







文章目录
1 自动化测试概述
1.1 测试的目的
自动化测试目的提高工作效率
直接目的:找出软件中潜在的各种缺陷和错误。
商业目的:规避软件发布后由于各种潜在的软件缺陷和错误造成的隐患所带来的商业风险。
投入产出比要求:投入最少的人力、物力和时间,找到尽可能多的问题。
软件的第一版用手工测试,自动化测试是在回归测试(回归测试分部分回归测试和全部回归测试),软件比较稳定的情况下进行。
1.2 自动化测试的优点
对回归测试更方便。
测试具有一致性和可重复性,自动化的一个明显的好处是可以在较少的时间运行。
有效的利用人力物力资源,提高测试工作效率。
将繁琐的重复任务自动化,可以提高准确性和测试人员的积极性,提高手工测试的效率。
1.3 自动化测试的缺点
自动化测试是工具执行,没有思维,无法进行主观判断,对界面色彩、布局和系统的崩溃现象无法发现,这些错误通过人眼很容易发现。
自动化测试工具本身是一个产品,在不同的系统平台或硬件平台可能会受影响,在运行时可能影响被测程序的测试结果。
对于需求更改频繁的软件,测试脚本的维护和设计比较困难。
自动化测试是机器执行,发现的问题比手工测试要少很多,通过测试工具没有发现缺陷,并不能说明系统不存在缺陷,只能通过工具评判测试结果和预期效果之间的差距。
自动化测试要编写测试脚本,设计场景,这些对测试人员的要求比较高,测试的设计直接影响测试的结果。
1.4 自动化测试工具
自动化工具,有多重划分模式,其中:
从所支持的系统架构上,可以分为两大类:
支持C/S和B/S架构的uft;
只支持B/S架构的selenium。
注:
B/S结构(Browser/Server,浏览器/服务器模式),是WEB兴起后的一种网络结构模式,WEB浏览器是客户端最主要的应用软件。
C/S结构,即Client-Server(C/S)结构,通常采取两层结构。服务器负责数据的管理,客户机负责完成与用户的交互任务。
从收费模式上,划分为三大类:
商业的功能的自动化测试工具:uft(QTP)
开源的软件自动化测试工具:selenium
自主开发工具:测试开发岗位(涉及产品,测试,开发)
1.5 自动化测试流程
自动化测试流程,如下图:
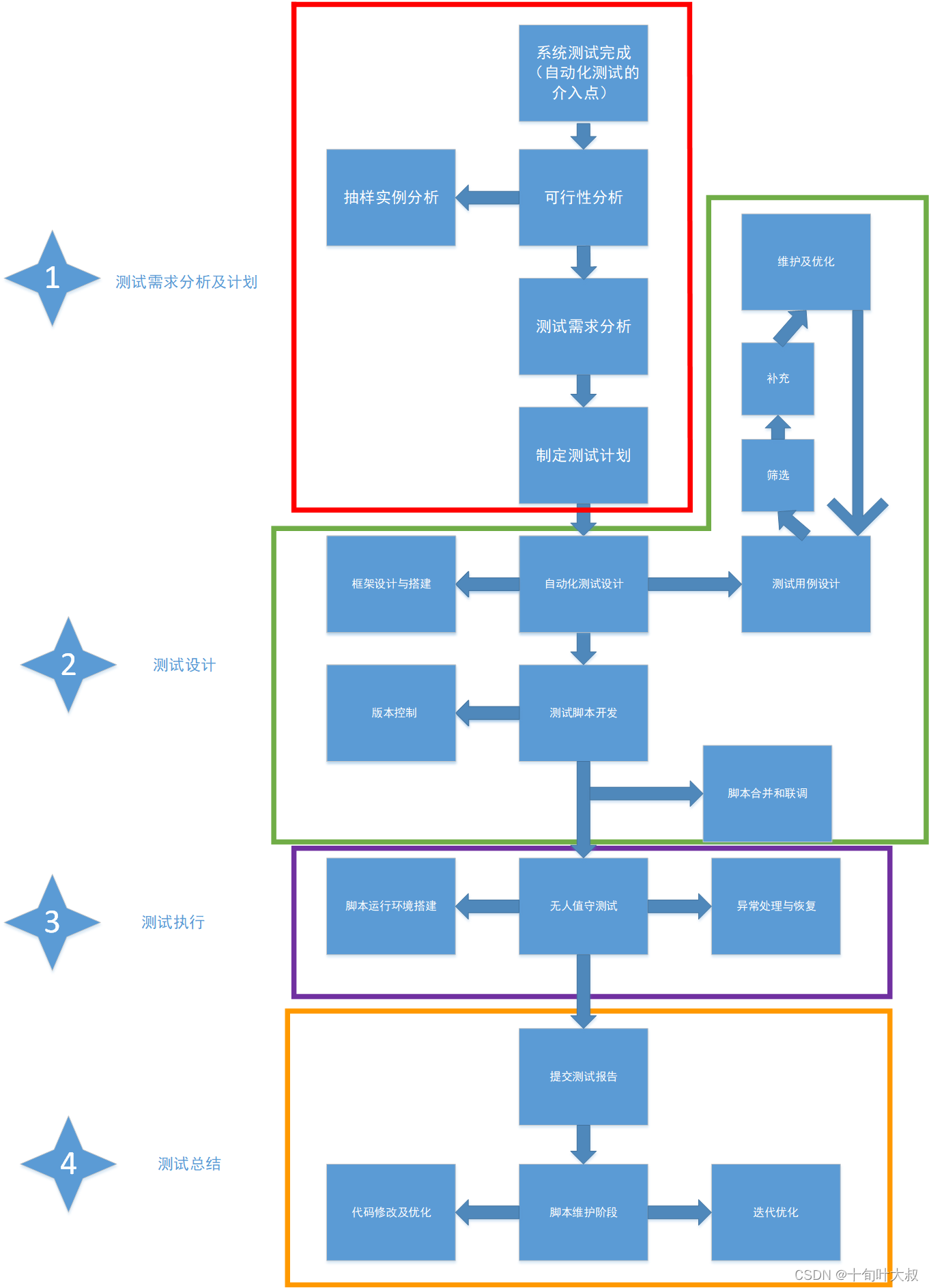
面–自动化测试流程
线-- python+selenium+unittes
点–python(数据类型,运算符、函数、类和对象、异常、IO、模块);selenium(api);unittes单元测试框架(测试用例的维护、执行和产出报告)
版本迭代越频繁,自动化测试效果越佳。
2 selenium基础
2.1 selenium的发展
Jason Huggins在2004年发起了Selenium项目,当时身处ThoughtWorks的他,为了不想让自己的时间浪费在无聊的重复性工作中而编写的JavaScript类库,这就是Selenium最早版本。
关于Selenium的命名比较有意思,当时QTP mercury (UFT)是主流的商业自化工具,是化学元素汞(俗称水银),而Selenium是开源自动化工具,是化学元素硒,硒可以对抗汞。
Selenium是一个验收测试工具,是一款基于Web应用程序的开源测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。它支持Firefox、IE、Chrome等众多浏览器,同时支持Java、C#、Ruby、Python、PHP、Perl、JS等众多主流语言。
2.2 selenium组成
selenlum 1.0:selenlum lDE、selenium rc、selenium grid
selenium 2.0:selenium IDE、selenium rc、webdriver、selenium grid
selenium 3.0:selenium lDE、webdriver、selenium grid
selenium IDE:UI用户界面的脚本录制工具(不用写脚本,应付功能测试),毕竟能够处理的逻辑有限,对于复杂的脚本处理起来很麻烦。除非刚入门、不会写代码,可以录制简单的脚本,或者可以使用其录制一个基本的脚本,然后去修改其逻辑,采用的关键字驱动的方式进行脚本开发的。selenium IDE是一个Firefox插件,可以让测试人员通过操作浏览器的操作来进行脚本的录制、回放功能。
selenlum rc:Selenium远程控制(RC)为第一代测试框架,它允许多个简单的浏览器动作和线性执行。它使用的编程语言,如Java,C#,PHP,Python和Ruby和Perl的强大功能来创建更复杂的测试。
webdriver:包(各种模块),对浏览器的api(对浏览器中元素或者浏览器的操作)。
问:为什么selenlum rc被webdriver代替呢?
答:主要是webdriver对浏览器的调度效率提高了好多。
selenium grid:利用grid可以在不同的主机上建立主节点(hub)和分支节点(node),可以使主节点上的测试用例在不同的分支节点上运行;对于不同的节点来说,可以搭建不同的测试环境(操作系统、浏览器),从而使得一份测试用例得到不同环境下的测试执行结果。
2.2.1 selenium IDE工具的使用
(1)在firefox安装selenium IDE
ctrl+shift+A,打开“扩展和主题”功能,进入到了附加组件管理器页面,在页面的搜索框输入“selenium IDE”,点击安装即可,最后在工具栏出现selenium的图标,如下:
(2)了解selenium IDE工具有哪些功能

Record a new test in a new project
录制一个新的测试在新的工程中(自动化测试的项目作为工程,一个具体的功能可以作为一个测试用例)
Open an existing project
打开一个已经存在的工程
Create a new project
创建一个新的工程
Close Selenium IDE
关闭selenium IDE
(3)脚本录制
测试脚本是以关键字驱动
target:对谁进行操作?使用属性进行定位
command:找到之后,你要对target做什么操作?如:键入数据
value:键入什么数据?
下面以打开百度页面,输入“selenium”,点击【百度一下】按钮。
第一步,录制并新建项目baidu
点击Record a new test in a new project ,如下图:

第二步,输入baidu,点击ok,如下图:

第三步,输入https://www.baidu.com,点击start recording,开始录制,录制结果如下:

点击停止按钮,即完成录制!
(4)添加描述
对第一个添加,如下图:

target为/表示根地址,即https://www.baidu.com
对第二个添加,如下图:

对第三个添加,如下图:

怎么知道id呢?打开百度页面,查看源码,如下图:

对第四个添加,如下图:

如何知道id=su?打开百度页面,查看源码,如下图:

(5)回放录制脚本
再次run一遍,点击播放按钮,如下图:

到此该用例完成并成功通过,如下图:

如何知道脚本是否满足预期呢?
写断言,断言的作用就是判断实际结果和预期结果是否一致。
断言要求,不需要多,一个就够,只要能够唯一确定你的脚本是通过的即可。
(6)写断言
command为assert value
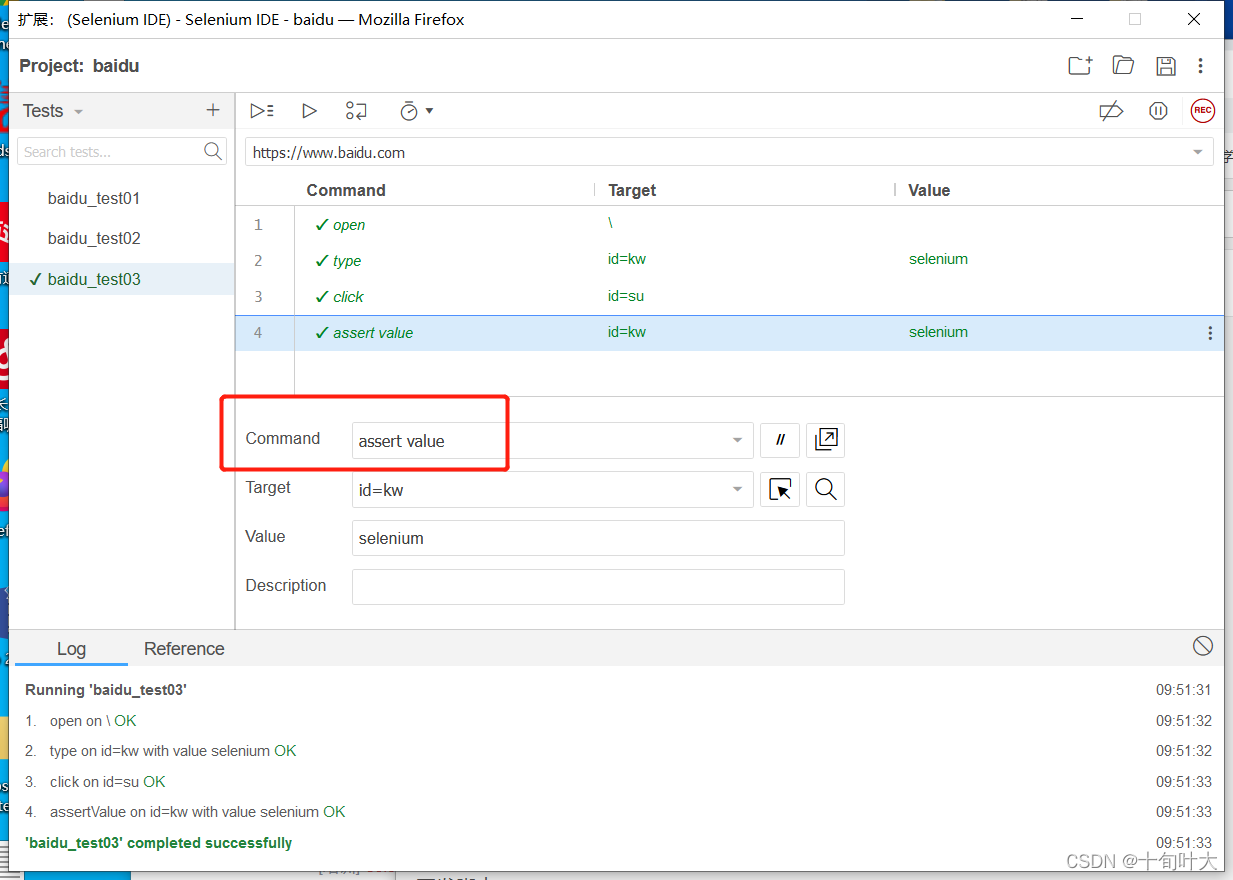
点击运行按钮,查看日志,看所有步骤是否ok,断言是否ok,是否出现最终的结果“baidu_test01 completed successfully”。如果都可以,则该脚本运行通过。
command为assert txt时,如下图:
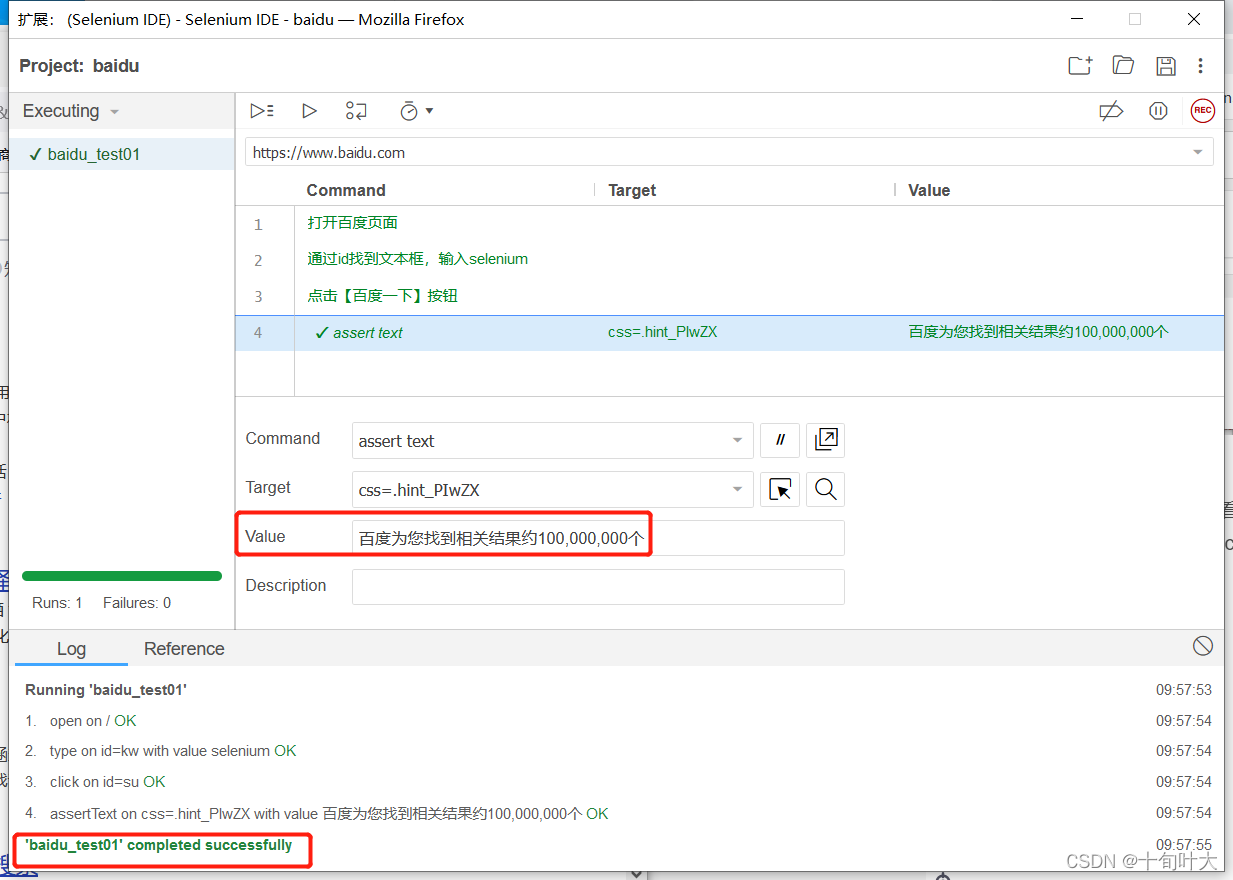
打开页面,找到定位,即可判断搜索成功,如下图:
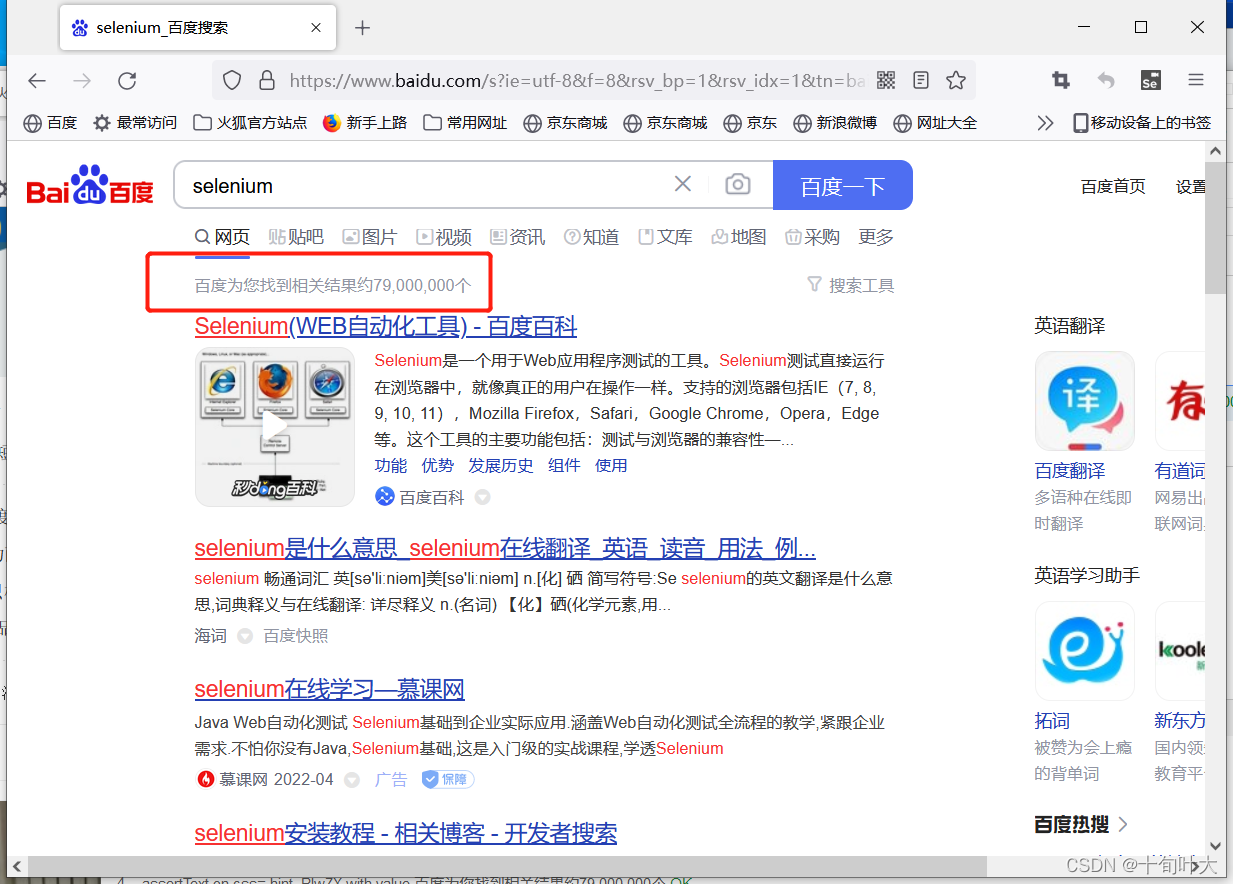
(7)导出功能
第一步,选中脚本,右键,选择export,如下图:
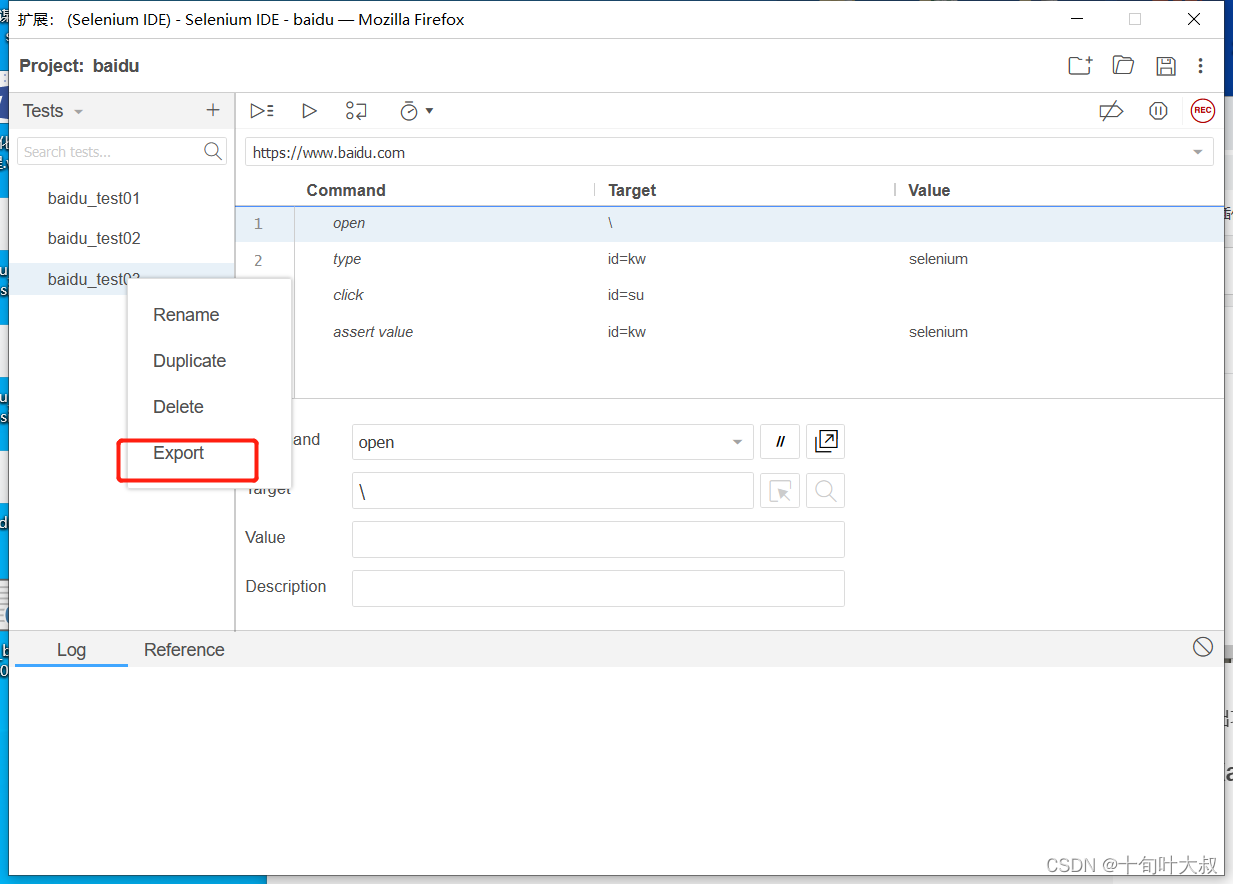
第二步,选择导出的语言,选择“将步骤描述作为单独的注释”,如下图:
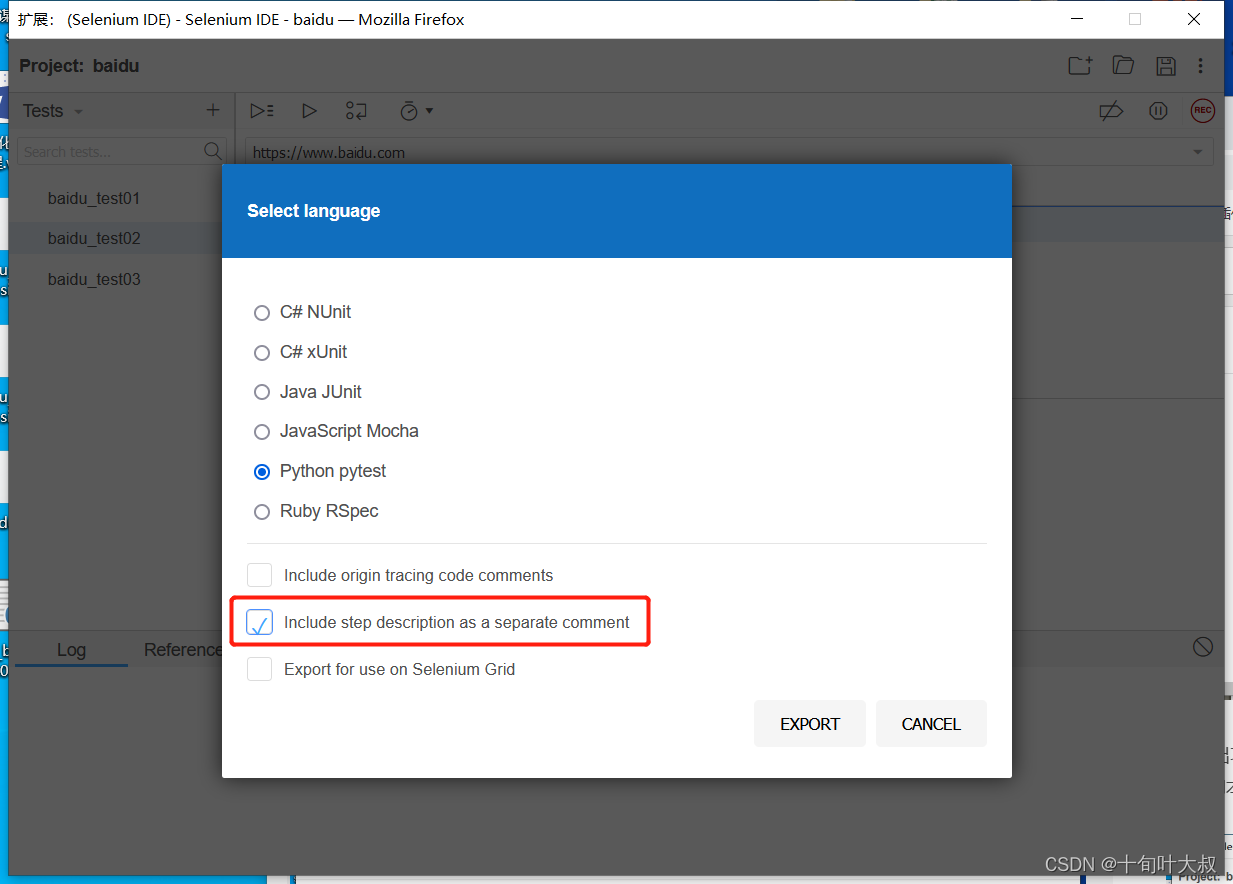
第三步,导出有py格式的文件和py.part格式文件,如下图:
最后,查看py格式的文件,如下:
# Generated by Selenium IDE
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class TestBaidutest02():
def setup_method(self, method):
self.driver = webdriver.Firefox()
self.vars = {}
def teardown_method(self, method):
self.driver.quit()
def test_baidutest02(self):
self.driver.get("https://www.baidu.com/")
