









文章目录
Python简介
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
1 Python基础语法
编码
默认情况下,Python3源码文件以utf-8编码,所有字符串都是unicode字符串。
标识符
标识符是用户边长时使用的名字,用与给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系。
规定:
第一个字符必须是字母或下划线
标识符的其他的部分可以由字符、数字和下划线组合
标识符区分大小写
不可以使用关键字
输出Python关键字代码如下:
from keyword import kwlist
print(kwlist)
print(len(kwlist))
运行效果如下:
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
35
一共有35个关键字。
注释
单行注释:以#开头
块注释:以三个’‘‘或"""开始,以三个’’'或"""结尾
行与缩进
python最具特色的就是使用缩进来表示代码块,不需要使用大括号{}。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数以下代码最后一行语句缩进数的空格数不一致,会导致运行错误。
缩进两种方式:可以使用tab或者空格(编码规范:统一使用4个空格代表一个缩进)
多行语句
Python通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠(来实现多行语句。
a,b,c=1,2,3
total=a+\
b+\
c
print(total)
上述代码运行结果为:6
print方法打印默认打印空行,如果不想换行需要加end=‘’
print("123",end='')
print("abc")
print打印多个对象时,默认使用一个空格间隔
print("123","abc")
上述代码运行结果为:123 abc
print打印多个对象时,可以通过参数sep指定间隔符
print("123","abc",sep='$')
import与from…import
导包方式,如下:
import 模块名 #导入模块
from 模块名 import 方法名 #导入模块下的单个方法
from 模块名 import 方法名1,方法名2 #导入模块下的两个方法
from 模块名 import * #导入模块下的所有方法
from 模块名 import 类名
import sys
print("==========python import mode=========")
print('命令参数为:')
for i in sys.argv:
print(i)
print('\n python路径为',sys.path)
上述代码运行结果为:
==========python import mode=========
命令参数为:
D:\jupyter-notebook\lib\site-packages\ipykernel_launcher.py
-f
C:\Users\DELL\AppData\Roaming\jupyter\runtime\kernel-611e04dc-cf43-41c7-9f50-6a1db0fb8929.json
python路径为 ['d:\\python-ml', 'D:\\jupyter-notebook\\python37.zip', 'D:\\jupyter-notebook\\DLLs', 'D:\\jupyter-notebook\\lib', 'D:\\jupyter-notebook', '', 'D:\\jupyter-notebook\\lib\\site-packages', 'D:\\jupyter-notebook\\lib\\site-packages\\win32', 'D:\\jupyter-notebook\\lib\\site-packages\\win32\\lib', 'D:\\jupyter-notebook\\lib\\site-packages\\Pythonwin', 'D:\\jupyter-notebook\\lib\\site-packages\\IPython\\extensions', 'C:\\Users\\DELL\\.ipython']
就是环境变量的配置路径。
help()函数
help(max)
上述代码运行效果如下:
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
print(max(1,9999999))
上述代码运行效果如下:
9999999
变量
Python中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
赋值号(=)给变量赋值。
Python运行同时为多个变量赋值,如下:
a=b=c=1
例子如下:
print('a变量的为',a,',a变量的数据类型为',type(a))
print('b变量的为',b,',b变量的数据类型为',type(b))
print('c变量的为',c,',c变量的数据类型为',type(c))
上述代码运行结果如下:

2 数据类型
Python3中有六个标准的数据类型:
number(数字)、string(字符串)、list(列表)、tuple(元组)、sets(集合)和dictionary(字典)。
2.1 数值型
Python3支持int、float、bool、complex(复数)
内置的type()函数可以用来查询变量所指的对象类型
内置的id()函数可以用来查询变量的内存空间地址。
数值的除法(/)总是返回一个浮点数,除法取整用(//),取余用(%)。
a=100
b=99.99
c="123"
print(id(a))
print(id(b))
print(id(c))
上述代码运行结果如下:
140731869740976
2090332931080
2090334650640
原因:内置的id()函数可以用来查询变量的内存空间地址。
print(10/5)
上述代码运行结果为:2.0,原因是,在混合计算时,Python会把整型转换成为浮点数。
print(10//3)
上述代码运行结果为:3,原因是,除法取整用(//)。
print(10%3)
上述代码运行结果为:1,除法取余用(%)。
2.2 字符串
字符串是有序的,有下标的,每一位都可以通过下标表示,从左到右,第一位是0,最后一位总长度减1。从右到左,是从-1开始。
取整个字符串
str="hello,world~"
print(str)
print(str[:])
print(str[0:])
print(str[0:len(str)])
第一种直接用字符串变量输出整个字符串。
第二种用字符串下标输出整个字符串,默认从0开始到最后一个字符。
第三种用字符串下标输出整个字符串,从0开始索引到最后一个字符。
第四种,获取字符串长度为12,索引从0开始的,所以str有11个字符,根据“左闭右开”原则,12刚刚好取到整个字符串。

切片取字符串
print(str[0:-1])#左闭右开,即左端的值取得到,右边的值取不到
上述代码输出结果为:hello,world。-1表示最后一个字符的下标,也就是导数第一位,因为左闭右开,所以结果不包含最后一个字符。
print(str[0:5])
上述代码输出结果为:hello。字符串从下标为0开始索引,到下标为5时停止,取不到下标为5的字符,故输入下标为0-4的字符。
print(str[0:12:2])
上述代码输出结果为:hlowrd。首先输出整个字符串,步长为2,即从下标为0开始取每个2个取一个字符,取下标为0,2,4,6,8,10的字符。
转义符
\n回车, \r 换行, \t 制表符, \代表一个反斜杠。
字符串前面加一个r或R表示让字符串原样输出,即里面的转义不转义。
str=r"hello,\nworld~"
print(str)
上述代码运行结果为:hello,\nworld~。
+号拼接两个str类型,* n输出多个字符串。
str1="123"
str2="abc"
print(str1+str2)
上述代码运行结果为:123abc。
str1="123"
print(str1*3)
上述代码运行结果为:123123123。
str="十旬叶大叔"
print(id(str))
str="十旬叶大叔"
print(id(str))
上述代码运行结果为:
2730723761560
2730723761976
list=[1,2]
print(list)
print(id(list))
list.append(3)
print(list)
print(id(list))
上述代码运行结果为:
[1, 2]
2730725774152
[1, 2, 3]
2730725774152
得出结论:可变对象(list)修改之后,前后地址不变;不可变对象(str)修改之后,前后地址改变。
字符串常用的内置方法
str="hello,world~"
print(str.isdigit())
上述代码运行结果为False,isdigit()判断字符串中的字符是否都为数字,是返回True,否则返回False。
str="ABC"
print(str.isupper())
上述代码运行结果为True,isupper()判断字符串中的字符是否全为大写,是返回True,否则返回False。
str="abc"
print(str.islower())
上述代码运行结果为True,isupper()判断字符串中的字符是否全为小写,是返回True,否则返回False。
str="abc123~"
print(str.isalnum())
上述代码运行结果为False,“~”不为字母或数字。isalnum()判断字符串中的字符是否全为字母或数字,是返回True,否则返回False。
str="hello,world~"
print(str.index('o'),end=' ')
print(str.index('or'))
上述代码运行结果为4 7。index(‘n’)返回n子字符的下标,若n为子字符串,则返回该子字符串的第一个字符的下标。“o”的下标为4,则输出;“or”子字符串中的“o”字符的下标为7,则输出。
str="hello,world"
print(str.replace('h','H'),end='//')
print(str.replace('o','O',1))
上述代码运行结果为Hello,world//hellO,world。replace(old, new[, max])。replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
第一次输出结果,把“h”换成“H”;第二次输出结果,把第一个“o”换成“O”。
url="www.baidu.com"
print(url.split('.'),end='//')
print(url.split('.',1))
上述代码运行结果为[‘www’, ‘baidu’, ‘com’]//[‘www’, ‘baidu.com’]。split() 通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割出 num+1 个子字符串。返回分割后的字符串列表。
第一个输出以“.”分割字符串url。第二个输出以“.”分割字符串url一次。
2.3 列表
序列是 Python 中最基本的数据结构。
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
Python 有 6 个序列的内置类型,但最常见的是列表和元组。
列表都可以进行的操作包括索引,切片,加,乘,检查成员。
此外,Python 已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表中的元素不需要具有相同的类型。
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1=['bass',1,2,9999]
print(list1)
2.3.1 访问列表中的值
与字符串的索引一样,列表索引从 0 开始,第二个索引是 1,依此类推。
通过索引列表可以进行截取、组合等操作。

