







 本文深入探讨了Java中的常量池,特别是字符串常量池的原理和不同JDK版本的变化。字符串创建的三种方式——直接赋值、newString()和intern()方法的内部机制被详细解析,包括它们在内存中的表现。此外,文章还分析了字符串比较的多种情况,以及字节码层面字符串相加的实现。最后,提到了基本类型包装类的常量池优化。
本文深入探讨了Java中的常量池,特别是字符串常量池的原理和不同JDK版本的变化。字符串创建的三种方式——直接赋值、newString()和intern()方法的内部机制被详细解析,包括它们在内存中的表现。此外,文章还分析了字符串比较的多种情况,以及字节码层面字符串相加的实现。最后,提到了基本类型包装类的常量池优化。
文章目录
1. 常量池概述
java代码经过编译后会生成.class字节码文件,随便打开一个target目录下的.class文件,可以看到cafe babe魔数等其他的二进制数据!
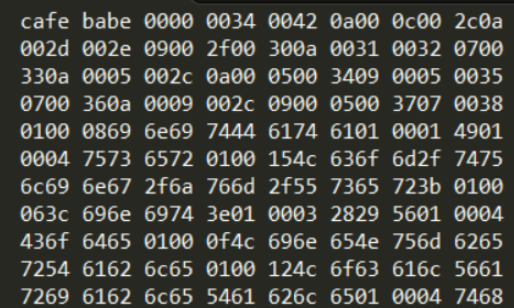

可以看到.class文件中除了魔数、主次版本等,其他的都属于常量池。常量池可以看做存放java代码的,主要存放两大类常量:字面量和符号引用。
- 字面量:字面量就是指由字母、数字等构成的字符串或者数值常量。字面量只可以右值出现,所谓右值是指等号右边的值,如:
int a=1这里的a为左值,1为右值。在这个例子中1就是字面量。
int a = 1;
int b = 2;
int c = "abcdefg";
int d = "abcdefg";
- 符号引用:上面的
a、b就是字段名称,就是一种符号引用,符号引用可以是:- 类和接口的全限定名
com.xx.User - 字段的名称和描述符
name - 方法的名称和描述符
set()
- 类和接口的全限定名
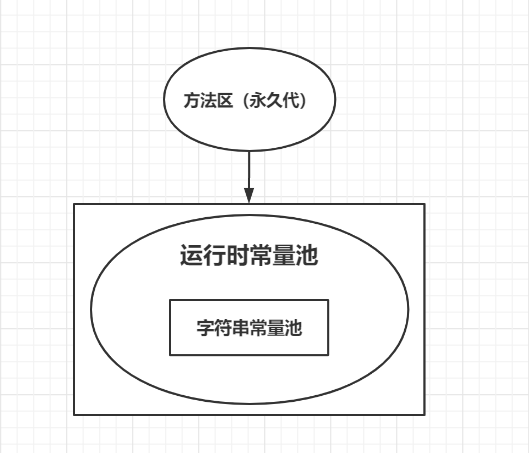
1.1 静态常量池、运行时常量池与字符串常量池的区别
像这些静态的、未加载的.class文件的数据被称为静态常量池,但经过jvm把.class文件装入内存、加载到方法区后,常量池就会变为运行时常量池!对应的符号引用在程序加载或运行时会被转变为被加载到方法区的代码的直接引用,在jvm调用这个方法时,就可以根据这个直接引用找到这个方法在方法区的位置,然后去执行。
而字符串常量池又是运行时常量池中的一小部分,字符串常量池的位置在jdk不同版本下,有一定区别!
