 NoSQL
传统的 RDBMS - 结构化组织 - SQL - 数据和关系都存在单独的表中 - 操作数据,数据定义语言 - 严格的一致性 - 基础的事务 - .......NoSql - 不仅仅是数据 - 没有固定的查询语言 - 键值对存储,列存储,文档储存,图形化存储 - 最终一致性 - CAP定理BASE - 高性能、高可用、高可扩展 - .......
阿里巴巴框架演进
nosql 数据模型
KV键值对:
- 新浪:Redis
- 美团:Redis + Tair
- 阿里、百度:Redis + memecache
文档型数据库:
- MongoDB
- MonoDB是一个基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档
- MonoDB是一个介于关系型数据库和非关系型数据库中中间的产品 (MonoDB是非关系型数据库功能最丰富的,最想关系型数据库)
- ConthDB
列存储:
- HBase
- 分布式文件系统
图形化数据库:
- 他不是存图形的,放的是关系,比如:朋友圈社交网络、广告推荐!
- Neo4J、InfoGrid
Nosql 四大分类
CAP
BASE
Redis入门
Redis是什么!
Redis(Remote Dictionary Server ),即远程字典服务
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
免费和开源!是当下最热门的NoSql 技术之一!也被人们称为架构化数据库
Redis能干什么!
- 内存储存、持久化、内存中的数据是断电及失、所以说持久化很重要!(rdb、aof)
- 效率高、可以用于告诉缓存
- 发布订阅系统
- 地图信息分析
- 计时器、计数器、(数据浏览量)
- ……
Redis特性!
- 持久化
- 多样化数据库
- 集群
- 事务
- ……
安装Redis
Windows安装
windows :下载地址
下载完成解压
启动Redis服务器:
双击运行服务 redis-server.exe
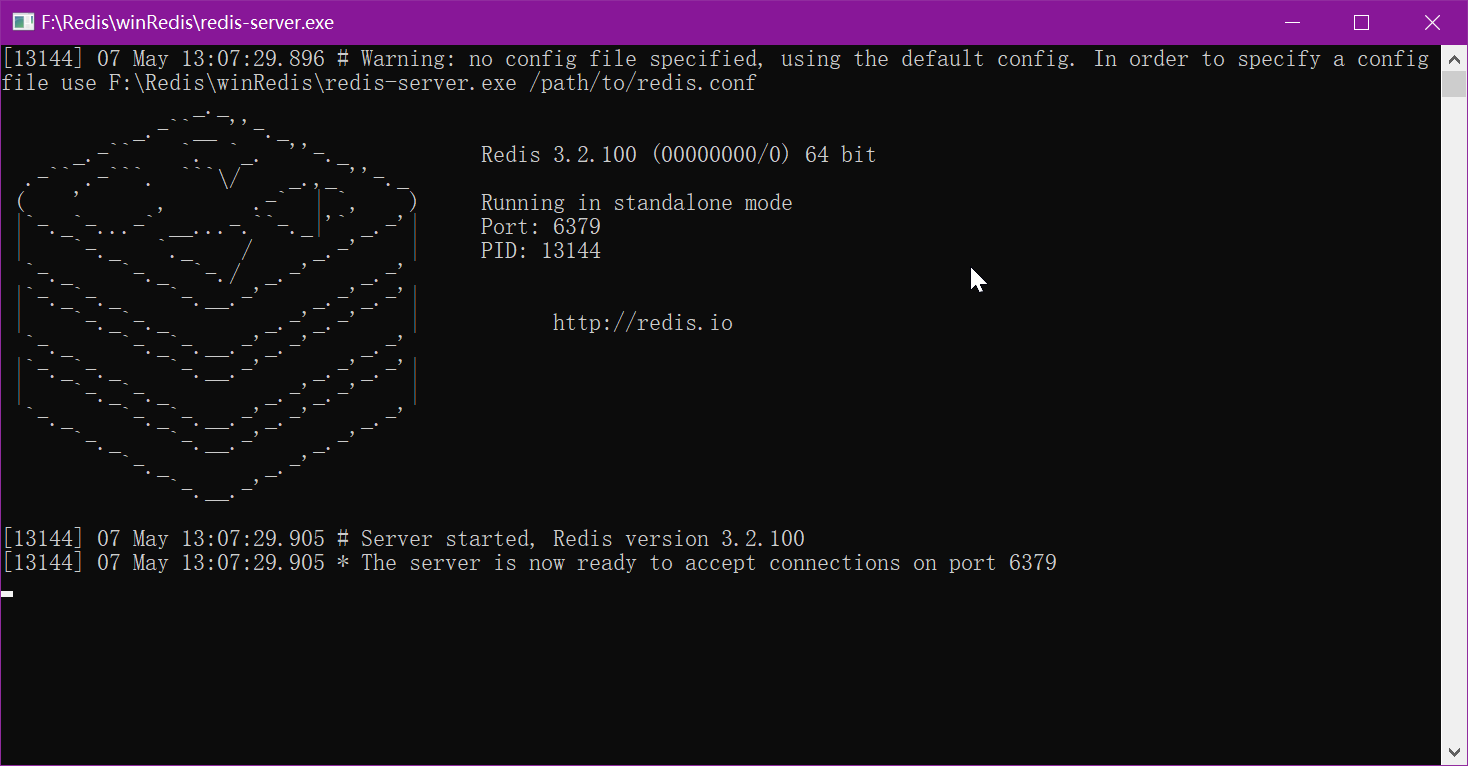
运行成功
再次运行redis客户端 启动 redis-cli.exe
127.0.0.1:6379> ping ----> 测试是否连接成功
PONG
127.0.0.1:6379> set name changan -----> 设置 key value
OK
127.0.0.1:6379> get name ------> 用 key 去寻找 value
"changan"
Linux安装
官网下载:地址
下载完成之后导入到 Liunx 的 opt 目录下面
执行 tar -zxvf redis... 进行解压
解压完成只要需要安装c++ 环境 yum -y install gcc-c++
安装完成执行 make
执行完成之后在执行一遍
然后执行 make install
redis 的默认路径在 usr/local/bin目录下面

移动 redis.config 到 本目录下

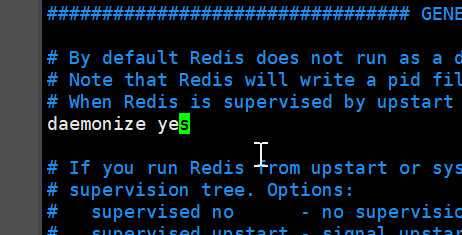
redis默认不是后台启动,我们需要修改配置文件
找到这个修改为 yes
启动redis 服务

