






假设现在有一个csv文件,文件里有几列数据,先尝试分析不同列数据之间的相关性。假设有6列数据,列名分别为'A'、'B'、'C'、'D'、'E'、'F'。
- 读入数据
import pandas as pd
import numpy as np
df = pd.read_csv('文件名.csv')
# 删除nan值以避免得到的相关系数为nan,
# dropna()用来删除dataframe数据中的缺失数据,即删除nan数据
# df.dropna(how='any')的意思是只要该行存在nan就删除该行
df = df.dropna(how='any')- 计算任意两列的相关系数矩阵
X=df['A']
Y=df['B']
result1=np.corrcoef(X,Y)
print(result1)如上代码所示,计算列'A'和列'B'的相关系数矩阵,可得到如下图所示的相关系数矩阵。下图中从左到右、从上到下分别代表AA AB BA BB之间的相关系数。

- 求表中所有变量之间的相关系数矩阵
# 计算表中所有列之间的相关系数矩阵,rowvar=False表示每一列是一个变量。
# 默认rowvar=True,表示每行是一个变量
result2=np.corrcoef(df,rowvar=False)
print(result2)
# 也可以计算表中任意多列之间的相关系数矩阵
# result3表示表中第1到第6列之间的相关系数矩阵,表中的第1列为df[df.columns[0]],即从0开始
result3 = np.corrcoef(df[df.columns[1:7]], rowvar=False)
print(result3)
# 也可以通过列名
result4=np.corrcoef(df[['A','B','C','D','E','F']],rowvar=False) 按照上面的代码即可得到如下图所示的相关系数矩阵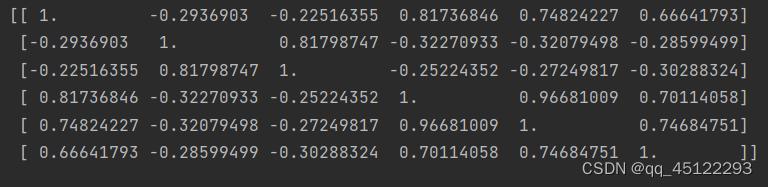
- 通过pandas进行相关性分析
# 上面的代码是通过numpy进行相关性分析,也可以通过pandas进行相关性分析
# 计算X和Y之间的相关系数(不是相关系数矩阵)
result5=X.corr(Y)
print(result5)
# 计算df中所有列之间的相关系数矩阵,
# 而且相关系数矩阵上会给出列名,看起来更加直观
# 确保df中的每一列都是数值,而不要存在是字符串的列。
# 也可以通过columns筛选列进行相关性分析(如之前的代码)
result6=df.corr()
print(result6)- 画出相关系数矩阵的热力图
import seaborn as sns
import matplotlib.pyplot as plt
plt.subplots(figsize = (12,12))
sns.heatmap(df.corr(), annot=True, square=True, cmap = "Reds")
plt.show() 















 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









