







本次需求是,pdf是表格类型的文件,我这里使用了word模板进行处理。但由于是多个文件一起导出,因此全部放到一个目录底下进行打包下载。
## 整体思路
/**
* 下载思路:
* 1、查询出数据后;
* 2、将数据按照word模板插入数据生成word文件,将word文件转成pdf(所有生成的数据都同一新增的目录下);
* 3、将该目录底下的所有文件打包成压缩包;
* 4、进行下载操作;
* 5、下载完毕需要对于zip包和word文件目录删除
*/
1.前提先准备好word模板, 记得模板里面的字段名字 要和实体类的属性名要一致 才能填充数据成功。
操作方法 跳转链接:https://blog.csdn.net/XuDream/article/details/122121892
使用模板生成word文档工具类 GenerateWordUtil :
ps:fileUtil方法步骤4有;
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import org.jeecg.common.util.file.FileUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.*;
import java.util.Map;
/**
* 模板生成word文档工具类
* @author xty
*/
public class GenerateWordUtil {
private static final Logger LOGGER = LoggerFactory.getLogger(GenerateWordUtil.class);
/**
* 通过模板生成word文档
* @param data 要填充的数据
* @param templatePath 模板路径
* @param templateFileName 模板名称
* @param docFilePath 输出文档路径
* @param docFileName 输出文档名称
*
*/
public static void generateWordByTemplate(Map<String, Object> data ,String templatePath, String templateFileName, String docFilePath, String docFileName) throws Exception {
try{
//Configuration 用于读取ftl文件
Configuration configuration = new Configuration();
configuration.setDefaultEncoding("utf-8");
//指定路径的第二种方式,我的路径是F:/test.ftl
configuration.setDirectoryForTemplateLoading(new File(templatePath));//ftl文件目录
//输出文档
File outFile = new File(docFilePath+File.separator+docFileName);
//创建目录
FileUtils.isExistDir(docFilePath);
//以utf-8的编码读取ftl文件
Template template = configuration.getTemplate(templateFileName, "utf-8");
Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile), "utf-8"), 10240);
template.process(data, out);
out.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
ps:传入的map,可以用实体类转换一下,记得属性不能为空,为空的话可以就行循环赋值“ ”;
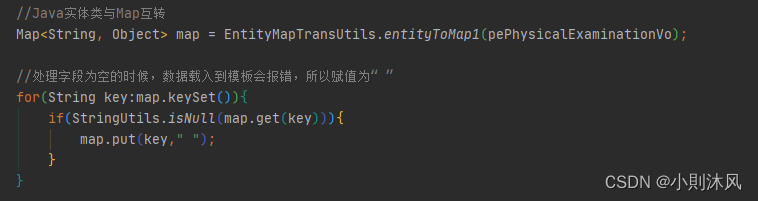
- Java实体类与Map互转工具类
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
1. Java实体类与Map互转
2. 3. @author xty
*/
public class EntityMapTransUtils {
private static final Logger logger = LoggerFactory.getLogger(EntityMapTransUtils.class);
/**
4. Java实体类转Map:方法一
5. @param obj
6. @return
*/
public static Map<String, Object> entityToMap1(Object obj){
Map<String, Object> map = new HashMap<String, Object>();
Class<?> clazz = obj.getClass();
for(Field field : clazz.getDeclaredFields()){
field.setAccessible(true);
String fieldName = field.getName();
Object object = null;
try {
object = field.get(obj);
} catch (IllegalArgumentException | IllegalAccessException e) {
logger.info(e.getMessage());
}
map.put(fieldName, object);
}
return map;
}
/**
7. Java实体类转Map:方法二
8. @param obj
9. @return
*/
public static Map<String, Object> entityToMap2(Object obj){
Map<String, Object> map = new HashMap<String, Object>();
try {
BeanInfo beanInfo = Introspector.getBeanInfo(obj.getClass());
PropertyDescriptor[] propertyDescriptors = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor property : propertyDescriptors) {
String key = property.getName();
// 过滤class属性
if (!key.equals("class")) {
// 得到property对应的getter方法
Method getter = property.getReadMethod();
Object value = getter.invoke(obj);