测试连接
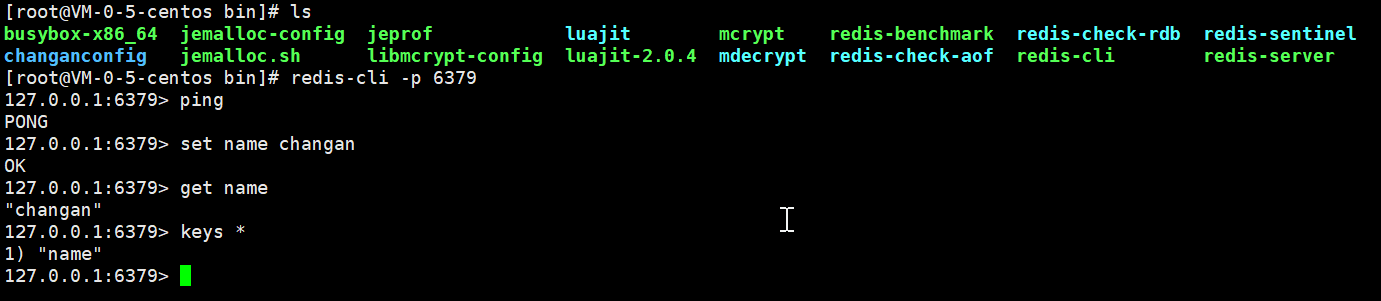
查看redis服务信息

关闭redis
127.0.0.1:6379> shutdown --->关闭redis
not connected> exit ---> 退出
redis性能测试
| 序号 | 选项 | 描述 | 默认值 |
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | –csv | 以 CSV 格式输出 | |
| 12 | -l | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | -I | Idle 模式。仅打开 N 个 idle 连接并等待。 |
测试 使用 redis-benchmark
测试 :100个并发连接, 100000 请求
redis-benchmark -h 127.0.0.0 -p 6379 -c 100 -n 100000
====== PING_INLINE ======
100000 requests completed in 2.31 seconds ----> 对我们10w请求进行测试
100 parallel clients -----> 100个并发的客服端
3 bytes payload ----> 每次写入3个字节
keep alive: 1 ---> 只有一台服务器来处理这些请求,单机性能
host configuration "save": 3600 1 300 100 60 10000
host configuration "appendonly": no
multi-thread: no
====== SET ======
100000 requests completed in 2.31 seconds
100 parallel clients
3 bytes payload
keep alive: 1
host configuration "save": 3600 1 300 100 60 10000
host configuration "appendonly": no
multi-thread: no
Latency by percentile distribution:
0.000% <= 0.935 milliseconds (cumulative count 1)
50.000% <= 1.599 milliseconds (cumulative count 50402)
75.000% <= 1.895 milliseconds (cumulative count 75422)
87.500% <= 2.039 milliseconds (cumulative count 87552)
93.750% <= 2.143 milliseconds (cumulative count 93953)
96.875% <= 2.487 milliseconds (cumulative count 96893)
98.438% <= 3.607 milliseconds (cumulative count 98439)
99.219% <= 6.535 milliseconds (cumulative count 99219)
99.609% <= 12.039 milliseconds (cumulative count 99613)
99.805% <= 12.583 milliseconds (cumulative count 99805)
99.902% <= 13.031 milliseconds (cumulative count 99903)
99.951% <= 13.479 milliseconds (cumulative count 99952)
99.976% <= 13.775 milliseconds (cumulative count 99976)
99.988% <= 13.927 milliseconds (cumulative count 99988)
99.994% <= 14.007 milliseconds (cumulative count 99994)
99.997% <= 14.039 milliseconds (cumulative count 99997)
99.998% <= 14.071 milliseconds (cumulative count 99999)
99.999% <= 14.087 milliseconds (cumulative count 100000)
100.000% <= 14.087 milliseconds (cumulative count 100000)
基础知识
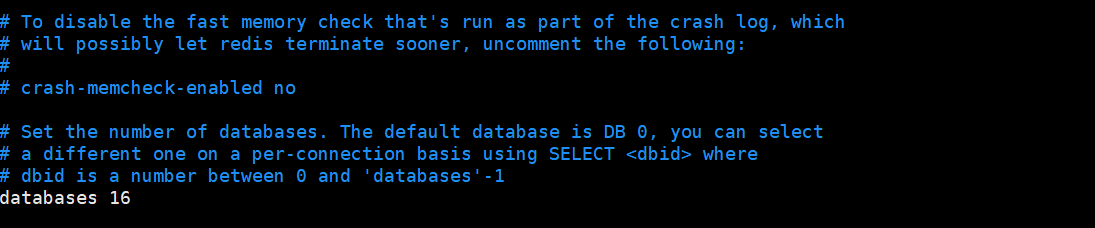
Redis默认数据库
Redis默认有16个数据库,默认使用第0个
- select 2 ----> 更换数据库
- dbsize -----> 查看数据库大小
- keys * ------> 查看数据库所有的key
- flushdb --------> 清空当前数据库
- flushall ------> 清空所有库
[root@VM-0-5-centos changanconfig]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> select 2 ----> 更换数据库
OK
127.0.0.1:6379[2]> dbsize -----> 查看数据库大小
(integer) 0
127.0.0.1:6379[2]>
Redis数据类型
五种基本数据类型
- Redis-key
- String
- List
- Set
- Hash
- Zset
Redis-key
keys * 查看当前库所有的key
exists name 判断namekey 是否存在
move name 1 移除 name
expire name 10 设置name 10秒钟之后过期
ttl name 查看过期时间
type name 查看当前 key 的类型
String
append 追加字符串
127.0.0.1:6379> keys *
1) "name"
2) "age"
127.0.0.1:6379> get name
"changan"
127.0.0.1:6379> append name love
(integer) 11
127.0.0.1:6379> get name
"changanlove"
127.0.0.1:6379> exists name
(integer) 1
incr views 给 views 加1
decr views 给 views 减1
incrby views 给 views 加10
decrby views 给 views 减10
127.0.0.1:6379> set views 0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views
(integer) 1
127.0.0.1:6379> decr views
(integer) 0
127.0.0.1:6379> incrby views 10
(integer) 10
127.0.0.1:6379> decrby views 10
getrange 范围查询数据
127.0.0.1:6379> getrange key1 0 3
"hell"
127.0.0.1:6379> getrange key1 0 -1
"hello,word"
127.0.0.1:6379> getrange key1 5 -1
",word"
127.0.0.1:6379> getrange key1 5 0
""
127.0.0.1:6379> getrange key1 1 -1
"ello,word"
127.0.0.1:6379> getrange key1 0 -1
setrange 范围修改
127.0.0.1:6379> setrange key1 1 xx
(integer) 10
127.0.0.1:6379> keys *
1) "key1"
127.0.0.1:6379> get key1
"hxxlo,word"
常在分布式锁使用
127.0.0.1:6379> setex key2 30 "hello" ---- > 设置过期时间
OK
127.0.0.1:6379> ttl key2 ---- > 查看剩余时间
(integer) 28
127.0.0.1:6379> setnx mykey "redis" ---- > 如果 mykey 不存在,创建 mykey 返回1
(integer) 1
127.0.0.1:6379> keys *
1) "key2"
2) "key1"
3) "mykey"
127.0.0.1:6379> ttl key2
(integer) -2
127.0.0.1:6379> setnx mykey "MongDB" ---- > 如果 mykey 存在,就创建失败 返回0
(integer) 0
127.0.0.1:6379> get mykey
"redis"
批量获取值和设置值
mset 批量设置
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> keys *
1) "k3"
2) "k2"
3) "k1"
mget 同时获取多个值
127.0.0.1:6379> mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
msetnx 设置多个值 如果一个值设置失败,那么全部失败 (原子性)
127.0.0.1:6379> msetnx k1 v1 k5 v5
(integer) 0
getset 先获取在设置
127.0.0.1:6379> getset db redis --> 不存在返回nil并创建
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongDb --> 如果存在,返回当前的值,并设置新的值
"redis"
127.0.0.1:6379> get db
"mongDb"
应用场景
- 计数器
- 统计多单位数量
- 粉丝数
- 对象缓存存储
List
基本数据类型,列表
lpush 储存 《左存储》
rpush 储存 《右存储》
lrange 读取
127.0.0.1:6379> lpush list one ---> 给左push
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> lrange list 0 1
1) "three"
2) "two"
#####################################################################
127.0.0.1:6379> rpush list yss
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "yss"
lpop : 左移除
rpop : 右移除
127.0.0.1:6379> lpop list ----> 移除list第一个元素
"three"
127.0.0.1:6379> rpop list ----> 移除list最后一个元素
"yss"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
lindex 通过下标获取值
127.0.0.1:6379> lindex list 0
"two"
127.0.0.1:6379> lindex list 1
"one"
llen 获取list的长度
127.0.0.1:6379> llen list
(integer) 4
lrem 删除 ‘精确匹配’
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
3) "asdfa"
4) "9889"
5) "9889"
127.0.0.1:6379> lrem list 1 asdfa ----- > 删除 1个 asdfa
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
3) "9889"
4) "9889"
127.0.0.1:6379> rpush list 9889
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
3) "9889"
4) "9889"
127.0.0.1:6379> lrem list 2 9889 ------ > 删除 2个 9889
(integer) 2
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
ltrim 修剪
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "hello1"
(integer) 2
127.0.0.1:6379> rpush mylist "hello2"
(integer) 3
127.0.0.1:6379> rpush mylist "hello3"
(integer) 4
127.0.0.1:6379> ltrim mylist 1 2 ----- > 通过下标截取指定长度
OK
127.0.0.1:6379> lrange mylist 0 -1
1) "hello1"
2) "hello2"
rpoplpush 移除列表的最后一个元素 并移动到新的列表中
127.0.0.1:6379> lrange mylist 0 -1
1) "hello1"
2) "hello2"
3) "hello3"
127.0.0.1:6379> rpoplpush mylist myotherlist
"hello3"
127.0.0.1:6379> lrange mylist 0 -1
1) "hello1"
2) "hello2"
127.0.0.1:6379> lrange myotherlist 0 -1
1) "hello3"
lset 将列表中指定下标的值替换为另外一个
127.0.0.1:6379> exists list --- > 判断是否有这个集合
(integer) 0
127.0.0.1:6379> lset list 0 item ----- > 给list的第0个下标添加 item
(error) ERR no such key ---> 报错,添加失败 没有这个list
127.0.0.1:6379> lpush list value1 ------ > 创建 list
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "value1"
127.0.0.1:6379> lset list 0 item ----- > 再次用 lset 覆盖 刚创建那个list的第0个下标
OK
127.0.0.1:6379> lrange list 0 -1
1) "item"
127.0.0.1:6379> lset list 1 item -----> 如果给list添加值 这个下标不存在那么就会报错
(error) ERR index out of range
linsert 将某一个具体的值插入列表某个元素的前后
参数:``before左、前after` 右、后
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "word"
(integer) 2
// before
127.0.0.1:6379> linsert mylist before "word" "other"
(integer) 3
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "word"
// after
127.0.0.1:6379> linsert mylist after "word" "king"
(integer) 4
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "word"
4) "king"
小结
-
set实际是一个链表,before Node after,left ,right 都可以插入值
-
如果key 不存在,创建新的链表
-
如果key 存在,新增内容
-
如果移除了所有的值,空链表,也代表不存在
-
在两边插入或改动值,效率最高!中间元素,相对来说效率会第一点
可以用来 消息排队! 消息队列(Lpush Rpop) 左进右出 ,栈(Lpush Lpop)左进左出
Set
set中的值不能重复
sadd
smembers
sismember
scard
127.0.0.1:6379> sadd myset hello ----> 给集合添加值
(integer) 1
127.0.0.1:6379> sadd myset changan
(integer) 1
127.0.0.1:6379> sadd myset king
(integer) 1
127.0.0.1:6379> SMEMBERS myset -----> 查看当前集合元素
1) "king"
2) "changan"
3) "hello"
127.0.0.1:6379> SISMEMBER myset hello -----> 查看集合是否有hello 有的话返回1 没有就是0
(integer) 1
127.0.0.1:6379> SISMEMBER myset word
(integer) 0
127.0.0.1:6379> scard myset ------> 获取当前集合的个数
(integer) 3
127.0.0.1:6379> srem myset hello -----> 删除集合指定的值
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "king"
2) "changan"
SRANDMEMBER 随机从集合中筛选一个数据
127.0.0.1:6379> SRANDMEMBER myset
"king"
127.0.0.1:6379> SRANDMEMBER myset
"king"
127.0.0.1:6379> SRANDMEMBER myset
"king"
127.0.0.1:6379> SRANDMEMBER myset
"king"
127.0.0.1:6379> SRANDMEMBER myset
"changan"
spop 随机删除一个元素
127.0.0.1:6379> SMEMBERS myset
1) "king"
2) "changan"
127.0.0.1:6379> spop myset
"king"
127.0.0.1:6379> SMEMBERS myset
1) "changan"
smove将一个指定的值移动到另外一个set集合中
127.0.0.1:6379> sadd myset hello
(integer) 1
127.0.0.1:6379> sadd myset word
(integer) 1
127.0.0.1:6379> sadd myset changanking
(integer) 1
127.0.0.1:6379> sadd myset king
(integer) 1
127.0.0.1:6379> sadd myset2 set2
(integer) 1
127.0.0.1:6379> smove myset myset2 changanking
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "word"
2) "hello"
3) "changan"
4) "king"
127.0.0.1:6379> SMEMBERS myset2
1) "changanking"
2) "set2"
SDIFF 查看2个集合的差集
SINTER 查看2个集合的交集 共同好友就可以实现
SUNION 查看2个集合的
127.0.0.1:6379> sadd key1 a
(integer) 1
127.0.0.1:6379> sadd key1 b
(integer) 1
127.0.0.1:6379> sadd key1 c
(integer) 1
127.0.0.1:6379> sadd key2 c
(integer) 1
127.0.0.1:6379> sadd key2 d
(integer) 1
127.0.0.1:6379> sadd key2 e
(integer) 1
127.0.0.1:6379> SDIFF key1 key2
1) "a"
2) "b"
127.0.0.1:6379> SINTER key1 key2
1) "c"
127.0.0.1:6379> SUNION key1 key2
1) "c"
2) "b"
3) "a"
4) "d"
5) "e"
应用场景
微博 ,A用户将所有的关注的人放在一个set集合中,将他的粉丝也放在一个集合中
共同关注,共同爱好,二度好友,推荐好友!
Hash
Map集合,Key–Value
127.0.0.1:6379> hset map k changan ----> 给map存一个k-v
(integer) 1
127.0.0.1:6379> hget map k ----> 通过k取值
"changan"
127.0.0.1:6379> hmset map y king u anuyn ----> 给map存多个值
OK
127.0.0.1:6379> hmget map y u ----> 获取map多个值
1) "king"
2) "anuyn"
127.0.0.1:6379> hgetall map ------> 查看map所有的kv
1) "k"
2) "changan"
3) "y"
4) "king"
5) "u"
6) "anuyn"
hdel 删除指定的kv
127.0.0.1:6379> hdel map u -----> 删除指定的 k
(integer) 1
127.0.0.1:6379> hgetall map
1) "k"
2) "changan"
3) "y"
4) "king"
hlen 查询集合有几组kv
127.0.0.1:6379> hlen map
(integer) 2
HEXISTS 查看集合的k是否存在
127.0.0.1:6379> HEXISTS map k
(integer) 1
127.0.0.1:6379> HEXISTS map u
(integer) 0
hkeys 查看所有的key
hvals 查看所有的value
127.0.0.1:6379> hkeys map
1) "k"
2) "y"
127.0.0.1:6379> hvals map
1) "changan"
2) "king"
HINCRBY 指定增量
hsetnx 创建一个集合 如果这个集合没有数据 就放入数据 返回1 如果有数据 那么返回0
127.0.0.1:6379> hset myhash field3 5 ----- >>> 指定增量
(integer) 1
127.0.0.1:6379> HINCRBY myhash field3 1 ------>>> 给数据加一
(integer) 6
127.0.0.1:6379> HINCRBY myhash field3 -1 ------>>>> 给数据减一
(integer) 5
127.0.0.1:6379> hsetnx myhash field4 hello -------> 创建一个集合 如果存在则不能设置 返回1
(integer) 1
127.0.0.1:6379> hsetnx myhash field4 world ---->> 创建一个集合 如果存在则不能设置 返回0
(integer) 0
hash可以用于存储对象
127.0.0.1:6379> hset user:1 name changan
(integer) 1
127.0.0.1:6379> hget user:1 name
"changan"
127.0.0.1:6379> hset user:1 age 23
(integer) 1
127.0.0.1:6379> hget user:1 age
"23"
应用场景
hash 用来处理变更的数据 user name age ,尤其是用户信息之类,经常变动的信息! hash 更适合与对象的存储,String 适合字符串的存储!
Zset(有序集合)
在set的基础上加了一个值
api:
127.0.0.1:6379> zadd myset 1 one -----> 创建一个值
(integer) 1
127.0.0.1:6379> zadd myset 2 two 3 three -----> 创建2个值
(integer) 2
127.0.0.1:6379> zrange myset 0 -1 ------> 获取myset 里的数据
1) "one"
2) "two"
3) "three"
zrangebyscore : 从低到高 进行排序
zrevrange : 从高到低 进行排序
127.0.0.1:6379> zadd salary 5000 xiaohong
(integer) 1
127.0.0.1:6379> zadd salary 2500 xiaoming
(integer) 1
127.0.0.1:6379> zadd salary 500 zhangsan
(integer) 1
127.0.0.1:6379> zrangebyscore salary -inf +inf ---- > 通过集合salary 的 钱数排序 -inf 负无穷 +inf 正无穷
从低到高
1) "zhangsan"
2) "xiaoming"
3) "xiaohong"
127.0.0.1:6379> zrevrange salary 0 -1
1) "xiaoming"
2) "zhangsan"
127.0.0.1:6379> zrangebyscore salary -inf +inf withscores -->> 查询出来所有数据 WITHSCORES会返回元素和其分数
1) "zhangsan"
2) "500"
3) "xiaoming"
4) "2500"
5) "xiaohong"
6) "5000"
127.0.0.1:6379> zrangebyscore salary -inf 2500 withscores
1) "zhangsan"
2) "500"
3) "xiaoming"
4) "2500"
zrem 移除
127.0.0.1:6379> zrange salary 0 -1
1) "zhangsan"
2) "xiaoming"
3) "xiaohong"
127.0.0.1:6379> zrem salary xiaohong
(integer) 1
zcard 获取集合中的个数
127.0.0.1:6379> zcard salary
(integer) 2
zcount 获取指定区间的成员数量
127.0.0.1:6379> zadd myset 1 "hello" 2 "word" 3 "changan"
(integer) 3
127.0.0.1:6379> zcount myset 1 2
(integer) 2
127.0.0.1:6379> zcount myset 1 3
(integer) 3
使用场景
set 排序 存储班级成绩,工资排序
普通消息 1、重要消息 2 带权重进行判断
排行榜应用实现 取 Top N测试
三种特殊数据类型
geospatial 地理位置
Redis 的 Geo 可以去实现 推算2地之间的距离,推算地理位置信息 … !
测试数据网站:http://www.toolzl.com/tools/gps.html

