







 本文档详述了如何在Hadoop YARN-client模式和Spark Standalone集群上运行WordCount程序,以及如何在Eclipse中配置并运行Python Spark程序。内容包括YARN上提交作业的步骤、查看HDFS输出、Spark Standalone Cluster的启动与运行、以及在Eclipse外部工具中设置和运行Spark程序。
本文档详述了如何在Hadoop YARN-client模式和Spark Standalone集群上运行WordCount程序,以及如何在Eclipse中配置并运行Python Spark程序。内容包括YARN上提交作业的步骤、查看HDFS输出、Spark Standalone Cluster的启动与运行、以及在Eclipse外部工具中设置和运行Spark程序。
11.13在Hadoop YARN-client上运行WordCount程序
介绍的是使用spark-submit在Hadoop Yarn上运行Wordcount程序
11.13.1在Hadoop Yarn上运行Wordcount程序
cd ~/pythonwork/PythonProject
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop spark-submit --driver-memory 512m --executor-cores 2 --master yarn --deploy-mode client WordCount.py
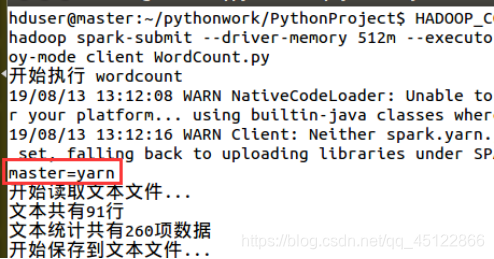
11.13.2查看执行完成后HDFS产生的目录
hadoop fs -ls /user/hduser/data/output
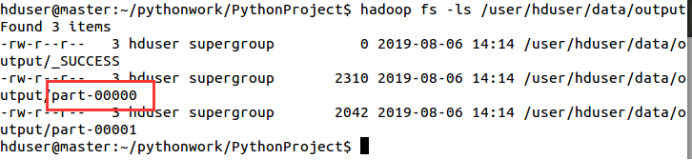
11.13.3查看执行完成后HDFS产生的文件
hadoop fs -cat /user/hduser/data/output/part-00000 |more
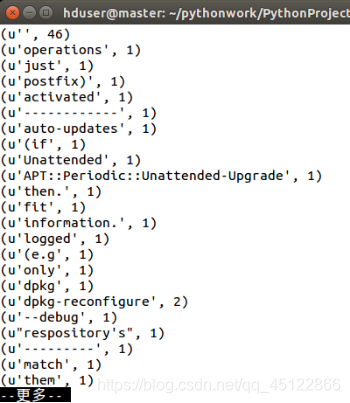
11.13.4在Hadoop Web界面查看WordCounts
网址:http://master:8088/
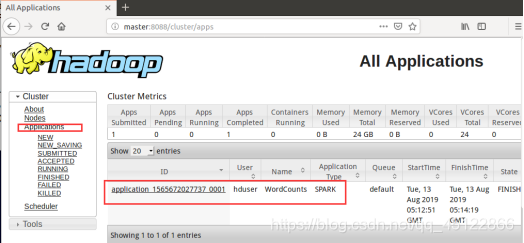
11.14在Spark Standalone Cluster上运行WordCount程序
11.14.1删除已产生的目录
hadoop fs -rm -R /user/hduser/data/output

11.14.2启动Standalone Cluster
/usr/local/spark/sbin/start-all.sh
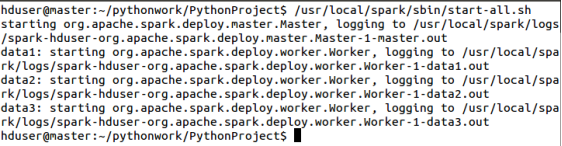
11.14.3在Spark Standalone Cluster上运行WordCount程序
cd ~/pythonwork/PythonProject
spark-submit --master spark://master:7077 --deploy-mode client --executor-memory 500m --deploy-mode client --total-executo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









