






1.引入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.1.0</version>
</dependency>
2.配置数据及分表规则
2.1.数据库配置。
因为只用到分表,所以只有一个库。
package cn.com.config;
import javax.sql.DataSource;
import cn.com.config.InitWorkerId;
import com.alibaba.druid.pool.DruidDataSource;
import com.google.common.collect.Lists;
import org.apache.shardingsphere.driver.api.ShardingSphereDataSourceFactory;
import org.apache.shardingsphere.driver.jdbc.core.datasource.ShardingSphereDataSource;
import org.apache.shardingsphere.infra.config.RuleConfiguration;
import org.apache.shardingsphere.infra.config.algorithm.ShardingSphereAlgorithmConfiguration;
import org.apache.shardingsphere.infra.instance.ComputeNodeInstance;
import org.apache.shardingsphere.sharding.api.config.ShardingRuleConfiguration;
import org.apache.shardingsphere.sharding.api.config.rule.ShardingTableRuleConfiguration;
import org.apache.shardingsphere.sharding.api.config.strategy.keygen.KeyGenerateStrategyConfiguration;
import org.apache.shardingsphere.sharding.api.config.strategy.sharding.StandardShardingStrategyConfiguration;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
@Slf4j
@Configuration
public class DataSource4Inject {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Bean(name = "dataSource")
@Primary
public DataSource dataSource() throws SQLException {
//数据源Map
Map<String, DataSource> dsMap = new HashMap<>();
// Druid连接池可以根据需要自己配置
DataSource dataSource = new DruidDataSource();
//配置主库
dsMap.put("ds", dataSource);
//配置分片规则
List<RuleConfiguration> ruleConfigs = Lists.newArrayList();
// user表分表规则规则
ruleConfigs.add(getUserRuleConfig());
//创建DS
// 可选参数
Properties prop = new Properties();
// 打印sql
prop.setProperty("sql-show", "true");
// 创建sharding数据源
DataSource source = ShardingSphereDataSourceFactory.createDataSource(dsMap, ruleConfigs, prop);
// 获取sharding上下文
ComputeNodeInstance instance = ((ShardingSphereDataSource) source).getContextManager().getInstanceContext().getInstance();
// 获取workId及设置workId
Long workerId = InitWorkerId.getInstance(redisTemplate);
instance.setWorkerId(workerId);
return source;
}
/**
* 分表配置
*/
private ShardingRuleConfiguration getUserRuleConfig() {
ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration();
//把逻辑表和真实表的对应关系添加到分片规则配置中
shardJdbcConfig.getTables().add(getTableRule01());
//设置表的分片规则(数据的水平拆分) 根据userid分表
shardJdbcConfig.setDefaultTableShardingStrategy(new StandardShardingStrategyConfiguration
("user_id", "user-role-inline"));
//设置分表策略
Properties props = new Properties();
shardJdbcConfig.getShardingAlgorithms().put("user-role-inline",
new ShardingSphereAlgorithmConfiguration("UserRoleAlgorithm", props));
//设置主键生成策略
// * 雪花算法
Properties idProperties = new Properties();
shardJdbcConfig.getKeyGenerators().put("snowflake", new ShardingSphereAlgorithmConfiguration("SNOWFLAKE", idProperties));
return shardJdbcConfig;
}
/**
* 数据表及id使用算法
*/
private ShardingTableRuleConfiguration getTableRule01() {
ShardingTableRuleConfiguration result = new ShardingTableRuleConfiguration("user_role", "ds.user_role_${0..15}");
result.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("id", "snowflake"));
return result;
}
}
2.2.自定义分表规则分表规则
package cn.com.config;
import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;
import org.springframework.stereotype.Component;
import java.util.Collection;
/**
* 分表算法
*/
@Component
public class UserRoleAlgorithm implements StandardShardingAlgorithm<String> {
/**
* 根据用户id分成16个表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
//15 & ((h = key.hashCode()) ^ (h >>> 16))
int h;
return "user_role_" + (15 & ((h = value.getValue().hashCode()) ^ (h >>> 16)));
}
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {
return null;
}
@Override
public void init() {
}
@Override
public String getType() {
return "UserRoleAlgorithm";
}
}
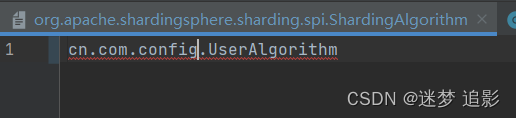
使用自定义的分表规则,还需在resource下增加配置文件,并写入全包名
org.apache.shardingsphere.sharding.spi.ShardingAlgorithm

2.3 workId的生成
workId有很多生成方法,本站采用的是redis自增。
package cn.com.config.sharding;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.support.atomic.RedisAtomicLong;
import java.util.Objects;
public class InitWorkerId {
private static Long workerId;
public static Long getInstance(RedisTemplate<String, String> redisTemplate) {
if (workerId == null) {
synchronized (InitWorkerId.class) {
if (workerId == null) {
RedisAtomicLong counter = new RedisAtomicLong("redis_work_id", Objects.requireNonNull(redisTemplate.getConnectionFactory()));
// workId最大值为1024 应该够用好久
workerId = (counter.incrementAndGet() % 1024);
return workerId;
}
}
}
return workerId;
}
}
3. 关于workId的设置
在刚开始设置workId时,试了很多种方法都不生效。看了源码是InstanceContext类从ComputeNodeInstance节点中取出。没找到设置值得地方。所以最后使用最笨但有效的方法,从DataSource 中取出上下文,直接设置值。
// 创建sharding数据源
DataSource source = ShardingSphereDataSourceFactory.createDataSource(dsMap, ruleConfigs, prop);
// 获取sharding上下文
ComputeNodeInstance instance = ((ShardingSphereDataSource) source).getContextManager().getInstanceContext().getInstance();
// 获取workId及设置workId
Long workerId = InitWorkerId.getInstance(redisTemplate);
instance.setWorkerId(workerId);
如果有更好的方法,可以评论。














 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