Jdk1.6及之前: 有永久代, 运行时常量池包含字符串常量池
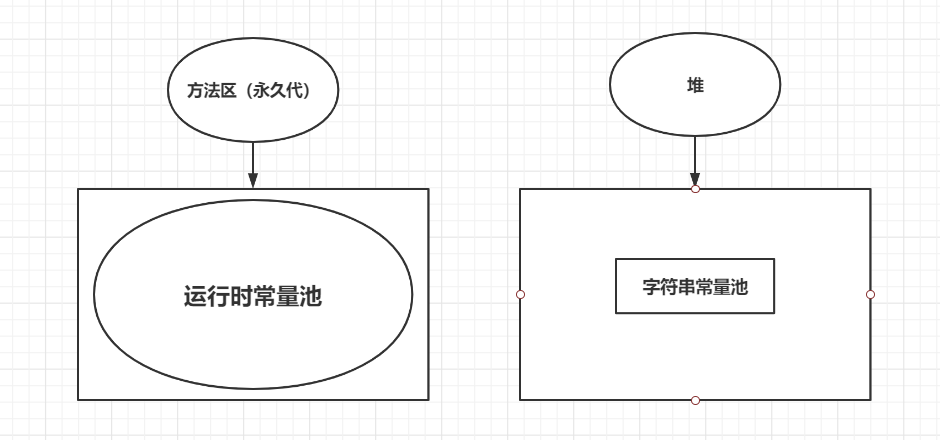
Jdk1.7:有永久代,但已经逐步“去永久代”,字符串常量池从永久代里的运行时常量池分离到堆里
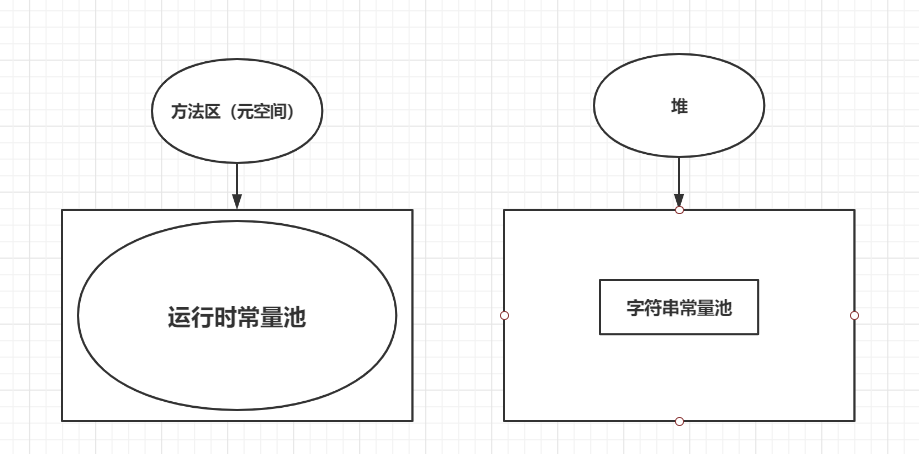
Jdk1.8及之后: 无永久代,运行时常量池在元空间,字符串常量池里依然在堆里
验证:不同jdk版本中,往ArrayList<String>中添加字符串
/**
* jdk6:-Xms6M -Xmx6M -XX:PermSize=6M -XX:MaxPermSize=6M
* jdk8:-Xms6M -Xmx6M -XX:MetaspaceSize=6M -XX:MaxMetaspaceSize=6M
*/
public class RuntimeConstantPoolOOM{
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
for (int i = 0; i < 10000000; i++) {
String str = String.valueOf(i).intern();
list.add(str);
}
}
}
运行结果:可以看到jdk7和jdk6抛出的异常是在不同的区域
- jdk7及以上抛的异常:Exception in thread “main” java.lang.OutOfMemoryError: Java heap space
- jdk6抛的异常:Exception in thread “main” java.lang.OutOfMemoryError: PermGen space
2. 字符串常量池的设计初衷
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。
JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化:为字符串开辟一个字符串常量池,类似于缓存区。在创建字符串常量时:
- 首先查询字符串常量池是否存在该字符串
- 如果存在该字符串,返回引用实例
- 如果不存在,先实例化该字符串并放入池中(),然后再把这个字符串返回。
- 下次再调用时,直接从字符串常量池中取值!
字符串常量池底层是hotspot的C++实现的,底层类似一个哈希表k-v结构的, 保存的本质上是字符串对象的引用。
3. 字符串的几种创建方式及原理
字符串的创建分为以下三种:
- 直接赋值
- new String()
- intern方法
①:直接赋值
这种方式创建的字符串对象,只会在常量池中。返回的也只是字符串常量池中的对象引用!