list1=['bass',1,2,9999]
print(list1[0])
print(list1[1])
print(list1[2])
print(list1[3])
上述代码运行结果:
bass
1
2
9999
索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。

list1=['bass',1,2,9999]
print(list1[-1])
print(list1[-2])
print(list1[-3])
print(list1[-4])
上述代码运行结果:
9999
2
1
bass
使用下标索引来访问列表中的值,同样你也可以使用方括号 [] 的形式截取字符,如下所示:
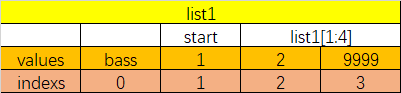
截取字符串list1
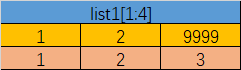
list1=['bass',1,2,9999]
print(list1[1:4])
上述代码运行结果:[1, 2, 9999]
list1=['bass',1,2,9999]
print(list1[1:-1])
上述代码运行结果:[1, 2]。与字符串切片一致,左闭右开,-1下标的值取不到,即截取到倒数第二位。
2.3.2 更新列表
对列表的数据项进行修改或更新,你也可以使用 append()方法来添加列表项,如下所示:
list1=['bass',1,2,9999]
print("第四个元素为",list1[3])
list1[3]=3
print("更新后的第四个元素为",list1[3])
print("更新后的list1",list1)
上述代码运行结果:
第四个元素为 9999
更新后的第四个元素为 3
更新后的list1 [‘bass’, 1, 2, 3]
修改原来列表中的值,通过下标找到该值,然后修改。
list1=['bass',1,2,9999]
list1.append(3)
print("更新后的list1:",list1)
上述代码运行结果:更新后的list1: [‘bass’, 1, 2, 9999, 3]。list1调用append方法对list1进行添加操作。
2.3.3 删除列表元素
可以使用 del 语句来删除列表的的元素,如下实例:
list1=['bass',1,2,9999]
del list1[3],list1[0]
print(list1)
上述代码运行结果:[1, 2]。
2.3.4 列表脚本操作符
list2=[1,2,3]
list3=['a','b','c']
list4=list2+list3
print(len(list4))
上述代码运行结果:6。len()计算luist4有多少个字符。
list2=[1,2,3]
list3=['a','b','c']
list4=list2+list3
print(list4)
list5=list4*2
print(list5)
上述代码运行结果:
[1, 2, 3, ‘a’, ‘b’, ‘c’]
[1, 2, 3, ‘a’, ‘b’, ‘c’, 1, 2, 3, ‘a’, ‘b’, ‘c’]
列表拼接。+号拼接列表内容,返回一个列表。列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
2.3.5 嵌套列表
使用嵌套列表即在列表里创建其它列表,例如:
list1=[['a','b','c'],[1,2,3]]
print(list1[1][0])
上述代码运行结果:1。
2.3.6 列表函数&方法
列表函数
| 函数 | 描述 |
|---|---|
| len(list) | 列表元素个数 |
| max(list) | 返回列表元素最大值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将元组转换为列表 |
list1=[1,2,3,4]
seq=(5,6,7,8)
print('list1列表的长度为',len(list1))
print('list1列表中的最大值为',max(list1))
print('list1列表中的最小值为',min(list1))
print('未转变为列表时',seq)
list2=list(seq)
print('转变为列表后',list2)
上述代码运行结果:
list1列表的长度为 4
list1列表中的最大值为 4
list1列表中的最小值为 1
未转变为列表时 (5, 6, 7, 8)
转变为列表后 [5, 6, 7, 8]
列表方法
| 方法 | 描述 |
|---|---|
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index,obj) | 将对象插入列表 |
| list.pop([idnex=-1]) | 删除列表中的一个元素(默认最后一个) |
| list.remove(obj) | 删除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort(key=None,reverse=False) | 对原列表进行排序 |
| list.clear() | 清空列表 |
| list.copy() | 复制列表 |
index()方法
语法:
list.index(x[, start[, end]])
x 查找的对象。
start 可选,查找的起始位置。
end 可选,查找的结束位置。
list1=['a','b','c']
print('a的索引值为',list1.index('a'))
print('b的索引值为',list1.index('b'))
print('c的索引值为',list1.index('c'))
上述代码运行结果:
a的索引值为 0
b的索引值为 1
c的索引值为 2
print(list1.index('c',2))
上述代码运行结果:
c的索引值为 2
若将2改为3,因为list1的最大索引值为2,3不是list1的索引值,则会报错。
insert() 方法
用于将指定对象插入列表的指定位置。
insert()方法语法:
list.insert(index, obj)
index 对象obj需要插入的索引的位置。
obj 要插入列表中的对象。
list1=[1,2,3,4]
list1.insert(2,90)
print(list1)
上述代码运行结果:
[1, 2, 90, 3, 4]
pop()方法
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
pop()方法语法:
list.pop([index=-1])
index 可选参数,要移除列表元素的索引值,不能超过列表总长度,默认为 index=-1,删除最后一个列表值。
list1=[1,2,3,4]
list1.pop()
list1.pop(0)
print(list1)
上述代码运行结果:[2, 3]。
remove()方法
remove() 函数用于移除列表中某个值的第一个匹配项。
remove()方法语法:
list.remove(obj)
obj 列表中要移除的对象。
list1=[1,2,3,4]
list1.remove(1)
print(list1)
上述代码运行结果:[2, 3, 4]
注:pop()方法按索引值删除列表中的元素,remove()方法直接删除列表中的元素。
reverse()方法
用于反向列表中元素。
语法:
list.reverse()
例子
list1=[1,2,3,4]
list1.reverse()
print(list1)
上述代码运行结果:[4, 3, 2, 1]
sort()方法
默认情况下,sort() 方法对列表进行升序排序。还可以让函数来决定排序标准。
语法:
list.sort(reverse=True|False, key=myFunc)
reverse 可选。reverse=True 将对列表进行降序排序。默认是 reverse=False,升序。
key 可选。指定排序标准的函数。
cars = ['Porsche','BMW','Volvo']
cars.sort(reverse=True)#降序排序
print(cars)
上述代码运行结果:[‘Volvo’, ‘Porsche’, ‘BMW’]
reverse=True,降序排序。
例子,按照值的长度对列表进行排序,利用key参数,指定排序标准。
def myFunc(e):
return len(e)
cars = ['Porsche', 'Audi', 'BMW', 'Volvo']
cars.sort(revrese=True,key=myFunc)
print(cars)
上述代码运行结果:[‘BMW’, ‘Audi’, ‘Volvo’, ‘Porsche’]
分析:myFunc()函数返回列表cars元素的长度,sort()方法进行降序排序。
copy()方法
法返回指定列表的副本。
语法:
list.copy()
clear() 方法
从列表中删除所有元素。
语法:
list.clear()
list()构造函数
thislist = list(('apple','banana','cherry'))
print(thislist)
上述代码运行结果:[‘apple’, ‘banana’, ‘cherry’]
列表小结