Geoadd 添加地理位置
- 2极地区无法直接添加,我们一般会下载城市数据,用Java程序导入
将指定的地理空间位置(纬度、经度、名称)添加到指定的key中
- 有效经度为-180至180度。
- 有效纬度为-85.05112878至85.05112878度。
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqi 114.05 22.52 shenzhen
(integer) 2
127.0.0.1:6379> geoadd china:city 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 2
geopos 查询地理位置
127.0.0.1:6379> geopos china:city beijing
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
127.0.0.1:6379> geopos china:city xian
1) 1) "108.96000176668167114"
2) "34.25999964418929977"
geodist
返回两个给定位置之间的距离。
如果两个位置之间的其中一个不存在, 那么命令返回空值。
指定单位的参数 unit 必须是以下单位的其中一个:
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
127.0.0.1:6379> geodist china:city beijing xian km 北京到西安的直线距离
"910.0565"
127.0.0.1:6379> geodist china:city beijing shanghai km 北京带上海的直线距离
"1067.3788"
附近的人
半径搜索
127.0.0.1:6379> georadius china:city 110 30 1000 km 以 110,30的地理坐标 查询 1000km 内的城市
1) "chongqi"
2) "xian"
3) "shenzhen"
4) "hangzhou"
127.0.0.1:6379> georadius china:city 110 30 500 km 以 110,30的地理坐标 查询 500km 内的城市
1) "chongqi"
2) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist 到中心的直线距离
1) 1) "chongqi"
2) "341.9374"
2) 1) "xian"
2) "483.8340"
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord 经纬度
1) 1) "chongqi"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) 1) "108.96000176668167114"
2) "34.25999964418929977"
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord count 1 查询指定数量的
1) 1) "chongqi"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
GEORADIUSBYMEMBER
找出位于指定元素周围的其他元素
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 1000 km
1) "beijing"
2) "xian"
127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 500 km
1) "beijing"
删除、查看
127.0.0.1:6379> zrange china:city 0 -1 查看所有
1) "chongqi"
2) "xian"
3) "shenzhen"
4) "hangzhou"
5) "shanghai"
6) "beijing"
127.0.0.1:6379> zrem china:city beijing 删除
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1
1) "chongqi"
2) "xian"
3) "shenzhen"
4) "hangzhou"
5) "shanghai"
Hyperloglog 基数统计
什么是基数!
A{ 1、3、5、7、8、7 }
B{ 1、3、5、7、8 }
基数 (不重复的元素)= 5,可以接收误差!
简介
pfadd :添加数据
pfcount :查询数据
pfmerge :合并数据
127.0.0.1:6379> pfadd mykey a b c d e f g h i j k
(integer) 1
127.0.0.1:6379> pfcount mykey
(integer) 11
127.0.0.1:6379> pfadd mykey2 b c d t y o p
(integer) 1
127.0.0.1:6379> pfcount mykey2
(integer) 7
127.0.0.1:6379> pfmerge mykey3 mykey mykey2
OK
127.0.0.1:6379> pfcount mykey3
(integer) 14
Bitmaps(位图) 位存储
只要是2位数的 数据结构就可以用
如:登录、未登录 活跃、不活跃
设置或者清空key的value(字符串)在offset处的bit值。
那个位置的bit要么被设置,要么被清空,这个由value(只能是0或者1)来决定。当key不存在的时候,就创建一个新的字符串value
测试
测试打卡记录 在2021年4月15日没有打卡等
setbit 存值
getbit 取值
bitcount 查询
127.0.0.1:6379> setbit sign 20210415 0
(integer) 0
127.0.0.1:6379> setbit sign 20210416 1
(integer) 0
127.0.0.1:6379> setbit sign 20210414 0
(integer) 0
127.0.0.1:6379> setbit sign 20210413 1
(integer) 0
127.0.0.1:6379> setbit sign 20210412 1
(integer) 0
127.0.0.1:6379> setbit sign 20210417 1
(integer) 0
127.0.0.1:6379> getbit sign 20210416
(integer) 1
127.0.0.1:6379> getbit sign 20210415
(integer) 0
127.0.0.1:6379> bitcount sign
(integer) 4
事务
Redis 事务本质:一组命令的集合!
一个事务中所有的命令都会被序列化,在事务执行过程中,会按照顺序执行!
一次性、序列型、非它性、
Redis事务没有隔离级别的概念
Redis 单条命令是保存原子性的、但是事务不保证原子性
所有的命令在事务中,并没有直接被执行!只有发起执行命令的时候才会执行!–Exec
Redis的事务:
- 开启事务 (multi)
- 命令入队 ( )
- 执行命令 (exec)
测试:
127.0.0.1:6379> multi // > 开启事务
OK
127.0.0.1:6379(TX)> set k1 1 // 命令入队
QUEUED
127.0.0.1:6379(TX)> set k1 2
QUEUED
127.0.0.1:6379(TX)> set k1 3
QUEUED
127.0.0.1:6379(TX)> set k2 2
QUEUED
127.0.0.1:6379(TX)> set k3 4
QUEUED
127.0.0.1:6379(TX)> set k4 6
QUEUED
127.0.0.1:6379(TX)> get k4
QUEUED
127.0.0.1:6379(TX)> set k7 9
QUEUED
127.0.0.1:6379(TX)> exec // 执行事务
1) OK
2) OK
3) OK
4) OK
5) OK
6) OK
7) "6"
8) OK
放弃事务:
127.0.0.1:6379> multi // 开启事务
OK
127.0.0.1:6379(TX)> set key7 7
QUEUED
127.0.0.1:6379(TX)> discard // 取消事务
OK
127.0.0.1:6379> get key7
(nil)
编译型异常: 命令错误
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 2
QUEUED
127.0.0.1:6379(TX)> set k2 4
QUEUED
127.0.0.1:6379(TX)> set k4 5
QUEUED
127.0.0.1:6379(TX)> getset k7 8
QUEUED
127.0.0.1:6379(TX)> getset k9 //错误语法
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379(TX)> set k8 9
QUEUED
127.0.0.1:6379(TX)> exec
(error) EXECABORT Transaction discarded because of previous errors.
/*提示语法错误,所有命令都不执行 **/
127.0.0.1:6379> get k4
(nil)
运行时异常:如果命令中存在错误,不会影响其他命令执行
127.0.0.1:6379> set k1 7
OK
127.0.0.1:6379> set k2 "j9"
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> incr k2 // 会执行失败
QUEUED
127.0.0.1:6379(TX)> set k3 3
QUEUED
127.0.0.1:6379(TX)> set k4 5
QUEUED
127.0.0.1:6379(TX)> get k4
QUEUED
127.0.0.1:6379(TX)> exec
1) (error) ERR value is not an integer or out of range
// 虽然第一条命令执行失败了后面的命令会继续执行
2) OK
3) OK
4) "5"
127.0.0.1:6379> get k3
"3"
127.0.0.1:6379> get k4
"5"
监控
悲观锁:
认为什么时候都会出现问题,无论做什么都会加锁
乐观锁:
-
认为什么时候都不会出现问题,所以不会上锁、可以更新数据的时候去判断一下,在此期间是否有人修改过这个数据
-
获取 version
-
更新的时候比较 version
数据测试:
单线程
127.0.0.1:6379> set money 100 // 设置金钱是100
OK
127.0.0.1:6379> set out 0 // 设置金钱是0
OK
127.0.0.1:6379> watch money // 给money上锁
OK
127.0.0.1:6379> multi // 开启事务
OK
127.0.0.1:6379(TX)> decrby money 20 // money金钱减 20
QUEUED
127.0.0.1:6379(TX)> incrby out 20 // out 加 220
QUEUED
127.0.0.1:6379(TX)> exec
1) (integer) 80
2) (integer) 20
多线程
使用 watch 来当做Redis的乐观锁
// 线程 1
127.0.0.1:6379> watch money // 开启监控
OK
127.0.0.1:6379> multi // 开启事务
OK
127.0.0.1:6379(TX)> decrby money 10 // 金币减10
QUEUED
127.0.0.1:6379(TX)> incrby out 10 // 金币加10
QUEUED
// 线程 2
127.0.0.1:6379> incrby money 1000 // 线程2 给这个用户 充值 1000
(integer) 1080
// 线程 1
127.0.0.1:6379(TX)> exec // 线程 1 继续执行 然后就会执行失败
(nil)
如果修改失败获取最新的值即可
解决办法:
127.0.0.1:6379> unwatch // 放弃旧的锁
OK
127.0.0.1:6379> watch money // 加新锁
OK
127.0.0.1:6379> multi // 开启事务
OK
127.0.0.1:6379(TX)> decrby money 100
QUEUED
127.0.0.1:6379(TX)> incrby out 100
QUEUED
127.0.0.1:6379(TX)> exec
1) (integer) 1000
2) (integer) 120
Jedis
什么是Jedis
Jedis是Redis 推荐使用的Java开发工具!使用Java操作中间件!
测试
1、导入依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.5.2</version>
</dependency>
<!-- fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
2、编码测试
连接数据库
public static void main(String[] args) {
Jedis jedis = new Jedis("XXXXXXX",6379); // ip地址及端口号
jedis.auth("---"); //redis 密码
System.out.println(jedis.ping());
}
本地访问 直接 Jedis jedis = new Jedis("127.0.0.1",6379);
输出 PONG 连接成功
操作命令
…
事务:
RedisApi api = new RedisApi();
Jedis jedis = api.connection();
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","word");
jsonObject.put("name","changan");
Transaction multi = jedis.multi();
String toString = jsonObject.toJSONString();
try {
multi.set("user1",toString); //注意事务执行的话要用事务 multi.set 而不是jedis.set
multi.set("user2",toString);
// int i = 1/0;
multi.exec();
}catch (Exception e){
multi.discard();
e.printStackTrace();
}finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
}
断开连接
jedis.close()
SpringBoot整合
说明:在SpringBoot2.x 之后 Jedis 被替换成为了 lettuce
区别:
- Jedis : 采用直连方式 、是不安全的,要避免安全隐患要采用 Jedis的pool连接池管理! 像BIO
- lettuce : 采用netty 实例可以在多个进程中共享、不存在线程不安全问题 像NIO
整合
-
添加依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> -
配置Redis
spring: redis: host: 服务器地址 port: 6379 password: redis密码 -
测试
@Resource private RedisTemplate redisTemplate; @Test void contextLoads() { RedisConnection connection = Objects.requireNonNull(redisTemplate.getConnectionFactory()).getConnection(); System.out.println(connection.ping()); // 测试链接是否成功 redisTemplate.opsForValue().set("key","changan"); // 操纵字符串 set 一个值 Object key = redisTemplate.opsForValue().get("key"); // 获取值 System.out.println(key); }-
redisTemplate.opsForValue() 操作字符串
-
redisTemplate.opsForList() 操作list
-
等
-
connection.close(); // 关闭链接 connection.flushAll(); // 清空所有数据库的所有 key connection.flushDb(); // 清空
-
测试
@Test
public void UserTest() throws JsonProcessingException {
RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
connection.flushDb();
User user = new User("长安",23);
String s = new ObjectMapper().writeValueAsString(user); // 转化为Json 数据
redisTemplate.opsForValue().set("user",s);
System.out.println(redisTemplate.opsForValue().get("user"));
}
// 输出结果 {"name":"长安","age":23}
如果我们直接传对象没有序列化 ,会报错
@Test
public void UserTest() throws JsonProcessingException {
RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
connection.flushDb();
User user = new User("长安",23);
redisTemplate.opsForValue().set("user",user);
System.out.println(redisTemplate.opsForValue().get("user"));
}
//Cannot serialize; nested exception is org.springframework.core.serializer.support.SerializationFailedException: Failed to serialize object using DefaultSerializer; nested exception is java.lang.IllegalArgumentException: DefaultSerializer requires a Serializable payload but received an object of type [com.changan.model.User]
如果要传递对象要序列化
public class User implements Serializable {
private String name;
private int age;
}
// 结果 User(name=长安, age=23)
编写一个自己的 Redis 序列化
@Configuration
public class RedisConfig {
// 配置自己的Redis 固定模板
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 我们为了自己开发方便,一般直接使用<String,Object>
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
// Json序列化配置
Jackson2JsonRedisSerializer<Object> jsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jsonRedisSerializer.setObjectMapper(objectMapper);
// String 的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key 采用String 方式序列化
template.setKeySerializer(stringRedisSerializer);
// hash 的key 采用String 方式序列化
template.setHashKeySerializer(stringRedisSerializer);
// Value 采用Json 序列化
template.setValueSerializer(jsonRedisSerializer);
// hash 的 Value 采用Json 序列化
template.setHashValueSerializer(jsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
Redis.conf详解
单位