String s = "aaa"; // s指向常量池中的引用
步骤如下:
- 因为有
aaa这个字面量,在创建对象s的时候,JVM会先去常量池中通过equals(key)方法,判断是否有相同的对象 - 如果有,则直接返回该对象在常量池中的引用
- 如果没有,则会在常量池中创建一个新对象,再返回常量池中
aaa的对象引用。
②:new String()
这种方式会保证字符串常量池和堆中都有这个对象,最后返回堆内存中的对象引用!
String s1 = new String("aaa"); // s1指向内存中的对象引用
步骤如下:
- 同上,看到有
"aaa"这个字面量,就会先去字符串常量池中检查是否存在字符串"aaa" - 如果不存在,先在字符串常量池里创建一个字符串对象
"aaa";再去堆内存中创建一个字符串对象"aaa" - 如果存在,就直接去堆内存中创建一个字符串对象
"aaa" - 无论存不存在,都只返回堆内存中的字符串对象
"aaa"的引用
③:intern()方法
String s1 = new String("aaa");
String s2 = s1.intern();
System.out.println(s1 == s2); //false
intern方法是一个 native 的方法,当调用 intern方法时:
- 如果字符串常量池中已经包含一个等于
"aaa"的字符串(用equals(oject)方法确定),则返回字符串常量池中的字符串"aaa"。 - 如果字符串常量池中没有
"aaa"这样一个字符串,则会将intern返回的引用指向当前字符串s1,也就说会返回堆中的"aaa"
注意:在jdk1.6版本及以前,如果字符串常量池中没有"aaa" 这样一个字符串 ,还需要将"aaa" 复制到字符串常量池里,然后返回字符串常量池中的这个新创建的字符串"aaa"。
3. 面试题:字符串比较
①:下面的代码创建了多少个 String 对象(intern方法的理解)?
String s1 = new String("he") + new String("llo");
String s2 = s1.intern();
System.out.println(s1 == s2);
答案:
- 在 JDK 1.6 下输出是
false,创建了6个对象 - 在 JDK 1.7 及以上的版本输出是
true,创建了5个对象
原理如下:
String s1 = new String("he") + new String("llo")这段代码首先会先根据字面量在字符串常量池中创建he、llo这两个对象- 然后根据
new String又会在堆中创建he、llo这两个对象,此时一共四个对象 - 然后再根据
+号,合成一个新的对象hello,这个对象是存在堆中的,一共五个对象
上述过程无论是jdk哪个版本都是一致的,但在调用intern()方法时,需要区分jdk版本:
在 jdk1.6 中调用 intern() 方法时:
- 首先会在字符串常量池中寻找与
hello(s1的值)的equal()方法相等的字符串 - 假如字符串存在,就返回该字符串在字符串常量池中的引用
- 假如字符串不存在,
jvm会重新在永久代上创建一个实例,并返回这个字符串常量池中新建的实例hello。 - 这道题显然是不存在的,所以
s2的引用是字符串常量池中新建的实例hello,而s1的引用则是堆中的实例hello,s1 == s2又比较的是引用地址,所以在jdk1.6创建了6个对象,输出是false
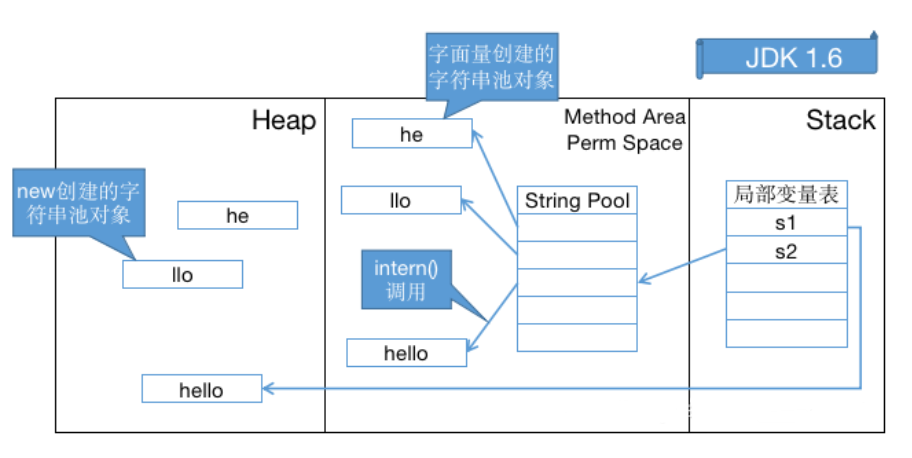
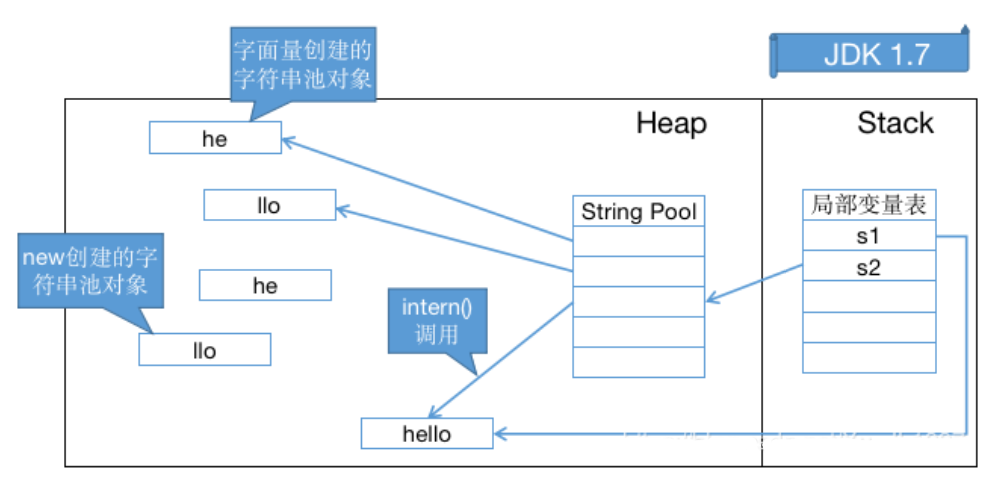
在 jdk1.8 中调用 intern() 方法时:
- 在 JDK 1.7 (及以上版本)中,由于字符串常量池不在永久代了,放在了堆中,刚好字符串对象
s1也是存在于堆中的,所以intern()做了一些修改,为了更方便地利用堆中的对象,省去了字符串常量池的复制操作!可以直接指向堆上的实例hello。 - 所以在 JDK 1.7 (及以上版本)中,只需要创建
5个对象,且intern()返回的对象s2也是堆中的对象hello,s1、s2同为堆中对象hello的引用,所以s1 == s2,返回true。
②:字符串比较
示例1:
String s0="ab";
String s1="ab";
String s2="a" + "b";
System.out.println( s0==s1 ); //true
System.out.println( s0==s2 ); //truea
解析:
- 例子中的 s0和s1中的
ab都是字符串常量,它们在编译期就被确定了,所以s0 == s1为 true; String s2="a" + "b"字面量a和字面量b直接相加,在编译期就被优化为一个字符串常量"ab",所以s0 、s1 、s2都可以看作是sx = "ab",返回的都是字符串常量池中的ab,无论怎么比较都是相等的!
示例2:
String s0="ab";
String s1=new String("ab");
String s2="a" + new String("b");
System.out.println( s0==s1 ); // false
System.out.println( s0==s2 ); // false
System.out.println( s1==s2 ); // false
解析:
- s0 指向字符串常量池中的
ab,s1指向堆中的ab,两者不相等 - s2因为有后半部分
new String(”b”),所以jvm无法在编译期确定,所以也是一个新创建对象”ab”的引用,s2也相当于new String("ab"),与其他的都不想等!