2.4 元组
元组是有序且不可更改的集合。在Python 中,元组是用圆括号编写的。
thistuple = ('apple','banana','cherry')
print(thistuple)
2.4.1 访问元组项目
通过引用方括号内的索引号来访问元组项目,如下例子:
thistuple = ('apple','banana','cherry')
print(thistuple[1])
负索引表示从末尾开始,-1 表示最后一个项目,-2 表示倒数第二个项目,依此类推,如下例子:
thistuple = ('apple','banana','cherry')
print(thistuple[-1])
通过指定范围的起点和终点来指定索引范围,,如下例子:
thistuple = ("apple", "banana", "cherry", "orange", "kiwi", "melon", "mango")
print(thistuple[2:5])
搜索将从索引 2(包括)开始,到索引 5(不包括)结束,第一项的索引为 0。
负索引范围
如果要从元组的末尾开始搜索,请指定负索引,如下例子:
thistuple = ("apple", "banana", "cherry", "orange", "kiwi", "melon", "mango")
print(thistuple[-4:-1])
此例将返回从索引 -4(包括)到索引 -1(排除)的元素。
2.4.2 更改元组值
创建元组后,您将无法更改其值。元组是不可变的,或者也称为恒定的。
但是有一种解决方法。可以将元组转换为列表,更改列表,然后将列表转换回元组。
thistuple = ("apple", "banana", "cherry", "orange", "kiwi", "melon", "mango")
upletolist = list(thistuple)#将元组转变为列表
upletolist[1] = "Banana" #将列表索引为1的值进行修改
newuple = tuple(upletolist)#将列表转换为元组
print(newuple)#输出更新后的元组
2.4.3 遍历元组
使用 for 循环遍历元组项目。
thistuple = ("apple", "banana", "cherry")
for x in thistuple:
print(x)
2.4.4 检查元素是否存在
要确定元组中是否存在指定的项,使用 in 关键字:
thistuple = ("apple", "banana", "cherry")
if "apple" in thistuple:
print("Yes,'apple' is in thistuple")
2.4.5 元组长度
要确定元组有多少项,使用 len() 方法
thistuple = ("apple", "banana", "cherry")
print(len(thistuple))
2.4.6 添加元素
元组一旦创建,您就无法向其添加项目。元组是不可改变的。
可以将元组转换为列表,更改列表,然后将列表转换回元组。
thistuple = ("apple", "banana", "cherry")
tupletolist = list(thistuple)#将元组转变为列表
tupletolist.append("orange")#在列表的末尾添加"orange"
newtuple = list(tupletolist)#将列表转变为新的元组
print(newtuple)#输出新的元组
2.4.7 创建只有一个元素的元组
如需创建仅包含一个元素的元组,必须在该项目后添加一个逗号,否则 Python 无法将变量识别为元组。
thistuple = ("apple",)
print(type(thistuple))
thistuple = ("apple")
print(type(thistuple))
上述代码运行结果为:
<class ‘tuple’>
<class ‘str’>
2.4.8 删除元组
thistuple = ("apple", "banana", "cherry")
del thistuple
2.4.9 合并两个元组
如需连接两个或多个元组,您可以使用 + 运算符:
tuple1 = ("a", "b" , "c")
tuple2 = (1, 2, 3)
tuple3 = tuple1 + tuple2
print(tuple3)
2.4.10 tuple()构造函数
可以使用 tuple() 构造函数来创建元组。
thistuple = tuple(("apple", "banana", "cherry"))
print(thistuple)
2.4.11 元组小结
| 方法 | 作用 |
|---|---|
| count() | 返回列表中某个元素值出现的次数 |
| index() | 在元组中搜索指定的值并返回它的索引值 |
tuple1 = (1,2,3,3,3,3)
print(tuple1.count(3))
tuple2 = ("aaple","banana", "cherry")
print(tuple2.index("aaple"))

2.5 集合
集合是无序和无索引的集合。在Python 中,集合用花括号编写。
thisset = {"apple","banana","cherry"}
print(thisset)
注:集合是无序的,因此无法确定元素的显示顺序。
2.5.1 访问元素
set是无序的,元素没有索引。
使用for循环遍历set元素,是用int关键字查询集合中是否存在指定值。
thisset = {"apple","banana","cherry"}
for x in thislist:
print(x)
print("apple" in thislist)
2.5.2 修改元素
集合一旦创建,您就无法更改元素,但是您可以添加新元素。
2.5.3 添加元素
(1)要将一个元素添加到集合,使用 add() 方法。
thisset = {"apple","banana","cherry"}
thisset.add("orange")
print(thisset)
(2)要向集合中添加多个元素,使用 update() 方法。
thisset = {"apple","banana","cherry"}
thisset.update(["orange","mango"])
print(thisset)
获取set的长度
thisset = {"apple","banana","cherry"}
print(len(thisset))
2.5.4 删除元素
(1) remove()
thisset = {"apple","banana","cherry"}
thisset.remove("apple")
print(thisset)
注:如果要删除的元素不存在,则会报错。
(2)discard()
thisset = {"apple","banana","cherry"}
thisset.discard("a")
print(thisset)
如果要删除的项目不存在,则 discard() 不会报错。
(3)pop()
pop() 方法删除元素,但此方法将删除最后一项。set 是无序的,因此不知道被删除的是哪个元素。
thisset = {"apple","banana","cherry"}
thisset.pop()
print(thisset)
分析:集合是无序的,因此在使用 pop() 方法时,您不会知道删除的是哪个元素。
(4)clear()
清空集合
thisset = {"apple","banana","cherry"}
thisset.clear()
print(thisset)
上述代码运行结果为:set()
(5)del
彻底删除集合
thisset = {"apple","banana","cherry"}
del thisset
2.5.5 合并两个集合
在Python 中,有两种方法可以连接两个或多个集合。
可以使用 union() 方法返回包含两个集合中所有项目的新集合,也可以使用 update() 方法将一个集合中的所有项目插入另一个集合中。
(1)union()
set1 = {"a","b","c"}
set2 = {1,2,3}
set3 = set1.union(set2)
print(set3)
(2)update()
set1 = {"a","b","c"}
set2 = {1,2,3}
set1.update(set2)
print(set1)
分析:union() 和 update() 都将排除任何重复项,运行结果都是无序的。
2.5.6 set()构造函数
thisset = set(("apple","banana","cherry"))
print(thisset)
2.5.7 set方法
(1)difference()
返回的集合包含仅在第一个集合中存在的元素,而同时不存在于两个集合中,即求差集。

语法:
set.difference(set)
set参数必需。要检查其中差异的元素。
x = {"apple","banana","cherry"}
y = {"google","microsoft","apple"}
z = y.difference(x)
print(z)
上述代码运行结果为:
{‘google’, ‘microsoft’}
difference()方法提取集合y的"google"和"microsoft"元素,因为"apple"为共有元素,则删除,将"google"和"microsoft"元素存进集合z。
(2)difference_update()
删除两个集合中都有的的元素。
语法:
set.difference_update(set)
例子
x = {"apple","banana","cherry"}
y = {"google","microsoft","apple"}
y.difference_update(x)#x.difference_update(y)
print(y)#print(x)
上述代码运行结果为:{‘google’, ‘microsoft’}
"apple"为集合x和集合y的共有部分,则删除"apple"元素,输入集合y。
difference_update()和difference()的不同之处:
difference() 方法返回一个新集合,而difference_update() 方法从原始集中删除了不需要的元素。
(3)isdisjoint()
判断集合x和集合y有没有包含相同的元素,若没有相同的元素,返回True。否则,返回False。
x = {"apple","banana","cherry"}
y = {"google","microsoft","apple"}
z = x.isdisjoint(y)#z = y.isdisjoint(x)
print(z)
上述代码运行结果为:False。
"apple"为集合x和集合y的共有元素,集合x调用isdisjoint()方法,参数为y。故返回False。
(4)issubest()
判断集合x是否是集合y的子集,若集合x是集合y的子集,则返回True,否则返回True。
x ={1,2,3}
y ={1,2,3,4,5}
print(x.issubset(y))
上述代码运行结果为:True。
集合x是集合y的子集,故返回True。
(5)symmetric_difference()
对称差相当于两个相对补集的并集。

x ={1,2,3}
y ={1,2,3,4,5}
print(x.symmetric_difference(y))
上述代码运行结果为:{4, 5}
删除集合x和集合y的共有元素1,2,3,集合x调用symmetric_difference()方法,参数为y。所以输入4,5。
(6)symmetric_difference_update()
在原始集合 x 中移除与 y 集合中的重复元素,并将不重复的元素插入到集合 x 中:
x = {1,2,3}
y = {4,5,1}
x.symmetric_difference_update(y)
print(x)
上述代码运行结果为:{2, 3, 4, 5}
集合x和集合y的共有部分为1,删除1。集合y中的4,5为不重复元素,插入集合x中。
集合小结

2.6 字典
字典是一个无序、可变和有索引的集合。
字典的每个键值(key,value)对用冒号“:” 分割。每个对之间用逗号“,”分割,整个字典包括在花括号“{}” 中 ,格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }

键必须是唯一的,但值可以不唯一。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
2.6.1 访问字典元素
(1)可以通过在方括号内引用其键名来访问字典的键的值
thisdict = {
"brand":"BMW",
"model":"z4",
"yeat":"2022"
}
print(thisdict["brand"])
上述代码结果为:BMW
(2)get()方法返回键的值
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
print(thisdict.get("model"))
上述代码结果为:z4
2.6.2 修改字典元素
通过使用字典名引用键名来更改特定项的值
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
thisdict["year"] = "2021"
print(thisdict.get("year"))
上述代码结果为:2021
2.6.3 遍历字典元素
(1)使用for语句分别返回字典的键值
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
for x in thisdict:
print(x)
上述代码运行结果为:
brand
model
year
例子
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
for x in thisdict:
print(thisdict[x])
上述代码运行结果为:
BMW
z4
2022
返回字典的值。
(2)使用values()方法返回字典的值
for x in thisdict.values():
print(x)
上述代码运行结果为:
BMW
z4
2022
返回字典的值。
(3)使用 items() 函数遍历键和值
for x,y in thisdict.items():
print(x,y)
上述代码运行结果为:
brand BMW
model z4
year 2022
2.6.4 检查键是否存在
格式如下:
key in dict
例子
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
"year" in thisdict
上述代码运行结果为:True
要确定字典有多少元素(键值对),使用 len() 方法。
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
print(len(thisdict))
上述代码运行结果为:3
2.6.5 添加元素
(1)使用字典名添加元素
格式如下:
dict[key]=value
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
thisdict["color"] = "red"
thisdict# print(thisdict)
上述代码运行结果为:
{'brand': 'BMW', 'model': 'z4', 'year': '2022', 'color': 'red'}
(2)使用update()方法添加元素
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
thisdict.update({"color":"red"})
thisdict
2.6.6 删除元素
(1)pop()方法
删除指定键,键对应值也随着删除。
格式如下:
dict.pop(key)
例子
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
thisdict.pop("model")
thisdict
上述代码运行结果为:
{'brand': 'BMW', 'year': '2022'}
(2)popitem()方法
删除最后一组键值对
格式如下:
dict.popitem()
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
print(thisdict)
thisdict.popitem()
print(thisdict)
上述代码运行结果为:
{'brand': 'BMW', 'model': 'z4'}
(3)del
删除键,键对应的值也随之删除。
格式如下:
del dict[key]
例子
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
del thisdict["model"]
print(thisdict)
上述代码运行结果为:
{'brand': 'BMW', 'year': '2022'}
完全删除字典,直接加上字典名,不需要键值。
del thisdict
print(thisdict) #this 会报错,因为 "thisdict" 不存在。
(4)clear()
清空字典
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
thisdict.clear()
print(thisdict)
上述代码运行结果为:
{}
分析:清空了字典里面的键值,但字典依旧存在,只不过是没有内容,为空。
2.6.7 复制字典
(1)使用 copy() 方法来复制字典
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
thisdict_copy = thisdict.copy()
thisdict_copy
上述代码运行结果为:
{'brand': 'BMW', 'model': 'z4', 'year': '2022'}
(2)使用dict()方法来复制字典
thisdict = {
"brand":"BMW",
"model":"z4",
"year":"2022"
}
thisdict_copy = dict(thisdict)
thisdict_copy
2.6.8 嵌套字典
字典中可以包含多个字典,称为嵌套字典。
classroom = {
'c1':{
'cno':1,
'cname':'1班'
},
'c2':{
'cno':2,
'cname':'2班'
},
'c3':{
'cno':3,
'cname':'3班'
}
}
print(classroom)
上述代码运行结果为:
{'c1': {'cno': 1, 'cname': '1班'}, 'c2': {'cno': 2, 'cname': '2班'}, 'c3': {'cno': 3, 'cname': '3班'}}
分析:在外层的值里面嵌套字典,外层的键与里层的字典用":"隔开。
例子:在一个字典里放三个字典如下代码:
classroom = {
'c1':c1,
'c2':c2,
'c3':c3
}
c1 = {
'cno':1,
'cname':'1班'
}
c2 = {
'cno':2,
'cname':'2班'
}
c3 = {
'cno':3,
'cname':'3班'
}
classroom
上述代码运行结果为:
{'c1': {'cno': 1, 'cname': '1班'},
'c2': {'cno': 2, 'cname': '2班'},
'c3': {'cno': 3, 'cname': '3班'}}
分析:外层字典中的值用“=”赋值给内层字典。
综上,嵌套字典的格式如下:
//第一种
dic = {
Key1:{
key1:value1,
key2:value2
},
Key2:{
key1:value1,
key2:value2
},
Key3:{
key1:value1,
key2:value2
}
}
//第二种
dic = {Key1:Value1,Key2:Value2,Key3:Value3}
Value1 = {
key1:value1,
key2:value2,
key3:value3
}
Value2 = {
key1:value1,
key2:value2,
key3:value3
}
Value3 = {
key1:value1,
key2:value2,
key3:value3
}
2.6.9 dict()构造函数
可以使用 dict() 构造函数创建新的字典:
thisdict = dict(brand="BMW", model="z4", year=2022)
# 请注意,使用了等号而不是冒号来赋值
print(thisdict)
上述代码运行结果为:
{'brand': 'BMW', 'model': 'z4', 'year': 2022}
2.6.10 字典方法
| 方法 | 描述 |
|---|---|
| clear() | 删除字典中的所有元素,但是字典依然存在 |
| copy() | 返回字典的副本 |
| fromkeys() | 返回拥有指定键值的字典 |
| get() | 返回有指定键的值 |
| items() | 返回包含每个键值 |
| keys() | 返回字典键 |
| pop() | 删除指定键的元素 |
| popitem() | 删除最后插入的键值对 |
| setdefault() | 返回指定键的值。如果该键不存在,则插入具有指定值的键 |
| update() | 添加字典的键值对 |
| values() | 返回字典中的值 |
fromkeys()方法
语法:
dict.fromkeys(keys, value)
| 参数 | 描述 |
|---|---|
| keys | 必需。指定新字典的键 |
| value | 可选。所有键的值。默认值是None |
例子:创建拥有 3 个键的字典,值均为 0
dic = {}
x =("key1","key2","key3")
y = 0
# thisdict = dict.fromkeys(x, y)
thisdict = dic.fromkeys(x,y)
thisdict
上述代码运行结果为:
{'key1': 0, 'key2': 0, 'key3': 0}
字典小结

2.7 类型转换
3 运算符
运算符有算术运算符、赋值运算符、比较运算符、逻辑运算符、身份运算符、成员运算符和位运算符。
3.1 算术运算符
算术运算符与数值一起使用来执行常见的数学运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | x + y |
| - | 减 | x - y |
| * | 两个数相乘或是返回一个被重复若干次的字符串 | x * y |
| / | 除 | x / y |
| % | 取模。返回除法的余数 | x % y |
| ** | 幂 | x ** y |
| // | 取整除 - 向下取接近商的整数(即向数轴的负方向取整) | x/ / y |
a = 3
b = 13
print(b//a)#4
c = -3
print(b//c)#-5
3.2 赋值运算符
赋值运算符用于为变量赋值
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | x = 5 | / |
| += | 加法赋值运算符 | x += 5 |
| -= | 减法赋值运算符 | x -= 5 |
| *= | 乘法赋值运算符 | x *= 5 |
| /= | 除法赋值运算符 | x /= 5 |
| %= | 取模赋值运算符 | x %= 5 |
| //= | 取整除赋值运算符 | x //= 5 |
| **= | 幂赋值运算符 | x **= 5 |
3.3 比较运算符
比较运算符用于比较两个值
| 远算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| == | 等于 | x == y | True/False |
| != | 不等于 | x != y | True/False |
| > | 大于 | x > y | True/False |
| < | 小于 | x < y | True/False |
| >= | 大于等于 | x >= y | True/False |
| <= | 小于等于 | x <= y | True/False |
3.4 逻辑运算符
逻辑运算符用于组合条件语句
| 远算符 | 描述 | 实例 |
|---|---|---|
| and | 如果两个变量是同一个对象,则返回 true | x > 5 and x <10 |
| or | 如果两个变量不是同一个对象,则返回 true | x > 5 or x <10 |
| not | 反转结果,如果结果为 true,则返回 False | not(x > 5 or x <10) |
3.5 身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(x) != id(y)。如果引用的不是同一个对象则返回结果 True,否则返回 False |
a = 7
b = 7
if(a is b):
print("a和b有相同的标识")
else:
print("a和没有相同的标识")
if(id(a) == id(b)):
print("a和b有相同的标识")
else:
print("a和没有相同的标识")
c = 13
if (a is not c):
print("a和c没有相同的标识")
else:
print("a和c有相同的标识")
上述代码运行结果为:
a和b有相同的标识
a和b有相同的标识
a和c没有相同的标识
3.6 成员运算符
成员运算符用于测试序列是否在对象中出现
| 远算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | x 在 y 序列中 , 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True |
list1 =[1,2,3,4]
print(4 in list1)#True
print(5 in list1)#False
print(5 not in list1)#True
3.7 位运算符
位运算符用于比较(二进制)数字
| 远算符 | 描述 |
|---|---|
| & | 按位与运算符 |
| I | 按位或运算符 |
| ^ | 按位异或运算符 |
| ~ | 按位取反运算符 |
| << | 左移动运算符。运算数的各二进位全部左移若干位,高位丢弃,低位补0。 |
| >> | 右移动运算符。把">>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数 |
按位与运算符如下例子:
a = 7#0000 0111
b = 13#0000 1101
c =0
c = a & b
print(c)#0000 0101 输出5
按位或运算符如下例子:
a = 7#0000 0111
b = 13#0000 1101
c =0
c = a | b
print(c)#0000 1111 输出15
按位异或运算符如下例子:
a = 7#0000 0111
b = 13#0000 1101
c =0
c = a ^ b
print(c)#0000 1010 输出10
按位取反运算符如下例子:
a = 7#0000 0111
print(~a)#1111 1000 #-8
#1111 1111 = -1
左移动运算符如下例子:
a = 7#0000 0111
print(a<<2)# 0001 1100 = 28
右移动运算符如下例子:
a = 7#0000 0111
print(a>>2)# 0000 0001 = 1
3.8 运算符优先级
以下表格列出了从最高到最低优先级的所有运算符
| 运算符 | 描述 |
|---|---|
| ** | 幂运算 |
| ~ | 按位取反 |
| * / % // | 乘、除、取余、地板整除 |
| + - | 加法减法 |
| << >> | 左移、右移运算符 |
| & | 按位与运算 |
| ^ I | 按位或运算,按异或运算 |
| <= < > >= | 比较运算符 |
| == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
注意:Pyhton3 已不支持 <> 运算符,可以使用 != 代替。
4 语句结构
语句结构主要循环和分支。
4.1 分支

