






 本文介绍如何使用Python的Pandas库处理两个Excel文件,当文件中存在相同但排列顺序不同的数据时,通过词这一列进行匹配并更新其他列的值。具体步骤包括读取文件、查找重复值、设置索引并应用映射表。
本文介绍如何使用Python的Pandas库处理两个Excel文件,当文件中存在相同但排列顺序不同的数据时,通过词这一列进行匹配并更新其他列的值。具体步骤包括读取文件、查找重复值、设置索引并应用映射表。
如果两个文件,有重复的数据,但排列顺序不同。数据量庞大时,手动一一映射显然不可能,如何使用python快速将表A的数据与表B的数据基于某列的字段名称进行匹配,映射其他列的数值?
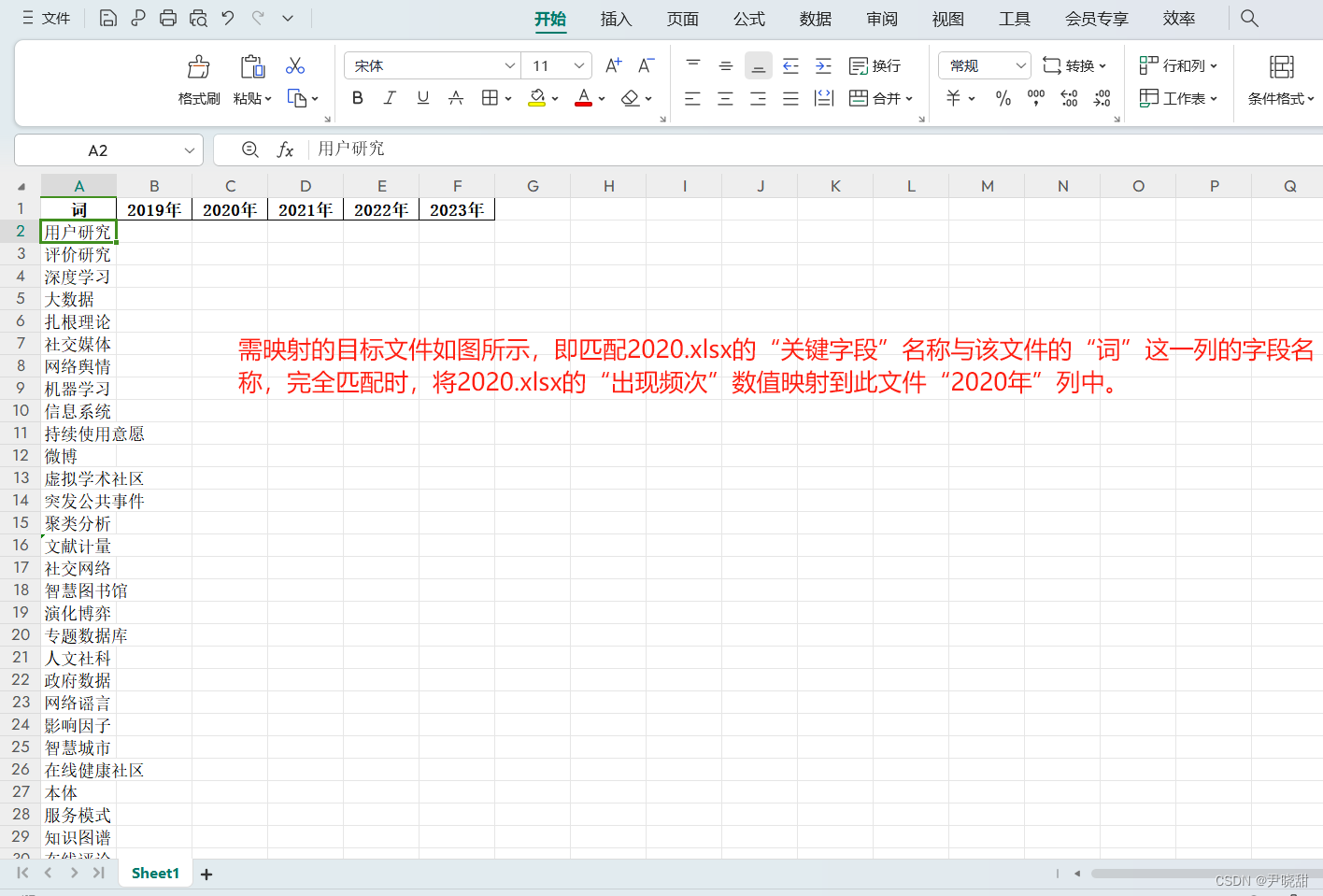
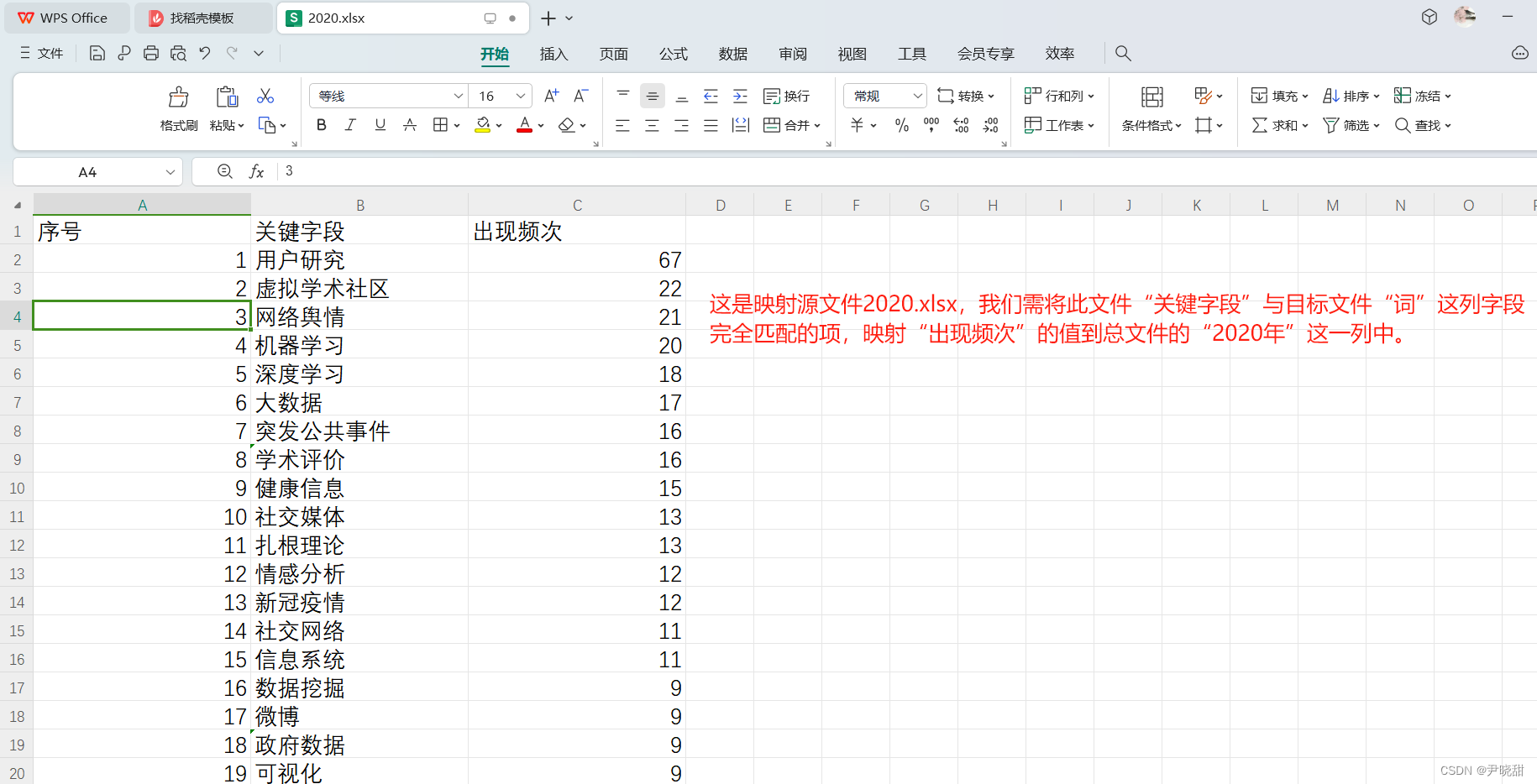
举一个列子,假设目标映射文件如下图所示。我们需要把2020.xlsx文件中对应的词频映射到这一个总文件中,可2020.xlsx文件与总文件顺序不符,不能直接复制。如何快速实现?