示例3:
String a = "a1";
String b = "a" + 1;
System.out.println(a == b); // true
String a = "atrue";
String b = "a" + "true";
System.out.println(a == b); // true
String a = "a3.4";
String b = "a" + 3.4;
System.out.println(a == b); // true
分析:
- JVM对于字符串常量的"+"号连接,将在程序编译期,JVM就将常量字符串的
"+"连接优化为连接后的值,拿"a" + 1来说,经编译器优化后在class中就已经是a1。 - 在编译期其字符串常量的值就确定下来,故上面程序最终的结果都为
true。
示例4:
String a = "ab";
String bb = "b";
String b = "a" + bb;
System.out.println(a == b); // false
分析:
- JVM对于字符串引用,由于在字符串的
"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + bb无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给b。所以上面程序的结果也就为false。
示例5:
String a = "ab";
final String bb = "b";
String b = "a" + bb;
System.out.println(a == b); // true
分析:
- 和示例4中唯一不同的是
bb字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + bb和"a" + "b"效果是一样的。故上面程序的结果为true。
示例6:
String a = "ab";
final String bb = getBB();
String b = "a" + bb;
System.out.println(a == b); // false
private static String getBB()
{
return "b";
}
分析:
- JVM对于字符串引用
bb,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和"a"来动态连接并分配地址为b,故上面程序的结果为false。
示例7:
//字符串常量池:"计算机"和"技术"
//堆内存:str1引用的对象"计算机技术"
//堆内存中还有个StringBuilder的对象,但是会被gc回收
//StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用
String str2 = new StringBuilder("计算机").append("技术").toString(); //字面量没有出现"计算机技术"字面量,所以不会在常量池里生成"计算机技术"对象
//"计算机技术" 在池中没有,但是在堆中存在,则intern时,会直接返回该堆中的引用
System.out.println(str2 == str2.intern()); //true
//字符串常量池:"ja"和"va"
//堆内存:str1引用的对象"java"
//堆内存中还有个StringBuilder的对象,但是会被gc回收
//StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用
String str1 = new StringBuilder("ja").append("va").toString(); //没有出现"java"字面量,所以不会在常量池里生成"java"对象
//java是关键字,在JVM初始化的相关类里肯定早就放进字符串常量池了
System.out.println(str1 == str1.intern()); //false
//"test"作为字面量,放入了池中
//而new时s1指向的是heap中新生成的string对象
//s1.intern()指向的是"test"字面量之前在池中生成的字符串对象
String s1=new String("test");
System.out.println(s1==s1.intern()); //false
String s2=new StringBuilder("abc").toString();
System.out.println(s2==s2.intern()); //false
//同上
4. 从字节码层面分析字符串相加"+"的原理
先看如下代码:分析为什么s0和s1不相等!
public class Stringtest {
public static void main(String[] args) {
String s0 = "a" + "b" + "c"; //就等价于String s = "abc";
String a = "a";
String b = "b";
String c = "c";
String s1 = a + b + c;
}
}
运行程序后,在IDEA里会生成Stringtest.class,打开后发现:
//编译后的 Stringtest.class 文件
public class Stringtest {
public Stringtest() {
}
public static void main(String[] args) {
//s0编译后已经被优化成abc
String s0 = "abc";
String a = "a";
String b = "b";
String c = "c";
//s1则不会直接被编译器优化,而是使用StringBuilder.append().toString()生成
(new StringBuilder()).append(a).append(b).append(c).toString();
}
}
可以看到:
- 对于字符串常量的相加操作:
s0 = "a" + "b" + "c"经过编译后已经被优化成s0 = "abc",这种返回的是字符串常量池中的对象引用 - 对于字符串引用的相加操作:
String s1 = a + b + c;编译器无法对其进行优化,在底层会调用StringBuilder.append().toString()生成对象引用
那么两者不相等的原因只能出现在StringBuilder.append().toString()中!我们进一步查看StringBuilder的源码发现其toString方法居然是new String():
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
new String返回的是堆中的对象引用,与s0 = "abc"返回常量池的对象引用是肯定的不相等的!
注意:Stringtest.class是字节码文件的易读版本,如果不信,可以使用javap -c Stringtest.class来直接查看字节码文件!