self.driver.find_element(By.ID, "kw").send_keys("selenium")
self.driver.find_element(By.ID, "su").click()
self.driver.close()
2.2.2 selenium webdriver环境搭建
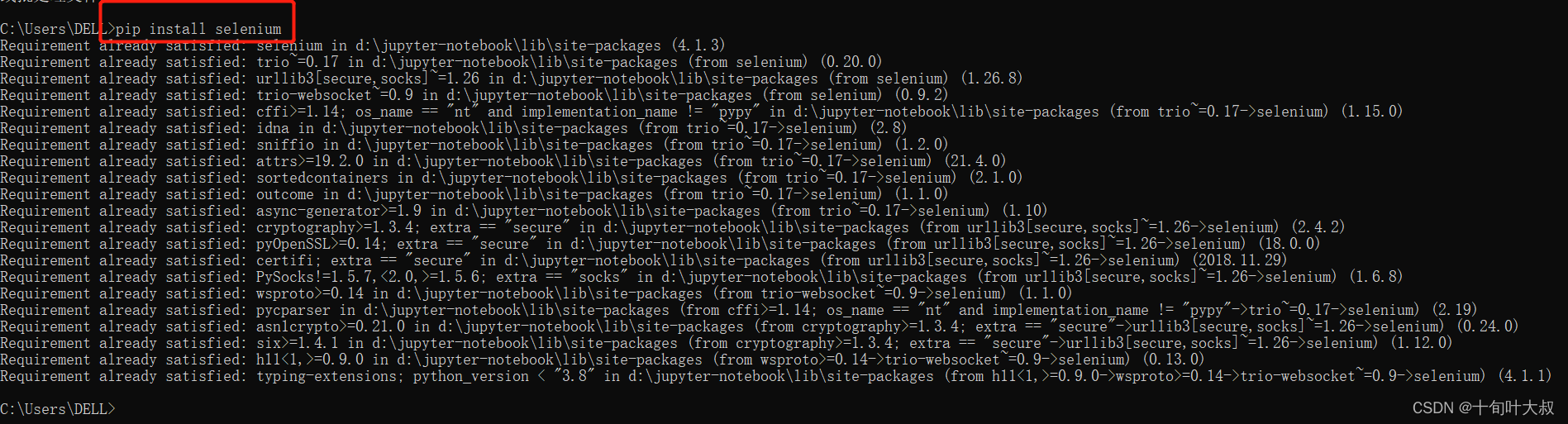
(1)安装selenium
输入命令,pip install selenium,如下图:
(2)安装驱动到python目录下,如下图:
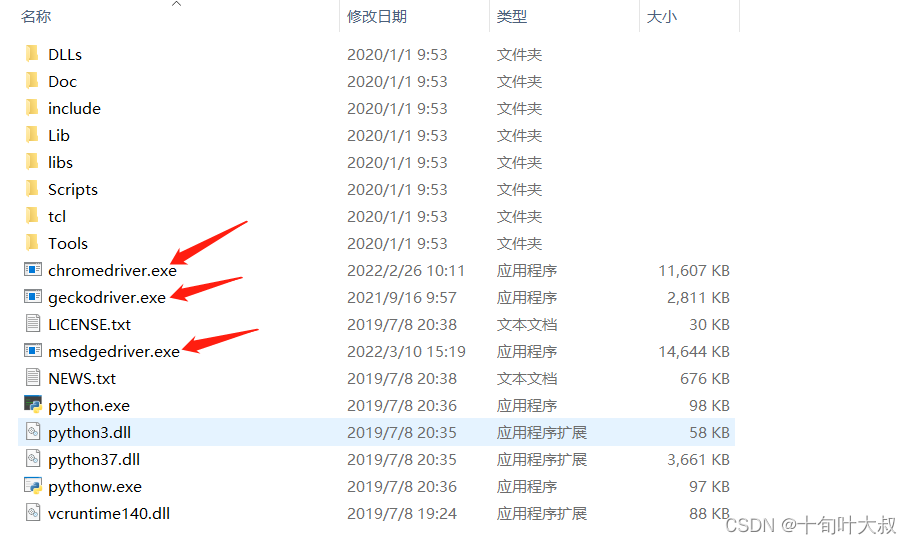
分别对应chrome浏览器、firefox浏览器和IE浏览器。
(3)编写test01.py,如下图:
#导包
from selenium import webdriver
#创建对象
driver = webdriver.Chrome()
#打开百度页面
driver.get("https://www.baidu.com")
#往文本框输入
driver.find_element_by_id("kw").send_keys("selenium")
#点击【百度一下】按钮
driver.find_element_by_id("su").click()
# driver.close()
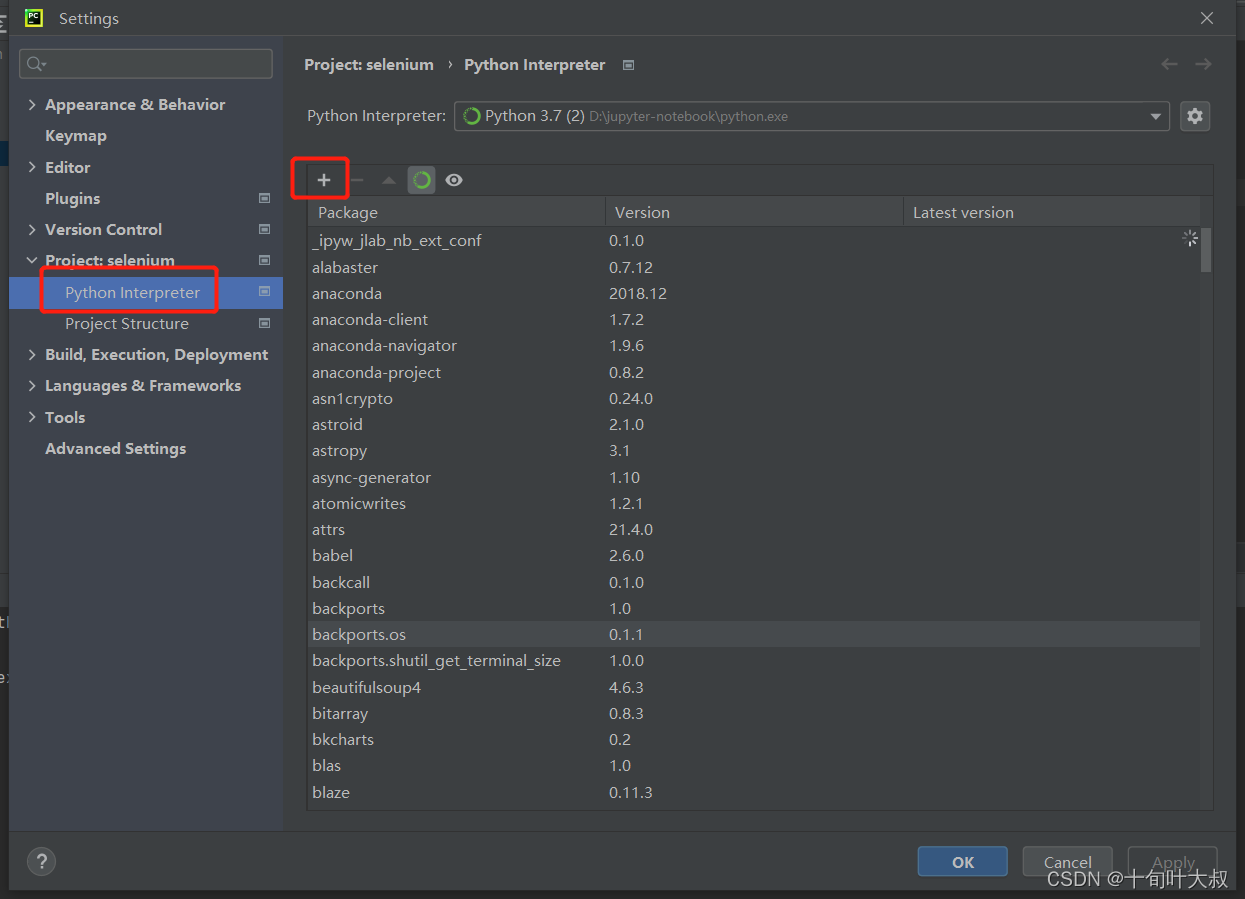
注:在Pycharm编辑器中把环境调成Anaconda不用添加添加驱动,但是需要手动添加selenium包,如下图:
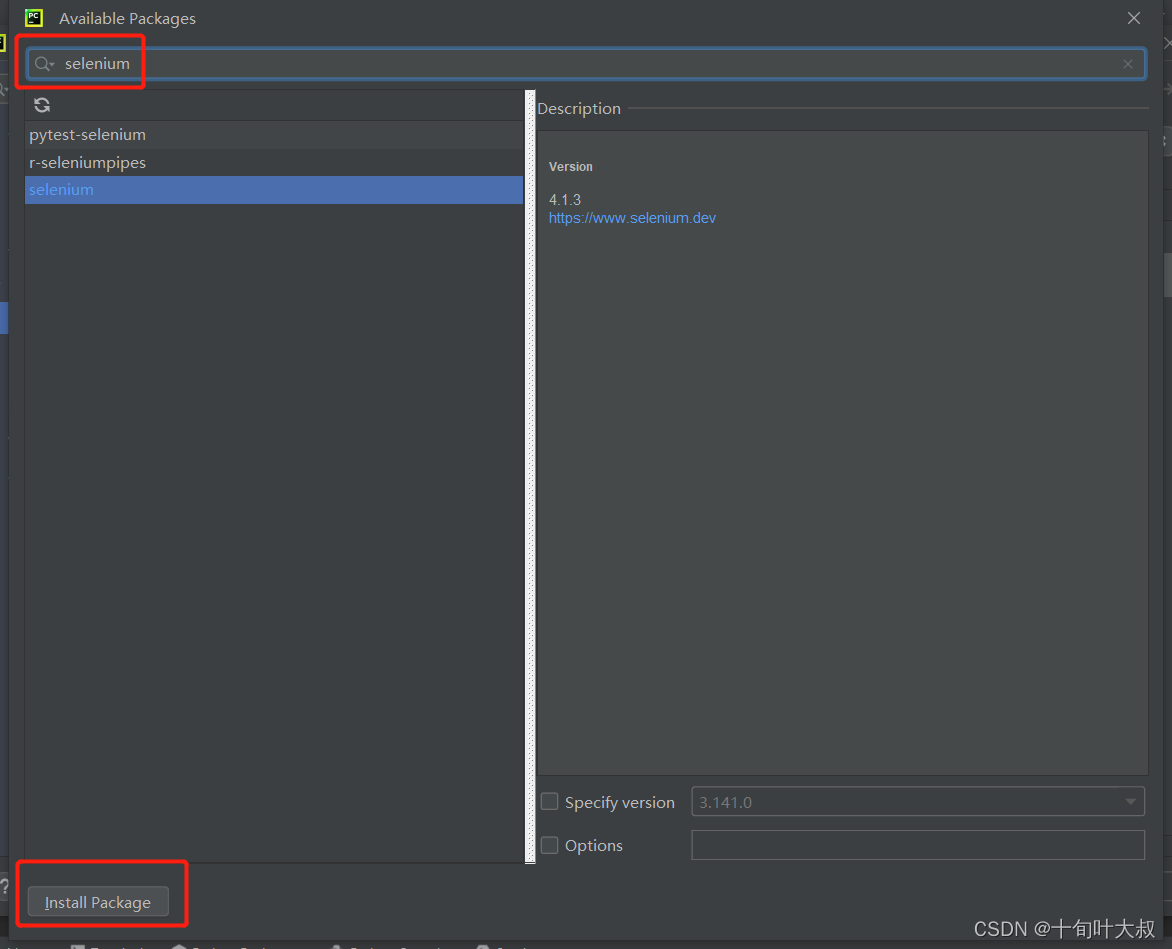
搜索selenium包,如下图:
什么是Anaconda?
Anaconda,中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等。
2.2.3 Katalon工具
Katalon工具比selenium IDE工具更强大。
(1)安装katalon并打开katalon