包含 INCLUDES
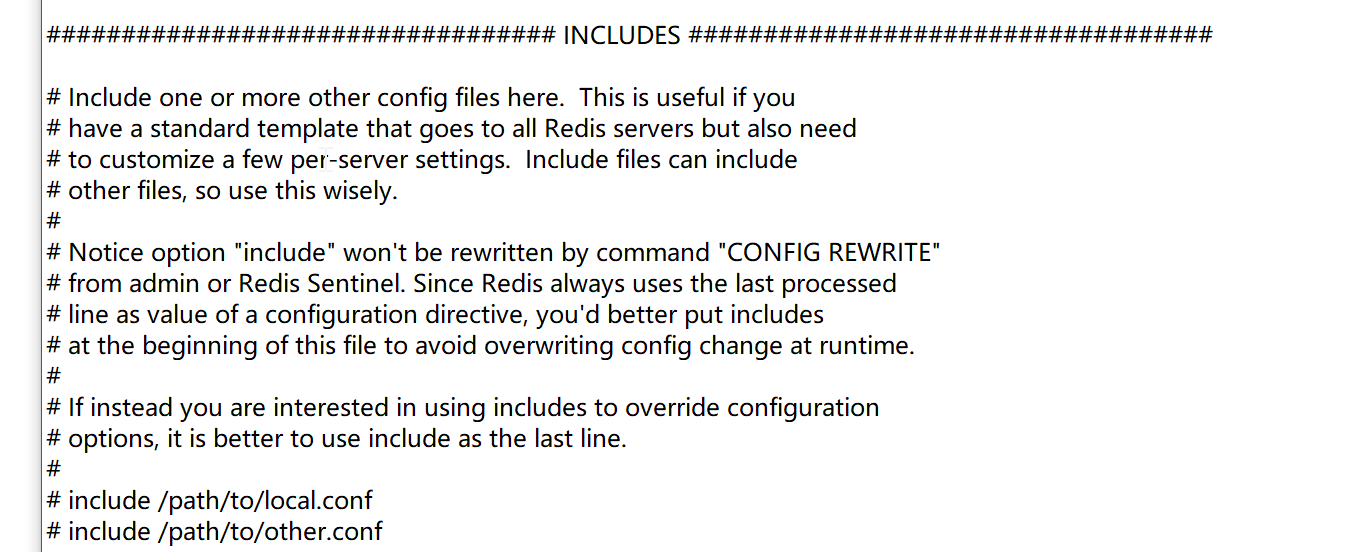
这里包括一个或多个其他配置文件。这很有用,如果你
有一个标准的模板,去所有的Redis服务器,但也需要
自定义一些服务器设置。包括文件可以包括
其他文件,所以明智地使用这个。
注意选项“include”不会被命令“CONFIG REWRITE”重写
从admin或Redis哨兵。因为Redis总是使用最后处理的
line作为配置指令的值,你最好放包含
在这个文件的开头,以避免在运行时覆盖配置更改。
如果你有兴趣使用include覆盖配置
options,最好使用include作为最后一行。
include /path/to/local.conf
include /path/to/other.conf
网络 NETWORK

bind 0.0.0.0 对所有人开放 可以指定单个或多个ip
指定多个ip 访问 ip 用空格 隔开

protected-mode yes 开启受保护模式
prot 6379 默认端口号
通用 GENERAL
daemonize yes 以守护进程的方式运行,默认是 no 我们需要自己设置为yes
pidfile /www/server/redis/redis.pid 如果是守护进程方式运行,我们需要指定一个pid文件
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
#指定服务器详细级别。
#这个可以是:
# debug(大量信息,对开发/测试有用)
# verbose(很多很少有用的信息,但不像调试级别那样混乱)
# notice(有点冗长,可能是在生产中需要的内容)
# warning(只记录非常重要/关键的消息)
logfile "/www/server/redis/redis.log" 日志的文件位置
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT <dbid> where
# dbid is a number between 0 and 'databases'-1
databases 16
#设置数据库个数。默认数据库为“DB 0”,可选择
#在每个连接上使用SELECT where
# dbid是一个介于0和'databases'-1之间的数字
databases 默认的数据库数量 16 个
# By default Redis shows an ASCII art logo only when started to log to the
# standard output and if the standard output is a TTY. Basically this means
# that normally a logo is displayed only in interactive sessions.
#
# However it is possible to force the pre-4.0 behavior and always show a
# ASCII art logo in startup logs by setting the following option to yes.
always-show-logo yes
always-show-logo yes 是否显示log 默认为开启
快照 SNAPSHOTTING

持久化数据 因为 Redis是内存数据库 如果断电等因素 会失去数据 所以我们需要在一定时间里 持久化数据
// 在 900s 内 有 1个key进行了操作 那么将会持久化一下
save 900 1
// 在 300s 内 有 10个key进行了操作 那么将会持久化一下
save 300 10
// 在 60s 内 有 1w个key进行了操作 那么将会持久化一下
save 60 10000
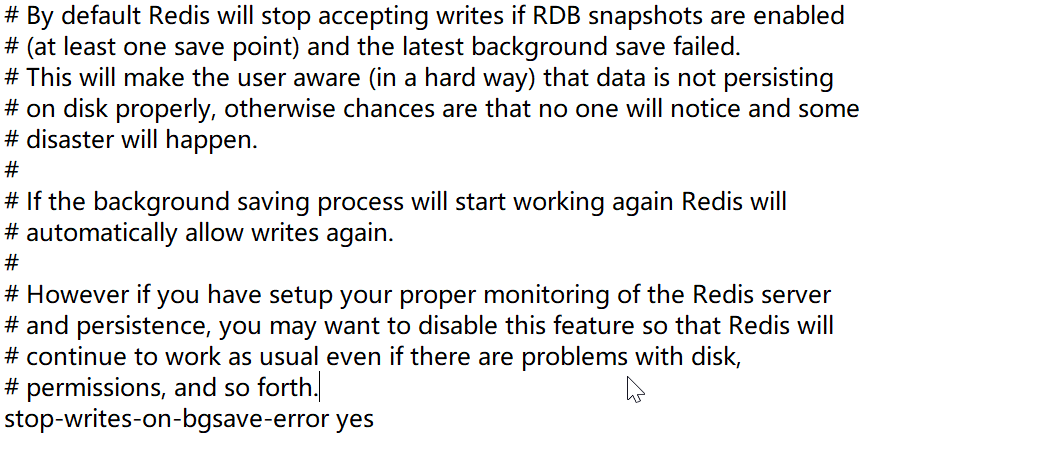
stop-writes-on-bgsave-error yes 持久化 出错了是否继续工作 默认继续
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
rdbcompression yes 是否压缩 rdb文件
默认压缩 压缩会消耗cpu资源
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
rdbchecksum yes 保存 rdb 文件时进行错误的校验
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir /www/server/redis/
rdb 文件保存的目录
复制 REPLICATION
安全 SECURITY
# Require clients to issue AUTH <PASSWORD> before processing any other
# commands. This might be useful in environments in which you do not trust
# others with access to the host running redis-server.
#
# This should stay commented out for backward compatibility and because most
# people do not need auth (e.g. they run their own servers).
#
# Warning: since Redis is pretty fast an outside user can try up to
# 150k passwords per second against a good box. This means that you should
# use a very strong password otherwise it will be very easy to break.
#
# requirepass foobared
requirepass xxxxx 设置redis 登录密码
#要求客户端在处理任何其他密码之前发出AUTH
#命令。这在您不信任的环境中可能很有用
#其他可以访问运行redis-server的主机。
#这个应该被注释掉,以便向后兼容,因为大多数
#人们不需要认证(例如,他们运行自己的服务器)
#警告:由于Redis是相当快的外部用户可以尝试
# 150k密码每秒对一个好的盒子。这意味着你应该这么做
#使用一个非常强的密码,否则它会很容易被破解
限制 CLIENTS
maxclients 10000 默认有 1w 个用户可以同时连接redis 服务器
maxmemory <bytes> redis 配置最大的内存容量
maxmemory-policy noeviction 内存到达上限的处理策略 6种
**1、volatile-lru:**只对设置了过期时间的key进行LRU(默认值)
2、allkeys-lru : 删除lru算法的key
**3、volatile-random:**随机删除即将过期key
**4、allkeys-random:**随机删除
5、volatile-ttl : 删除即将过期的
6、noeviction : 永不过期,返回错误
aof配置 APPEND ONLY MODE
基本配置
appendonly no 默认不开启 默认使用rdb持久化方式
appendfilename "appendonly.aof" 持久化文件的名字
# appendfsync always // 每修改一个key都会执行 sync,消耗性能
appendfsync everysec // 每一秒执行一次 sync,可能会丢失这1s的数据
# appendfsync no // 不执行 sync,这个时候操作系统会自己同步数据速度是最快的
详细配置
Redis持久化
因为Redis是内存数据库,如果不把数据保存到磁盘中,那么如果机器出现断电等,数据就会丢失,
所以Redis提供了持久化功能
RDB
RDB (Redis DataBase)
什么是RDB
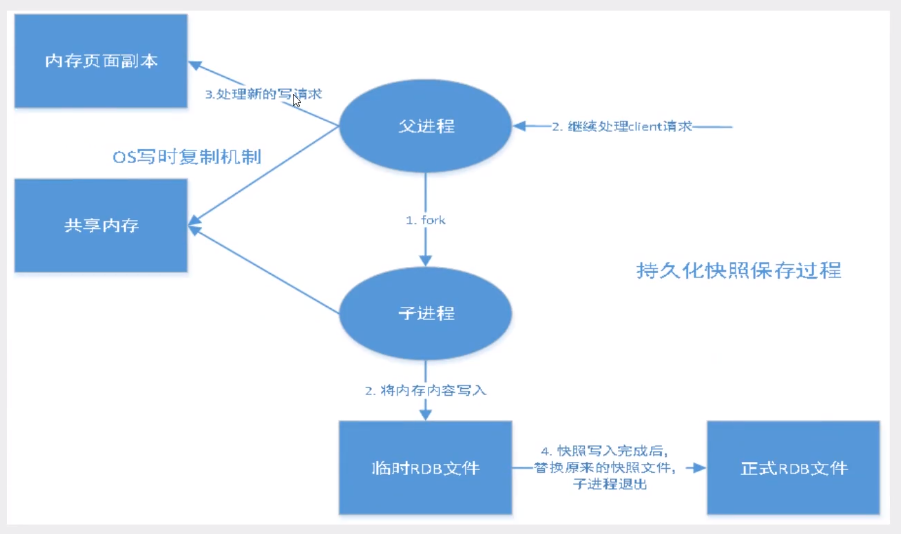
就是在指定时间里把内存的数据存储到磁盘中
Rdb 默认保存的文件叫做 dump.rdb