Python中if语句的一般形式如下所示:
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
如果 “condition_1” 为 True 将执行 “statement_block_1” 块语句
如果 “condition_1” 为False,再判断 “condition_2”
如果"condition_2" 为 True 将执行 “statement_block_2” 块语句
如果 “condition_2” 为False,将执行"statement_block_3"块语句
注意点:
1每个条件后面要使用冒号 :,表示接下来是满足条件后要执行的语句块。
2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
3、在Python中没有switch case语句。
关键字
if 语句使用if关键词来写。
例子如下:
a = 220
b = 66
if(a>b):
print("a is greater than a")
简写如下:
a = 220
b = 66
if(a>b):print("a is greater than a")
elif关键字是 python 对“如果之前的条件不正确,那么试试这个条件”的表达方式。
例子如下:
a = 220
b = 220
if(a>b):
print("a is greater than a")
elif a == b:
print("a and b are equal")
else关键字捕获未被之前的条件捕获的任何内容,例子如下:
a = 220
b = 221
if(a>b):
print("a is greater than b")
else:
print("a is not greater than b")
简写上述代码如下:
a = 220
b = 221
print("a is greater than b") if a>b else print("a is not greater than b")
if语句常于逻辑运算符配合使用
a = 1
b = 2
c = 3
d = 4
if(b > a and d > c):
print("True")
if(b < a or d > c):
print("True")
嵌套if
可以在if-else语句中包含if-else语句。
num=int(input("输入一个数字:"))
if num%2 == 0:
if num%3 == 0:
print("输入的数字可以被2和3整除")
else:
print("输入的数字可以被2整除,但不能被3整除")
else:
if num%3 == 0:
print("输入的数字不能被2整除,能被3整除")
else:
print("输入的数字不能被2和3整除")
pass 语句
if 语句不能为空,但是如果您处于某种原因写了无内容的 if 语句,请使用 pass 语句来避免错误。
a = 7
b = 13
if a > b:
pass
4.2 循环
循环结构有while循环和for循环。
Python 循环语句的控制结构图如下所示:

4.2.1 while
(1)语法格式如下:
while (condition):
(statements)......
执行流程图如下:

注意:
冒号和缩进;在 Python 中没有 do…while 循环。
例子:使用while求1到100的和
i = 1
sum = 0
while i <= 100:
sum = sum + i
i = i + 1
print(sum)
分析:
递增 i,否则循环会永远继续。
while循环需要准备好相关的变量。在这个例子中,我们需要定义一个索引变量 i,我们将其设置为 1。
(2)无限循环
n = 1
while (n):print("heoll,world~")
以上为无线循环。
(3)while 循环使用else语句
通过使用 else 语句,当条件不再成立时,我们可以运行else里面的语句块。
例子如下:
(4)while 循环使用break 语句
如果使用 break 语句,即使 while 条件为真,终止循环。
break 执行流程图如下:

例子如下:
i = 1
while i < 7:
print(i)
if(i == 3):
break
i = i+1
(5)while 循环使用continue语句
使用 continue语句,停止当前的迭代,再次进入循环。
continue执行流程图如下:

例子如下:
i = 0
while i < 7:
i = i+1
if(i == 3):
continue
print(i)
上述代码运行效果如下:
1
2
4
5
6
7
4.2.2 for
for循环可以遍历任何可迭代对象,如列表,元组,字典,集合或字符串。
for循环的格式如下:
for <variable> in <sequence>:
<statements>
else:
<statements>
(1)通过使用 break语句,我们可以在循环遍历所有元素之前停止循环。
thisset = {1,2,3,4}
for x in thisset:
print(x,end=" ")
if x == 2:
break
上述代码运行结果为:
1 2
(2)通过使用continue语句,我们可以停止循环的当前迭代,并继续下一个。
thisset = {1,2,3,4}
for x in thisset:
if x == 2:
continue
print(x,end=" ")
上述代码运行结果为:
1 3 4
(3)for循环中的else关键字指定循环结束时要执行的代码块
for x in range(1,10,2):
print(x)
else:
print("finished")
(4)for 语句不能为空,但是如果您处于某种原因写了无内容的 for 语句,请使用 pass 语句来避免错误。
for x in range(1,10,2):
pass
(5)使用range() 函数,循环一组代码指定的次数
使用格式如下:
range(first,second,step)
range() 函数返回一个数字序列,默认情况下从 0 开始,并递增 1(默认地),并以指定的数字结束。
例子如下:
for x in range(10):
print(x)
分析:
range(10)是值 0 到 9。
range() 函数默认0为起始值,不过可以通过添加参数来指定起始值:range(3, 10),这意味着值为 3 到 10(但不包括 10)。
使用起始参数例子如下:
for x in range(3,10):
print(x)
range() 函数默认将序列递增 1,但是可以通过添加第三个参数来指定步长
for x in range(1,10,2):
print(x)
可以结合range()和len()函数以遍历一个序列的索引和索引对应的值
fruits = ["apple","banana","cherry"]
for x in range(len(fruits)):
print(x,fruits[x])
上述代码运行结果如下:
0 apple
1 banana
2 cherry
(6)嵌套循环
嵌套循环是循环内的循环。
“外循环”每迭代一次,“内循环”将执行一次
adj = ["big","red","tasty"]
fruits = ["apple","banana","cherry"]
for x in adj:
for y in fruits:
print(x,y)
上述代码运行结果如下:
big apple
big banana
big cherry
red apple
red banana
red cherry
tasty apple
tasty banana
tasty cherry
4.3 迭代器与生成器(补充)
迭代是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束,迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
列表、元组、字典和集合都是可迭代的对象,它们是可迭代的容器。
list1 = [1,2,3,4]
it = iter(list1)#创建迭代器对象
print(next(it))#输出迭代器的下一个元素,1
print(next(it))#输出迭代器的下一个元素,2
print(next(it))#输出迭代器的下一个元素,3
print(next(it))#输出迭代器的下一个元素,4
迭代器对象可以使用for语句进行遍历
list1 = [1,2,3,4]
it = iter(list1)#创建迭代器对象
for x in it:
print(x,end=' ')
上述代码运行结果如下:
1 2 3 4
使用next()函数
import sys
list1 = [1,2,3,4]
it = iter(list1)#创建迭代器对象
while True:
try:
print(next(it))
except StopIteration:
sys.exit()
上述代码代码运行结果如下:
1
2
3
4
创建一个迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__() 。
__iter__() 方法返回一个特殊的迭代器对象。
__next__()方法(Python 2 里是 next())会返回下一个迭代器对象。
__next__()方法并通过 StopIteration 异常标识迭代的完成。
例子:创建一个返回数字的迭代器,初始值为 1,逐步递增 1。
class MyNumber:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a = self.a + 1
return x
myclass = MyNumber()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 __next__() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
在 10 次迭代后停止执行
class MyNumber:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <=10:
x = self.a
self.a = self.a + 1
return x
else:
raise StopIteration
myclass = MyNumber()
myiter = iter(myclass)
for x in myiter:
print(x)
4.4 小结
语句结构分为分支和循环。
分支用if 、else和elif关键字。
循环用while和for关键字。
迭代器对象可以使用for语句进行遍历。
5 函数
函数是一种仅在调用时运行的代码块。
您可以将数据(称为参数)传递到函数中。
函数可以把数据作为结果返回。
5.1 函数的定义
函数的定义规则:
(1)函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
(2)任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
(3)函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
(4)函数内容以冒号 : 起始,并且缩进。
(5)return[表达式]结束函数,选择性地返回一个值给调用方,不带表达式的return相当于返回 None。