代码如下:
import pandas as pd
# 读取两个Excel文件
df_2019 = pd.read_excel('2020.xlsx')
df_competitive = pd.read_excel('词频汇总.xlsx')
print(df_2019.columns)
print(df_competitive.columns)
duplicates = df_2019[df_2019.duplicated(subset='词', keep=False)]
if not duplicates.empty:
print("关键字段列存在重复值:")
print(duplicates)
else:
print("关键字段列无重复值")
assert '词' in df_2019.columns and '对应频次' in df_2019.columns
assert '词' in df_competitive.columns and '2020年' in df_competitive.columns
df_map = df_2019[['词', '对应频次']].set_index('词')
df_competitive['2020年'] = df_competitive['词'].map(df_map['对应频次'])
df_competitive['2020年'].fillna(0, inplace=True)
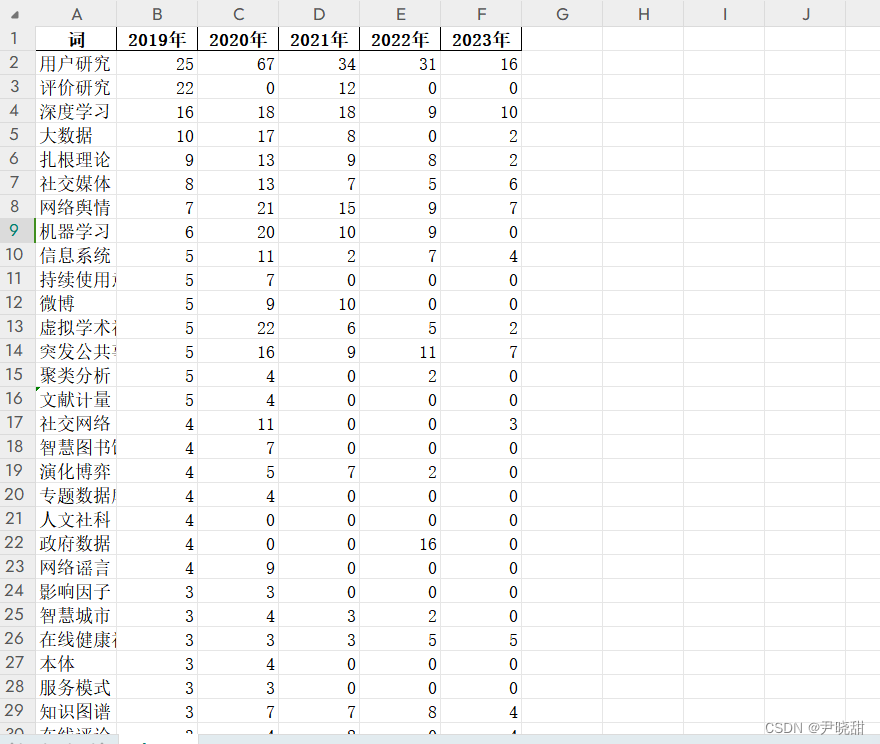
df_competitive.to_excel('映射后.xlsx', index=False)同2020年数据的映射方式,将五年表格数据分别映射到汇总后的文件中,映射后效果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