map.put(key, value);
}
}
} catch (Exception e) {
logger.info(e.getMessage());
}
return map;
}
/**
10. Map转实体类:要转换的Map的key跟实体类属性名相同的数据会转过去,不相同的字段会为null
11. @param clazz
12. @param map
13. @return
*/
public static <T> T mapToEntity1(Class<T> clazz,Map<String, Object> map){
T obj = null;
try {
BeanInfo beanInfo = Introspector.getBeanInfo(clazz);
obj = clazz.newInstance(); // 创建 JavaBean 对象
PropertyDescriptor[] propertyDescriptors = beanInfo.getPropertyDescriptors();
// 给 JavaBean 对象的属性赋值
for (int i = 0; i < propertyDescriptors.length; i++) {
PropertyDescriptor descriptor = propertyDescriptors[i];
String propertyName = descriptor.getName();
if (map.containsKey(propertyName)) {
Object value = map.get(propertyName);
Object[] args = new Object[1];
args[0] = value;
try {
descriptor.getWriteMethod().invoke(obj, args);
} catch (InvocationTargetException e) {
logger.info(e.getMessage());
}
}
}
} catch (IllegalAccessException e) {
logger.info(e.getMessage());
} catch (IntrospectionException e) {
logger.info(e.getMessage());
} catch (IllegalArgumentException e) {
logger.info(e.getMessage());
} catch (InstantiationException e) {
logger.info(e.getMessage());
}
return (T)obj;
}
}
- 生成word文件到目录底下后,在将word文件转成pdf,然后删除掉word文件
依赖:
<!--导出word-->
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>fr.opensagres.xdocreport.template.freemarker</artifactId>
<version>2.0.2</version>
</dependency>
<!--word转pdf-->
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc.free</artifactId>
<version>5.2.0</version>
</dependency>
Word转pdf工具类:
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.File;
/**
* Word转pdf工具类
* @author xty
*/
public class WordToPdfUtil {
/**
* Word转pdf
* @param docFilePath
* @param pdfFilePath
*/
public static void wordToPdf( String docFilePath, String pdfFilePath) {
//实例化Document类的对象
Document doc = new Document();
//加载Word docFilePath需要为完整路径+文件名
doc.loadFromFile(docFilePath);
//保存为PDF格式 pdfFilePath需要为完整路径+文件名
doc.saveToFile(pdfFilePath, FileFormat.PDF);
//删除原来的doc文件
File file = new File(docFilePath);
file.delete();
}
}
- 将指定路径下的所有文件打包zip导出下载

工具类:
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang.StringUtils;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
/**
1. 将指定路径下的所有文件打包zip导出工具类
2. @author xty
*/
public class FileZipUtil {
/**
* 将指定路径下的所有文件打包zip导出
*
* @param response HttpServletResponse
* @param sourceFilePath 要打包的路径
* @param fileName 下载时的文件名称
* // * @param postfix 下载时的文件后缀 .zip/.rar
*/
public static void exportZip(HttpServletResponse response, String sourceFilePath, String fileName) {
// 默认文件名以时间戳作为前缀
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
String downloadName = sdf.format(new Date()) + fileName;
// 将文件进行打包下载
try {
OutputStream os = response.getOutputStream();
// 接收压缩包字节
byte[] data = createZip(sourceFilePath);
response.reset();
response.setCharacterEncoding("UTF-8");
response.addHeader("Access-Control-Allow-Origin", "*");
response.setHeader("Access-Control-Expose-Headers", "*");
// 下载文件名乱码问题
response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(downloadName, "UTF-8"));