5.2 函数的调用
如需调用函数,请使用函数名称后跟括号
函数名 ([实参1,实参2,...])
例子如下:
def printme(str):
print(str)
return
printme("调用用户自定义函数!")
printme("再次调用用户自定义函数!")
5.3 可变对象和不可变对象
类型属于对象,对象有不同类型的区分,变量是没有类型的。
在 python 中,strings,tuples和numbers 是不可更改的对象。而 list,dict 等则是可以修改的对象。
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变 a 的值,相当于新生成了 a。
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 传不可变对象实例,通过 id() 函数来查看内存地址变化
def change(a):
print(id(a)) # a = 1
a = 10
print(id(a)) # a = 10 一个新对象
a = 1
print(id(a)) # a = 1
change(a)# 调用 change函数,参数为a
上述代码运行结果如下:
140718799434576
140718799434576
140718799434864
分析:在调用函数前后,形参和实参指向的是同一个对象(对象 id 相同),在函数内部修改形参后,形参指向的是不同的 id。
传可变对象实例。可变对象在函数里修改了参数,那么在调用这个函数的函数里,原始的参数也被改变了。
def changeme(mylist):
"修改传入的列表"
mylist.append([1,2,3,4])
print("函数内取值",mylist)
return
mylist = [11,22,33]
changeme(mylist)
print("函数外取值",mylist)
上述代码运行结果如下:
函数内取值 [11, 22, 33, [1, 2, 3, 4]]
函数外取值 [11, 22, 33, [1, 2, 3, 4]]
分析:传入函数的和在末尾添加新内容的对象用的是同一个引用。列表是可变类型。
5.4 参数
参数在函数名后的括号内指定。您可以根据需要添加任意数量的参数,只需用逗号分隔即可。
调用函数时可使用的正式参数类型有:必需参数、关键字参数、默认参数和不定长参数。
5.4.1 必需参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
下述例子为错误示范:
def printme(str):
print(str)
return
printme()
调用printme()函数时没有加参数会报错。
5.4.2 关键字参数
使用 key = value 语法发送参数,参数的顺序无关紧要。
def my_function(child3, child2, child1):
print("The youngest child is " + child3)
my_function(child1 = "Phoebe", child3 = "Rory",child2 = "Jennifer")
上述代码运行结果如下:
The youngest child is Rory
5.4.3 默认参数
调用函数时,如果没有传递参数,则会使用默认参数。
以下实例中如果没有传入 age 参数,则使用默认值:
def printinfo(name,age = 100):
print("名字为:",name)
print("年龄为",age)
return
printinfo(age = 50,name = "叶大叔")
print("-----------"*3)
printinfo(name = "李老汉")
上述代码运行结果如下:
名字为: 叶大叔
年龄为 50
---------------------------------
名字为: 李老汉
年龄为 100
5.4.4 不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数。
基本语法如下:
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了星号*的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。
def printinfo(arg1,*vartuple):
print(arg1)
print(vartuple)
printinfo(70,60,50)
上述代码运行结果如下:
70
(60, 50)
还有一种就是参数带两个星号**基本语法如下:
def functionname([formal_args,] **var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了两个星号**的参数会以字典的形式导入。字典以键值对的形式出现。
def printinfo(arg1,**vardict):
print(arg1)
print(vardict)
printinfo(70,a=60,b=50)
上述代码运行结果如下:
70
{'a': 60, 'b': 50}
声明函数时,参数中星号*可以单独出现,星号 * 后的参数必须用关键字(键值对)传入,如下:
def f(a,b,*,c):
return a+b+c
f(1,2,c=3) #6
5.5 匿名函数
Python 使用 lambda 来创建匿名函数。
匿名,即不再使用 def 语句这样标准的形式定义一个函数。
lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。
lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
lambda 函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
例子如下:
x = lambda a: a+100
print(x(5)) #105
例子:匿名函数设置两个参数
sum = lambda arg1,arg2: arg1+arg2
sum(10,20) #30
例子:将匿名函数封装在 myfunc 函数中,通过传入不同的参数来创建不同的匿名函数
def myfunc(n):
return lambda a: a*n
mydoubler = myfunc(2)
mytripler = myfunc(3)
print(mydoubler(11)) #22
print(mytripler(11)) #33
5.6 return语句
return [表达式]语句用于退出函数,选择性地向调用方法返回一个表达式。不带参数值的return语句返回None。
def sum(arg1,arg2):
total = arg1+arg2
return total
sum(22,11) #33
5.7 小结
函数用def关键字定义,函数就是方法,为了解决一个问题的对策。
函数参数有必需参数、关键字参数、默认参数和不定长参数。
匿名函数使用lambda来创建。
return语句退出函数,调用方法返回一个值。
6 IO和文件操作
文件处理是任何 Web 应用程序的重要组成部分。
Python 有几个用于创建、读取、更新和删除文件的函数。
6.1 文件打开
open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出OSError。
格式如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
open()函数参数说明
| 参数 | 描述 |
|---|---|
| file | 必需,文件路径(相对或者绝对路径) |
| mode | 可选,文件打开模式 |
| buffering | 设置缓冲 |
| errors | 报错级别 |
| newline | 区分换行符 |
| closefd | 传入的file参数类型 |
| opener | 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符 |
例子:
f = open("小王子.txt",encoding="utf8")
#等同于f = open("小王子.txt",mode="rt",encoding="utf8")
f.close()
"r" (读取)和 "t" (文本)是默认值,所以不需要指定它们。
mode参数值说明
| 模式 | 描述 |
|---|---|
| r | 读取。默认值。打开文件进行读取,如果文件不存在则报错 |
| a | 追加。打开供追加的文件,如果不存在则创建该文件 |
| w | 写入。打开文件进行写入,如果文件不存在则创建该文件 |
| x | 创建。创建指定的文件,如果文件存在则返回错误 |
| t | 文本。默认值。文本模式 |
| b | 二进制。二进制模式(例如图像) |
file 对象
file对象使用 open 函数来创建,下表列出了file对象常用的函数
| 方法 | 描述 |
|---|---|
| file.close() | 关闭文件。关闭后文件不能再进行读写操作 |
| file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入 |
| file.fileno() | 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上 |
| file.isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False |
| file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有 |
| file.readline([size]) | 读取整行,包括 “\n” 字符 |
| file.readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区 |
| file.seek() | 移动文件读取指针到指定位置 |
| file.tell() | 返回文件当前位置 |
| file.truncate([size]) | 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小 |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符 |
6.2 文件读取
open()函数返回文件对象,此对象有一个 read()方法用于读取文件的内容
读取所有内容,如下:
f = open("小王子.txt",encoding="utf8")
print(f.read())
只读取文件的一部分,如下:
f = open("小王子.txt",mode="rt",encoding="utf8")
print(f.read(100))
返回文件中的前100个字符。
readline()方法返回一行,如下:
f = open("小王子.txt",encoding="utf8")
print(f.readline())
readlines(size)方法,读取size个整行,包括 “\n” 字符,如下:
f = open("小王子.txt",encoding="utf8")
print(f.readlines(100))
readlines(size)方法,读取100个整行,包括 “\n” 字符。
通过循环遍历文件中的行,逐行读取整个文件,如下:
f = open("小王子.txt",encoding="utf8")
for x in f:
print(x)
完成后始终关闭文件是一个好习惯,如下:
f = open("小王子.txt",encoding="utf8")
print(f.read())
f.close()
6.3 写入和创建文件
如需写入已有的文件,必须向 open()函数添加参数
| 参数 | 描述 |
|---|---|
| a | 追加。会追加到文件的末尾。 |
| w | 写入。会覆盖任何已有的内容。 |
打开文件 “demofile.txt” 并将内容追加到文件中,如下:
f = open("demofile.txt","a")
f.write("Now the file has more content!")
f.close()
f = open("demofile.txt")
print(f.read())
打开文件 “demofile.txt” 并覆盖内容,如下:
f = open("demofile.txt","w")
f.write("I have deleted the content!")
f.close()
f = open("demofile.txt","r")
print(f.read())
"w"参数值会覆盖全部内容。
在Python中创建新文件,请使用open()方法,并使用以下参数之一,如下:
| 参数 | 描述 |
|---|---|
| x | 创建。将创建一个文件,如果文件存在则返回错误 |
| a | 追加。如果指定的文件不存在,将创建一个文件 |
| w | 写入。如果指定的文件不存在,将创建一个文件 |
如果不存在,则创建新文件,如下:
f = open("demofile2,txt","w")
f.write("该文件不存在,创建新文件,写入内容")
f.close()
f = open("demofile2,txt","r")
print(f.read())
f.close()
6.4 文件删除
删除文件,必须导入 OS 模块,并运行其 os.remove() 函数。
为避免出现错误,删除文件之前检查该文件是否存在,如下:
import os
if os.path.exists("demofile.txt"):
os.remove("demofile.txt")
else:
print("The file does not exist")
删除整个文件夹,请使用 os.rmdir()方法,如下:
import os
os.rmdir("myfolder")
只能删除空文件夹。
6.5 csv文件格式处理
逗号分隔值(Comma-Separated Values,CSV),其文件以纯文本形式存储表格数据(数字和文本),文件的每一行都是一个数据记录。每个记录由一个或多个字段组成,用逗号分隔。
6.5.1 读取csv文件格式
读取demo.csv文件,如下:
import csv
with open('demo.csv','r',encoding='utf8') as f:
obj = csv.reader(f)
for i in obj:
print(i)
分析:打开demo.csv,字符编码为utf8,创建obj对象,使用foe循环遍历obj对象的内容。
将读取csv文件封装为一个方法,如下:
def read_csv(file_name):
result = []#用来存放csv文件中的每一行内容
with open(file_name,'r',encoding='utf8') as f:
obj = csv.reader(f)
for i in obj:
result.append(i)
return result
result = read_csv('demo.csv')
for x in result:
print(x)
问:为什么需要result列表?
答:result列表用与存储读取csv文件,若没有result列表,会报csv关闭的错误。
6.5.2 在csv文件格式写入内容
在demo文件写入['2','李四','18岁'],如下:
import csv
with open('demo.csv','a',encoding='utf8',newline='') as f:
obj = csv.writer(f)
obj.writerow(['1','张三','14岁'])
分析:以追加的方式打开demo文件,newline=''为了写入时不会在下一行插入多余的空行。writerow()方法为写入一行内容。
将在csv文件写入内容封装成一个方法,如下:
def write_csv(file_name,content):
with open(file_name,'a',encoding='utf8',newline='') as f:
obj = csv.writer(f)
obj.writerow(content)
write_csv('demo.csv',['2','李四','18岁'])
分析:参数为文件名和写入的内容。
6.6 excel文件处理
打开excel文件
下载xlrd包,在命令行窗口输入pip install xlrd下载到对应的目录下,如下:

123.xlsx文件内容如下:
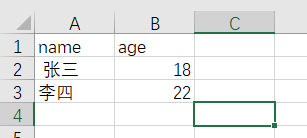
打开123.xlsx文件,代码如下:
import xlrd
def read_excel(path,index):
excel = xlrd.open_workbook(path) #打开一个excel文件
sheet = excel.sheets()[index]#找到具体的sheet
return sheet
table = read_excel('123.xlsx',0) #调用方法,得到sheet1
for i in range(1,table.nrows): #table.nrows返回行数,以此确定遍历的次数
rows = table.row_values(i) #得到每一行的具体内容,以列表的形式返回
print(rows)#打印一行的内容
print(rows[0])#打印每行的第一个元素,也就是下标为0的元素
分析:range()从1开始读取,除去字段。
6.7 xml文件处理
可扩展标记语言,标准通用标记语言的子集,简称xml。
首先,新建123.xml文件,如下:

然后,定义read_xml方法,如下:
import xml.etree.ElementTree as ET
def read_xml(filename,node_name):
datas = []#定义一个空列表,用来存储指定字段的内容
tree = ET.parse(filename)#得到元素树
root = tree.getroot()#得到根
for i in root.iter(node_name):#循环遍历指定的字段
datas.append(i.text)#将匹配的字段的值加入列表
return datas
result = read_xml('123.xml','username')
print(result)
print(result[1])
上述代码运行结果如下:
['admin', '张三', '李四']
张三
6.8 小结
文件有打开、读取、写入和删除操作。
文件类型有txt文本文件、csv格式文件、excel文件和xml文件。
读取文件用open()方法,读取文件一般使用read()方法,写入文件在open()方法中加入参数'w'。
对csv格式文件进行操作导入 csv模块。
对excel文件进行操作导入 xlrd模块。
对xml文件进行操作导入xml.etree.ElementTree模块。
7 类和对象
Python 是一种面向对象的编程语言。
Python 中的几乎所有东西都是对象,拥有属性和方法。
类(Class)类似对象构造函数,或者是用于创建对象的“蓝图”。
7.1 简介
面向对象:(Object Oriented,简称OO)是把构成问题的事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事务在整个解决问题的步骤中的行为。
类:是对现实生活中一类具有共同特征的事物的抽象。类是属性和方法的集合。
对象:类的实例化得到的,对象具备类的属性和方法。
属性:描述对象和类的特征。
方法:描述对象和类的能力和动作。
面向对象三大特征:封装、继承和多态。
7.2 封装
将数据和操作封装为一个整体,由于类中私有成员都是隐藏的,只向外部提供有限的接口,所以能够保证内部的高内聚与外部的低耦合性。使用者不比了解具体的实现细节,而只是通过外部接口,以特定的访问权限来使用类的成员,能够增强安全性和简化编程。
(1)创建类和对象
类的定义用class关键字定义。创建对象,即实例化类,这时对象可以使用类的属性和方法,通过对象名访问类的属性和方法。
创建MyClass类和创建x对象,如下:
class Person:
name = "张三"
def hello(self):
return "hello,world"
p1 = Person()#实例化类
(2)__init__()方法和__del__()方法
所有类都有一个名为 __init__() 的函数,最优先执行。
使用__init__()函数将值赋给对象属性。
__del__(),最后执行,用来回收对象,释放资源。
例子:创建名为Person的类,使用__init__() 函数为name和age 赋值,如下:
class Person:
def __int__(self,name,age):
self.name = name
self.age = age
p1 = Person("bass",18)
print(p1.name)
print(p1.age)
注:
每次使用类创建新对象时,都会自动调用__init__()函数。
__init__()函数必须包含参数 self, 且为第一个参数。
(3)类方法
创建了对象后,该对象可以调用类方法,在Person类添加mufunc()方法,如下:
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
def myfunc(self):
print("Hello my name is "+self.name)
p1 = Person("bass",18)
# print(p1.name)
# print(p1.age)
p1.myfunc()
(4)self参数
self代表类的实例,而非类。
它不必被命名为self,您可以随意调用它,但它必须是类中任意函数的首个参数。
例子:使用单词ab和abc代替 self,如下:
class Person:
def __init__(ab,name,age):
ab.name = name
ab.age = age
def myfunc(abc):
print("Hello my name is "+abc.name)
p1 = Person("bass",18)
print(p1.name)
print(p1.age)
p1.myfunc()
(5)类的私有属性和类的私有方法
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
class Person01:
def __init__(self,name,age):
self.name = name
self.__age = age
def hello(self):
print("name:",self.name)
print("age:",self.__age)
def __f(self):#私有方法
print("这时是私有方法")
def f(self):#公共方法
print("这是公共方法")
self.__f()#私有方法只能在类的内部调用
p1 =Person01("张三",18)
p1.hello()#正常输出
p1.f()#正常输出
p1.__f()#报错 私有方法不能在类的外部调用
7.3 继承
继承允许我们定义继承另一个类的所有方法和属性的类。
父类是继承的类,也称为基类。
子类是从另一个类继承的类,也称为派生类。
7.3.1 创建父类
例子:创建Person类,有fname和ownname属性,printname方法,如下:
class Person:
def __init__(self,fname,ownname):
self.fname = fname
self.ownname = ownname
def printname(self):
print("姓为"+self.fname,"名为"+self.ownname)
p1 = Person("张","三")
p1.printname()
7.3.2 创建子类
创建从其他类继承功能的类,请在创建子类时将父类写在子类参数中
例子:创建一个名为 Student 的类,它将从 Person 类继承属性和方法,如下:
class Student(Person):
pass
使用 Student 类创建一个对象,然后执行 printname 方法,如下:
s1= Student("李","四")
s1.printname()
现在,Student 类拥有与 Person类相同的属性和方法。
使用 Student 类创建一个对象,然后执行 printname 方法,如下:
s1= Student("李","四")
s1.printname()
7.3.3 添加__init__()函数
把__init__()函数添加到子类,如下:
class Student(Person):
def __init__(self,fname,ownname):
在子类里添加 __init__()函数时,子类将不再继承父的 __init__()函数。
如果需要保持父的__init__() 函数的继承,请添加对父的 __init__()函数的调用,如下:
class Student(Person):
def __init__(self,fname,ownname,age):
Person.__init__(self,fname,ownname)
上述代码让子类保留了父类的继承
7.3.4 使用super()函数
super() 函数,它会使子类从其父继承所有方法和属性,如下:
class Student(Person):
def __init__(self,fname,ownname,age):
super().__init__(fname,ownname)
通过使用 super() 函数,您不必使用父元素的名称,它将自动从其父元素继承方法和属性。
注意:super() 函数引用的__init__() 函数中的参数。没有self参数!
7.3.5 添加属性
把age属性添加到Student类(子类)中,如下:
class Student(Person):
def __init__(self,fname,ownname,age):
Person.__init__(self,fname,ownname)
self.age = age
s1= Student("李","四",18)
print(s1.age)
分析:在子类里的 __init__() 函数中添加age属性。
7.3.6 添加方法
把welcome()方法添加到Student类(子类)中,如下:
class Student(Person):
def __init__(self,fname,ownname,age):
super().__init__(fname,ownname)
self.age = age
def welcome(self):
print("姓为",self.fname,"。名为",self.ownname,"。年纪为",self.age)
创建子类对象s1,该对象调用welcome()方法,如下:
s1= Student("李","四",18)
s1.welcome()
7.3.7 重写方法
在子类中添加一个与父类中的函数同名的方法,则将覆盖父方法的继承。
例子:在Student类(子类)重写printname()方法,如下:
class Student(Person):
def __init__(self,fname,ownname,age):
super().__init__(fname,ownname)#Person.__init__(self,fname,ownname)
self.age = age
def welcome(self):
print("姓为",self.fname,"。名为",self.ownname,"。年纪为",self.age)
def printname(self):