触发机制

- save 的规则满足的情况下,会自动触发rdb规则
- 执行flushdb 命令,也会触发rdb文件规则
- 退出Redis ,也会产生rdb文件
备份就会生成一个 dump.rdb文件
如何回复rdb文件
- 只需要将rdb文件放到Redis启动目录下就可以,Redis启动的时候自动检查
dump.rdb回复其数据 - 可以用
config get dir查询我们需要将文件放在那个目录下
优点
适合大规模数据恢复
对数据的完成性数据不高可以使用
缺点
需要一定的时间间隔进行操作 ,如果在最后一次操作的时候当机了 那么最后修改的数据就没了
fork 一条进程的时候会占用一定的内存空间
AOF
AOF (Append Only File)
Aof是什么
将我们的所有命令记录下来,恢复的时候就把这个文件全部再执行一遍
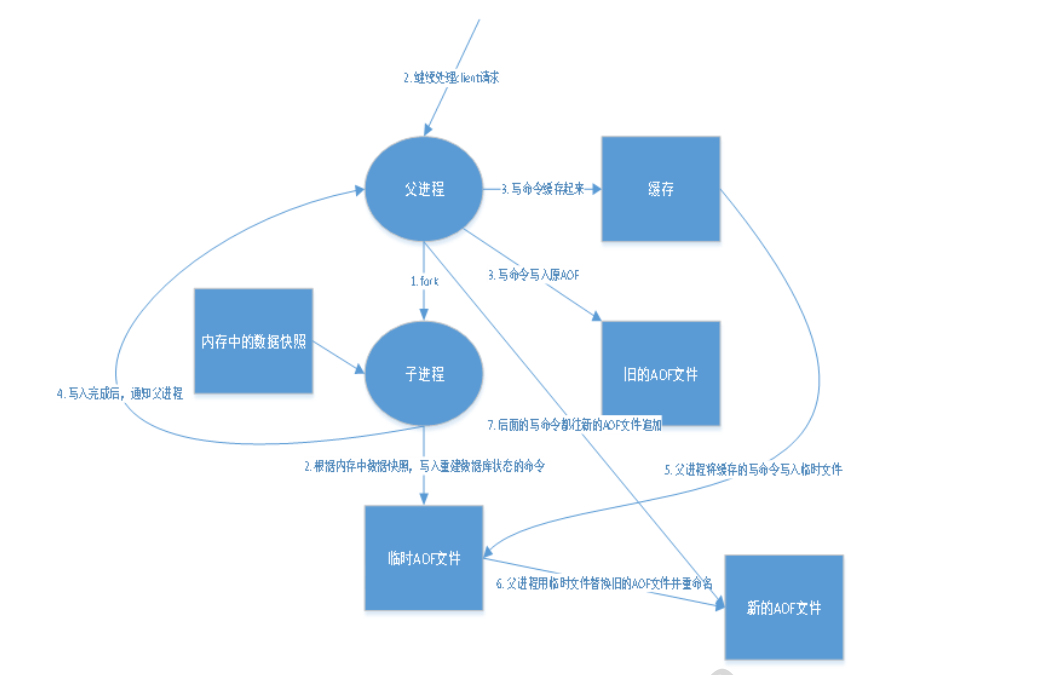
以日志的形式记录每一个写的操作,将Redis执行过程中的所有命令指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取文件重新构建数据
aof 保存的文件是 appendonly.aof
默认是没有开启的 我们需要的话需要手动开启 把 appendonly no 改为 appendonly yes
如果Aof文件受损了Redis启动不起来 我们可以通过 redis-check-aof --fix 来修复aof文件

优点
- 每一次修改都同步,文件的完整性会更加好
- 每秒同步一次,可能会丢失一秒的数据
- 从来不同步,效率最高
缺点
- 相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢
- aof 运行效率也要比rdb慢,所以Redis默认的配置就是rdb持久化
Redis发布与订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息 ------ > 微信 、微博的 关注系统
Redis 客户端可以订阅任意数量的频道
订阅/发布消息图:
- 消息发布者
- 频道
- 消息订阅者
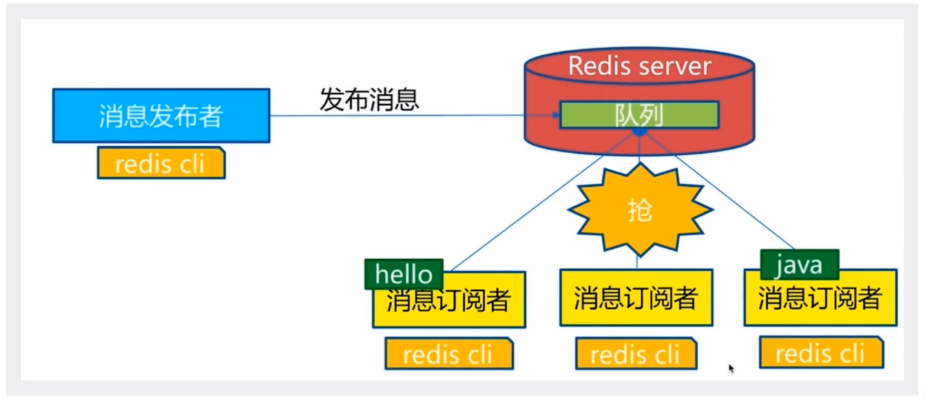
下图是频道 channel1 , 以及订阅这个频道的三个客户端 ----- cilent2,cilent5 和 cilent1 之间的关系
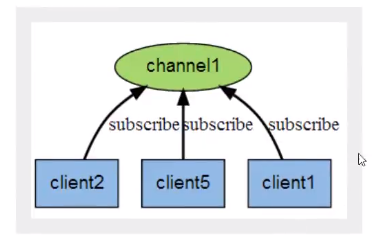
当有消息通过Publish 命令发送给频道 channel1 时,这个消息就会被它发送给订阅它的三个客户端
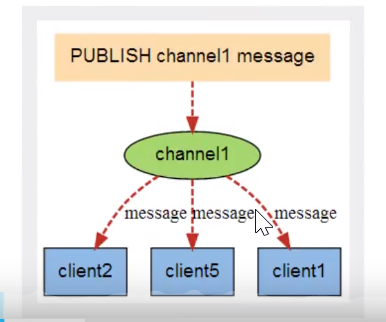
命令
redis 发布订阅常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | PSUBSCRIBE pattern [pattern …] 订阅一个或多个符合给定模式的频道。 |
| 2 | [PUBSUB subcommand argument [argument …]] 查看订阅与发布系统状态。 |
| 3 | PUBLISH channel message 将信息发送到指定的频道。 |
| 4 | [PUNSUBSCRIBE pattern [pattern …]] 退订所有给定模式的频道。 |
| 5 | SUBSCRIBE channel channel …] 订阅给定的一个或多个频道的信息。 |
| 6 | [UNSUBSCRIBE channel [channel …]] 指退订给定的频道。 |
订阅信息:
127.0.0.1:6379> subscribe king // 订阅一个频道
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "king"
3) (integer) 1
// 等待推送的信息
1) "message" // 消息
2) "king" // 来自于那个频道
3) "hello,yss" // 来自哪个频道的内容
1) "message"
2) "king"
3) "\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0"
推送信息:
127.0.0.1:6379> publish king "hello,yss" // 发布信息到指定的频道
(integer) 1
127.0.0.1:6379> publish king "我爱你"
(integer) 1
Redis主从复制
概念
一般来说,要将 Redis用于工程项目中,只使用一台 Redist是万万不能的,原因如下:
1、从结构上,单个 Redist服务器会发生单点故障,井且一台服务器需要处理所有的请求负載,压力较大
2、从容量上,单个 Redis服务器内存容量有限就算一台 Redis服务器内存容量为266,也不能将所有内存用作 Redis?存储内存一般来说,单台 Redist最大使用内存不应该超过206
电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点也就是"多读少写"。
对于这种场景,我们可以使如下这种架构主从复制,息指将一台Reds3服的数据,复制他的Reds眼努,前者称为主节点 master/leade,后者称为从节点( slave/ follower);数据的复制是单向的,只能由主节点到从节点。 Master以写为主,Save以读为主。
认情况下,每台 Redish服务器都是主节点:且ー个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点
主从复制的作用主要包括:
- 数据元余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现可题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写 Redisa效据时应用连接主节点,读Reds数据时应用连接从节点),分担服务器负载;尤具是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis服务器的并发量
- 高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Reds高可用的基础
环境配置
只配置从库,不配置主库!
查看当前库的信息
127.0.0.1:6379> info replication
# Replication
role:master // 角色
connected_slaves:0 // 连接的丛机
master_failover_state:no-failover
master_replid:c52bb664e09e9e76e9c995fdd15215578e38250f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0

复制3个Redis.conf
然后修改配置文件:
- 端口号
- .pid 名字
- log 文件名字
- dump.rdb 名字
配置成功
启动3个redis
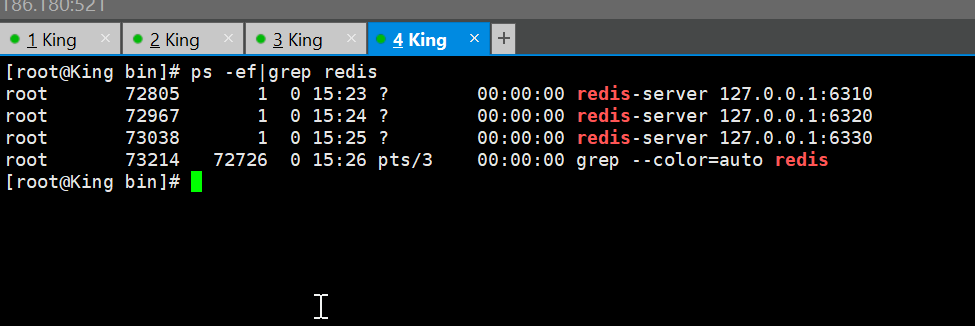
一主二从
默认情况Redis每一个服务都是主节点
一般只配置从机
一主 (6310)二从 (6320,6330)
查看Redis当前库信息
6310的信息