//response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + downloadName);
response.addHeader("Content-Length", "" + data.length);
response.setContentType("application/octet-stream;charset=UTF-8");
IOUtils.write(data, os);
os.flush();
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 创建zip文件
*
* @param sourceFilePath
* @return byte[]
* @throws Exception
*/
private static byte[] createZip(String sourceFilePath) throws Exception {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
ZipOutputStream zip = new ZipOutputStream(outputStream);
// 将目标文件打包成zip导出
File file = new File(sourceFilePath);
handlerFile(zip, file, "");
// 无异常关闭流,它将无条件的关闭一个可被关闭的对象而不抛出任何异常。
IOUtils.closeQuietly(zip);
return outputStream.toByteArray();
}
/**
* 打包处理
*
* @param zip
* @param file
* @param dir
* @throws Exception
*/
private static void handlerFile(ZipOutputStream zip, File file, String dir) throws Exception {
// 如果当前的是文件夹,则循环里面的内容继续处理
if (file.isDirectory()) {
//得到文件列表信息
File[] fileArray = file.listFiles();
if (fileArray == null) {
return;
}
//将文件夹添加到下一级打包目录
zip.putNextEntry(new ZipEntry(dir + "/"));
dir = dir.length() == 0 ? "" : dir + "/";
// 递归将文件夹中的文件打包
for (File f : fileArray) {
handlerFile(zip, f, dir + f.getName());
}
} else {
// 如果当前的是文件,打包处理
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file));
ZipEntry entry = new ZipEntry(dir);
zip.putNextEntry(entry);
zip.write(FileUtils.readFileToByteArray(file));
IOUtils.closeQuietly(bis);
zip.flush();
zip.closeEntry();
}
}
}
- 下载完成之后,删掉临时zip包和临时生成的文件夹

fileUtil工具类新增两个方法
/**
* 删除指定文件夹下文件
*
* @param filePath
*/
public static void deleteFolders(String filePath) {
Path path = Paths.get(filePath);
try {
Files.walkFileTree(path, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attributes) throws IOException {
Files.delete(file);
LOGGER.info("删除文件: {}", file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir,
IOException exc) throws IOException {
Files.delete(dir);
LOGGER.info("文件夹被删除: {}", dir);
return FileVisitResult.CONTINUE;
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 判断多级路径是否存在,不存在就创建
*
* @param filePath 支持带文件名的Path:如:D:
ews201412abc.text,和不带文件名的Path:如:D:
ews201412
*/
public static void isExistDir(String filePath) {
String paths[] = {""};
//切割路径
try {
String tempPath = new File(filePath).getCanonicalPath();//File对象转换为标准路径并进行切割,有两种windows和linux
paths = tempPath.split("\\\\");//windows
if(paths.length==1){paths = tempPath.split("/");}//linux
} catch (IOException e) {
System.out.println("切割路径错误");
e.printStackTrace();
}
//判断是否有后缀
boolean hasType = false;
if(paths.length>0){
String tempPath = paths[paths.length-1];
if(tempPath.length()>0){
if(tempPath.indexOf(".")>0){
hasType=true;
}
}
}
//创建文件夹
String dir = paths[0];
for (int i = 0; i < paths.length - (hasType?2:1); i++) {// 注意此处循环的长度,有后缀的就是文件路径,没有则文件夹路径
try {
dir = dir + "/" + paths[i + 1];//采用linux下的标准写法进行拼接,由于windows可以识别这样的路径,所以这里采用警容的写法
File dirFile = new File(dir);
if (!dirFile.exists()) {
dirFile.mkdir();
System.out.println("成功创建目录:" + dirFile.getCanonicalFile());
}