print("输出姓为",self.fname,"输出名为",self.ownname,"输出年龄",self.age)
注:
问:重写和重载有什么区别?
答:Python中有重写,没有重载。重载在Java中有,以Java语言为例子演示如下:
public class E06 {
public String test(int a,String s) {
System.out.println(+a+s);
return "1";
}
public int test(String s,int a) {
System.out.println(s+a);
return 2;
}
public int test(String s,int a,int b) {
System.out.println(s+a+b);
return 3;
}
public static void main(String[] args) {
E06 e1= new E06();
System.out.println(e1.test(1234, "bass"));
System.out.println(e1.test("top", 2));
System.out.print(e1.test("basstop", 123,456));
}
}
7.4 多态
调用相同名称的方法,传入不同的参数对象,展现出不同的结果,这就叫多态。
例子如下:
class Father:
def study(self):
print("Father:study")
class Son(Father):
def study(self):
print("Son:study")
def method(obj):
obj.study()
f = Father()
s = Son()
method(f)
method(s)
分析:建立Father类和Son类。定义method方法,方法体调用Father类里的方法。实例化Father类对象,f和Son类对象,s。调用method方法,参数为f和s。
7.5 小结
类是对象的抽象,对象是类的具体。
封装将数据和操作封装为一个整体。
创建类由class关键字定义,在类中的__init__()方法写类的属性,类的操作或动作写成函数。
父类是继承的类,也称为基类。
子类是从另一个类继承的类,也称为派生类。
子类可以继承父类的所有方法和属性的类,也可以在子类里添加 __init__()函数时,子类将不再继承父的 __init__()函数。
多态是调用相同名称的方法,传入不同的参数对象,展现出不同的结果。
8 异常
try块允许您测试代码块以查找错误。
except块允许您处理错误。
finally块允许您执行代码,无论 try 和 except 块的结果如何。
8.1 try/except
Python 并发生错误或异常时,通常会停止并生成错误消息。
例子:try块将生成异常,如下:
try:
print(x)
except:
print("异常")
分析: x 未定义,执行except块语句。
根据需要定义任意数量的 except块。
try块引发 NameError,则打印一条消息,如果是其他错误则打印另一条消息,如下:
try:
print(x)
except NameError:
print("变量未定义")
except:
print("Something went wrong")
上述代码运行结果为:变量未定义
8.2 try/except…else
else块将在try块没有发生任何异常的时候执行。
try:
{执行代码}
except:
{发生异常时执行的代码}
else:
{没有异常时执行的代码}
例子:try块不会生成任何错误,如下:
try:
print("hello")
except:
print("Somrhing went wrong")
else:
print("Nothing went wrong")
使用 else块比把所有的语句都放在 try块里面要好,这样可以避免一些意想不到,而 except 又无法捕获的异常。
8.3 try-finally
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
{执行代码}
except:
{发生异常时执行的代码}
else:
{没有异常时执行的代码}
finally:
{不管有没有异常都会执行的代码}
finally块最大的作用:关闭对象并清理资源非常有用
例子:试图打开并写入不可写的文件,如下:
try:
f = open("demo.txt")
f.write("Lulu")
except:
print("Someting went wrong")
finally:
f.close()
8.4 raise
使用 raise块可以选择在条件发生时抛出异常。
例子:假如 x 小于 0,则引发异常并终止程序,如下:
x = -1
if x < 0:
raise Exception("x不能小于0。x的值为:{}".format(x))
上述代码运行结果如下:
Exception Traceback (most recent call last)
<ipython-input-9-e181ee05dac3> in <module>
1 x = -1
2 if x < 0:
----> 3 raise Exception("x不能小于0。x的值为:{}".format(x))
Exception: x不能小于0。x的值为:-1
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
8.5 异常小结
| 语句块 | 描述 |
|---|---|
| try | 执行代码 |
| except | 发生异常时执行的代码 |
| else | 没有异常时执行的代码 |
| finally | 不管有没有异常都会执行的代码 |
| raise | 选择在条件发生时抛出异常 |
9 导包
建立model1.py文件,如下:
class E01:
def method1(self):
print("package1的model1中的E01类的method1被调用")
def method2(self):
print("package1的model1中的E01类的method2被调用")
class E02:
def method5(self):
print("package1的model1中的E01类的method5被调用")
def method6(self):
print("package1的model1中的E01类的method6被调用")
分析:model1.py文件定义E01类和E02类,E01类里面有method1方法和method2方法。E01类里面有method5方法和method6方法。
建立model2.py文件,如下:
def method3():
print("package1的model2的method3被调用")
def method4():
print("package1的model2的method4被调用")
分析:定义method3方法和method4方法。
建立test.py文件,如下:
#直接导入包
import packeage1.model1 as m1
import packeage1.model2 as m2
if __name__ == '__main__':
m1.E01().method1()
m1.E01().method2()
m1.E02().method5()
m1.E02().method6()
m2.method3()
m2.method4()
分析:在test调用model1的method1,method2,method5和method6。调用model2的method3方法和method4方法。
或者导入具体的方法和类,如下:
导入方法和类
from packeage1.model2 import method3,method4
from packeage1.model1 import E01,E02
if __name__ == '__main__':
#导入具体方法和类
method3()
method4()
e1 = E01()
e1.method1()
e1.method2()
e2 = E02()
e2.method5()
e2.method6()
分析:导入model2的method3方法和method4方法,在main类中直接调用。导入model1的E01类和E02类,在main类中实例化类对象e1和e2,e1调用method1方法和method2方法,e2调用method5方法和method6方法。
小结
调用一个类中的方法,如果类中的方法只是部分要使用,使用导包方式调用。如果类中的方法是全部要使用,使用继承方式来调用。
10 OS模块
使用os模块找文件的路径
import os
class Test:
def read_csv(self,file_name):
result = []
with open(file_name,'r',encoding='utf8') as f:
obj = csv.reader(f)
for x in obj:
result.append(x)
return result
if __name__ == '__main__':
path = os.getcwd()
print(path)
result = Test().read_csv(path+'./data/12.csv')
print(result)
分析:os模块下的getcwd()方法获取执行文件的绝对路径。
例子:获取当前路径,如下:
path = os.path.abspath('.')
print(path)
例子:获取当前的父路径,如下:
path = os.path.abspath('..') # 获取当前的父路径
print(path)
其他路径表示方法,如下:
import csv
class Test:
def read_csv(self,file_name):
result = []
with open(file_name,'r',encoding='utf8') as f:
obj = csv.reader(f)
for x in obj:
result.append(x)
return result
if __name__ == '__main__':
#相对路径
# result = Test().read_csv('./data/12.csv')
#绝对路径,加上R或r,转义字符'\',不进行转义
# result = Test().read_csv(r'D:\Neusoft\test\PC workspace\packeage1\data\12.csv')
#绝对路径,'\\'表示'\'
# result = Test().read_csv('D:\\Neusoft\\test\\PC workspace\\packeage1\\data\\12.csv')
#绝对路径,使用斜杠'/'
result = Test().read_csv('D:/Neusoft/test/PC workspace/packeage1/data/12.csv')
print(result)
print(result[1][1])
分析:路径表示方法有相对路径和绝对路径。相对路径在用.表示上一级。绝对路径表示分/斜杠和 \反斜杠。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