6320的信息
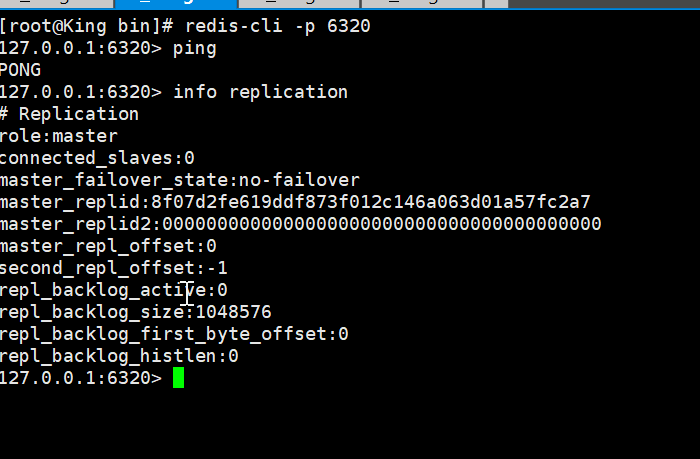
6330的信息
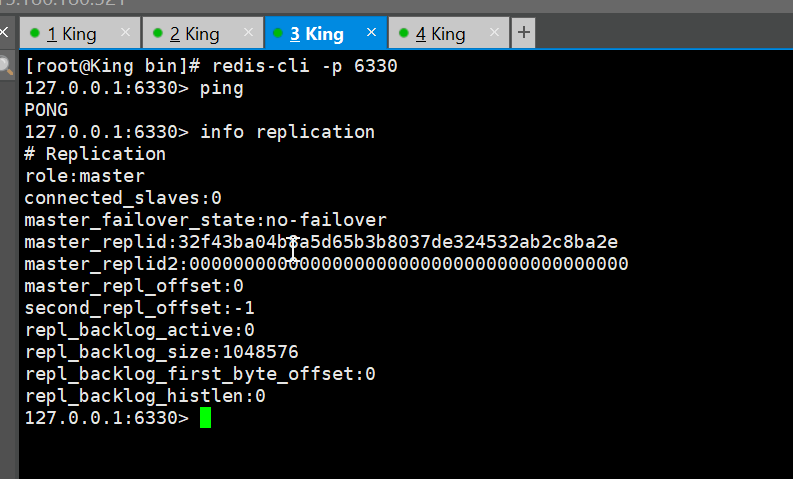
配置
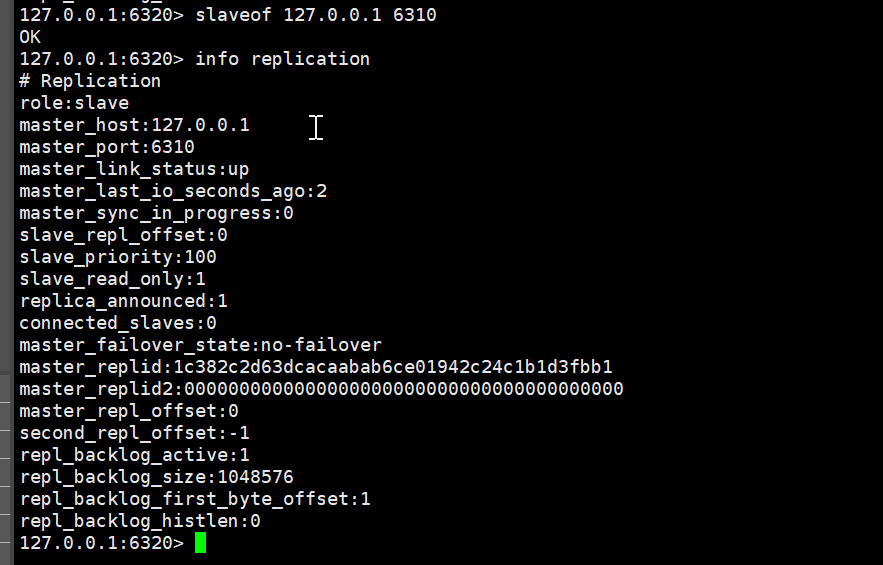
命令slaveof 127.0.0.1 6310
给 6320 认 6310 是老大
6320的信息
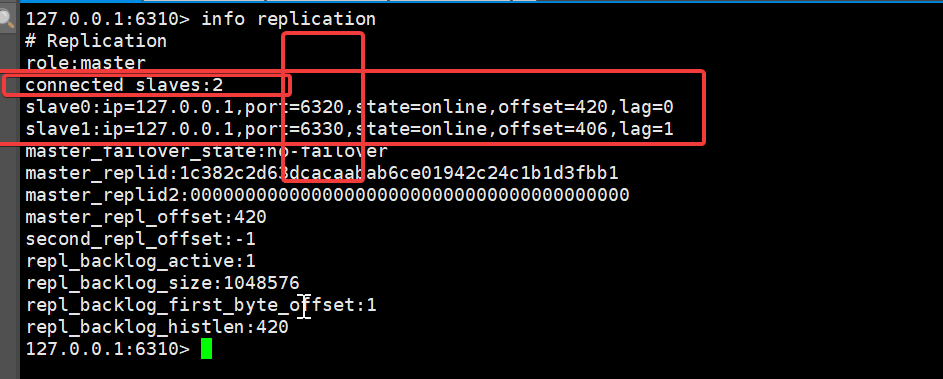
同样给 6330 配置一下
6310的信息
127.0.0.1:6310> info replication
# Replication
role:master // 主机标识
connected_slaves:1 // 他有一个从机
slave0:ip=127.0.0.1 // 从机地址
,port=6320 // 从机端口
,state=online // 从机状态
,offset=252,lag=1
master_failover_state:no-failover
master_replid:1c382c2d63dcacaabab6ce01942c24c1b1d3fbb1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:252
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:252
2个都配置完成
细节
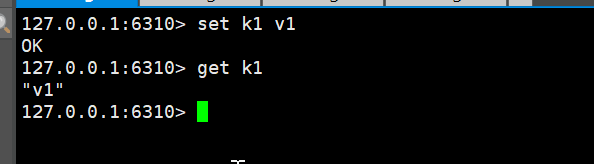
主机可以写,从机不可以写只能读!主机中的所有数据都会被从机保存
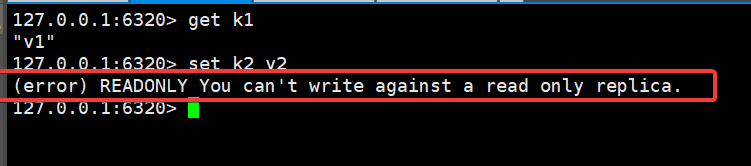
主机可以读写 :
从机只能读不能写不然会报错:
测试
1、主机宕机了 从机状态
127.0.0.1:6310> SHUTDOWN
not connected> exit
[root@King bin]# redis-cli -p 6310
Could not connect to Redis at 127.0.0.1:6310: Connection refused
not connected> ping
Could not connect to Redis at 127.0.0.1:6310: Connection refused
主机关闭
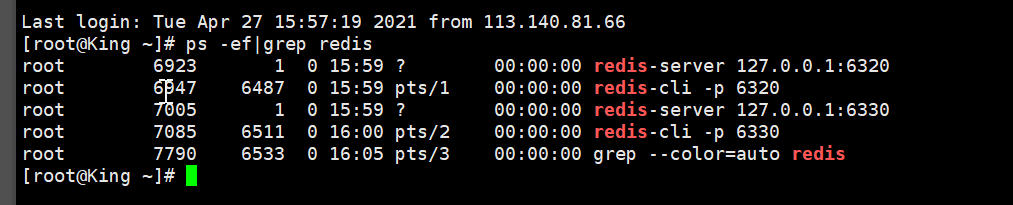
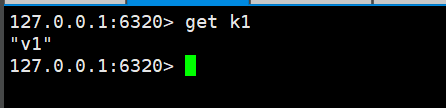
主机宕机不会影响从机的读取操作
2、主机从新工作
[root@King bin]# redis-server KingConfig/redis-10.conf
[root@King bin]# redis-cli -p 6310
127.0.0.1:6310> ping
PONG
127.0.0.1:6310> set k2 v2
OK
127.0.0.1:6310> get k2
"v2"
从机状态
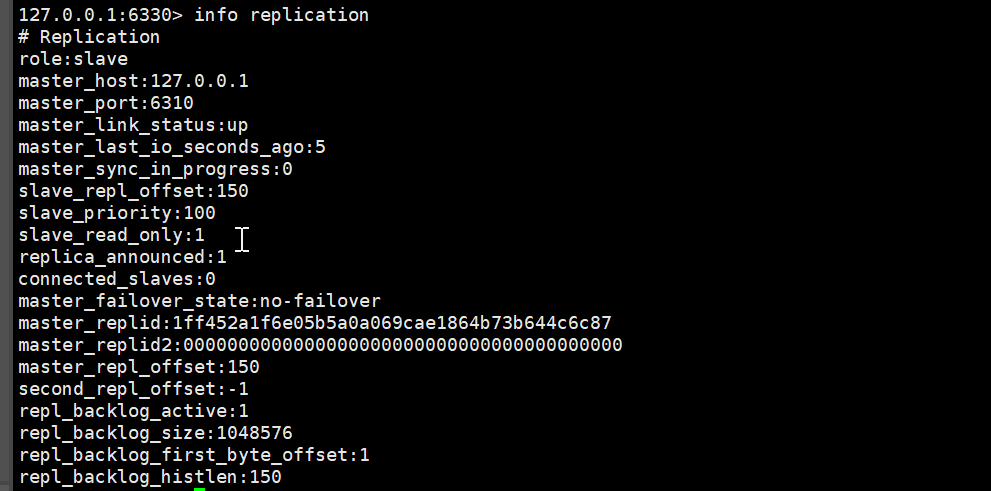
也可以查询值
127.0.0.1:6320> get k2
"v2"
测试从机断开 :如果从机是使用命令连接的主机 那么从机断开之后 重新连接 他就会变为自己的主机,这样是取不到主机更新数据,但是可以取到以前的数据,我们重新让它成为从机 那么他还是可以读取到数据
复制原理
Slave启动成功连接到 master 后会发送一个sync命令
Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后, master将传送整个数据文件到 slave,井完成一次完全同步
全量复制:而 slave服务在接收到数据库文件数据后,将其存盘井加载到内存中
增量复制:Master继续将新的所有收集到的修改命令依次传给 slave,完成同步
但是只要是重新连接 master,一次完全同步(全量复制)将被自动执行
主机宕机
如果主机宕机了,从机想要变成主机 我们可以通过命令 slaveof no noe 让自己变成主机!其他节点就可以手动连接,这个时候主机连接了 还想要 这个主机当老大 那么我们需要手动配置
哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
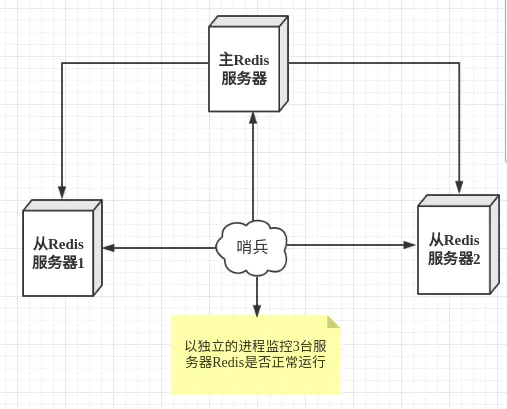
哨兵模式概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
Redis哨兵
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
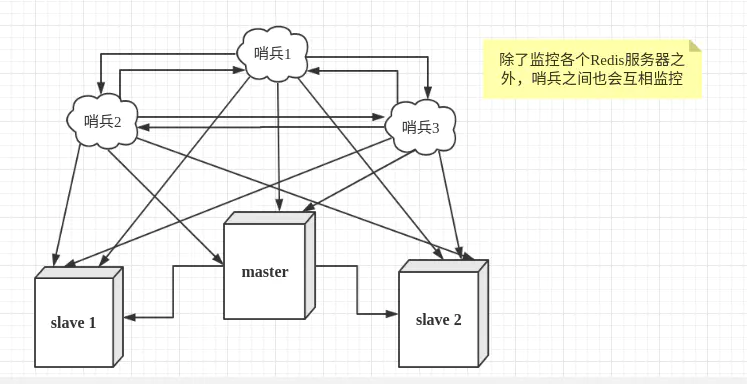
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
用文字描述一下故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
Redis配置哨兵模式
配置3个哨兵和1主2从的Redis服务器来演示这个过程。
| 服务类型 | 是否是主服务器 | IP地址 | 端口 |
|---|---|---|---|
| Redis | 是 | 192.168.11.128 | 6379 |
| Redis | 否 | 192.168.11.129 | 6379 |