} catch (Exception e) {
System.err.println("文件夹创建发生异常");
e.printStackTrace();
}
}
}
最后附上接口方法;上面那些代码块都是对于方法的补充,只是记录学习一下,整合了各个大佬的方法最终实现的。
路径和模板配置

引入属性;
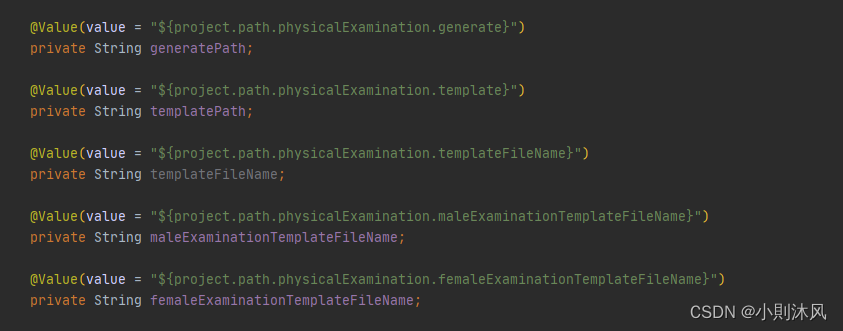
接口方法:
// 下载体检报告PDF
@AutoLog(value = "学校体检列表-下载体检报告PDF", operateType = CommonConstant.OPERATE_TYPE_ADD)
@ApiOperation(value="学校体检列表-下载体检报告PDF", notes="学校体检列表-下载体检报告PDF")
@GetMapping(value = "/uploadPhysicalExaminationListPDF")
public void uploadPhysicalExaminationListPDF(@RequestParam Integer activityId,
@RequestParam Integer gradeCode,
@RequestParam Integer classCode,
@RequestParam Integer gender,
@RequestParam Integer releaseStatus,
HttpServletResponse response) throws Exception {
/**
* 下载思路:
* 1、查询出数据后;
* 2、将数据按照word模板插入数据生成word文件,将word文件转成pdf(所有生成的数据都同一新增的目录下);
* 3、将该目录底下的所有文件打包成压缩包;
* 4、进行下载操作;
* 5、下载完毕需要对于zip包和word文件目录删除
*/
PePhysicalExaminationQuery pePhysicalExaminationQuery = new PePhysicalExaminationQuery();
pePhysicalExaminationQuery.setActivityId(activityId);
pePhysicalExaminationQuery.setGradeCode(gradeCode);
pePhysicalExaminationQuery.setClassCode(classCode);
pePhysicalExaminationQuery.setGender(gender);
pePhysicalExaminationQuery.setReleaseStatus(releaseStatus);
List<PePhysicalExaminationVo> pePhysicalExaminationVos = pePhysicalExaminationService.selectPhysicalExaminationListToPDF(pePhysicalExaminationQuery);
if(pePhysicalExaminationVos==null||pePhysicalExaminationVos.size()<1){
log.error("查询到体检数据为空");
return;
}
//存放doc和pdf的目录 后面用前缀路径拼接起来。因为打包要单独在一个目录底下
String folderName = DateUtil.format(new Date(), DatePattern.PURE_DATETIME_PATTERN)+(int) (Math.random()*9000+1000);//时间+随机生成一个四位整数;
//循环进行数据插入到doc模板中,生成word文件;然后转pdf到底下
for (PePhysicalExaminationVo pePhysicalExaminationVo:pePhysicalExaminationVos){
try {
//Java实体类与Map互转
Map<String, Object> map = EntityMapTransUtils.entityToMap1(pePhysicalExaminationVo);
//处理字段为空的时候,数据载入到模板会报错,所以赋值为“ ”
for(String key:map.keySet()){
if(StringUtils.isNull(map.get(key))){
map.put(key," ");
}
}
//输出文档路径及名称
String docFilePath = generatePath + folderName;
String docFileName = pePhysicalExaminationVo.getStudentName() + ".doc";
if("男".equals(pePhysicalExaminationVo.getGender())){
//使用男生体检模板
GenerateWordUtil.generateWordByTemplate(map,templatePath,maleExaminationTemplateFileName, docFilePath,docFileName);
}else {
//使用女生体检模板
GenerateWordUtil.generateWordByTemplate(map,templatePath,femaleExaminationTemplateFileName, docFilePath,docFileName);
}
//将生成的word转换成pdf File.separator分隔符
String pdfFileName = generatePath + folderName + File.separator + pePhysicalExaminationVo.getStudentName() + ".pdf";
WordToPdfUtil.wordToPdf(docFilePath+File.separator+docFileName,pdfFileName);
} catch (Exception e) {
e.printStackTrace();
}
}
//将指定路径下的所有文件打包zip导出下载
FileZipUtil.exportZip(response, generatePath+folderName, generatePath+"temporary.zip");
//下载完成之后,删掉临时zip包和临时生成的文件夹
File file = new File(generatePath+"temporary.zip");
file.delete();
FileUtils.deleteFolders(generatePath+folderName);
}
对了;前端下载的话,返回的流。前端直接保存即可

















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