(2)编写脚本并运行脚本
test suites为存放测试脚本的文件夹
创建baidu_test05_katalon文件夹和baidu_tes05脚本文件,并编写脚本文件,如下图:
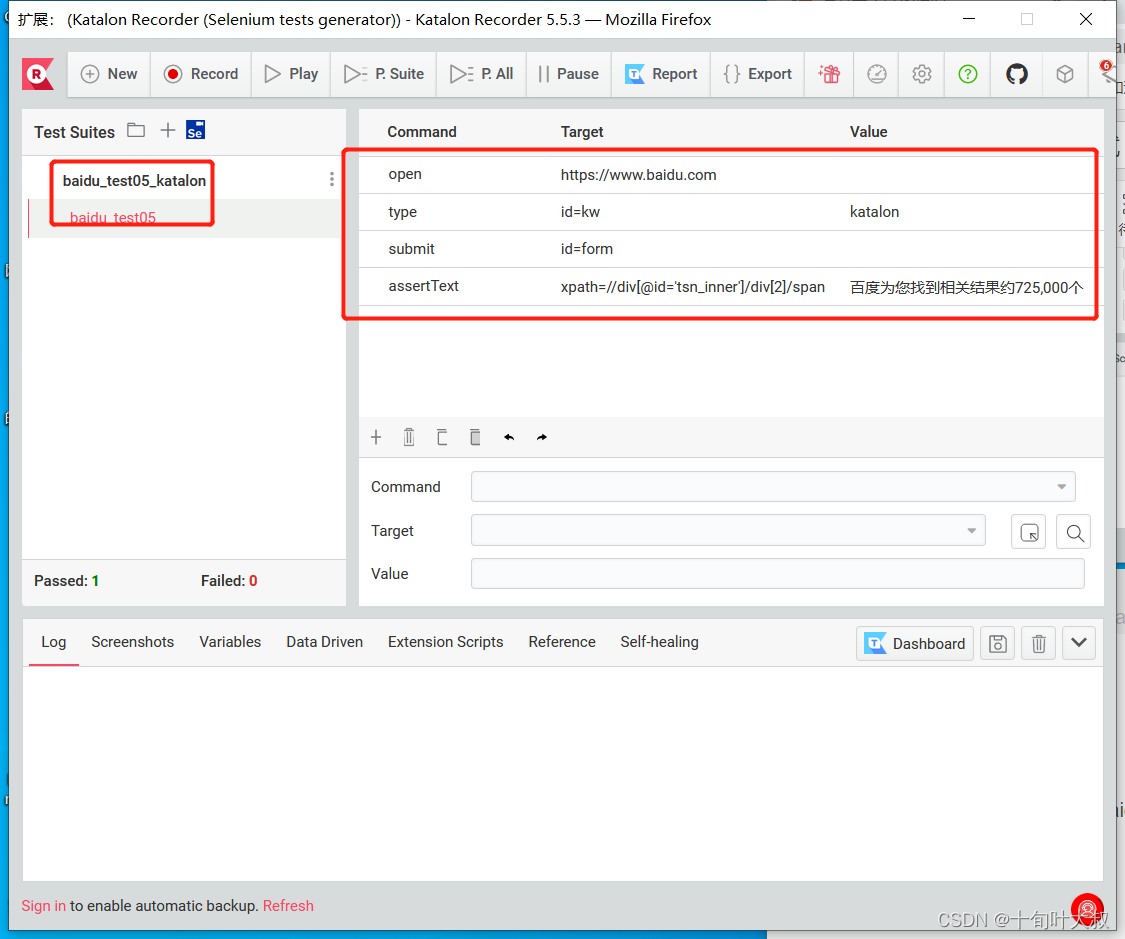
运行脚本,如下图:
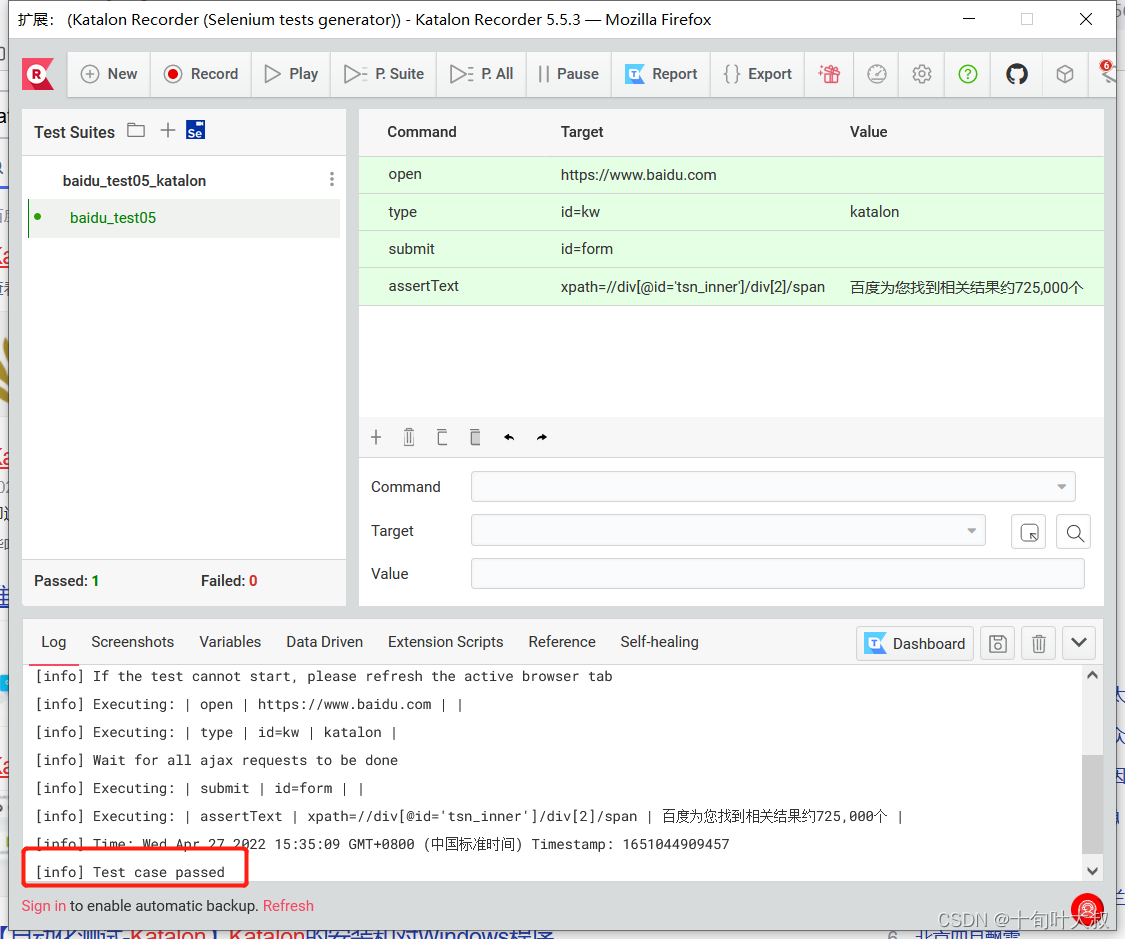 运行成功!
运行成功!
(3)导出该脚本的代码
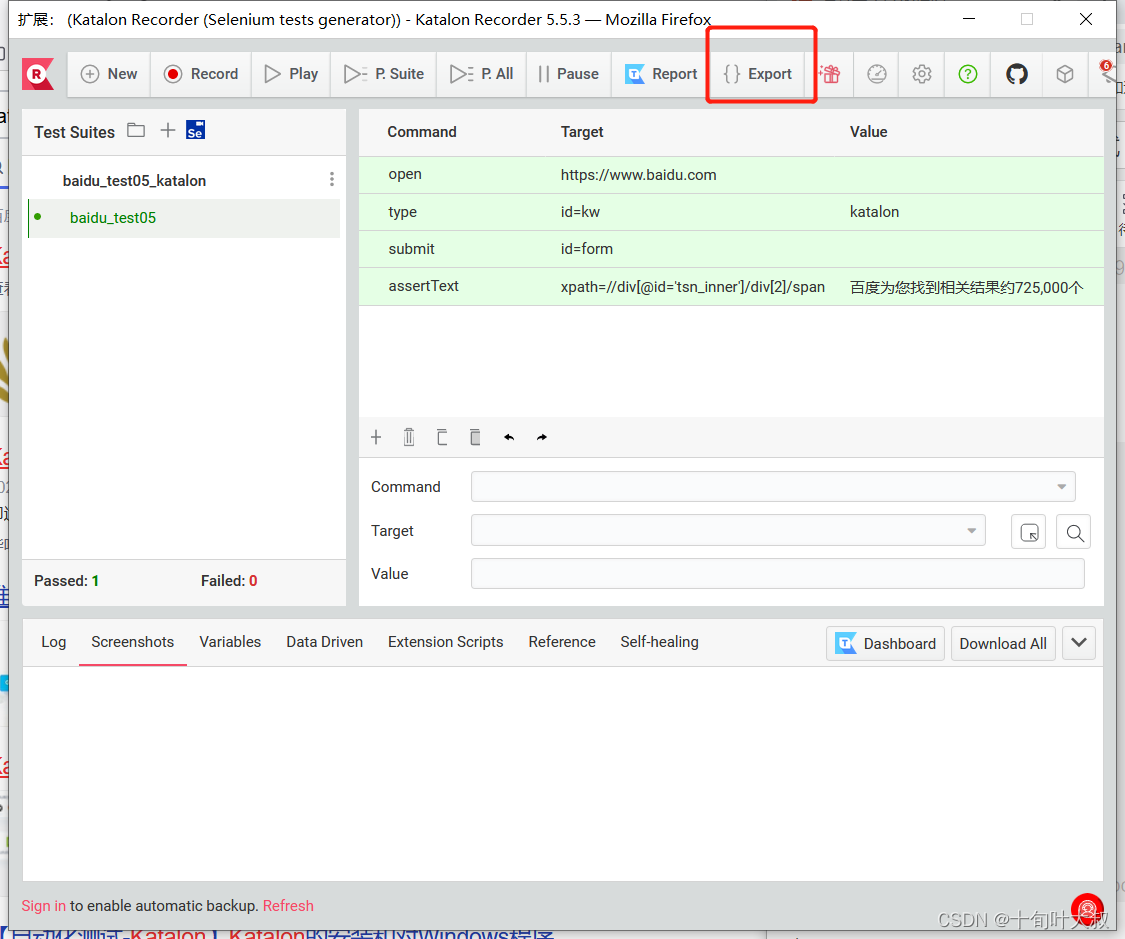
选择语言,如下图:
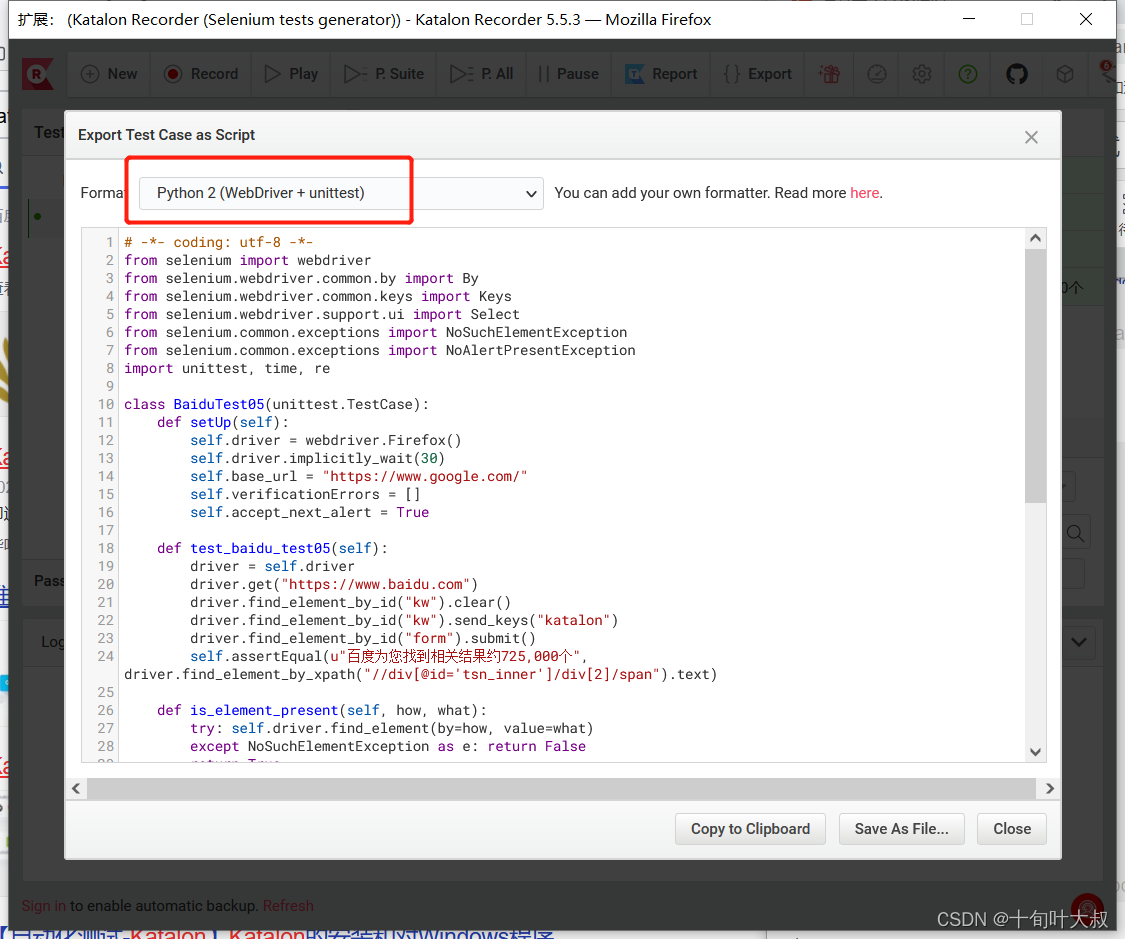
导出成功如下图:
查看代码,如下:
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
class BaiduTest05(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "https://www.google.com/"
self.verificationErrors = []
self.accept_next_alert = True
def test_baidu_test05(self):
driver = self.driver
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("katalon")
driver.find_element_by_id("form").submit()
self.assertEqual(u"百度为您找到相关结果约725,000个", driver.find_element_by_xpath("//div[@id='tsn_inner']/div[2]/span").text)
def is_element_present(self, how, what):
try: self.driver.find_element(by=how, value=what)
except NoSuchElementException as e: return False
return True
def is_alert_present(self):
try: self.driver.switch_to_alert()
except NoAlertPresentException as e: return False
return True
def close_alert_and_get_its_text(self):
try:
alert = self.driver.switch_to_alert()
alert_text = alert.text
if self.accept_next_alert:
alert.accept()
else:
alert.dismiss()
return alert_text
finally: self.accept_next_alert = True
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
unittest.main()
以后写自动化测试代码,上面就是最好的模板!
2.2.4 webdriver API
通过前端工具可以查看页面HTML源码,通过页面源码可以看到页面上的元素都是由一行行的代码组成的,它们之间有层级的组织起来,每个元素有不同的标签名和属性值。WebDriver就是通过这些信息找到不同元素的。
自动化测试的主要步骤:
1.通过某些方式定位到我们要执行的对象(Target)
2.对这个对象进行怎样的操作(command)
3.通过操作对对象赋值(value)
4.添加断言操作
(1)页面元素定位和操作
页面元素:在浏览器中显示的所有要素,如文本框、按钮、图片、表单、表格、视频……
webdriver提供了八种元素定位方法,以下是各种定位方法及其对应的Python方法,如下表:
| Webdriver元素定位方式 | 对应Python方法 |
|---|---|
| id | find_element_by_id(“id属性值”) |
| name | find_element_by_name() |
| class name | find_element_by_class_name() |
| xpath | find_element_by_xpath() |
| tag name | find_element_by_tag_name() |
| link text | find_element_by_link_text(“链接的显示文本”) |
| partial link text | find_element_by_ partial_link_text(“链接的显示的部分文本”) |
| css selector | find_element_ by_css_selector() |
使用id属性定位
html规定id属性在html文档中必须是唯一的,具有唯一性。WebDriver提供id定位方法:find_element_by_id()。
要求:在百度文本框输入selenium,再点击【百度一下】按钮。使用id属性定位。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
driver.quit()
分析以上代码:
使用id属性定位:1 确定要操作的对象 2获取id属性 3 对该对象操作
总结步骤:
1 导包,创建浏览器对象,获取百度一下页面url地址
2 使用id属性定位
3 对该对象操作
通过name属性来定位
html规定name来指定元素名称,name属性在页面中不唯一,通过name属性来定位。WebDriver提供name定位方法:find_element_by_name()。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_name("wd").send_keys("selenium")
driver.find_element_by_id("su").click()
分析上述代码:
通过name属性找到百度页面的文本框。
【百度一下】按钮没有name属性,还是使用id属性进行定位。
class名定位
html规定class来指定元素的类名,通过class属性来定位。WebDriver提供name定位方法:find_element_by_class_name()。(少用,class属性不唯一)
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_class_name("s_ipt").send_keys("selenium")
driver.find_element_by_class_name("btn self-btn bg s_btn").click()#报错
运行结果如下图:

找不到【百度一下】按钮。
可以使用find_elements_by_class_name()返回所有的选项,返回类型是一个列表,通过click()方法实现多选效果。
使用链接的内容来定位
使用find_element_by_link_text()定位元素,定位超链接,以超链接的文本内容为参数内容,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_link_text("新闻").click()
time.sleep(2)
driver.quit()
使用xpath定位
理想状态下,在一个页面中每一个元素都有唯一的id和name属性值,我们可以通过他们的属性值找到它们。但是,实际项目中并非如此,有时候一个元素并没有属性,或者页面上有多个id元素和name属性值相同,又或者每一次刷新页面,id属性值都会随机变化,这些情况下,我们如何定位元素呢?
答:使用xpath定位或css定位。
Xpath是一种在XML (HTML)文档中定位元素的语言。因为HTML可以看作XML的一种实现,所以Selenium用户可以使用这种强大的语言在Web应用中定位元素。
Xpath可以分为以下几种定位方法:
绝对路径定位;
元素属性定位;
利用父子关系以及属性定位;
元素属性定位配合逻辑运算符。
使用元素属性定位,在百度页面文本框输入“selenium”,并点击【百度一下】按钮,代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_xpath("//input[@id='kw']").send_keys("selenium")
time.sleep(3)
driver.find_element_by_xpath("//input[@id='su']").click()
time.sleep(3)
driver.quit()
分析上述代码:
//表示相对路径,页面中有多个input元素,再填充id属性值,定位到百度文本框的位置。input也可以改为*通配符。
利用父子关系以及元素属性定位,在百度页面文本框输入“selenium”,并点击【百度一下】按钮,代码如下:
driver.find_element_by_xpath("//form[@id='form']/span/input").send_keys("selenium")
time.sleep(2)
driver.find_element_by_xpath("//form[@id='form']/span[2]/input").click()
time.sleep(2)
driver.quit()
分析上述代码:先找到form元素同时找出form元素的id属性值,往下找到span元素,最后找到input元素,即百度页面文本框。
元素属性定位配合逻辑运算符,在百度页面文本框输入“selenium”,并点击【百度一下】按钮,代码如下:
driver.find_element_by_xpath("//input[@id='kw' and @name='wd']").send_keys("selenium")
time.sleep(2)
driver.find_element_by_xpath("//input[@id='su']").click()
time.sleep(2)
driver.quit()
分析上述代码:在使用元素属性定位的基础上,添加name属性值。
使用css定位
| 选择器 | 例子 | 描述 |
|---|---|---|
| .class | .su | class选择器,选择class="su"的所有元素 |
| #id | #form | id选择器,选择id="form"的所有元素 |
| element > element | form > span | 选择父元素为<form>下的所有<span>元素 |
使用css的类选择定位百度文本框,id属性定位【百度一下】按钮,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_css_selector(".s_ipt").send_keys("selenium")
time.sleep(2)
driver.find_element_by_id("su").click()
time.sleep(2)
driver.quit()
分析上述代码:
使用css定位的类选择器进行定位。class选择器用.表示。
使用css中id选择器定位百度页面的文本框,如下:
driver.find_element_by_css_selector("#kw").send_keys("selenium")
time.sleep(2)
driver.find_element_by_css_selector("#su").click()
time.sleep(2)
driver.quit()
分析上述代码:
使用webdriver中的find_element_by_css_selector()方法,注意不是find_elements_by_css_selector()方法。id选择器用#表示。
使用css的父子继承关系定位文本框和【百度一下】按钮,如下:
driver.find_element_by_css_selector("form > span > input").send_keys("selenium")
time.sleep(2)
driver.find_element_by_css_selector("form > span > input#su").click()
time.sleep(2)
driver.quit()
分析上述代码:
使用父子继承关系定位的同时可以使用css的id选择器配合使用。
定位元素小结
8种方法定位元素如下图:

重点掌握id、name、link_text、xpath、css_selector。
定位只是第一步,定位之后需要对这个元素进行操作,或单击(按钮)或输入(输入框)。
以下是webdriver中最常用的几个方法:
| 方法 | 描述 |
|---|---|
| clear() | 清除文本 |
| send_keys(value) | 模拟按键输入 |
| click() | 单击元素,例如按钮操作 |
| current_url | 返回当前页面的url地址。常用在断言。 |
| title | 返回当前页面的title。常用在断言。 |
| text | 获取页面(提示框、警告框)。常用在断言。 |
| get_attribute(name) | 获得属性值,文本框中的值使用value属性名。常用在断言。 |
| is_displayed() | 设置该元素是否用户可见 |
| is_enabled() | 判断是否可用 |
| is_selected() | 判断是否选中,一般用于复选框或者单选框的判断 |
在百度页面文本框输入“seleniummmm”,输入有误,清空输入内容,输入“selenium”,点击【百度一下】按钮,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_css_selector(".s_ipt").send_keys("seleniummmm")
time.sleep(2)
driver.find_element_by_css_selector(".s_ipt").clear()
time.sleep(2)
driver.find_element_by_css_selector(".s_ipt").send_keys("selenium")
time.sleep(2)
driver.find_element_by_css_selector("#su").click()
time.sleep(2)
driver.quit()
分析上述代码:
使用css的id选择器定位百度页面的文本框,css的id选择器定位【百度一下】按钮。在文本框输入“seleniummmm”,输入有误,使用clear()清空,然后再文本框输入“selenium”,最后点击【百度一下】按钮。
获取百度页面的url地址,以此作为断言,判断获取到的url地址是否与百度页面url地址一致,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
time.sleep(2)
# 返回当前页面的url地址
url = driver.current_url
print(url)
time.sleep(2)
if url == "https://www.baidu.com/":
print("跳转成功")
else:
print("跳转失败")
driver.quit()
分析上述代码:
打开百度页面,利用current_url获取百度页面的url地址,判断是否跳转成功。
利用百度页面的链接文本判断是否成功打开百度页面,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 使用text操作
word = driver.find_element_by_link_text("关于百度").text
print(word)
time.sleep(2)
driver.quit()
分析上述代码:
打开百度页面,定位百度页面底部的链接“关于百度”,获取链接“关于百度”的文本内容。
获取在百度页面文本框的输入内容,获取【百度一下】按钮的class属性值和value值,如下:
# 获取百度文本框的name属性值
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium")
time.sleep(2)
value1 = driver.find_element_by_id("kw").get_attribute("value")
value2 = driver.find_element_by_id("su").get_attribute("class")
value3 = driver.find_element_by_id("su").get_attribute("value")
print(value1)
print(value2)
print(value3)
driver.quit()
分析上述代码:
打开百度页面,在文本框输入“selnium”,先定位百度文本框,然后通过get_attribute()获取输入文本框的内容。利用id定位【百度一下】按钮,使用get_attribute()获取按钮的class值和value值。
判断【百度一下】按钮是否显示成功,如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 判断【百度一下】按钮是否显示出来了
if driver.find_element_by_id("su").is_displayed():
print("显示了【百度一下】按钮")
else:
print("没有显示了【百度一下】按钮")
driver.quit()
分析上述代码:
打开百度页面,使用id定位到按钮,添加断言,采用is_displayed()判断是否成功打开百度页面。
元素操作小结
元素操作经常作为断言。