| Redis | 否 | 192.168.11.130 | 6379 |
| Sentinel | - | 192.168.11.128 | 26379 |
| Sentinel | - | 192.168.11.129 | 26379 |
| Sentinel | - | 192.168.11.130 | 26379 |
多哨兵监控Redis
首先配置Redis的主从服务器,修改redis.conf文件如下
# 使得Redis服务器可以跨网络访问
bind 0.0.0.0
# 设置密码
requirepass "123456"
# 指定主服务器,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
slaveof 192.168.11.128 6379
# 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
masterauth 123456
上述内容主要是配置Redis服务器,从服务器比主服务器多一个slaveof的配置和密码。
配置3个哨兵,每个哨兵的配置都是一样的。在Redis安装目录下有一个sentinel.conf文件,copy一份进行修改
# 禁止保护模式
protected-mode no
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
sentinel monitor mymaster 192.168.11.128 6379 2
# sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
上述关闭了保护模式,便于测试。
有了上述的修改,我们可以进入Redis的安装目录的src目录,通过下面的命令启动服务器和哨兵
# 启动Redis服务器进程
./redis-server ../redis.conf
# 启动哨兵进程
./redis-sentinel ../sentinel.conf
注意启动的顺序。首先是主机(192.168.11.128)的Redis服务进程,然后启动从机的服务进程,最后启动3个哨兵的服务进程。
哨兵模式的其他配置项
| 配置项 | 参数类型 | 作用 |
|---|---|---|
| port | 整数 | 启动哨兵进程端口 |
| dir | 文件夹目录 | 哨兵进程服务临时文件夹,默认为/tmp,要保证有可写入的权限 |
| sentinel down-after-milliseconds | <服务名称><毫秒数(整数)> | 指定哨兵在监控Redis服务时,当Redis服务在一个默认毫秒数内都无法回答时,单个哨兵认为的主观下线时间,默认为30000(30秒) |
| sentinel parallel-syncs | <服务名称><服务器数(整数)> | 指定可以有多少个Redis服务同步新的主机,一般而言,这个数字越小同步时间越长,而越大,则对网络资源要求越高 |
| sentinel failover-timeout | <服务名称><毫秒数(整数)> | 指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟 |
| sentinel notification-script | <服务名称><脚本路径> | 指定sentinel检测到该监控的redis实例指向的实例异常时,调用的报警脚本。该配置项可选,比较常用 |
sentinel down-after-milliseconds配置项只是一个哨兵在超过规定时间依旧没有得到响应后,会自己认为主机不可用。对于其他哨兵而言,并不是这样认为。哨兵会记录这个消息,当拥有认为主观下线的哨兵达到sentinel monitor所配置的数量时,就会发起一次投票,进行failover,此时哨兵会重写Redis的哨兵配置文件,以适应新场景的需要。
哨兵配置
配置哨兵配置文件 sentinel.conf
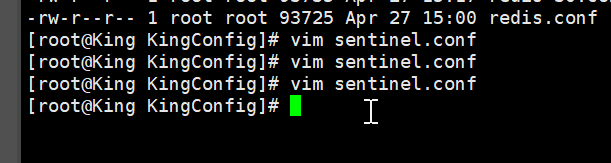
sentinel monitor 被监控的名字自定义 ip地址 端口号 1
sentinel monitor myredis 127.0.0.1 6310 1
后面这个1代表 如果主机宕机了 slave 投票看让谁接替成为主机,票数最多的,就会成为主机
用 redis-sentinel 服务来启动 哨兵
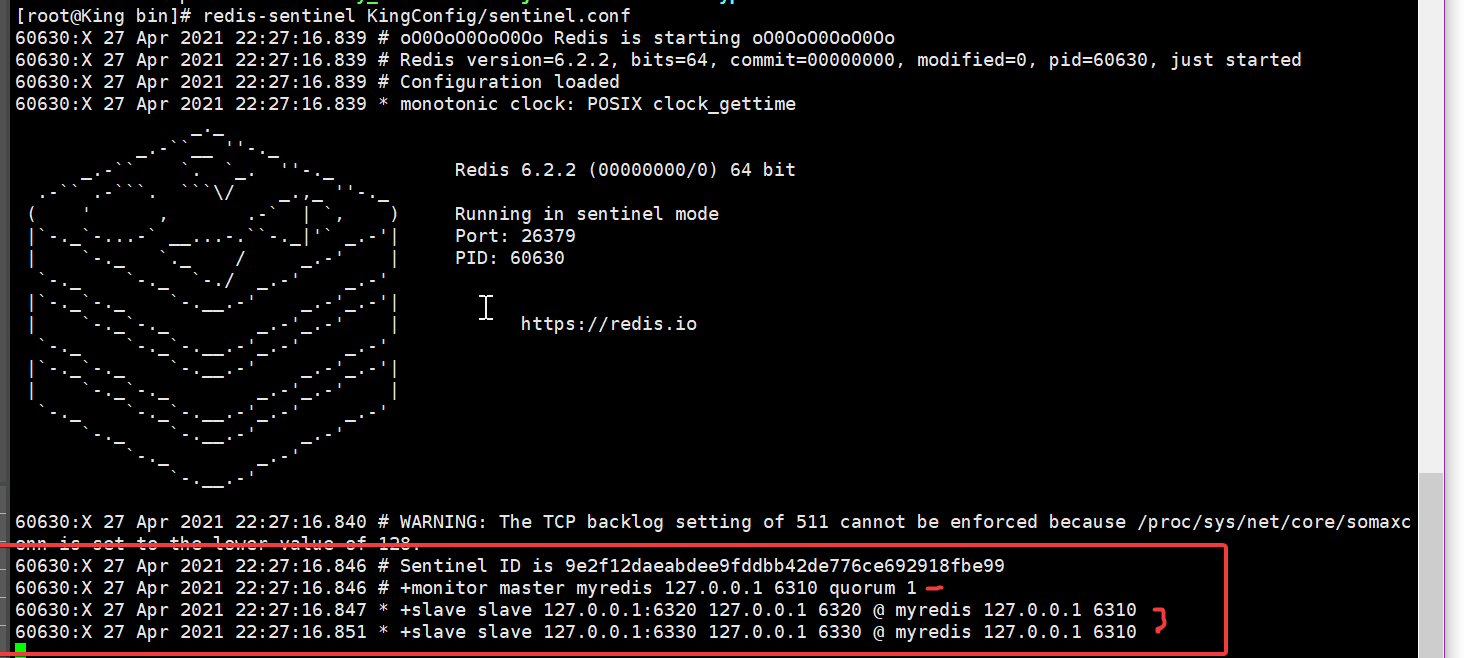
这个时候如果主机宕机了
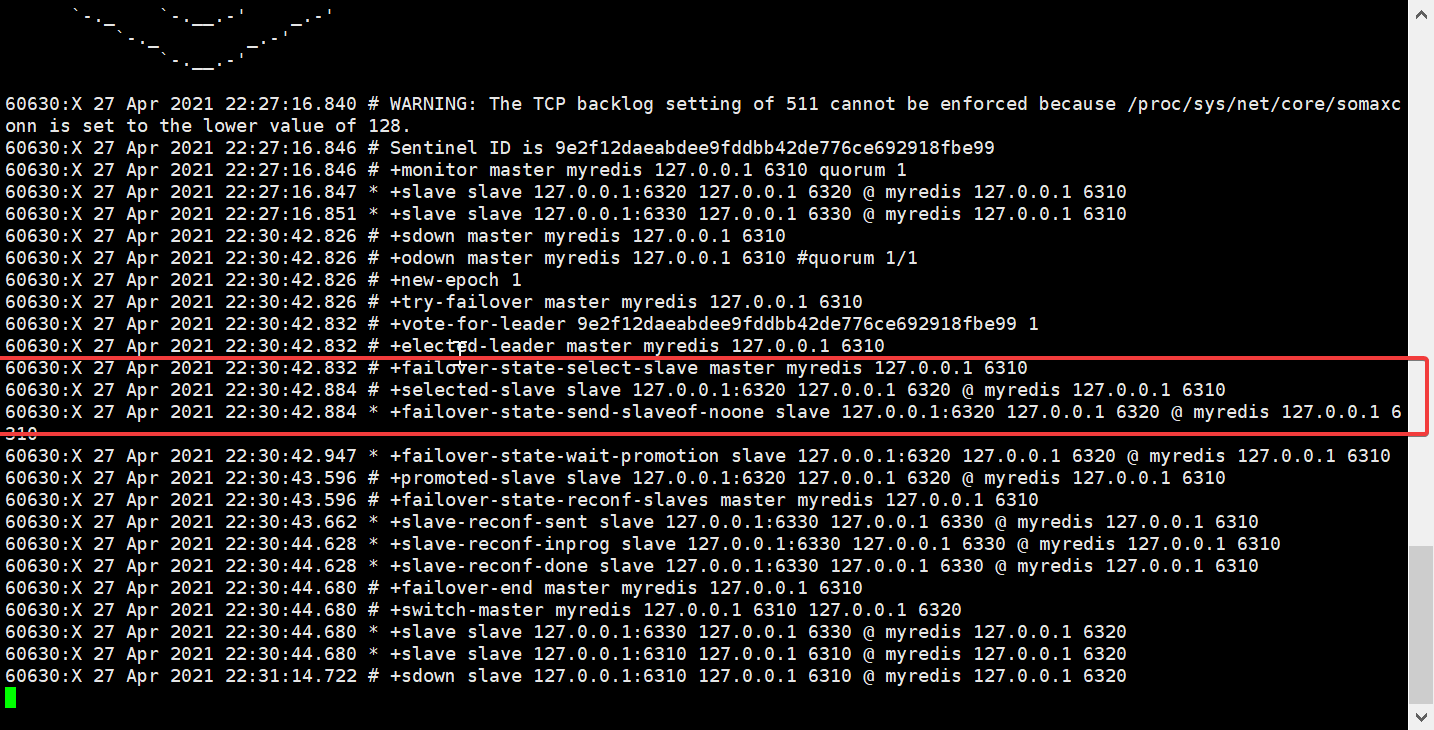
哨兵就会去检测 主机是否还有呼吸 如果检查没有了 那么他就是从从机里面选一个来作为主机
选举 6320 来做为主机
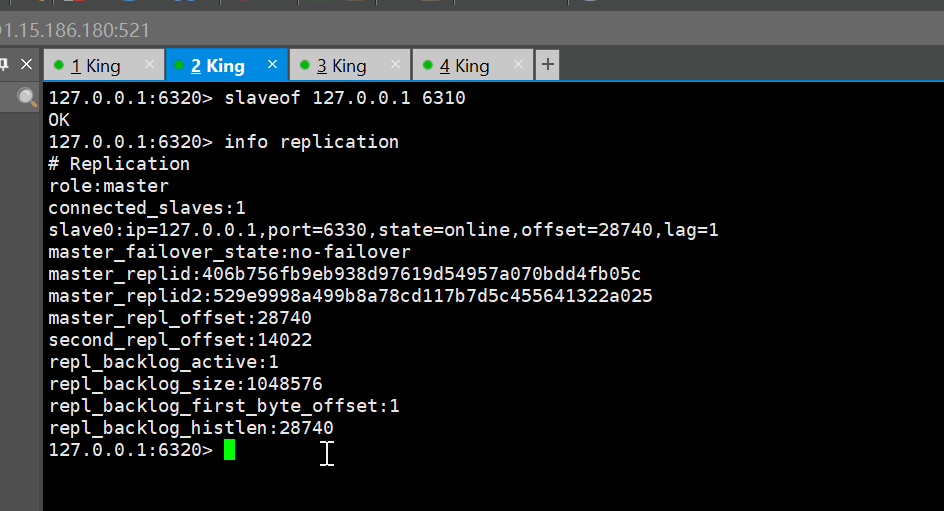
如果 6310 回来 那么 他就会作为 现任老大的从机
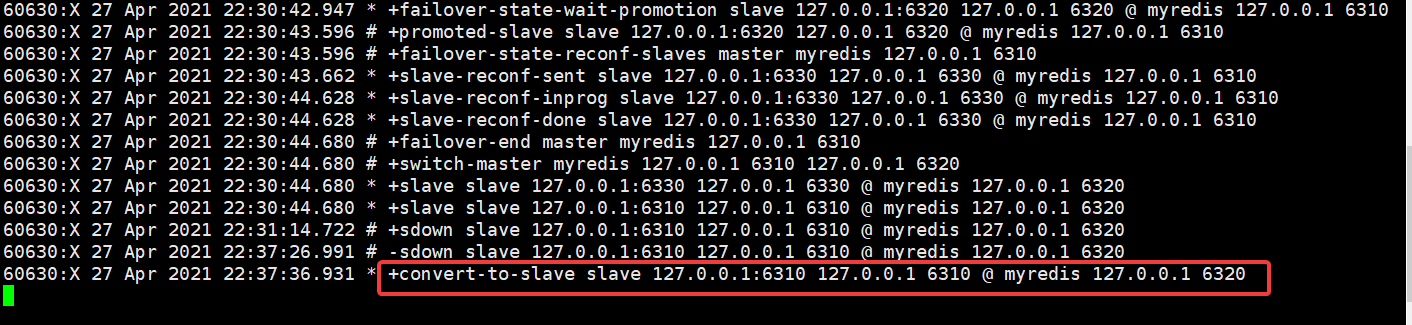
6320 主机
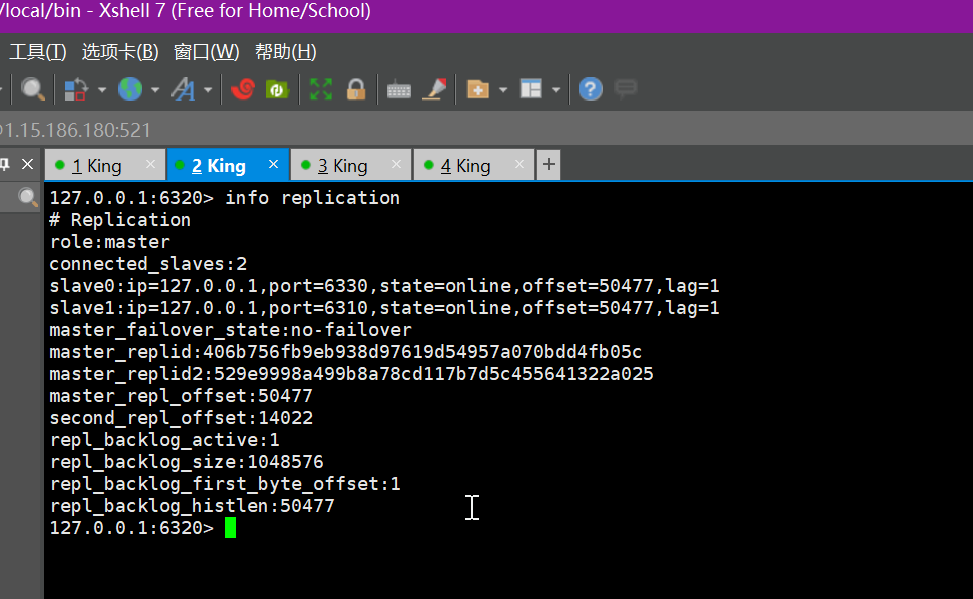
哨兵集群配置
# Example sentinel.conf
# port <sentinel-port> 哨兵的默认端口 默认是 26379
port 8001
# 守护进程模式
daemonize yes
# 指明日志文件名
logfile "./sentinel1.log"
# 工作路径,sentinel一般指定/tmp比较简单
dir ./