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String abc s0直接被优化成abc
2: astore_1
3: ldc #3 // String a
5: astore_2
6: ldc #4 // String b
8: astore_3
9: ldc #5 // String c
11: astore 4
13: new #6 // class java/lang/StringBuilder
16: dup
17: invokespecial #7 // Method java/lang/StringBuilder."<init>":()V
20: aload_2
21: invokevirtual #8 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
24: aload_3
25: invokevirtual #8 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
28: aload 4
30: invokevirtual #8 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
33: invokevirtual #9 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
36: astore 5
38: return
5. 其他的常量池
java中基本类型的包装类的大部分都实现了常量池技术(严格来说应该叫对象池,在堆上),这些类是Byte、Short、Integer、Long、Character、Boolean。另外两种浮点数类型的包装类Float、Double则没有实现。
Byte、Short、Integer、Long、Character这5种整型的包装类也只是在值为【-128 ,127】之间才可使用对象池, 因为一般这种比较小的数用到的概率相对较大。
public class IntegerTest {
public static void main(String[] args) {
//5种整形的包装类Byte,Short,Integer,Long,Character的对象,
//在值小于127时可以使用对象池
Integer i1 = 127; //这种调用底层实际是执行的Integer.valueOf(127),里面用到了IntegerCache对象池
Integer i2 = 127;
System.out.println(i1 == i2);//输出true
//值大于127时,不会从对象池中取对象
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4);//输出false
//用new关键词新生成对象不会使用对象池
Integer i5 = new Integer(127);
Integer i6 = new Integer(127);
System.out.println(i5 == i6);//输出false
//Boolean类也实现了对象池技术
Boolean bool1 = true;
Boolean bool2 = true;
System.out.println(bool1 == bool2);//输出true
//浮点类型的包装类没有实现对象池技术
Double d1 = 1.0;
Double d2 = 1.0;
System.out.println(d1 == d2);//输出false
}
}
上述代码,使用javap -c IntegerTest.class查看字节码文件如下:
public static void main(java.lang.String[]);
Code:
0: bipush 127
2: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
5: astore_1
6: bipush 127
8: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
11: astore_2
12: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
15: aload_1
16: aload_2
17: if_acmpne 24
20: iconst_1
21: goto 25
24: iconst_0
25: invokevirtual #4 // Method java/io/PrintStream.println:(Z)V
28: sipush 128
31: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
34: astore_3
35: sipush 128
38: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
41: astore 4
43: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
46: aload_3
47: aload 4
49: if_acmpne 56
52: iconst_1
53: goto 57
56: iconst_0
57: invokevirtual #4 // Method java/io/PrintStream.println:(Z)V
60: new #5 // class java/lang/Integer
63: dup
64: bipush 127
66: invokespecial #6 // Method java/lang/Integer."<init>":(I)V
69: astore 5
71: new #5 // class java/lang/Integer
74: dup
75: bipush 127
77: invokespecial #6 // Method java/lang/Integer."<init>":(I)V
80: astore 6
82: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
85: aload 5
87: aload 6
89: if_acmpne 96
92: iconst_1
93: goto 97
96: iconst_0
97: invokevirtual #4 // Method java/io/PrintStream.println:(Z)V
100: iconst_1
101: invokestatic #7 // Method java/lang/Boolean.valueOf:(Z)Ljava/lang/Boolean;
104: astore 7
106: iconst_1
107: invokestatic #7 // Method java/lang/Boolean.valueOf:(Z)Ljava/lang/Boolean;
110: astore 8
112: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
115: aload 7
117: aload 8
119: if_acmpne 126
122: iconst_1
123: goto 127
126: iconst_0
127: invokevirtual #4 // Method java/io/PrintStream.println:(Z)V
130: dconst_1
131: invokestatic #8 // Method java/lang/Double.valueOf:(D)Ljava/lang/Double;
134: astore 9
136: dconst_1
137: invokestatic #8 // Method java/lang/Double.valueOf:(D)Ljava/lang/Double;
140: astore 10
142: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
145: aload 9
147: aload 10
149: if_acmpne 156
152: iconst_1
153: goto 157
156: iconst_0
157: invokevirtual #4 // Method java/io/PrintStream.println:(Z)V
160: return
}
可以看到,当比较【-128,127】以内的数时,会调用Byte、Short、Integer、Long、Character、Boolean这五种包装类的valueOf()方法,以Integer为例:
public static Integer valueOf(int i) {
//如果在【low,hign】区间内,则统一使用IntegerCache缓存池中的对象
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
//如果不在【low,hign】区间内,则 new 一个对象,生成一个新的地址引用
return new Integer(i);
}
其中【low,hign】区间如下:
static final int low = -128;
static final int high;
...
int h = 127;
high = h;

















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