(2)浏览器操作
webdriver提供了调整浏览器的大小、操作浏览器前进和后退、刷新浏览器等。
| 方法 | 描述 |
|---|---|
| set_window_size(width,heigh) | 控制浏览器窗口大小 |
| maximize_window() | 最大化浏览器窗口 |
| minimize_window() | 最小化浏览器窗口 |
| back(),forward() | 控制浏览器后退和前进 |
| refresh() | 模拟浏览器刷新 |
| save_screenshot() | 截屏操作 |
| close() | 关闭单页页面 |
| quit() | 关闭所有页面 |
将百度页面窗口最小化,最大化,调成1080*600的窗口,如下:
# 调整窗口大小
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 最小化窗口
driver.minimize_window()
time.sleep(2)
driver.find_element_by_id("kw").send_keys("selenium")
# 最大化窗口
driver.maximize_window()
time.sleep(2)
# 将窗口调整为1080*600
driver.set_window_size(1080,600)
time.sleep(2)
driver.quit()
分析上述代码:
窗口最小化之后依然可以输入内容并进行操作。
点击新闻超链接,进入百度新闻页面,回退到百度页面,再前进到百度新闻页面,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_link_text("新闻").click()
time.sleep(3)
# 后退到百度页面
driver.back()
time.sleep(3)
# 前进到百度新闻页面
driver.forward()
time.sleep(3)
driver.quit()
分析上述代码:
涉及到重要问题:句柄。
刷新百度页面,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
time.sleep(2)
driver.refresh()
time.sleep(2)
driver.quit()
分析上述代码:
refresh()刷新当前页面。
截百度页面的图,存放在D盘中,命名为“abcd123.png”,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
time.sleep(2)
driver.save_screenshot(r"d:/abcd123.png")
driver.quit()
分析上述代码:
save_screenshot()截取当前页面。
此外还有其他截屏的方法,如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
time.sleep(2)
driver.find_element_by_link_text("新闻").click()
driver.get_screenshot_as_file("{}.{}".format("d:/123","png"))
time.sleep(2)
driver.quit()
分析上述代码:
format()格式灵活,以参数的形式传入。get_screenshot_as_file()从功能上来说,与save_screenshot()一样。
存在问题:无法截百度新闻页面,只是截百度页面,因为页面句柄在百度页面,没有在百度新闻页面。
截图的方法:
1 get_screenshot_as_file("{}.{}".format("pwd","model"))
2 save_screenshot("pwd")
3 get_screenshot_as_file("pwd")
句柄知识
要求:打开百度页面,从百度页面进入百度新闻页面,在百度新闻页面点击帮助链接,帮助页面在当前页面跳转,帮助页面退回到百度新闻页面。
代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 获取百度页面的handle
# handle1 = driver.current_window_handle
# print(handle1)
# 打开百度新闻页面
driver.find_element_by_link_text("新闻").click()
time.sleep(2)
# 获取所有句柄值
handles = driver.window_handles
print(handles)
# 将句柄绑定在百度新闻页面上
driver.switch_to.window(handles[1])
# 在百度新闻页面中跳转到百度新闻帮助页面
driver.find_element_by_link_text("帮助").click()
time.sleep(2)
#回退到百度新闻页面
driver.back()
time.sleep(2)
# 关闭当前页面,即driver对象绑定的句柄页面
driver.close()
# driver.quit()
分析上述代码:
没有将句柄绑定在百度新闻页面,将无法跳转到帮助页面。因为句柄一直在百度页面,而百度页面中没有帮助页面,就一定会报错。所以需要把句柄绑定在百度新闻页面中。
current_window_handle获取当前句柄。
window_handles获取所有句柄,返回的是一个列表。
switch_to.window(window_name)window_name为句柄,将句柄绑定给driver对象,如:driver.switch_to.window(handles[1])
浏览器操作小结
重点是句柄,driver对象绑定在哪个句柄。

(3)鼠标操作
click()是模拟鼠标的单击操作,此外还有鼠标右击、双击、悬停、拖动等功能。在Webdriver中,这些方法封装在ActionChains类中,需要导入。导入代码如下:
from selenium.webdriver.common.action_chains import ActionChains
导包路径如下图:
常见的方法如下表:
| 方法 | 描述 |
|---|---|
| perform() | 执行所有ActionChains中存储的行为 |
| context_click() | 右击 |
| double_click() | 双击 |
| drag_and_drop() | 拖动 |
| move_to_element() | 鼠标悬停 |
鼠标悬停在百度首页页面的“设置”上,然后右键百度页面的搜索文本框,代码如下:
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
time.sleep(3)
# 定位“设置”
set_link = driver.find_element_by_xpath('//*[@id="s-usersetting-top"]')
#将对设置的操作封装到ActionChains,利用perform()存储该操作
ActionChains(driver).move_to_element(set_link).perform()
time.sleep(5)
# 定位百度页面的搜索文本框
text = driver.find_element_by_id("kw")
# 将对文本框右键操作封装到ActionChains中,利用perform()存储该操作
ActionChains(driver).context_click(text).perform()
time.sleep(3)
driver.quit()
分析上述代码:
导入ActionChains包。定位到“设置”,将对设置的操作封装到ActionChains,利用perform()存储该操作。定位百度页面的搜索文本框,将对文本框右键操作封装到ActionChains中,利用perform()存储该操作。
鼠标操作小结

(4)键盘操作
Keys类提供了所有键盘的方法。send_keys()方法可以用来模拟键盘输入。此外,还可以输入键盘上的按键,还可以是组合键,如ctrl+A,ctrl+C等,需要导入包,代码如下:
from selenium.webdriver.common.keys import Keys
相关包的路径如下图:
| 方法 | 描述 |
|---|---|
| send_keys(Keys.BACK_SPACE) | 删除键 |
| send_keys(Keys.SPACE) | 空格键 |
| send_keys(Keys.TAB) | 制表键 |
| send_keys(Keys.ESCAPE) | esc键 |
| send_keys(Keys.ENTER) | 回车键 |
| send_keys(Keys.CONTROL,‘a’) | 全选 |
| send_keys(Keys.CONTROL,‘c’) | 复制 |
| send_keys(Keys.CONTROL,‘x’) | 剪切 |
| send_keys(Keys.CONTROL,‘v’) | 粘贴 |
要求:在百度页面文本框输入“seleniumm”,删除末尾的“m”,在文本框追加“ 教程”,全选文本框的内容,剪切文本框的内容,将剪切的内容复制到文本框,用回车按键搜索,代码如下:
from selenium import webdriver
import time
import time
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 在百度页面文本框输入selenium
driver.find_element_by_id("kw").send_keys("seleniumm")
time.sleep(2)
# 删除末尾的m
driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
time.sleep(2)
#在文本框添加“ 教程”
driver.find_element_by_id("kw").send_keys(" 教程")
time.sleep(3)
# 全选文本框的内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,"a")
time.sleep(3)
# 剪切
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,"x")
time.sleep(3)
# 粘贴
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,"v")
time.sleep(3)
# 按下回车键
driver.find_element_by_id("kw").send_keys(Keys.ENTER)
time.sleep(3)
driver.quit()
分析上述代码:
利用send_keys()方法可以用来模拟键盘输入。
键盘操作小结

(5)警告窗口处理
处理JavaScript生成的alert、confirm和prompt操作。
用法:switch_to.alert
将driver对象的控制权转交到警告框上。
警告窗口处理方法如下表:
| 方法 | 描述 |
|---|---|
| text | 获取alert/confirm/prompt中的文字 |
| accept() | 接受现有警告框 |
| dismiss() | 放弃现有警告框 |
| send_keys(keystosend) | 发送文本到警告框 |
模式窗体
模式窗体也可称为模态窗口,即用户必须在完成该窗体上的操作或关闭窗体后才能返回打开此窗体外的窗体。也就是说,在模式窗体下,如果我们想对其他窗体进行操作,必须要先完成该模式窗体相对应的操作。我们经常使用到的一种模式窗体是msgbox(警示框),警示框中一般会有两个基本按钮,一个“确定”按钮用来提交,另一个“取消”按钮用来撤销提交,强迫用户完成该窗体上的相对应的操作,才可以切换到其他界面。
非模式窗体
不用关闭该窗体,就可以对其他窗体进行操作,可以在窗体间任意的切换。
显然,警告框属于模式窗体。
要求:打开百度首页,鼠标悬浮在“设置”上,点击搜索设置,然后选中每页20条单选框,点击【保存设置】按钮,代码如下:
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
time.sleep(2)
# set = driver.find_element_by_link_text("设置")
# 定位“设置”的位置
set = driver.find_element_by_xpath('//*[@id="s-usersetting-top"]')
# 鼠标悬浮在“设置”上
ActionChains(driver).move_to_element(set).perform()
# 点击“搜索设置”
driver.find_element_by_link_text("搜索设置").click()
time.sleep(3)
# 点击单选框,每页20条
driver.find_element_by_xpath('//*[@id="nr_2"]').click()
time.sleep(2)
# 点击【保存设置】按钮
driver.find_element_by_link_text("保存设置").click()
time.sleep(2)
# driver对象控制权转交到警告框上
alertbox_contorl = driver.switch_to.alert
time.sleep(2)
# 输入警告框上的文本内容
print(alertbox_contorl.text)
time.sleep(2)
# 点击警告框的【确定】按钮
alertbox_contorl.accept()
time.sleep(2)
driver.quit()
分析上述代码:
通过xpath方法定位到百度页面的“设置”,鼠标悬停在“设置”上这操作涉及鼠标操作,需要导入ActionChains包。然后,利用find_element_by_link_text()定位“搜索设置”,使用click()点击“搜索设置”。借助find_element_by_xpath()定位“每页20条”单选框,使用click()点击该单选框。点击【保存设置】按钮,弹出警告框,通过driver.switch_to.alert将控制权从driver对象转交到警告框上,alertbox_contorl.text获取警告框的内容,accept()点击警告框的【确定】按钮。
警告框小结

(6)多框架处理
在Web应用中经常遇到frame/iframe框架嵌套页面上,WebDriver只能在一个页面对一个框架识别和定位,对于frame/iframe框架内嵌上的元素无法直接定位,这是需要switch_to.frame()方法将当前主题切换为frame/iframe框架内嵌页面中。
iframe是HTML标签,作用是文档中的文档,或者浮动的框架(frame)。iframe元素会创建包含另外一个文档的内联框架(即行内框架)。
要求:打开https://www/mail.qq.com页面,输入用户名和密码,点击登录,关闭浏览器,代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://mail.qq.com/")
time.sleep(2)
# 方式一:通过frame的name值找到对应的frame
# driver.switch_to.frame("login_frame")
# 方式二:通过frame的索引所以找到对应的frame,索引值从0开始算起
# driver.switch_to.frame(1)
# 方式三:通过先找到iframe的元素,定位,转换。列表索引值从0开始算起
driver.switch_to.frame(driver.find_elements(By.XPATH,"//iframe")[1])
# 输入账号
driver.find_element_by_xpath('//*[@id="u"]').send_keys("123456789")
time.sleep(2)
# 输入密码
driver.find_element_by_xpath('//*[@id="p"]').send_keys("12345678910")
time.sleep(2)
# 点击【登录】按钮
driver.find_element_by_xpath('//*[@id="login_button"]').click()
time.sleep(2)
driver.quit()
分析上述代码:
在跳转到qq邮箱登录页面时,driver对象必须与该页面绑定。在输入账号和密码时,driver对象必须定位内层的框架(iframe)才可以输入账号和密码。
多框架处理小结
重点是driver对象操作转移到内层的框架上才可以对内层的框架上的元素进行操作,driver对象默认操作最外层框架的元素。

(7)设置元素等待
现在很多web都在使用AJAX技术,运用这种技术的软件当浏览器加载页面时,页面上的元素可能不会被同步加载完成,导致定位元素时会出现困难。可以通过设置元素等待来改善这类问题。
WebDriver提供三种元素等待方式:隐式等待,显式等待、强制等待。
隐式等待。在脚本创建driver对象之后,给driver设置一个全局的等待时间,对driver对象的整个生命周期(创建到关闭)都起效。如果在设置等待时间内,定位到了页面元素,则不等待,继续执行下面的代码,如果超出了等待时间,则抛出异常。
使用方法:driver.implicity_wait()
要求:使用显示等待,打开百度页面,在文本框输入“selenium”,点击【百度一下】按钮。
代码如下:
# 导入包
from selenium import webdriver
import time
# 生成chrome浏览器对象
driver = webdriver.Chrome()
# 全局隐性等待10s
driver.implicitly_wait(10)
# 打开百度页面
driver.get("https://www.baidu.com")
# 在百度页面文本框输入selenium
driver.find_element_by_id("kw").send_keys("selenium")
# 点击【百度一下】按钮
driver.find_element_by_id("su").click()
# 关闭全部页面
driver.quit()
显式等待。等待某个元素的出现才操作,如果超时则报异常。
使用方法:
要求:使用显示等待的方式等待百度页面的搜索文本框,并输入内容“selenium”,否则报错“定位失败”。
代码如下:
# 导入包
from selenium import webdriver
import time
# 显性等待使用
from selenium.webdriver.support.ui import WebDriverWait
# until()方法使用
from selenium.webdriver.support import expected_conditions as EC
# locator使用
from selenium.webdriver.common.by import By
# 创建浏览器对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com")
# util(method,info) 直到满足某一个条件,返回结果,等不到就报错
# method ---> EC.presence_of_element_located(locator) 判断某个元素是否定位到了
# locator ---> By.Id/By.Name,"属性值"
meg = WebDriverWait(driver,5,0.5,ignored_exceptions=None).until(EC.presence_of_element_located((By.ID,"kw")),"定位失败")
time.sleep(2)
# 测试是否定位到百度页面的搜索文本框
meg.send_keys("selenium")
# 执行完上一行代码,线程休眠2s
time.sleep(2)
# 关闭全部页面
driver.quit()
分析上述代码:
显性等待就是明确的要等到某个元素的出现,等不到就一直等,除非在规定的时间之内都没找到,那就就报异常。
显性等待用在关注某一个元素的加载问题才使用。
显性等待涉及的4个方法有:WebDriverWait()、until()、presence_of_element_located(locator)判断某个元素是否定位成功和locator(By,ID,“属性值”)。
强制等待。
使用方法:time.sleep(t)
推迟调用线程的运行,可通过参数secs指秒数,表示进程挂起的时间。
优先级:强制等待>隐式等待>显性等待
设置元素等待小结

webdriver API总结
webdriver API包括圆面元素定位和操作、浏览器操作、鼠标和键盘操作、警告框处理操作、多框架处理和设置元素等待。

3 自动化脚本开发
自动化测试用例一般可以由手工测试用例转化而来,需注意:
1 不是所有的手工测试用例都要转为自动化测试用例。
2 考虑到脚本开发的成本,不要选择流程太复杂的用例。如果有必要,可以把流程拆分成多个用例来实现脚本。
3 选择的用例最好可以构建成场景。例如,一个功能模块,分多个用例,多个用例使用同一个场景。
4 选取的用例可以是你认为是重复执行,很繁琐的部分。例如字段验证、提示信息验证这类,这部分适用于回归测试。
5 选取的用例可以是主体流程,这部分适用于冒烟测试。
3.1 自动化测试用例设计
在编写自动化测试用例过程中应该遵循以下原则:
1 一个用例为一个完整的场景,从用户登录系统到最终退出并关闭浏览器。
2 一个用例只验证一个功能点,不要试图在用户登录后把所有的功能都验证一遍。
3 尽可能少的编写逆向测试用例。一方面因为逆向逻辑的用例很多(例如,手机号输错有几十种情况)。
4 另一方面自动化测试脚本本身比较脆弱,复杂的逆向逻辑用例实现起来较为麻烦且容易出错。
5 用例和用例之间尽量避免产生依赖。
6 一条用例完成测试之后需要对测试场景进行还原,以免影响其它用例的执行。
测试点转为测试用例的原则:
设计一条正向用例,覆盖足够多的有效等价类数据;
设计一条反向用例,需要覆盖一条无效等价类数据,其他数据一律使用正向数据。
有验证码的时候,该怎么进行自动化测试?
让开发暂时屏蔽验证码、将验证码改为万能码(000000);
利用机器学习,训练样本,可以达到99%以上识别的成功率;
调用OCR的接口,去解析图片中验证码
例子:编写自动化测试用,测试QQ注册页面。
第一,编写需求分析表如下图:

第二,测试用例设计参考如下图:
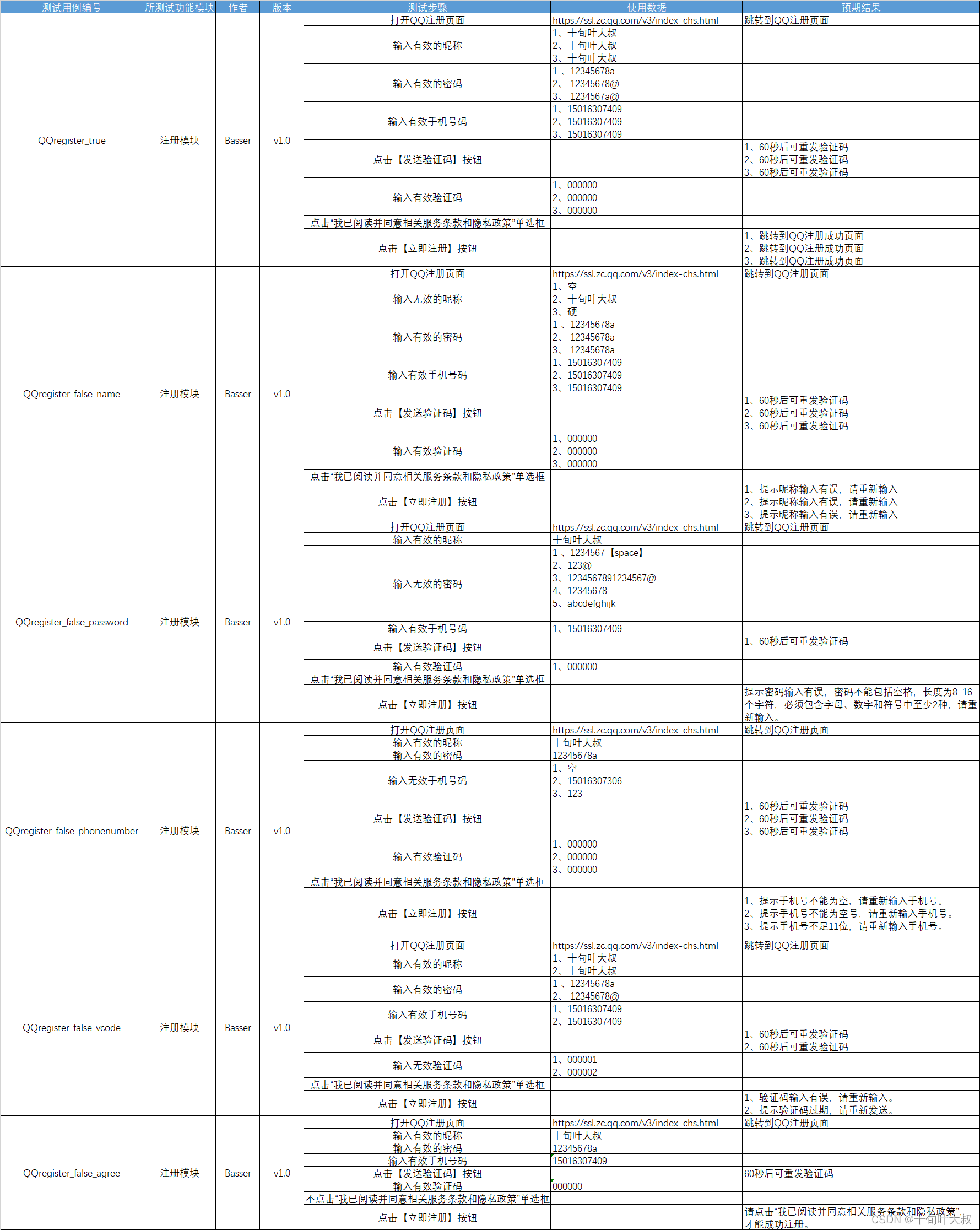
综上,业务和需求点要分开。业务就是具体操作的步骤写在测试用例中。如:输入有效的昵称、密码和手机号号码为业务。需求就写在需求分析中,如:昵称不能为空,密码不能包括空格等等为需求。
3.2 自动化测试分类
自动化测试模型有线性测试模型、模块化驱动测试模型、数据驱动测试模型和关键字驱动测试模型。
3.2.1 线性测试
脚本相对独立,单纯的模拟用户完整的操作场景,测试用例的开发和维护成本很高。
例子:QQ注册页面,结合上述的正向用例,用线性测试编写自动化测试。
第一条测试用例,py文件的文件名为QQregister_true_1,代码如下:
# 导包
from selenium import webdriver
import time
# 创建浏览器对象
driver = webdriver.Chrome()
# 打开QQ注册页面
driver.get("https://ssl.zc.qq.com/v3/index-chs.html")
# 输入有效昵称
driver.find_element_by_id("nickname").send_keys("十旬叶大叔")
time.sleep(2)
# 输入有效密码
driver.find_element_by_id("password").send_keys("12345678a")
time.sleep(2)
# 输入有效手机号码
driver.find_element_by_id("phone").send_keys("15016307409")
time.sleep(2)
# 点击【发送验证码】按钮
driver.find_element_by_id("send-sms").click()
time.sleep(5)
# 输入有效验证码
driver.find_element_by_xpath('//*[@id="code"]').send_keys("000000")
time.sleep(2)
# 点击同意协议
driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[1]/form/div[8]/label/img[2]').click()
time.sleep(2)
# 点击【立即注册】按钮
driver.find_element_by_id("get_acc").click()
time.sleep(2)
driver.quit()
第二条测试用例,QQregister_true_2,代码如下:
# 导包
from selenium import webdriver
import time
# 创建浏览器对象
driver = webdriver.Chrome()
# 打开QQ注册页面
driver.get("https://ssl.zc.qq.com/v3/index-chs.html")
# 输入有效昵称
driver.find_element_by_id("nickname").send_keys("十旬叶大叔")
time.sleep(2)
# 输入有效密码
driver.find_element_by_id("password").send_keys("12345678@")
time.sleep(2)
# 输入有效手机号码
driver.find_element_by_id("phone").send_keys("15016307409")
time.sleep(2)
# 点击【发送验证码】按钮
driver.find_element_by_id("send-sms").click()
time.sleep(5)
# 输入有效验证码
driver.find_element_by_xpath('//*[@id="code"]').send_keys("000000")
time.sleep(2)
# 点击同意协议
driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[1]/form/div[8]/label/img[2]').click()
time.sleep(2)
# 点击【立即注册】按钮
driver.find_element_by_id("get_acc").click()
time.sleep(2)
driver.quit()
第三条测试用例,QQregister_true_3,代码如下:
# 导包
from selenium import webdriver
import time
# 创建浏览器对象
driver = webdriver.Chrome()
# 打开QQ注册页面
driver.get("https://ssl.zc.qq.com/v3/index-chs.html")
# 输入有效昵称
driver.find_element_by_id("nickname").send_keys("十旬叶大叔")
time.sleep(2)
# 输入有效密码
driver.find_element_by_id("password").send_keys("1234567a@")
time.sleep(2)
# 输入有效手机号码
driver.find_element_by_id("phone").send_keys("15016307409")
time.sleep(2)
# 点击【发送验证码】按钮
driver.find_element_by_id("send-sms").click()
time.sleep(5)
# 输入有效验证码
driver.find_element_by_xpath('//*[@id="code"]').send_keys("000000")
time.sleep(2)
# 点击同意协议
driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[1]/form/div[8]/label/img[2]').click()
time.sleep(2)
# 点击【立即注册】按钮
driver.find_element_by_id("get_acc").click()
time.sleep(2)
driver.quit()
分析上述三条测试用例的代码:
很多重复的地方,要求已改许多地方都要同时该,维护性很差。
利用模块导包,一次性依次运行3条用例,即3个py文件。
新建registertotal.py文件,代码如下:
#导包 写到一个pt文件,一个个跑
import QQregister_true_1,QQregister_true_2,QQregister_true_3
分析上述代码:
只是运行1次,维护起来还是不方便。
现在需要把重复的操作写在方法中或者是类中。
线性测试模型小结:
以一行行的代码直接实现测试步骤,脚本相对独立,单纯的模拟用户完整的操作场景,测试用例的开发和维护成本很高,如果一个页面元素被改动了,所有线性脚本中用到这个元素的都需要更改。
3.2.2 模块化驱动测试
把重复的操作独立成公共模块,当用例执行过程中需要用到这一模块时则被调用,最大限度的消除了重复的操作,提高测试用例的可维护、复用性。
为了解决上述维护性差的问题将重复的操作写成一个方法,在main方法调用此方法,代码如下:
def reg(username,password,phonenumber,vcode):
from selenium import webdriver
import time
# 创建浏览器对象
driver = webdriver.Chrome()
# 打开QQ注册页面
driver.get("https://ssl.zc.qq.com/v3/index-chs.html")
# 输入有效昵称
driver.find_element_by_id("nickname").send_keys(username)
time.sleep(2)
# 输入有效密码
driver.find_element_by_id("password").send_keys(password)
time.sleep(2)
# 输入有效手机号码
driver.find_element_by_id("phone").send_keys(phonenumber)
time.sleep(2)
# 点击【发送验证码】按钮
driver.find_element_by_id("send-sms").click()
time.sleep(5)
# 输入有效验证码
driver.find_element_by_xpath('//*[@id="code"]').send_keys(vcode)
time.sleep(2)
# 点击同意协议
driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[1]/form/div[8]/label/img[2]').click()
time.sleep(2)
# 点击【立即注册】按钮
driver.find_element_by_id("get_acc").click()
time.sleep(2)
driver.quit()
if __name__ == '__main__':
reg("十旬叶大叔","12345678a","15016307409","000000")
reg("十旬叶大叔", "12345678@", "15016307409", "000000")
reg("十旬叶大叔", "1234567a@", "15016307409", "000000")
分析上述代码:
在main类中调用reg()方法,传入实参。但是内聚性不高,功能之间没有分开。可以将不同功能写成一个类,类中有不同的方法。
定义一个类,类中有创建浏览器对象方法、执行测试用例方法和关闭浏览器对象方法,代码如下:
# 导包
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
# 建立类
class reg():
# 打开浏览器功能
def open_brower(self,driver):
self.driver = driver
# 打开QQ注册页面
driver.get("https://ssl.zc.qq.com/v3/index-chs.html")
# 语言换成English
def change_language_toEnglish(self,driver):
self.driver = driver
language = driver.find_element_by_xpath('/html/body/div[2]/div[2]/div')
ActionChains(driver).move_to_element(language).perform()
driver.find_element_by_link_text("English").click()
# 执行测试用例
def input_info(self,driver,username,password,phonenumber,vcode):
self.driver = driver
# 输入有效的昵称
driver.find_element_by_id("nickname").send_keys(username)
time.sleep(2)
# 输入有效密码
driver.find_element_by_id("password").send_keys(password)
time.sleep(2)
# 输入有效手机号码
driver.find_element_by_id("phone").send_keys(phonenumber)
time.sleep(2)
# 点击【发送验证码】按钮
driver.find_element_by_id("send-sms").click()
time.sleep(2)
# 输入验证码
driver.find_element_by_xpath('//*[@id="code"]').send_keys(vcode)
time.sleep(2)
# 点击同意协议
driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[1]/form/div[8]/label/img[2]').click()
time.sleep(2)
# 清除填入的数据
def clear_info(self,driver):
self.driver = driver
driver.find_element_by_id("nickname").clear()
driver.find_element_by_id("password").clear()
driver.find_element_by_id("phone").clear()
driver.find_element_by_xpath('//*[@id="code"]').clear()
# 关闭浏览器功能
def quit_brower(self,driver):
self.driver = driver
driver.quit()
if __name__ == '__main__':
driver = webdriver.Chrome()
# 实例化类
obj1 = reg()
# obj1对象调用open_brower()方法,参数为上面的driver
obj1.open_brower(driver)
obj1.input_info(driver,"十旬叶大叔","12345678a","15016307409","000000")
obj1.input_info(driver, "十旬叶大叔", "12345678@", "15016307409", "000000")
obj1.input_info(driver, "十旬叶大叔", "1234567a@", "15016307409", "000000")
obj1.quit_brower(driver)
分析上述代码:
在main类中,实例化类,生成一个对象。obj1对象可以调用open_brower()、input_info()、input_info()和quit_brower()。实现打开浏览器、执行测试用例和关闭浏览器功能,提高了内聚性。
此外可以使用列表字典的形式存储用例数据,如下代码:
from selenium import webdriver
import time
dicData =[
{"username":"十旬叶大叔","password":"12345678a","phonenumber":"15016307409","vcode":"000000"},
{"username":"十旬叶大叔","password":"12345678@","phonenumber":"15016307409","vcode":"000000"},
{"username":"十旬叶大叔","password":"1234567a@","phonenumber":"15016307409","vcode":"000000"},
]
for i in dicData:
driver = webdriver.Chrome()
# driver.implicitly_wait(10)
driver.get("https://ssl.zc.qq.com/v3/index-chs.html")
driver.find_element_by_id("nickname").send_keys(i["username"])
time.sleep(2)
driver.find_element_by_id("password").send_keys(i["password"])
time.sleep(2)
driver.find_element_by_id("phone").send_keys(i["phonenumber"])
time.sleep(2)
driver.find_element_by_xpath('//*[@id="code"]').send_keys(i["vcode"])
time.sleep(2)
driver.quit()
分析上述代码:
列表里面嵌套字典,字典以属性为键,以属性值为值。
在for循环中,一行一行遍历,通过字典的键找到值。
存在问题:没有写断言!因为没有这么多真实有效的数据(QQ号注册需要手机号验证)。
模块化驱动测试小结:
把公用的功能(业务、步骤)放在一个专门的模块中,以方法和类来实现。如果其他模块需要这些公用的功能,直接调用即可,无需重复显示这些代码。模块化常出现在登录模块、退出模块、邮寄发送模块、数据库处理模块和日志生成模块等。
3.2.3 数据驱动测试
要求:将用例数据写在123_csv.csv文件中,编写自动化测试脚本完成3条用例的测试。
将用例数据写在123_csv.csv文件中,利用for循环遍历,代码如下:
import csv
from selenium import webdriver
import time
with open(r"Data/123_csv.csv", "r", encoding="utf-8") as f:
data = csv.reader(f)
for i in data:
driver = webdriver.Chrome()
# driver.implicitly_wait(10)
driver.get("https://ssl.zc.qq.com/v3/index-chs.html")
driver.find_element_by_id("nickname").send_keys(i[0])
time.sleep(2)
driver.find_element_by_id("password").send_keys(i[1])
time.sleep(2)
driver.find_element_by_id("phone").send_keys(i[2])
time.sleep(2)
driver.find_element_by_xpath('//*[@id="code"]').send_keys(i[3])
time.sleep(2)
分析上述代码:
导入csv包,打开csv文件,使用for遍历文件中的内容,一行一行遍历。输出是3个列表,因此可以通过下标找到具体的值。
此外,还可以使用excel文件存储用例数据。
要求:将用例数据写在123_excel.xlsx文件中,编写自动化测试脚本完成3条用例的测试。
在Python中处理excel文件,是需要专门模块的(额外安装)
将用例数据写在123_excel.xlsx文件中,利用for循环遍历,代码如下:
import xlrd
from selenium import webdriver
import time
# 打开xlsx格式文件
data = xlrd.open_workbook(r"./Data/123_excel.xlsx")
# 读取文件的第一张sheet
table1 = data.sheets()[0]
# 获取table1的行数
total_row = table1.nrows
for i in range(total_row):
# 创建浏览器对象
driver = webdriver.Chrome()
# 打开QQ注册页面
driver.get("https://ssl.zc.qq.com/v3/index-chs.html")
# 输入用例用户名
driver.find_element_by_id("nickname").send_keys(table1.row_values(i)[0])
time.sleep(2)
# 输入用例密码
driver.find_element_by_id("password").send_keys(table1.row_values(i)[1])
time.sleep(2)
# 输入用手机号码
driver.find_element_by_id("phone").send_keys(table1.row_values(i)[2])
time.sleep(2)
# 输入验证码
driver.find_element_by_xpath('//*[@id="code"]').send_keys(table1.row_values(i)[3])
time.sleep(2)
# 关闭全部浏览器
driver.quit()
分析上述代码:
安装xlrd模块,在命令行窗口输入:pip install xlrd
在py文件中导包import xlrd。
使用open_workbook("pwd")方法打开excel文件。
通过sheets()方法读取表格的第几张,返回的是一个列表。
row_values() 获取当前sheet页某一行数据,索引号从0开始。
col_values() 获取当前sheet页某一列数据,索引号从0开始。
nrows获取行数。
ncols获取列数。
使用for循环一行一行遍历单元格数据。
excel操作练习
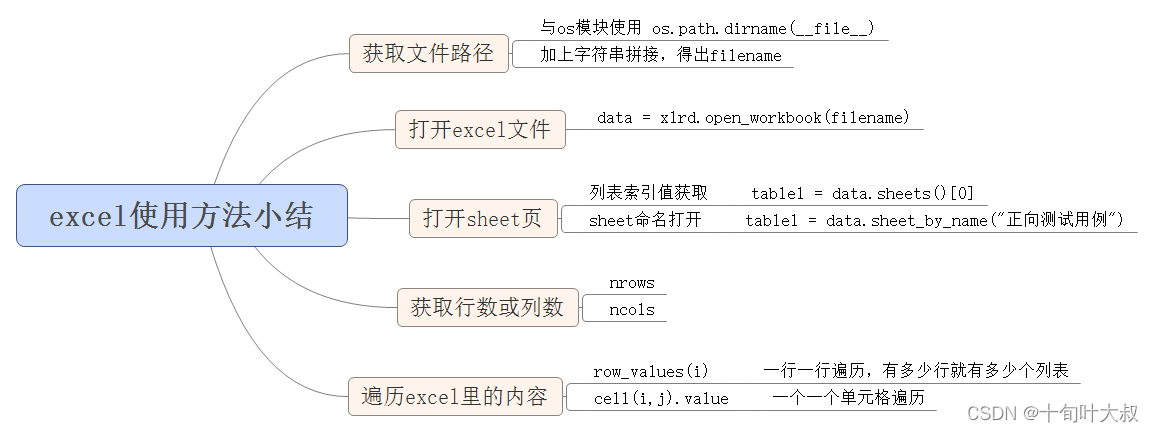
获取文件根目录位置,获取123_excel.xlsx文件位置,如下代码:
import os
# 文件路径
filename = os.path.dirname(__file__)+r'/QQregister/Data/123_excel.xlsx'
print(filename)
分析上述代码:
导入os模块,使用path.dirname(__file__)方法获取到当前文件的根目录,通过字符串拼接,得出123_excel.xlsx文件位置。需要获取根目录的上一级则使用os.path.dirname(os.path.dirname(__file__))。
打开123_excel.xlsx文件,打开sheet的第一页,如下代码:
# 打开excel文件
data = xlrd.open_workbook(filename)
print(data)
#方法1:打开sheet第一页
# table1 = data.sheets()[0]
# print(table1)
# 方法2:根据sheet的名字来获取
table1 = data.sheet_by_name("正向测试用例")
分析上述代码:
使用open_workbook()方法打开文件,打开sheet方法有两种,一是,根据索引值。二是,根据sheet命名。
遍历123_excel.xlsx,如下代码:
# 获取行数和列数
total_row = table1.nrows
total_col = table1.ncols
# print(total_row)
# 遍历table1的内容
for i in range(total_row):
print(table1.row_values(i))
# cell().value 获取单元格的值
for i in range(total_row): #一行一行读数据
for j in range(total_col): # 读第i行中的第j列
print(table1.cell(i,j).value) # 获取第i行第j列单元格中的值
分析上述代码:
获取行数和列数是为了得到遍历的次数,遍历方式有两种:第一,一次获取一行的内容;第二,一次获取一个单元格的值。
excel使用方法小结
3.2.4 关键字驱动测试
通过“关键字”的改变引起测试结果的改变,关键字驱动工具有UEF,slenium ide,Katalon Recoder等,提供用户图形化界面,降低脚本的编写难度。
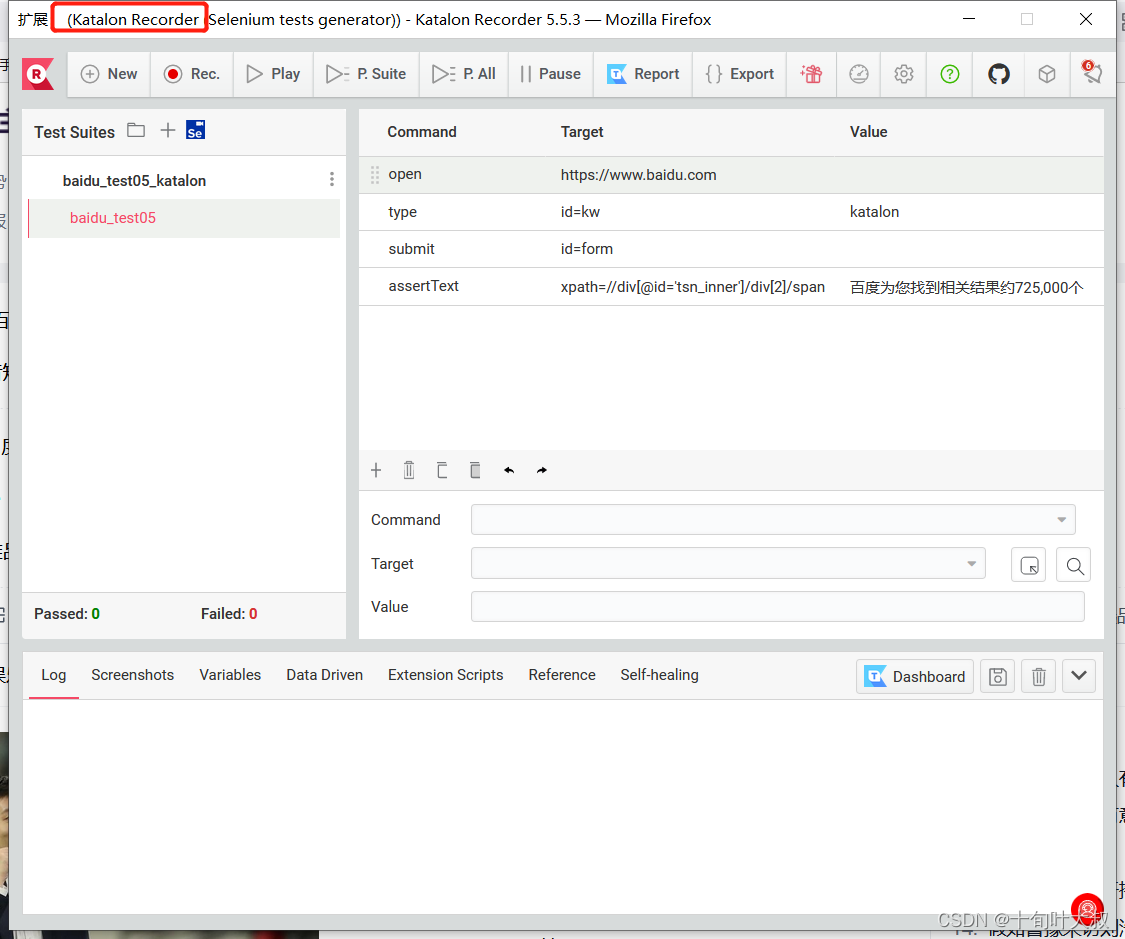
编写测试步骤如下图:
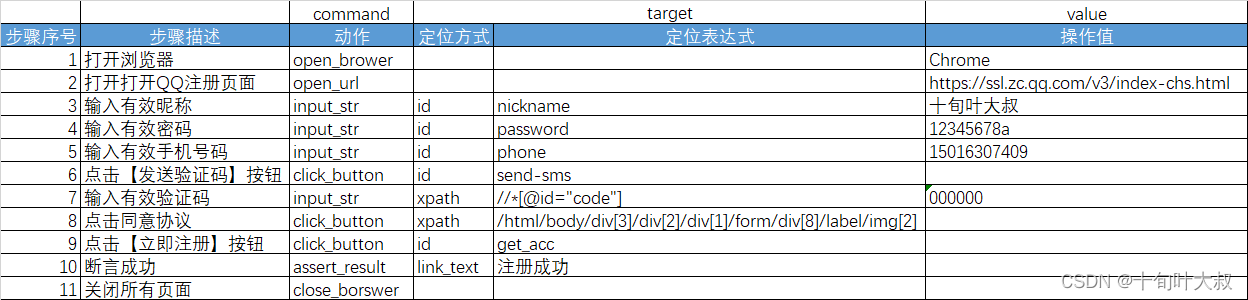
测试用例必须包括断言(检查点或验证)。
总结
Web自动化测试使用selenium+Python。
webdriver API包括圆面元素定位和操作、浏览器操作、鼠标和键盘操作、警告框处理操作、多框架处理和设置元素等待。
自动化测试有线性测试、模块驱动测试、数据驱动测试和关键字驱动测试。
自动化脚本开发还是存在很多问题。
如果超时用例数量很多,要么一个个执行,要么导包执行。
断言方式不够全面,只能是在控制台打印测试用例是否通过,希望断言的状态是显示在报告中,而不是通过if语句进行判断。
无法得知测试报告的效果,总共执行多少条用例,通过了多少条测试用例,不通过的测试用例有几条,不通过的原因是什么?
因此,需要引入测试框架。















 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