# 哨兵监控这个master,在至少quorum个哨兵实例都认为master down后把master标记为odown
# (objective down客观down;相对应的存在sdown,subjective down,主观down)状态。
# slaves是自动发现,所以你没必要明确指定slaves。
sentinel monitor MyMaster 127.0.0.1 7001 1
# master或slave多长时间(默认30秒)不能使用后标记为s_down状态。
sentinel down-after-milliseconds MyMaster 1500
# 若sentinel在该配置值内未能完成failover操作(即故障时master/slave自动切换),则认为本次failover失败。
sentinel failover-timeout TestMaster 10000
# 设置master和slaves验证密码
sentinel auth-pass TestMaster testmaster123
sentinel config-epoch TestMaster 15
#除了当前哨兵, 还有哪些在监控这个master的哨兵
sentinel known-sentinel TestMaster 127.0.0.1 8002 0aca3a57038e2907c8a07be2b3c0d15171e44da5
sentinel known-sentinel TestMaster 127.0.0.1 8003 ac1ef015411583d4b9f3d81cee830060b2f29862
Redis缓存穿透和雪崩
缓存穿透 (查不到)
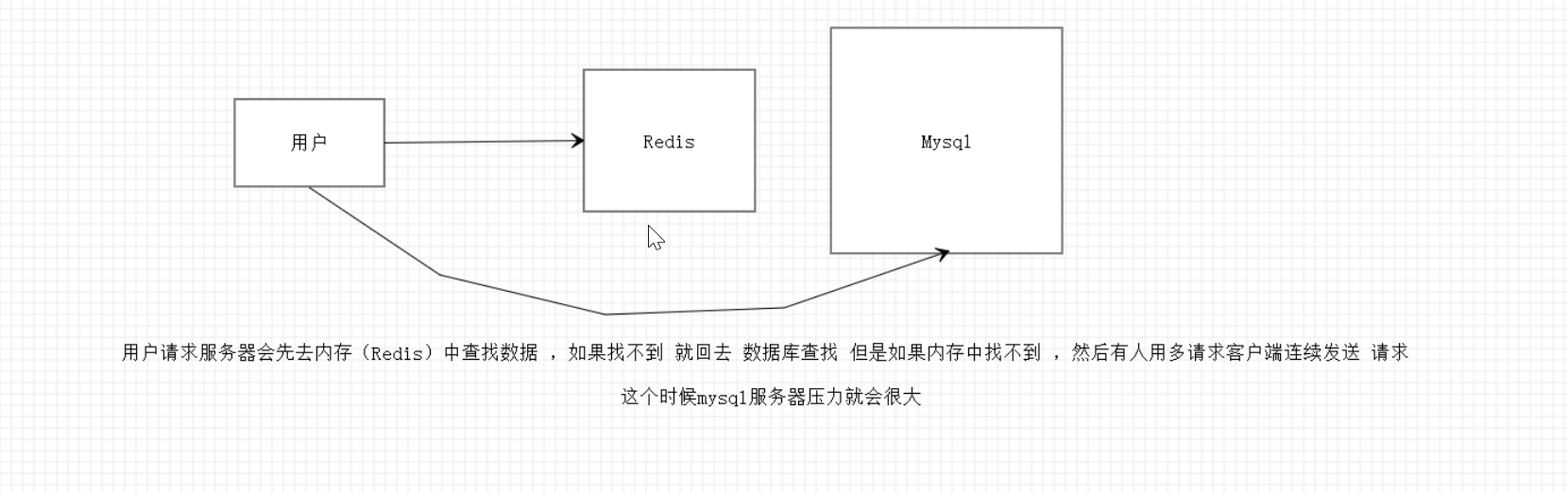
概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
解决方案
布隆过滤器
布隆过滤器是一种数据结构,垃圾网站和正常网站加起来全世界据统计也有几十亿个。网警要过滤这些垃圾网站,总不能到数据库里面一个一个去比较吧,这就可以使用布隆过滤器。假设我们存储一亿个垃圾网站地址。
可以先有一亿个二进制比特,然后网警用八个不同的随机数产生器(F1,F2, …,F8) 产生八个信息指纹(f1, f2, …, f8)。接下来用一个随机数产生器 G 把这八个信息指纹映射到 1 到1亿中的八个自然数 g1, g2, …,g8。最后把这八个位置的二进制全部设置为一。过程如下:
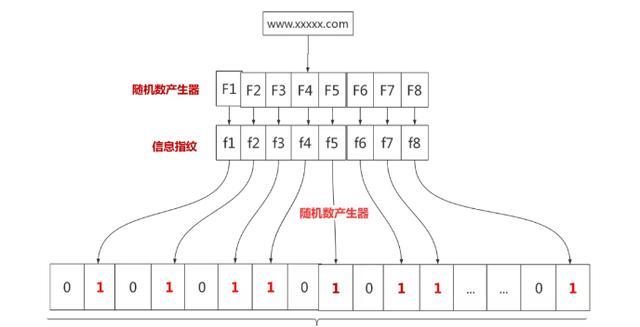
有一天网警查到了一个可疑的网站,想判断一下是否是XX网站,首先将可疑网站通过哈希映射到1亿个比特数组上的8个点。如果8个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。
那这个布隆过滤器是如何解决redis中的缓存穿透呢?很简单首先也是对所有可能查询的参数以hash形式存储,当用户想要查询的时候,使用布隆过滤器发现不在集合中,就直接丢弃,不再对持久层查询。
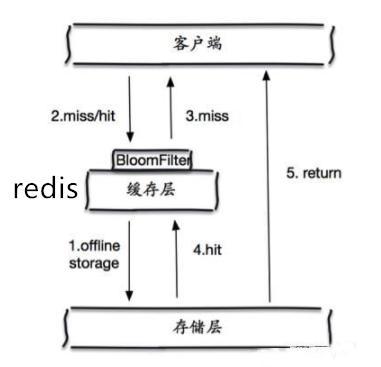
这个形式很简单。
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
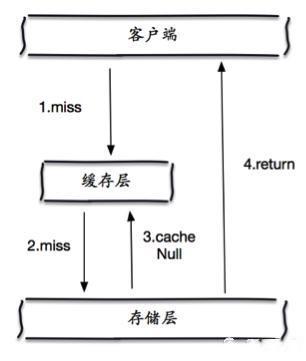
但是这种方法会存在两个问题:
如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿 (查询量太大,缓存过期)
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
- 设置热点数据永远不过期
- 接口限流与熔断,降级
重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。
- 布隆过滤器
bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小
- 加互斥锁,互斥锁参考代码如下:
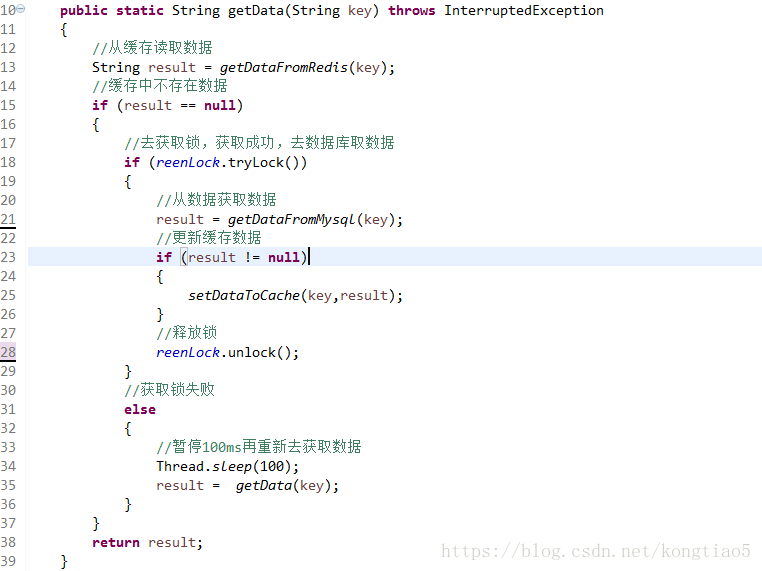
说明:
1)缓存中有数据,直接走上述代码13行后就返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据key值加锁就更好了,就是线程A从数据库取key1的数据并不妨碍线程B取key2的数据,上面代码明显做不到这点。
缓存雪崩
概念
缓存雪崩是指,缓存层出现了错误,不能正常工作了。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
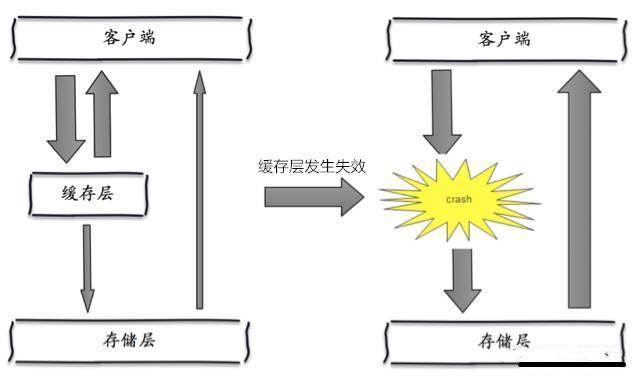
解决方案
(1)redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
(2)限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
(3)数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
实战项目 (很小的,就简单测试一下)
https://gitee.com/PoseidonKing/projects














 3227
3227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









